It is not so easy to take and write SELECT, if the vendor does not allow ... but we still write
TL; DR: GitHub: // PastorGL / AQLSelectEx .
Once, not in the cold, but already winter time, and specifically a couple of months ago, for the project I'm working on (something Geospatial based on Big Data), it took a quick NoSQL / Key-Value storage.
We quite successfully chew terabytes of source codes with the help of Apache Spark, but the ridiculously collapsed volume (only millions of records) has to be stored somewhere. And it is very desirable to store it in such a way that it can be associated with each result line (this is one digit) metadata (but quite a lot of them) to quickly find and give out.
In this sense, the Hadupow stack formats are of little use, and relational databases on millions of records slow down, and the set of metadata is not so fixed as to fit well into the rigid scheme of the usual RDBMS - PostgreSQL in our case. No, it normally supports JSON, but it still has problems with indices on millions of records. The indices swell, the table becomes necessary to partition, and such a confusion begins with the administration that nafig-nafig.
Historically, MongoDB was used as a NoSQL on the project, but Monga shows itself worse and worse (especially in terms of stability) over time, so it was gradually decommissioned. A quick search for a more modern, faster, less buggy, and generally better alternative led to the Aerospike . Many big guys have it in favor, and I decided to check it out.
Tests have shown that, indeed, the data is stored in the story straight from Sparkov's job with a whistle, and the search for many millions of entries is much faster than in Mong. Yes, and she eats less memory. But it turned out one "but." Aerospay client API is purely functional, not declarative.
This is not important for writing to story, because all the same, all the field types of each resulting record have to be determined locally in the job itself - and the context is not lost. The functional style is right here, all the more so under the spark it is different to write code and it will not work. But in the web-face, which should upload the result to the outside world, and is a regular web application in the spring, it would be much more logical to form a standard SQL SELECT from a user form, which would be full of AND and OR - predicates , - in the WHERE clause.
Let me explain the difference on this synthetic example:
SELECT foo, bar, baz, qux, quux FROM namespace.set WITH (baz!='a') WHERE (foo>2 AND (bar<=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON) - this is both readable and relatively clear, which records the customer wanted to get. If such a request is thrown into the log as it is, it can be pulled later for manual debugging. Which is very convenient when analyzing any strange situations.
And now we will look at the appeal to the predicate API in a functional style:
Statement reference = new Statement(); reference.setSetName("set"); reference.setNamespace("namespace"); reference.setBinNames("foo", "bar", "baz", "qux", "quux"); reference.setFillter(Filter.stringNotEqual("baz", "a")); reference.setPredExp(// 20 expressions in RPN PredExp.integerBin("foo") , PredExp.integerValue(2) , PredExp.integerGreater() , PredExp.integerBin("bar") , PredExp.integerValue(3) , PredExp.integerLessEq() , PredExp.integerBin("foo") , PredExp.integerValue(5) , PredExp.integerGreater() , PredExp.or(2) , PredExp.and(2) , PredExp.stringBin("quux") , PredExp.stringValue(".*force.*") , PredExp.stringRegex(RegexFlag.ICASE) , PredExp.and(2) , PredExp.geoJSONBin("qux") , PredExp.geoJSONValue("{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}") , PredExp.geoJSONWithin() , PredExp.not() , PredExp.or(2) ); Here is the wall of code, and yes even in reverse Polish notation . No, I still understand that the stack machine is simple and convenient to implement from the point of view of the programmer of the engine itself, but to puzzle and write predicates in RPN from the client application ... I personally do not want to think of a vendor, I want to, as a consumer of this API It was convenient. And it is inconvenient to write predicates even with a vendor client extension (conceptually similar to the Java Persistence Criteria API). And there is still no readable SELECT in the query log.
In general, SQL was invented in order to write criterion queries on it in a bird's language close to the natural one. So, one wonders, what the devil?
