Adblock Radio Development

tl; dr: Adblock Radio recognizes audio ads using machine learning and Shazam-like techniques. The main open source engine : use it in your products! You can join forces to support more radio stations and podcasts.
Few people like to listen to radio ads. I launched the AdblockRadio.com project so that listeners can skip ads on their favorite Internet radio. The algorithm is published open source , and this article describes how it works.
Adblock Radio has already tested more than 60 radio stations in seven countries on real data. It is also compatible with podcasts and works quite well!
Compared to previous implementations, our algorithm offers a universal approach, processing streams from various sources. From previous implementations, one relies on Internet radio metadata , but only a small portion of the radio is compatible with this method. Another implementation recognizes known jingles , but in many cases the beginning and end of commercial breaks are not marked by a jingle.
')
In addition to the detection of commercials, the proposed algorithm can distinguish conversation from music. Therefore, it also avoids chatter and listens to music only.
This is a report on my personal work for almost three years. I launched Adblock Radio at the end of 2015, a few months after graduating from a graduate school in fusion plasma physics. When Adblock Radio gained some notoriety in 2016, I received threats from lawyers from French radio stations (more details below). I had to partially close the site, change the system architecture, better study the legal implications, etc. Today, I believe that AdBlock Radio will develop much better in the paradigm of open innovation .
This article consists of three parts. They are intended for different audiences. You can scroll down or click on the title to go directly to the desired section.
- Ad detection: proven strategies . For tech-savvy people, scientists, data analysts ... Here are various technical methods that I tried to detect advertisements, including speech recognition, sound prints and machine learning. Thoughts on options for further work.
- It is not recommended to run Adblock Radio in the cloud . For software developers and people interested in copyright. Let's discuss how difficult it is to find a satisfactory compromise between technical and legal constraints when running Adblock Radio in cloud services. For these reasons, it is better to run Adblock Radio only on end-user devices.
- You can integrate Adblock Radio into your player . For manufacturers, product owners, UX designers, techies ... I am considering ideas for integrating an open source algorithm into final products, including car players, and emphasize the need to get feedback from users about incidents of improper operation. It is necessary to maintain the system. Finally, here are tips on how to create the right user interfaces. I expect a lot of feedback on this topic.

Adblock Radio returns the pleasure of listening to the radio
Ad detection: proven strategies
To block an ad, you first need to find it. The goal is to detect an advertisement in an audio stream without any help from the radio station. This is not an easy task. I tried several approaches before getting a good result.
1. Simple ways (do not work)
Volume
The first idea is to check the volume of the sound, because the ads are so loud! For advertising, acoustic compression is often used. This is an interesting criterion, but it is not enough to distinguish advertising. For example, this strategy works quite well for classical music stations, where advertising is usually louder than music. But pop music is as loud as advertising. Moreover, some advertising on purpose can be made silent to avoid detection.
Lock on the clock
Another idea is that advertising is broadcast on a schedule at a specific time. To some extent this is true, but there is no accuracy here. For example, I watched as the morning show on the French station did not start at exactly the same time, with variations of up to two minutes. Radio stations can easily bypass such blocking by randomly shifting their programs by several tens of seconds.
Metadata
The obvious solution is to rely on ICY / Shoutcast metadata , according to which players like VLC display information about the stream. Unfortunately, this data is in most cases broken. It would be possible to take information from a live broadcast on the websites of radio stations (I developed a tool for this ), but more often advertising is not identified as it is. Usually during the advertising on the site displays the name of the previous song or program. One notable exception is Jazz Radio , which during the commercials writes “la musique revient vite ...” (the music will be back soon). In conclusion, it should be noted that this is an unreliable strategy, since radios can very easily change metadata.
Manual marking
In the end, the detection of advertising is possible without any algorithm at all! You can simply ask some listeners to press a button when an advertisement begins and ends. Other listeners will benefit from this. This is the strategy of the TiVo Bolt set-top box. It allows you to delete ads on installed channels at a set time. This gives excellent results, but does not scale to thousands of radio stations.
