Ascetic web: prototype flea market on go and js
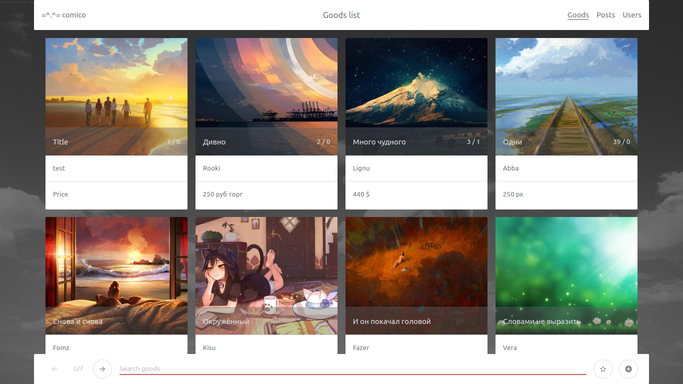
Hello everyone, I want to share the result of thinking on the topic - what could be a modern web application. As an example, consider the design of a bulletin board for comics. In a sense, the product in question is designed for an audience of geeks and their sympathizers, which allows for freedom in the interface. The technical component, on the contrary, requires attention to trifles.
Truth be told, I do not understand anything in comics, but I like flea markets, especially in forum format, which were popular in zero. Hence, the assumption (possibly false), from which the subsequent conclusions flow, only one - the main type of interaction with the application - viewing, secondary - placement of announcements and discussion.
Our goal is to create a simple application, without technical know-how extra whistles, however, corresponding to modern realities. Basic requirements that I would like to achieve:
Server part:
a) Performs the functions of saving, validating, sending user data to the client
b) The above operations consume an acceptable amount of resources (time, incl.)
c) Application and data are protected from popular attack vectors.
d) It has a simple API for third-party clients and inter-server communication.
e) Cross-platform, simple deploymentClient part:
a) Provides the necessary functionality for creating and consuming content.
b) The interface is convenient for regular use, the minimum way to any action, the maximum amount of data on the screen
c) Out of communication with the server, all possible functions are available in this situation.
d) The interface displays the current version of the status and content, without rebooting and waiting
e) Restarting the application does not affect its state.
e) If possible, reuse DOM elements and JS code
g) We will not use third-party libraries and frameworks in runtime.
h) Layout is semantic for accessibility, parsers, etc.
i) Navigation through the main content is available using the URL and keyboard
In my opinion, the logical requirements, and most modern applications in varying degrees, meet these conditions. Let's see what happens with us (link to source code and demo at the end of the post).
- I would like to apologize to the authors of the images used in the demo without permissions, as well as Goess G.
- The author is not a real programmer, I do not advise using the code or techniques used in this project, if you do not know what you are doing.
- I apologize for the style of the code, it was possible to write more readable and obvious, but it is not fun. A project for the soul and for a friend, as is as they say.
- I also apologize for the literacy rate, especially in the English text. Years Speak Frome May Hart.
- The performance of the presented prototype was tested in [chromium 70; linux x86_64; 1366x768], I will be very grateful to users of other platforms and devices for error messages.
- This is a prototype and a proposed topic for discussion - approaches and principles, I ask you to accompany all the criticism of the implementation and the aesthetic side with arguments.
Server
The language for the server is golang. Simple, fast language with excellent standard library and documentation ... a bit annoying. The initial choice fell on elixir / erlang, but since I already knew go (relatively), it was decided not to complicate (and the necessary packages were only for go).
The use of web frameworks in the go-community is not encouraged (justifiably, we must admit), we choose a compromise and use labstack / echo microframe , thereby reducing the amount of routine and, it seems to me, not much losing in performance.
We use tidwall / buntdb as the database. Firstly, the embedded solution is more convenient and reduces overhead, secondly in-memory + key / value - fashionable, stylish fast and no need for cache. We store and give data in JSON, validating only when changed.
