Why is it so difficult to store in Kubernetes?

When container orchestrators arrived, like Kubernetes, the approach to developing and deploying applications changed dramatically. Microservices have appeared, and for the developer, the logic of the application is no longer related to the infrastructure: create applications for yourself and offer new functions.
Kubernetes abstracts from the physical computers it controls. Just tell him how much memory and computing power you need - and you’ll get everything. Ifrastruktura? No, have not heard.
Managing images Docker, Kubernetes and applications makes it portable. Having developed container applications with Kubernetes, they can be deployed at least anywhere: in an open cloud, locally or in a hybrid environment - and without changing the code.
We love Kubernetes for scalability, portability and manageability, but it does not store the state. But we have almost all stateful applications, that is, they need external storage.
Kubernetes has a very dynamic architecture. Containers are created and destroyed depending on the load and instructions of the developers. Pods and containers are self-replicating and replicating. They are, in fact, ephemeral.
External storage such variability is too tough. It does not obey the rules of dynamic creation and destruction.
Just need to deploy a stateful application to another infrastructure: to another cloud there, locally or into a hybrid model — how it has problems with portability. External storage can be tied to a specific cloud.
Here are just in these repositories for cloud applications hell break his leg. And go and understand the clever ideas and meanings of terminology repositories in Kubernetes . And there are also Kubernetes own storage facilities, open-source platforms, managed or paid services ...
Here are examples of CNCF cloud storage :

It would seem, deploy a database in Kubernetes - you just need to choose the appropriate solution, pack it into a container to work on the local disk and deploy it to the cluster as the next workload. But the database has its own characteristics, so thinking is not ice.
Containers - they are so stuck up that they do not save their condition. That is why they are so easy to start and stop. And since there is nothing to save and transfer, the cluster does not bother with read and copy operations.
With the database state will have to be stored. If a database deployed on a cluster in a container is not transferred anywhere and does not start up too often, data storage physics comes into play. Ideally, containers that use data should be in the same database as the database.
In some cases, the database, of course, can be expanded into a container. In a test environment or in tasks where there is little data, databases comfortably live in clusters.
For production, you usually need external storage.
Kubernetes communicates with the repository through control plane interfaces. They link Kubernetes to an external repository. External storage bound to Kubernetes are called volume plugins. With them, you can abstract storage and move storage.
Previously, volume plug-ins were created , tied, compiled, and delivered using the Kubernetes codebase. This greatly limited the developers and required additional maintenance: if you want to add new storages, please change the Kubernetes code base.
Now the volume plug-ins are clustered — I don't want to. And there is no need to dig into the code base. Thanks to CSI and Flexvolume.
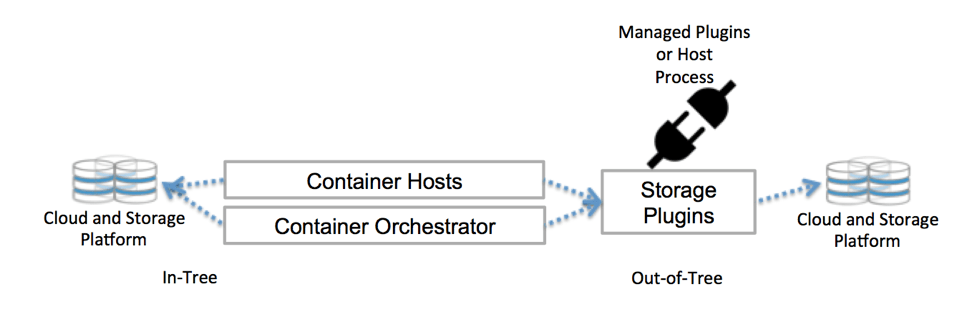
Kubernetes own storage
How does Kubernetes handle storage issues? There are several solutions: ephemeral variants, persistent storage in persistent volumes, Persistent Volume Claim queries, storage classes or StatefulSets. Come see, in general.
Persistent Volumes (PV) are storage units prepared by the admin. They do not depend on hearths and their transient life.
Persistent Volume Claim (PVC) are storage requests, that is, PV. With PVC, you can bind storage to a node, and this node will use it.
You can work with the storage statically or dynamically.
With a static approach, the admin prepares the PVs that are supposed to be needed beforehand, before requests, and these PVs are manually tied to specific deliveries using explicit PVCs.
In practice, specially defined PVs are incompatible with the portable Kubernetes structure — storage depends on the environment, such as AWS EBS or a permanent GCE disk. For manual binding, you need to point to a specific repository in the YAML file.
