Tornado vs Aiohttp: a journey into the wilds of asynchronous frameworks
Hello! I am Dima, and I have been sitting on Python for quite a long time. Today I want to show you the differences between two asynchronous frameworks - Tornado and Aiohttp. I'll tell you the story of the choice between frameworks in our project, the difference between Tortado and Tornado and AsyncIO, show benchmarks and give some useful tips on how to get into the wilds of frameworks and successfully get out.

As you know, Avito is a fairly large ad service. We have a lot of data and workload, 35 million users every month and 45 million active ads daily. I work as a technical recommendation team. My team writes microservices, now we have about twenty of them. All this is filled with the top load - like 5k RPS.
First, I will tell you how we got to where we are now. In 2015, we had to choose an asynchronous framework, because we knew:
')
Thus, we have a lot of network tasks, and the application is mainly busy with I / O. The actual version of python at that time - 3.4, async and await did not yet appear. Aiohttp was also in version 0.x. Asynchronous Tornado from Facebook appeared in 2010. For him, written a lot of drivers to the databases that we need. On the benchmarks Tornado showed stable results. Then we stopped our choice on this framework.
Three years later we understood a lot.
First, there was Python 3.5 with async / await mechanics. We figured out what is the difference between yield and yield from and how Tornado fits in with await (spoiler: not very good).
Secondly, we are faced with strange performance problems when there is a large amount of coruntine in the scheduler, even when the CPU is not fully occupied.
Thirdly, we found that when performing a large number of http requests to other Tornado services, it is necessary to be friendly with the asynchronous dns resolver, it does not respect the timeouts for establishing a connection and sending a request, which we specify. And in general, the best way to do http requests in Tornado is curl, which is rather strange in itself.
In his report on PyCon Russia 2018, Andrey Svetlov said: “If you want to write some kind of asynchronous web application, please just write async, await. Event loop, probably, you will not need any soon. Do not climb into the wilds of frameworks, so as not to get confused. Do not use low-level primitives, and everything will be fine with you ... ". Over the past three years, we, unfortunately, had to quite often get into the inside of the Tornado, learn from there a lot of interesting things and see giant trainings for 30-40 calls.
One of the biggest problems to understand in an asynchronous python is the difference between yield from and yield.
Guido Van Rossum wrote more about this. I enclose a translation with small cuts.
The two old and new school korutin have only one minor difference - get yield from iter vs get awaitable.
What is this all about? Tornado uses simple yield. Prior to version 5, it connects all of this call chain through yield, which is poorly compatible with the new cool yield from / await paradigm.
It is difficult to find a really good framework, choosing it only according to the synthetic tests. In real life, a lot of things can go wrong.
I took Aiohttp version 3.4.4, Tornado 5.1.1, uvloop 0.11, took the server processor Intel Xeon, CPU E5 v4, 3.6 GHz, and with Python 3.6.5 I started checking the web servers for competitiveness.
A typical problem that we solve with the help of microservices, and which works on asynchronous, looks like this. We will receive requests. For each of them we will do one request to some microservice, receive data from there, then go to another two or three microservice, also asynchronously, then write the data somewhere to the database and return the result. It turns out many moments where we will wait.
We perform a simpler operation. Turn on the server, make him sleep 50 ms. Create a corutin and complete it. We will not have a very large RPS (it may not coincide by an order of magnitude with what is seen in fully synthetic benchmarks) with an acceptable delay due to the fact that a lot of coroutines will simultaneously rotate in a competitive server.
Load - GET http requests. Duration - 300s, 1s - warmup, 5 repetitions of the load.

Results on service response time percentiles.
We see that Aiohttp on such a simple test did a great job on 1000 RPS. All while without uvloop .
Compare Tornado with the old and new async schools. Authors are strongly advised to use async. We can make sure that they are really much faster.
At 1200 RPS, the Tornado, even with the new school korutinami, is already beginning to give up, and the Tornado with the old school korutinami has completely blown away. If we sleep 50 ms, and microservice is responsible for 80 ms, it does not go into any gate at all.
The new Tornado school for the 1500 RPS completely surrendered, and Aiohttp is still far from the 3000 RPS limit. The most interesting is yet to come.
Let's see what is happening at this moment with the processor.