On the second generation i3, the built-in logger shows the execution time for different requests from 0.5 to 10 ms. Running wrk on the same machine also shows sufficient results for our purposes:
➜ comico git:(master) wrk -t2 -c500 -d60s http://localhost:9001/pub/mtimes Running 1m test @ http://localhost:9001/pub/mtimes 2 threads and 500 connections Thread Stats Avg Stdev Max +/- Stdev Latency 20.74ms 16.68ms 236.16ms 72.69% Req/Sec 13.19k 627.43 15.62k 73.58% 1575522 requests in 1.00m, 449.26MB read Requests/sec: 26231.85 Transfer/sec: 7.48MB ➜ comico git:(master) wrk -t2 -c500 -d60s http://localhost:9001/pub/goods Running 1m test @ http://localhost:9001/pub/goods 2 threads and 500 connections Thread Stats Avg Stdev Max +/- Stdev Latency 61.79ms 65.96ms 643.73ms 86.48% Req/Sec 5.26k 705.24 7.88k 70.31% 628215 requests in 1.00m, 8.44GB read Requests/sec: 10454.44 Transfer/sec: 143.89MB Project structure
The comico / model package is divided into three files:
model.go - contains a description of data types and common functions: create / update (buntdb does not distinguish between these operations and the presence of a record we check manually), validation, deletion, getting one record and getting a list;
rules.go - contains validation rules for a specific type and logging function;
files.go - work with images.
The Mtimes type stores data on the last change of other types in the database, thus informing the client what data has changed.
The comico / bd package contains generalized functions for interacting with the database: creating, deleting, selecting, etc. Buntdb saves all changes to the file (in our case once per second), in text format, which is convenient in some situations. The database file is not edited; changes in case of success are added to the end of the transaction. All my attempts to violate the integrity of the data were unsuccessful, in the worst case, the changes are lost in the last second.
In our implementation, each type corresponds to a separate database in a separate file (except for logs that are stored exclusively in memory and are reset when reset). This is largely due to the convenience of backup and administration, a small plus - the transaction opened for editing blocks access to only one type of data.
This package can be easily replaced by a similar one using another database, SQL for example. To do this, simply implement the following functions:
func Delete(db byte, key string) error func Exist(db byte, key string) bool func Insert(db byte, key, val string) error func ReadAll(db byte, pattern string) (str string, err error) func ReadOne(db byte, key string) (str string, err error) func Renew(db byte, key string) (err error, newId string) The comico / cnst package contains some constants necessary in all packages (data types, action types, user types). In addition, this package contains all human-readable messages with which our server will respond to the outside world.
The comico / server package contains routing information. Also, just a couple of lines (thanks to the Echo developers), authorization using JWT, CORS headers, CSP headers, logger, static distribution, gzip, ACME auto-certificate, etc. are configured.
API entry points
| URL | Data | Description |
|---|---|---|
| get / pub / (goods | posts | users | cmnts | files) | - | Getting an array of current ads, posts, users, comments, files |
| get / pub / mtimes | - | Getting the last modified time for each data type |
| post / pub / login | {id *: login, pass *: password} | Returns the JWT token and its duration |
| post / pub / pass | {id *, pass *} | Creates a new user if the data is correct. |
| put / api / pass | {id *, pass *} | Password update |
| post | put / api / goods | {id *, auth *, title *, type *, price *, text *, images: [], Table: {key: value}} | Create / Update Advertisement |
| post | put / api / posts | {id *, auth *, title *, type *, text *} | Create / update forum post |
| post | put / api / users | {id *, title, type, status, scribes: [], ignores: [], Table: {key: value}} | Create / update user |
| post / api / cmnts | {id *, auth *, owner *, type *, to, text *} | Creating a comment |
| delete / api / (goods | posts | users | cmnts) / [id] | - | Deletes an entry with id id |
| get / api / activity | - | Updates the time of the last reading of incoming comments for the current user. |
| get / api / (subscribe | ignore) / [tag] | - | Adds or deletes (if available) the user tag in the list of subscriptions / ignore |
| post / api / upload / (goods | users) | multipart (name, file) | Uploads a user's photo / avatar |
* - required fields
api - requires authorization, pub - no
When a get request does not match the above, the server searches for a file in the static directory (for example, / img / * - images, /index.html - client).