The disadvantage is that it is difficult to start the system from scratch. At the new station, there may not be enough audience to work properly. The first listeners will be upset and leave, so the station will never gather a large enough audience.
Another difficulty is that radio stations will want to send fake signals to sabotage the system. It requires a moderation mechanism, a consensus system, or a voting threshold.
Crowdsourcing is a good idea. I think it looks even better if the algorithm does most of the work, leaving a minimum for people. This is what I did.
2. Speech recognition and analysis of the lexical field (failure)
Advertising is always the same subject and lexical field: buying a car, getting supermarket coupons, subscribing to insurance, etc. If you recognize a speech, you can use standard tools to combat spam . This was my first research path at the end of 2015, but I was unable to implement speech recognition.
Being a newcomer to speech processing, I began by reading Huang's The Oral Processing , an excellent book, although a bit dated. I put my dirty little hands on CMU Sphinx , the best free speech recognition engine at the time.
The first attempt gave very poor results and required intensive computations on the CPU. I used the default parameters: a standard French dictionary (a list of possible words and corresponding phonemes), a language model (probabilities of word sequences), and an acoustic model (connection of phonemes with a sound waveform).
Attempts to improve the system were in vain: recognition still worked poorly. I set up a dictionary and language model on a small data set, sharing the sound with a diarization tool . Also adapted the MLLR acoustic model to the Europe 1 (French) radio station, where he trained the system.
In general, the idea of speech recognition had to be abandoned. This is probably for experts. However, in the future you can return to it. Since 2015, significant progress has been made in speech recognition. New open source tools such as Mozilla Deep Speech have been published.
3. Crowdsourcing advertising base, the detection of sound prints (encouraging)
The first version of Adblock Radio in 2016 worked with a base of commercials. The system continuously listened to the sound stream in search of advertising. The results were really promising, but it turned out to be difficult to keep such a database up to date.
The audio fingerprint search technique is similar to what Shazam does on its song recognition servers . This type of algorithm is commonly known as a landmark . I adapted it for streaming and opened the source code .
Fingerprinting is suitable for the detection of commercials, because they are repeatedly broadcast in the same form. For the same reason, he recognizes music. But this technique will not work on speech, because people never utter words the same way. This is only possible with a re-broadcast of programs at night that does not interest us. Thus, in the database of prints you need to make and advertising, and music (as "not advertising"), but it makes no sense to process speech.
In essence, sound prints are the conversion of some sound characteristics into a series of numbers called fingerprints. If many prints live on the air coincide with the base, it can be concluded that the advertisement is being broadcast. For optimal resolution, the time and frequency ranges need some adjustment. Different samples should vary well. However, the system should work even with a slight change in the sound compression algorithms, or if the radio station has changed the equalizer settings. Finally, you should limit the number of prints so as not to load computing resources.
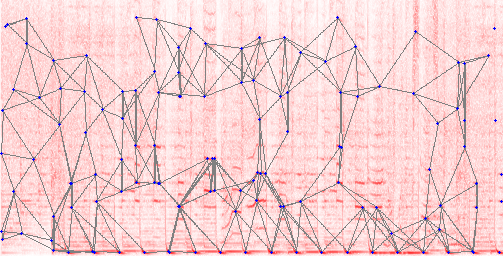
An example of the calculation of sound prints. Red background - spectrogram. It reflects the change in sound intensity in frequency (low frequencies below). On this map, spectral peaks are identified (blue dots) and connected (gray lines). The position, length and orientation of each gray line is converted to a unique number, imprint
Binary classification gives the result: is the sample advertising or not. If we analyze the cases of errors, the system almost always gave a false negative result, that is, it missed advertising, and very rarely marked good content as advertising. Users can report undetected ads with one click, providing a great user interface. The corresponding sound is automatically added to the database. I moderated these actions a posteriori.
It was difficult to keep the database up to date, as commercials change frequently, and ads are broadcast with minor variations. They are also updated frequently, in some cases every few days. Some streams with an insufficient number of listeners were very poorly recognized.