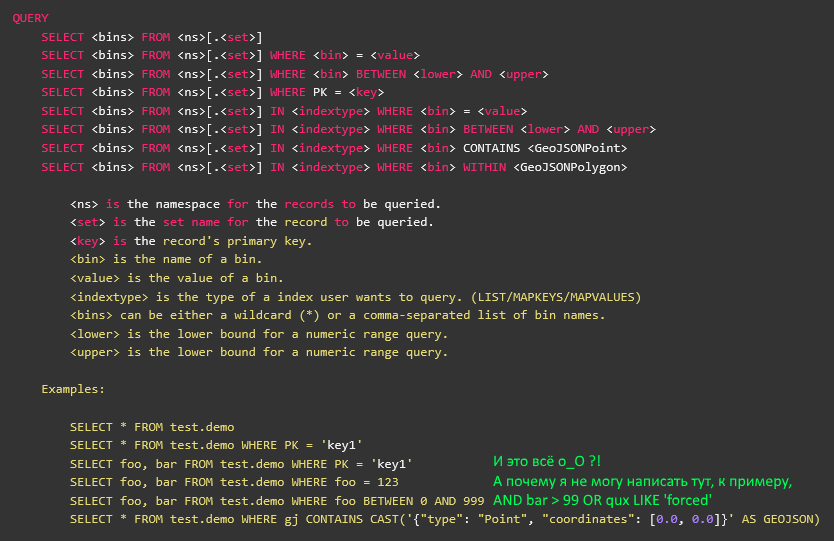
Wait, something is wrong here ... Is the screenshot on the KDPV the official documentation of the aero spike, in which the SELECT is completely described?
Yes, it is described. Here only AQL is the third-party utility written by a back left foot in dark night, and abandoned by a vendor three years ago at the time of the previous version of aero spike. It has no relation to the client library, although it is written on a toad - including.
The three-year-old version did not have a predicate API, and therefore in AQL there is no support for predicates, and all that after WHERE is actually a reference to the index (secondary or primary). Well, I mean, closer to the extension of the SQL type USE or WITH. That is, you cannot just take the AQL source code, disassemble it for parts, and use it in your application for predicate calls.
In addition, as I have already said, it was written on the dark night with the back left foot, and the grammar , which the AQL parses the query with, cannot be looked at without tears on ANTLR4. Well, for my taste. For some reason, I love it when the declarative definition of a grammar is not intermingled with pieces of a toad code, and very steep noodles are brewed there.
Well, fortunately, I also seem to know how in ANTLR. True, he didn’t take the sword for a long time, and the last time he wrote was a third version. Fourth - it is much nicer, because who wants to write a manual bypass of AST, if everything is written to us, and there is a normal visitor, so let's start.
As a base, take the syntax SQLite , and try to throw out all unnecessary. We only need SELECT, and nothing more.
grammar SQLite; simple_select_stmt : ( K_WITH K_RECURSIVE? common_table_expression ( ',' common_table_expression )* )? select_core ( K_ORDER K_BY ordering_term ( ',' ordering_term )* )? ( K_LIMIT expr ( ( K_OFFSET | ',' ) expr )? )? ; select_core : K_SELECT ( K_DISTINCT | K_ALL )? result_column ( ',' result_column )* ( K_FROM ( table_or_subquery ( ',' table_or_subquery )* | join_clause ) )? ( K_WHERE expr )? ( K_GROUP K_BY expr ( ',' expr )* ( K_HAVING expr )? )? | K_VALUES '(' expr ( ',' expr )* ')' ( ',' '(' expr ( ',' expr )* ')' )* ; expr : literal_value | BIND_PARAMETER | ( ( database_name '.' )? table_name '.' )? column_name | unary_operator expr | expr '||' expr | expr ( '*' | '/' | '%' ) expr | expr ( '+' | '-' ) expr | expr ( '<<' | '>>' | '&' | '|' ) expr | expr ( '<' | '<=' | '>' | '>=' ) expr | expr ( '=' | '==' | '!=' | '<>' | K_IS | K_IS K_NOT | K_IN | K_LIKE | K_GLOB | K_MATCH | K_REGEXP ) expr | expr K_AND expr | expr K_OR expr | function_name '(' ( K_DISTINCT? expr ( ',' expr )* | '*' )? ')' | '(' expr ')' | K_CAST '(' expr K_AS type_name ')' | expr K_COLLATE collation_name | expr K_NOT? ( K_LIKE | K_GLOB | K_REGEXP | K_MATCH ) expr ( K_ESCAPE expr )? | expr ( K_ISNULL | K_NOTNULL | K_NOT K_NULL ) | expr K_IS K_NOT? expr | expr K_NOT? K_BETWEEN expr K_AND expr | expr K_NOT? K_IN ( '(' ( select_stmt | expr ( ',' expr )* )? ')' | ( database_name '.' )? table_name ) | ( ( K_NOT )? K_EXISTS )? '(' select_stmt ')' | K_CASE expr? ( K_WHEN expr K_THEN expr )+ ( K_ELSE expr )? K_END | raise_function ; Hmm ... Taki and SELECT alone is a bit too much. And if to get rid of the superfluous is simple enough, then there is another bad thing about the structure of the resulting workaround.