The static approach is generally contrary to the Kubernetes philosophy: CPUs and memory are not allocated in advance and are not tied to pits or containers. They are issued dynamically.
For dynamic preparation, we use storage classes. The cluster administrator does not need to create a PV in advance. It creates several storage profiles, like templates. When a developer makes a PVC request, at the time of the request one of these templates is created and bound to the hearth.

So, in a very general way, Kubernetes works with external storage. There are many other options.
CSI - Container Storage Interface
There is such a thing - Container Storage Interface . CSI was created by the CNCF Storage Group, which decided to define a standard container storage interface so that the storage drivers work with any orchestrator.
The CSI specifications are already adapted for Kubernetes, and there are a bunch of driver plugins for deployments in the Kubernetes cluster. You need to access the storage through a CSI-compatible volume driver — use the csi volume type in Kubernetes.
With CSI, storage can be considered another workload for containerization and deployment to the Kubernetes cluster.
If you want more details, listen to how Jie Yu talks about CSI in our podcast .
Open-source projects
Tools and projects for cloud technologies are rapidly multiplying, and a fair share of open-source projects - which is logical - solve one of the main problems of production: working with repositories in cloud architecture.
The most popular ones are Ceph and Rook.
Ceph is a dynamically managed, distributed storage cluster with horizontal scaling. Ceph provides a logical abstraction for storage resources. He does not have a single point of failure, he controls himself and works on the basis of software. Ceph provides interfaces for storing blocks, objects, and files simultaneously for a single storage cluster.
Ceph has a very complex architecture with RADOS, librados, RADOSGW, RDB, CRUSH algorithm and various components (monitors, OSD, MDS). We will not delve into the architecture, it’s enough to understand that Ceph is a distributed storage cluster that simplifies scalability, eliminates a single point of failure without sacrificing performance, and provides a single storage with access to objects, blocks and files.