I researched interesting strategies for partial automation of the work of students. Ads are broadcast the same way many times every day. This can be used to identify them. Records were searched for the most repetitive sequences (MRS). Other content is also repeated, for example, songs and jingles (screensavers). I sorted all sequences by length and took samples with a length of about 30 seconds, typical of commercials. Thus, it was often possible to catch advertising. But sometimes there were choruses of songs or even recorded weather forecasts.
I found a way to filter out most of the music replays: I analyzed the station's playlists, downloaded the songs, and integrated them into the database with the label “not advertising.” Therefore, more and more candidates for MRS turned out to be real commercials. But still not everything, so user assistance remained necessary.
It took less manual work, but the load on the servers has already become a problem. Looking back, the choice of SQLite for these resource-intensive, time-critical database operations turned out to be far from the best.
Fortunately, the algorithm had a few seconds to determine whether the sound is advertising or not. This is because Internet radio uses an audio buffer, typically 4-30 seconds, which is not immediately played on the end-user device. This helps prevent interruptions in the event of a temporary network loss.
I used this buffer latency for post-processing to make the predictions of the algorithm more stable and context-sensitive. Immediately before playing the sound on the end-user device, the algorithm looks at the results of the predictions that are still in the buffer, as well as the older ones that have already been played. It cuts out questionable data points with multiple fingerprints, showing a hysteresis . It also takes into account the weighted average time to smooth out possible failures.

Adblock Radio at a certain stage in 2016. Highlighting the red radio stations, where advertising is currently sounding, looked really great! Users could mark missed ads with a blue button. The music-in-a-cloud button at the top allows you to export a custom MP3 stream with advertising removed from it and, if such a function is configured, with smooth transitions between radio stations. The following are additional buttons and features.
4. Classification of advertising, conversations and music in machine learning (almost ready!)
The next version of the algorithm analyzes the acoustics: from low to high sounds and their change over time. New unknown commercials are detected almost as well as the old ones, where the training took place, only on the basis of noisy and intrusive signs. This is a more sophisticated method of analyzing the volume of a sound (see previous discussion).
For this, I used machine learning tools, namely the Keras library, connected to Tensorflow . This gave very good results with low CPU utilization. This version has been in production for over a year, from the beginning of 2017 to the middle of 2018. Now it’s realistic to distinguish between talk and music, so the classification has become more accurate: instead of “advertising / not advertising” - “advertising / conversation / music”.
We study the details. The sound is converted to a 2D map, where the sound intensity is presented as a function of frequency and time (on a scale of about four seconds). This card is conceptually similar to the red card in the chapter on prints. The main difference is that instead of the classical Fourier spectrum, I used Mel-cepstral coefficients that are relevant in the context of speech recognition.
Sequential cards with different time stamps were then analyzed as pictures in a recurrent neural network like LSTM (long short-term memory). Each card was analyzed independently of the other (RNN stateless ), but the cards overlapped each other. The cards were 4 seconds long and a new one appeared every second. The end result for each card was a softmax vector, for example,
ad: 72%, talk: 11%, music 17% . These forecasts were then processed by the same method as described in the section on prints.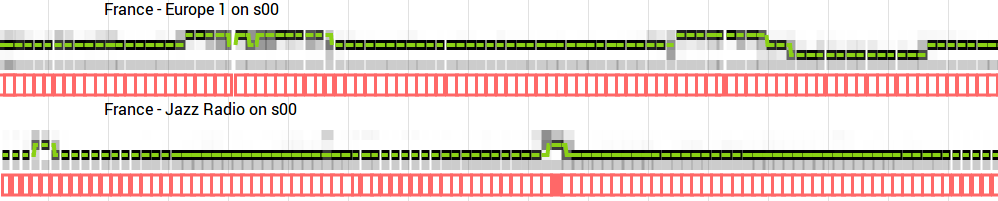
Preview typical machine learning results for two radio stations. The horizontal axis represents about 17 minutes of time. The green line moves between three positions: advertising at the top, conversation in the middle and music at the bottom (the closest to the uniform gray background). Red areas - intervals of listening to the sound by the user. If the algorithm gives an incorrect prediction, the user can correct it.