The ultimate goal is to translate into a predicate API with its RPN and implied stack engine. And here atomic expr does not contribute to such a transformation, because it implies the usual analysis from left to right. Yes, and recursively defined.
I mean, we can get our synthetic example, but it will be read exactly as written, from left to right:
(foo>2 (bar<=3 foo>5) quux _ '%force%') (qux _('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}') In the presence of brackets that determine the priority of parsing (which means you will need to dangle back and forth along the stack), as well as some operators behave like function calls.
And we need this sequence:
foo 2 > bar 3 <= foo 5 > quux ".*force.*" _ qux "{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}" _ Brr, tin, poor brain, which is to read. But without the brackets, there is no rollback and misunderstanding with the order of the call. And how do we translate one into another?
And here in the poor brain is chpok! - Hello, this is a classic Shunting Yard from mnogow. prof. Dijkstra! Usually, such okolobigdatovsky shamans, like me, do not need algorithms, because we simply translate prototypes already written from data of Satanists from python to toad, and then long and tediously tyunim performance of the solution obtained by purely engineering (== shamanic) methods, not scientific .
But then suddenly it became necessary and knowledge of the algorithm. Or at least the idea of it. Fortunately, not the entire university course has been forgotten over the past years, and if I remember about stack machines, I can dig up something else about the associated algorithms as well.
Okay. In the grammar, sharpened by Shunting Yard, SELECT at the top level will look like this:
select_stmt : K_SELECT ( STAR | column_name ( COMMA column_name )* ) ( K_FROM from_set )? ( (K_USE | K_WITH) index_expr )? ( K_WHERE where_expr )? ; where_expr : ( atomic_expr | OPEN_PAR | CLOSE_PAR | logic_op )+ ; logic_op : K_NOT | K_AND | K_OR ; atomic_expr : column_name ( equality_op | regex_op ) STRING_LITERAL | ( column_name | meta_name ) ( equality_op | comparison_op ) NUMERIC_LITERAL | column_name map_op iter_expr | column_name list_op iter_expr | column_name geo_op cast_expr ; I mean, the tokens corresponding to the brackets are significant, but there should not be a recursive expr. Instead of it there will be a lot of any private anything_expr, and all are finite.
In the code on the toad, which implements the visitor for this tree, things are a little more addictive - in strict accordance with the algorithm, which itself processes the hanging logic_op and balances the brackets. I will not give an excerpt ( look at the GC yourself), but I will give the following consideration.
It becomes clear why the authors of Aerospay did not bother with the support of predicates in AQL, and abandoned it three years ago. Because it is strongly typed, and the aero spike is presented as a schema-less story. And just like that, it is impossible to simply pick up a request from bare SQL without a predefined schema. Oops.
But we guys are hardened, and, most importantly, arrogant. We need a scheme with field types, so there will be a scheme with field types. Moreover, the client library already has all the necessary definitions, they just need to pick up. Although the code for each type had to be written a lot (see the same link, from line 56).
Now we are initializing ...
final HashMap FOO_BAR_BAZ = new HashMap() {{ put("namespace.set0", new HashMap() {{ put("foo", ParticleType.INTEGER); put("bar", ParticleType.DOUBLE); put("baz", ParticleType.STRING); put("qux", ParticleType.GEOJSON); put("quux", ParticleType.STRING); put("quuux", ParticleType.LIST); put("corge", ParticleType.MAP); put("corge.uier", ParticleType.INTEGER); }}); put("namespace.set1", new HashMap() {{ put("grault", ParticleType.INTEGER); put("garply", ParticleType.STRING); }}); }}; AQLSelectEx selectEx = AQLSelectEx.forSchema(FOO_BAR_BAZ); ... and voila, now our synthetic query is simply and clearly pulled from the aero spike:
Statement statement = selectEx.fromString("SELECT foo,bar,baz,qux,quux FROM namespace.set WITH (baz='a') WHERE (foo>2 AND (bar <=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)"); And to convert the molds from the web muzzle into the request itself, we start a ton of code written long ago in the web muzzle ... when the project finally reaches the project, otherwise the customer has postponed it to the shelf. It's a shame, damn it, I spent almost a week of time.
I hope I spent it with benefit, and the AQLSelectEx library will be needed by someone, and the approach itself will be a little closer to reality with a training tool than other articles from Habr on ANTLR.
')
Source: https://habr.com/ru/post/435902/
All Articles