Any point api with success returns a response code of 200, with an error of 400 or 404 and a short message if necessary.
Access rights are simple: creating a record is available to an authorized user, editing the author and moderator, the admin can edit and assign moderators.
The API is equipped with the simplest anti-vandal: actions are logged along with the user’s id and IP, and, in case of frequent access, an error is returned asking to wait a bit (useful against password guessing).
Customer
I like the concept of a reactive web, I think that most modern sites / applications should be done either within the framework of this concept, or completely static. On the other hand, an uncomplicated website with megabytes of JS-code can not fail. In my opinion, this (and not only) problem can be solved by Svelte. This framework (or rather, the language for building reactive interfaces) is not inferior to the necessary functionality of the same Vue, but has an undeniable advantage - the components are compiled into vanilla JS, which reduces both the size of the bundle and the load on the virtual machine (bundle.min.js.gz our flea market is modest, by today's standards, 24KB). Details you can learn from the official documentation .
We choose SvelteJS for the client part of our flea market, we wish Rich Harris all the best and further development of the project!
PS I do not want to offend anyone. I am sure that for each specialist and each project their own toolkit is suitable.
Customer / Data
URL
Use for navigation. We will not imitate a multi-page document; instead, we use page hash with query parameters. For transitions, you can use the usual <a> without js.
Sections correspond to data types: / # goods , / # posts , / # users .
Parameters :? Id = entry_id ,? Page = page_number ,? Search = search_query .
A few examples:
- / # posts? id = 1542309643 & page = 999 & search = {auth: anon} - posts section, post id - 1542309643 , comments page - 999 , search query - {auth: anon}
- / # goods? page = 2 & search = siddhartha - goods section, section page - 2 , search query - siddhartha
- / # goods? search = wer {key: value} t - the goods section, the search query - consists of searching for the substring wert in the header or ad text and substring value in the key property of the table part of the advertisement
- / # goods? search = {model: 100, display: 256} - I think everything is clear by analogy
The parsing and url generation functions in our implementation look like this:
window.addEventListener('hashchange', function() { const hash = location.hash.slice(1).split('?'), result = {} if (!!hash[1]) hash[1].split('&').forEach(str => { str = str.split('=') if (!!str[0] && !!str[1]) result[decodeURI(str[0]).toLowerCase()] = decodeURI(str[1]).toLowerCase() }) result.type = hash[0] || 'goods' store.set({ hash: result }) }) function goto({ type, id, page, search }) { const { hash } = store.get(), args = arguments[0], query = [] new Array('id', 'page', 'search').forEach(key => { const value = args[key] !== undefined ? args[key] : hash[key] || null if (value !== null) query.push(key + '=' + value) }) location.hash = (type || hash.type || 'goods') + (!!query.length ? '?' + query.join('&') : '') } API
For data exchange with the server we will use fetch api. To download updated posts at short intervals, make a request to / pub / mtimes , if the last modified time for any type is different from the local one, download the list of this type. Yes, it was possible to implement update notification via SSE or WebSocket and incremental upload, but in this case we can do without it. What we did:
async function GET(type) { const response = await fetch(location.origin + '/pub/' + type) .catch(() => ({ ok: false })) if (type === 'mtimes') store.set({ online: response.ok }) return response.ok ? await response.json() : [] } async function checkUpdate(type, mtimes, updates = {}) { const local = store.get()._mtimes, net = mtimes || await GET('mtimes') if (!net[type] || local[type] === net[type]) return const value = updates['_' + type] = await GET(type) local[type] = net[type]; updates._mtimes = local if (!!value && !!value.sort) store.set(updates) } async function checkUpdates() { setTimeout(() => checkUpdates(), 30000) const mtimes = await store.GET('mtimes') new Array('users', 'goods', 'posts', 'cmnts', 'files') .forEach(type => checkUpdate(type, mtimes)) } For filtering and pagination, we use Svelte computed properties based on navigation data. The direction of the calculated values is as follows: items (arrays of entries coming from the server) => ignoredItems (filtered entries based on the current user’s ignore list) => scribedItems (filters entries by the list of subscriptions, if this mode is activated) => curItem and curItems (calculates current entries depending on the section) => filteredItems (filters records depending on the search query, if there is one record - filters comments to it) => maxPage (calculates the number of pages at the rate of 12 records / comments per page) => pagedItem (returns the final array h entries / comments based on the current page number).