Initially, I trained the neural network on a very small data set. I developed a UI (see figure above) to visualize forecasts and could add more data to train models with better performance. At the time of this writing, the training dataset contains about ten days of audio: 66 hours of advertising, 96 hours of conversations and 73 hours of music.
Despite the good work, the classification accuracy still turned out to be slightly lower than the users' expectations (see the section below on future improvements). When training, the accuracy of the forecast category was 95%, but the remaining incorrect classifications left users dissatisfied.
Note to data processing professionals: it is common practice to present formal results by breaking the data set into subsets of training and testing. I think that here it does not make sense, because the data set is gradually built on the data, where previous models were wrong. This means that the data set contains more pathologies than the average broadcast, and accuracy will be underestimated. Separate work on measuring real indicators will be required. The operator can mark continuous segments of regular audio recordings as test data, then calculate the accuracy and recall on them. Such regular testing will allow you to monitor the performance of filters.
The categorization of advertisements / conversations / music added convenience to listeners. However, this classification has complicated the user interface, and it has become more difficult to work with user reports. If the flag indicates that some content is not music, is it an advertisement or conversation? It requires immediate moderation, not after the fact.
To further improve quality, I developed the latest version of Adblock Radio, which slightly improves this strategy.
5. The combination of sound classification and matching prints (success!)
My best algorithm is published on Github . To improve reliability, it combines the concepts of the two previous attempts: acoustic classification and the base of prints.
A properly trained machine learning predictor provides the correct classification of most of the source materials, but does not work in some situations (see below in the section on future improvements). The role of the fingerprint matching module is to reduce the errors of the machine learning module.
Not all known training data are entered into the database of prints, but only a small subset where machine learning demonstrates errors. I call it the “hotlist database” (hotlist database). The small size helps to reduce the overall error rate while keeping the CPU load low.
On an ordinary laptop, the algorithm consumes only 5-10% of CPU on files and 10-20% on live broadcast.
Future improvements
Some content is still problematic.
The detector works imperfectly on some specific types of audio content:
- hip-hop music is often recognized as an advertisement. You can get around the problem by adding tracks to the hotlist, but this is too much music. A more general neural network could be developed, possibly at the expense of performance.
- Music album ads are often recognized as music. But blocking through fingerprints will lead to false positives when the real song is broadcast. The problem can be solved by a deeper analysis of the context, but it is difficult on the air, where the context is known only for a few seconds ahead.
- Talk show advertising is often recognized as a conversation. There are blurred boundaries, because it is both a conversation and an advertisement. We see the limit of the classifier advertising / conversation / music. For classification by prints, for some time I used the ad_self class, which contains advertisements for talk shows at specific stations, but with the implementation of the machine learning algorithm I stopped doing this. It may be wise to recreate this class. Another option is a better context analysis.
- native advertising, where the presenter reads the sponsor's text. On the radio, this is rare, and more often in podcasts. The logical next step for blocking such advertising is the introduction of speech recognition software.
Markov chains for more stable post processing
Postprocessing stability can be improved. Currently only confidential thresholds are used. When the threshold value is reached, the last confident forecast is taken. Thus, the system sometimes saves the error.
The cycles of advertising, conversations and music are quite cyclical on every broadcast. For example, advertising usually lasts a few minutes. For each period of time in the commercial break, you can calculate the probability of transition to another state (conversation or music). This probability will help to better interpret the noisy predictions of the algorithm: is it just a short segment of the music in the announcement or is the commercial break completed? Here, hidden Markov models will be a good line of research.
Analog radio is not yet supported.
Analog signals (FM) have not been tested and are not currently supported. Analog noise cancels the methods used here. Filters and / or noise-proof fingerprint recognition algorithms may be required. If this happens, the program is able to find wider use among users. However, the radio is increasingly moving to digital technology without noise, such as DAB and Internet radio.
Do not run Adblock Radio in the cloud
Ideally, Adblock Radio should only be run on end devices. But now cloud services are in fashion. Moreover, it is a great business idea! Adblock Radio tested two versions of the architecture with this paradigm. However, experience shows that this is not the best option for technical and legal reasons.