Naturally, Ceph is adapted for the cloud. You can deploy a Ceph cluster in different ways, for example, using Ansible or in a Kubernetes cluster via CSI and PVC.
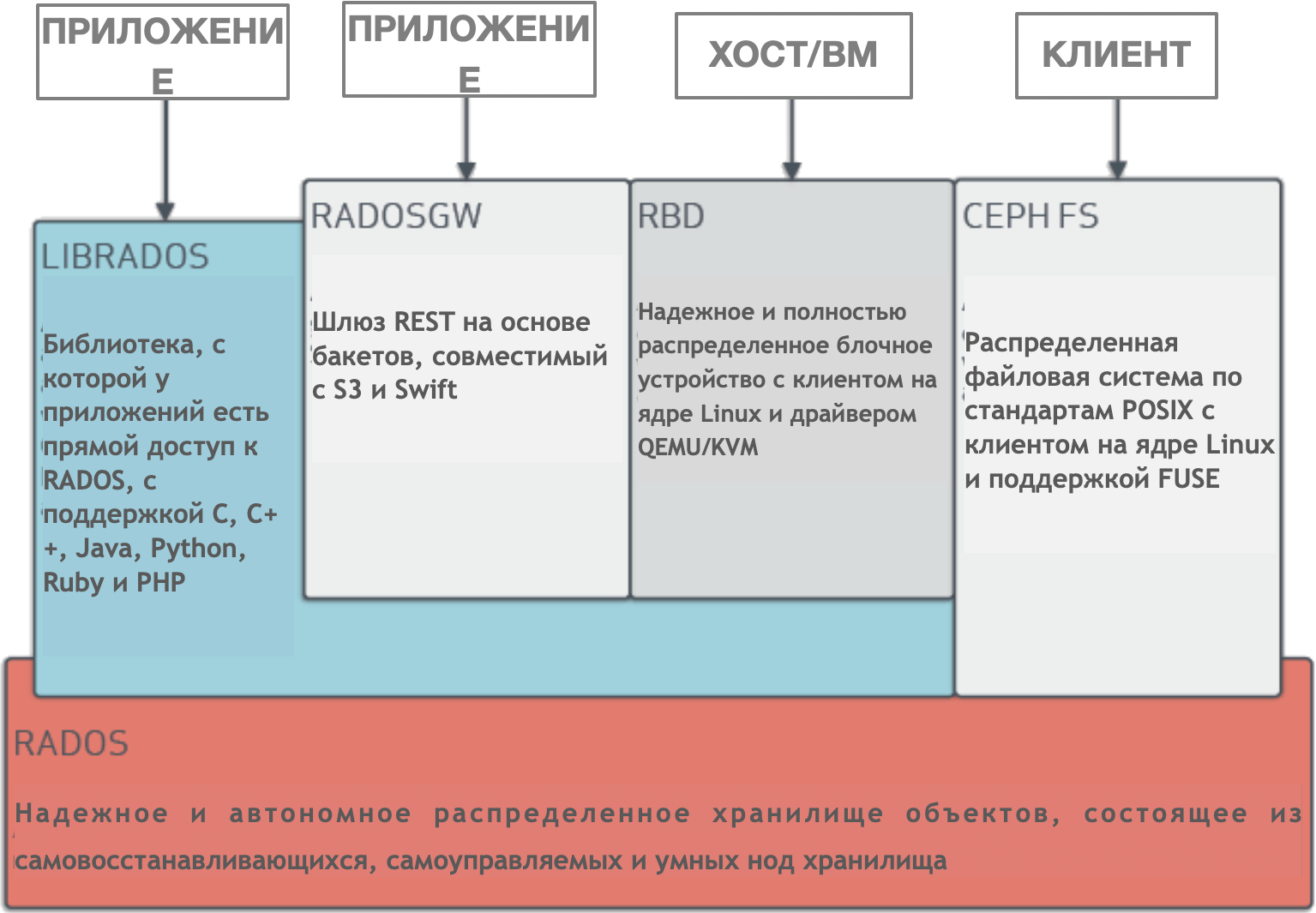
Ceph architecture
Rook is another interesting and popular project. He combines Kubernetes with his calculations and Ceph with his storages into one cluster.
Rook is a cloud storage orchestrator that complements Kubernetes. With it, Ceph is packed into containers and used cluster management logic for reliable Ceph operation in Kubernetes. Rook automates the warmup, bootstrapping, tuning, scaling, rebalancing - in general, everything that the admin cluster does.
With Rook, a Ceph cluster can be deployed from yaml, like Kubernetes. In this file, the admin in general describes what he needs in a cluster. Rook starts the cluster and starts actively monitoring. This is something like an operator or controller - he ensures that all requirements from yaml are fulfilled. Rook runs synchronization cycles — it sees the state and takes action if there are deviations.
He does not have his constant state and he does not need to manage. Quite in the spirit of Kubernetes.
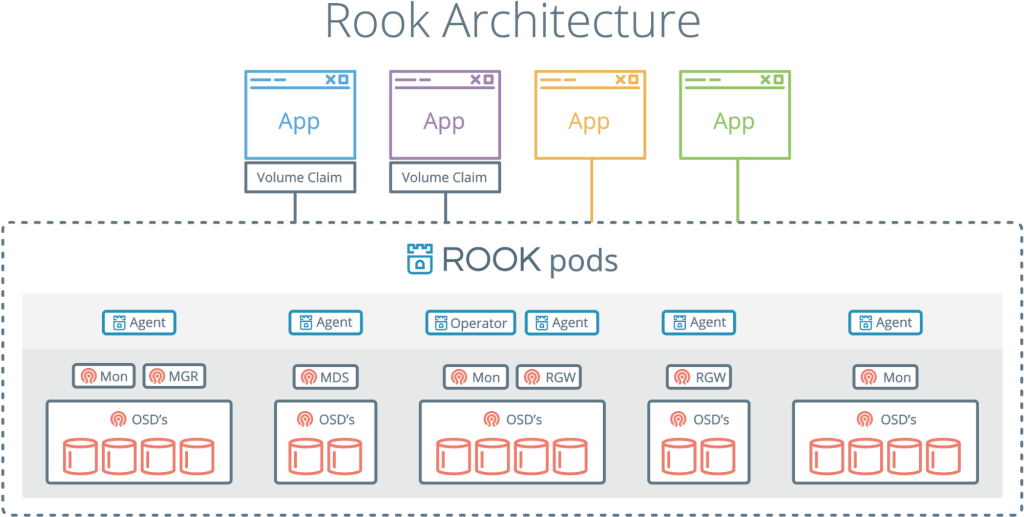
Rook, combining Ceph and Kubernetes, is one of the most popular cloud storage solutions: 4000 stars on Github, 16.3 million downloads and more than a hundred contributors.
The Rook project has already been accepted at CNCF, and recently it has fallen into an incubator .
More about Rook will tell you about Bassam Tabara in our repository episode in Kubernetes .
If the application has a problem, you need to know the requirements and create a system or take the necessary tools. This also applies to storage in the cloud. And although the problem is not simple, we have heaps of tools and approaches. Cloud technologies continue to evolve, and we are definitely waiting for new solutions.
')
Source: https://habr.com/ru/post/441222/
All Articles