Comments and images ( comments and _images ) are calculated separately, grouped by type and owner-record.
Calculations happen automatically and only when the related data changes, intermediate data are constantly in memory. In this regard, we make an unpleasant conclusion - for a large amount of information and / or its frequent updating a large amount of resources can be spent.
Cache
According to the decision to make an offline application, we implement the storage of records and some aspects of the state in localStorage, image files in CacheStorage. Working with localStorage is extremely simple, agree that the properties with the "_" prefix are automatically saved when changed and restored upon reboot. Then our solution might look like this:
store.on('state', ({ changed, current }) => { Object.keys(changed).forEach(prop => { if (!prop.indexOf('_')) localStorage.setItem(prop, JSON.stringify(current[prop])) }) }) function loadState(state = {}) { for (let i = 0; i < localStorage.length; i++) { const prop = localStorage.key(i) const value = JSON.parse(localStorage.getItem(prop) || 'null') if (!!value && !prop.indexOf('_')) state[prop] = value } store.set(state) } The files are a bit more complicated. First of all, we will use the list of all actual files (with creation time) coming from the server. When updating this list, we compare it with the old values, we place the new files in CacheStorage, the outdated ones are deleted from there:
async function cacheImages(newFiles) { const oldFiles = JSON.parse(localStorage.getItem('_files') || '[]') const cache = await caches.open('comico') oldFiles.forEach(file => { if (!~newFiles.indexOf(file)) { const [ id, type ] = file.split(':') cache.delete(`/img/${type}_${id}_sm.jpg`) }}) newFiles.forEach(file => { if (!~oldFiles.indexOf(file)) { const [ id, type ] = file.split(':'), src = `/img/${type}_${id}_sm.jpg` cache.add(new Request(src, { cache: 'no-cache' })) }}) } Then you need to override the behavior of fetch so that the file is taken from CacheStorage without a connection to the server. To do this, you have to use the ServiceWorker. At the same time, we will configure saving the cache of other files to work out of communication with the server:
const CACHE = 'comico', FILES = [ '/', '/bundle.css', '/bundle.js' ] self.addEventListener('install', (e) => { e.waitUntil(caches.open(CACHE).then(cache => cache.addAll(FILES)) .then(() => self.skipWaiting())) }) self.addEventListener('fetch', (e) => { const r = e.request if (r.method !== 'GET' || !!~r.url.indexOf('/pub/') || !!~r.url.indexOf('/api/')) return if (!!~r.url.lastIndexOf('_sm.jpg') && e.request.cache !== 'no-cache') return e.respondWith(fromCache(r)) e.respondWith(toCache(r)) }) async function fromCache(request) { return await (await caches.open(CACHE)).match(request) || new Response(null, { status: 404 }) } async function toCache(request) { const response = await fetch(request).catch(() => fromCache(request)) if (!!response && response.ok) (await caches.open(CACHE)).put(request, response.clone()) return response } It looks a bit clumsy, but performs its functions.