Option 1. Relay from the server
The server can relay audio content with ad / talk / music tags to listeners. We tested it in 2016. There are legal problems here, since stream relaying can be considered as fake and / or copyright infringement (although I am not a lawyer). It also doesn’t scale well because you are now a CDN and have to incur costs.
For the sake of a joke, on Sunday, when I was absent for family reasons, Adblock Radio got wildly popular, from which it fell . Funny fact: a few days later France Inter , a large French public radio station, advertised Adblock Radio in prime time (though not naming it). This is an unexpected decision by the editorial board in the context of the fact that regulators decided in 2016 to relax restrictions on advertising on public radio stations , which aggravated the discord between Radio France employees and management .
A few weeks later, I received threats from a lawyer at the French private radio network Les Indés Radio , allegedly on the basis of copyright and trademark infringement. Not having financial resources for serious protection, I had to remove some streams from the site, partially close the site and change the system architecture. At the same time, this radio network refused to cooperate in the search for a compromise. Since I see in the logs that they continued to monitor my site (sometimes with pseudonymous accounts), they also consulted with their lawyers . What an honor for me! In retrospect, they successfully won time, but no more. Hi guys from Indés! Hope you enjoy reading this! xoxoxo .

A declaration of love from Les Indés, a network of 131 French radio stations
Option 2. The server relays the sound, but privately.
Here it is supposed to analyze on the server and retransmit the cleared sound for a specific user. Such a system may be subject to an exception to copyright law as its own private copy of the media. If the server is managed by the end user and the source is legal and officially available in your area, everything is probably legally clean. For more information, see the discussions of Station Ripper [FR] and VCast [FR] . But users are rarely technically savvy to self-rent and install a server.
It is very tempting to put a server under the control of a third party, but this leads to legal problems, because then the operator making the copy and the end user are not the same person. In this case, legal restrictions are imposed, at least in France. The French Internet service Wizzgo [FR] ran into this rule in 2008. More recently, in the US, the Aereo television service was closed, although it took precautions to distribute a separate tuner to each client (!).
At the moment, the service Molotov.TV [FR] is fighting with the right holders who want to limit its functions [FR] , despite the significant influence of its co-founders. You must pay to the official organization a tax on a private copy of [FR] . The amount is determined by rather opaque calculations [FR] and increases [FR] every year, reaching several dozen eurocents per user per month. This board has become so high that Molotov.TV recently removed the functions of its service for free users [FR] . (Note: I sincerely thank the journalists of the French site NextINpact for very good coverage of this topic).
Paying is not enough: the law requires entities like Molotov.TV to sign [FR] agreements with copyright companies on the functionality of their service. Try to reach an agreement with radio companies if you start cutting their ads.
Option 3. The server sends only metadata.
Another option is for the user and the server to simultaneously listen to the same Internet radio. At the same time, the server analyzes the sound and sends classification metadata (ad / talk / music) to the user, but not audio content. Since 2017, adblockradio.com has been working on such an architecture. It relies on CDN, so it does not incur any costs in terms of audio broadcast.
This architecture removes the problem of copyright infringement (disclaimer: I am not a lawyer). However, there may still be some ambiguity regarding trademark laws. Recently (October 2018), Skyrock radio owners demanded that content be removed on this basis.

Romantic message from the Skyrock legal department
In addition to legal considerations, there is a technical problem of correct synchronization between sound and metadata. In most cases, everything works fine with a synchronization interval of less than two seconds. But some radio stations have strange / malicious CDNs or they dynamically insert ads into the stream. This means that the flow between the server and different clients may differ significantly. For example, on Radio FG , lags for up to 20 seconds were observed, and for Jazz Radio - up to 45 seconds. It disappoints the listeners.
Synchronization can be rigidly implemented by comparing data blocks between a server and a user. Unfortunately, this does not work in web browsers, because most CDNs on Internet radio stations do not use CORS headers . Therefore, JavaScript in the browser will not be able to read the audio content for comparison. You will need separate stand-alone modules (for example, Electron ), Flash (aha) modules or web extensions, which seems a bit redundant.
You can integrate Adblock Radio into your player.
This project is not for end users, but for companies that produce a mass product. You can do this!
Developers have two options for integrating Adblock Radio. First, the SDK just takes the metadata from the adblockradio.com server. This is not an ideal solution for the reasons described above (legal and timing issues). It is better to run the full analysis algorithm .
Software
- Mobile applications for Internet radio and podcasts. Keras models need to be converted to native Tensorflow, and Keras + Tensorflow can be replaced with Tensorflow Lite for Android and iOS . Node.JS routines are implemented using the React Native plugin or in case of emergency with Termux .
- browser extensions work with Tensorflow JS and SQL.js. The extension can control the volume slider in popular Internet radio directories such as TuneIn or Radio.de . I have already worked on this extension. It was fun to tinker with JavaScript players to get this control. Depending on your implementation, keep in mind the timing issues we discussed above.
Hardware
- digital alarm clocks and amateur projects, subject to the availability of sufficient computing power and access to the network. Platforms like Raspberry Pi Zero / A / B should be sufficient for analyzing a single stream, although RPi 3B / 3B + is recommended for parallel management of multiple threads. Tensorflow is on Raspbian .
- connected speakers like Sonos . The algorithm itself will not work on such equipment, so you need to process data either in the cloud or on a separate device on the same local network (for example, on Raspberry). Great idea for a crowdfunding campaign.
Adblock Radio in the car
The car is one of the most popular places to listen to the radio. There, people really need an ad blocker. But this is the context where implementing Adblock Radio is not easy. After all, the system should receive feedback in order to effectively filter new advertisements, so the program needs a network connection. I see three possible concepts for automotive products with Adblock Radio.
- Application compatible with the infotainment systems of modern cars . Probably the easiest way to transfer data is through the user's smartphone. The smartphone can also be used separately - with a mobile application, streaming Internet radio, via audio output, connecting to the car's AUX or Bluetooth. It can also be integrated with the car's infotainment system, in the spirit of Apple Car Play , Android Auto and MirrorLink . It would be fantastic to listen to terrestrial radio (FM, DAB). But work is needed to determine in which configurations Adblock Radio can access the audio output of the radio tuner and, at the same time, control it (volume, channel).
- Universal hardware adapter, dedicated user interface . It is also possible to develop non-standard equipment, similar to existing DAB-adapters for cars . These devices are tuned to radio stations and transmit audio data to the car system via the AUX connector or via an unused FM channel, like old iPod FM adapters . Access to the network can be via a smartphone via a Bluetooth connection. Alternative solutions could be considered, such as Sigfox and LoRa , if the bitrate and price are appropriate. A special user interface should be developed, separately from the main car device. In the end, this may be too expensive solution.
- The minimalist device that hacks FM-receiver . Such a small device can, if necessary, manage the tuner. We need a standard, but easy to connect interface. Steering wheel switches are a good candidate, but end users cannot easily modify them for this purpose. So you need to hack the system.
This headless device will have an FM tuner and a microphone for analyzing which station the user is listening to (cross-correlation). When an advertisement is detected, the device emits fake RDS data (for example, traffic announcements ) to trick the car's tuner and change the station for the duration of the advertisement. FM-.
, . , . , , . , , DAB.
, . , .
Adblock Radio , , . , .
: () , . .
. , , adblockradio.com. , -. . , , , .
: UX
: . , . !
adblockradio.com :
- . , . .
- . .
, - . , , . .

- Adblock Radio

, . . , . . ! ,
. adblockradio.com , . ( Github ), . 10 ( , , 7.30 7.20). — . . , .
, . , ? , ( ) .

. . , , — . (ads),
— . , , . . -, «» , : , , , . . , - .
Conclusion
, . . , , , WiFi-. (FM, DAB+). , , .
Adblock Radio.
! , .
Source: https://habr.com/ru/post/435720/
All Articles