Client / Interface
Component structure:
index.html | main.js
== header.html - contains a logo, status bar, main menu, lower navigation menu, commenting form
== aside.html - is a container for all modal components
==== goodForm.html - form for adding and editing ads
==== userForm.html - the form of editing the current user
====== tableForm.html - a fragment of the form for entering tabular data
==== postForm.html - form for the forum post
==== login.html - login / registration form
==== activity.html - displays comments addressed to the current user
==== goodImage.html - view the main and additional photo ads
== main.html - the container for the main content
==== goods.html - a list card or a single ad
==== users.html - the same for users
==== posts.html - I think it is clear
==== cmnts.html - list of comments for the current record
====== cmntsPager.html - pagination for comments
- In each component, we try to minimize the number of html tags.
- Classes are used only as an indicator of state.
- Similar functions are placed in the store (svelte store properties and methods can be used directly from the components by adding the prefix '$' to them).
- Most functions expect a user event or change of certain properties, manipulate the state data, save the result of their work back to the state, and end. Thus, small coherence and extensibility of the code is achieved.
- For visible speed of transitions and other UI-events, we separate out possible manipulations with data occurring in the background and actions associated with the interface, which in turn uses the current result of the calculations, rearranging, if necessary, the rest of the work will be kindly performed by the framework.
- The data of the filled form is saved in localStorage for each input in order to prevent their loss.
- In all components, we use an immutable mode in which the property object is considered to be changed only when a new reference is received, regardless of changing fields, thus speeding up our applications a little, even if the code is slightly increased.
Client / Management
To control using the keyboard use the following combinations:
Alt + s / Alt + a - toggles the page of records forward / backward; for one record it switches the page of comments.
Alt + w / Alt + q - moves to the next / previous entry (if any), works in list mode, single entry and image viewing
Alt + x / Alt + z - scrolls the page down / up. In the image viewer mode, toggles the image forward / backward.
Escape - closes the modal window, if open, returns to the list, if a single entry is open, cancels the search query in list mode
Alt + c - focuses on the search field or enter a comment, depending on the current mode
Alt + v - enables / disables photo viewing for a single ad.
Alt + r - opens / closes the list of incoming comments for an authorized user.
Alt + t - switches light / dark themes
Alt + g - list of ads
Alt + u - users
Alt + p - forum
I know that in many browsers these combinations are used by the browser itself, but for my chrome I couldn’t think of something more convenient. I will be glad to your suggestions.
In addition to the keyboard, of course, you can use the browser console. For example, store.goBack () , store.nextPage () , store.prevPage () , store.nextItem () , store.prevItem () , store.search (stringValue) , store.checkUpdate ('goods' ||' users' || 'posts' ||' files' || 'cmnts') - do what the name implies; store.get (). comments and store.get () ._ images - returns grouped files and comments; store.get (). ignoredItems and store.get (). scribedItems are lists of entries that you are ignoring and tracking. A complete list of all intermediate and calculated data is available from store.get () . I don’t think that this can seriously be necessary for someone, but, for example, it seemed to me quite convenient to filter the records by user and delete from the console.
Conclusion
On this familiarity with the project can be completed, more details can be found in the source code. As a result, we have a fairly fast and compact application, with most validators, checkers for security, speed, availability, etc., it shows good results without targeted optimization.
I would like to know the opinion of the community how justifiably used in the prototype approaches to the organization of applications, what could be the pitfalls, what would you have implemented in a fundamentally different way?
Source code, sample installation instructions and demo by reference (please to beat test under the Criminal Code of the Russian Federation).
P.S. A little mercantile in the end. Tell me with this level really start programming for money? If not, what to look for in the first place, if so, tell me where they are now looking for an interesting job on a similar stack. Thank.
Postpostcriptum A little more about money and work. How do you get such an idea: suppose a person is ready to work on an interesting project for any salary, however, data on tasks and their payment will be publicly available (accessibility is desirable and a code for assessing the quality of performance), if the payment is significantly lower than the market, the employer's competitors can offer a lot of money for performing their tasks, if higher - many performers will be able to offer their services at a lower price. Would not such a scheme in some situations more optimally and fairly balance the market (IT)?
')
Source: https://habr.com/ru/post/435908/
All Articles