When we figured out how asynchronous Python microservices work in production, they tried to understand what was going on. In most cases, the problem was with the CPU or with descriptors. There is a great profiling tool created in Uber, the Pyflame profiler, which is based on the ptrace system call.
We start some service in the container and start throwing a combat load on it. Often, this is not a very trivial task - to create just such a load that is in combat, because it often happens that you run synthetic tests on load testing, you look, and everything works fine. You are pushing a combat load onto it, and now microservice starts to blunt.
During operation, this profiler does snapshots of the call stack for us. You can not change the service at all, just run pyflame next to it. It will collect the stack trace once in a while, and then does a cool visualization. This profiler gives very little overhead, especially when compared with cProfile. Pyflame also supports multithreaded programs. We ran this thing right in the market, and the performance was not degraded.
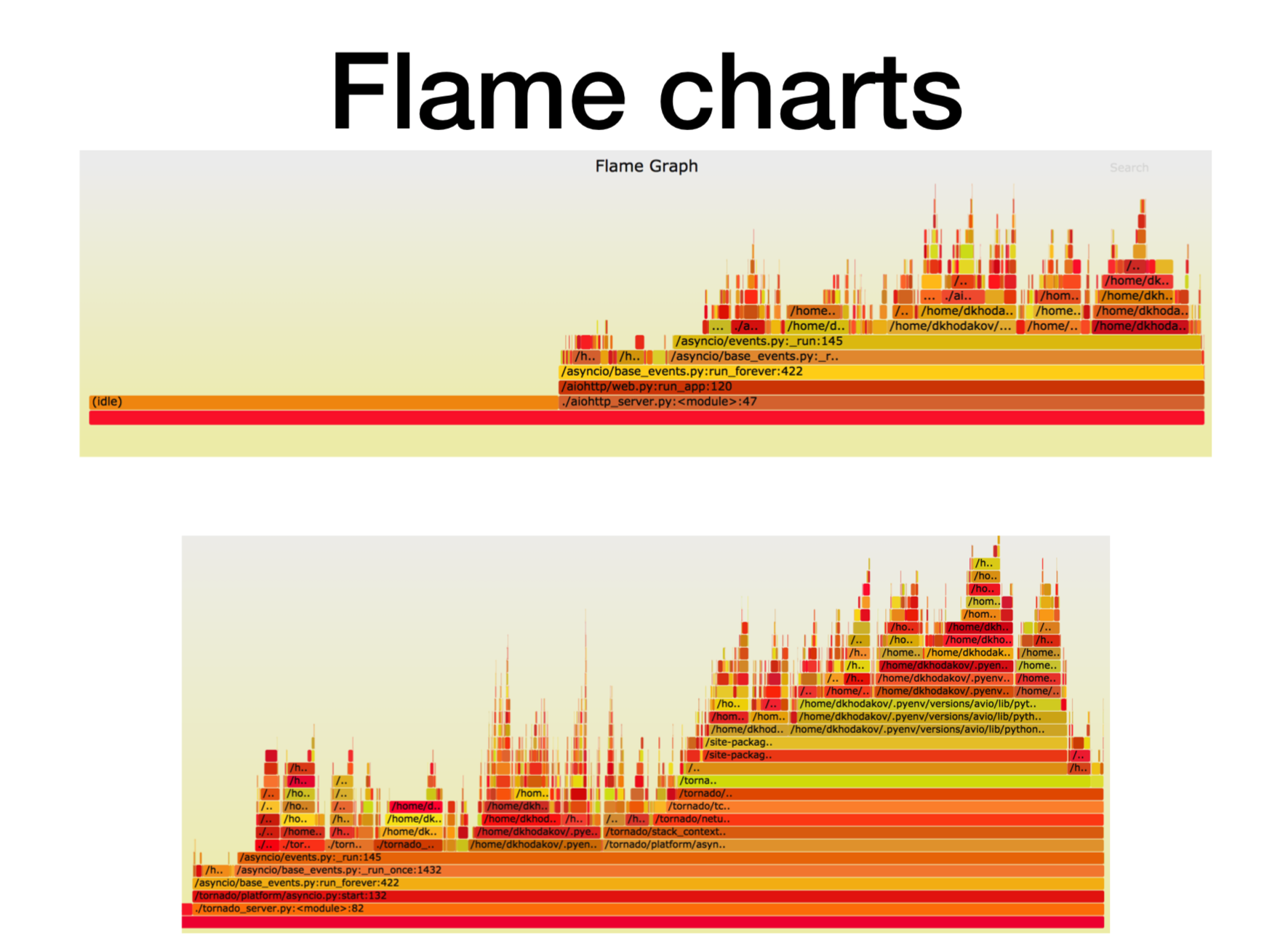
Here on the X axis is the amount of time, the number of calls when the stack frame was in the list of all the stack of Python frames. This is the approximate amount of CPU time that we spent in this particular stack frame.
As you can see, most of the time in aiohttp is spent on idle. Great: this is what we want from an asynchronous service, so that it will deal with network calls most of the time. In this case, the stack depth is about 15 frames.
In Tornado (the second picture) with the same load, much less time is spent on idle and the stack depth in this case is about 30 frames.
Here is a link to svg , you can twist it yourself.
You should expect a runtime of 125 ms.

Tornado with uvloop holds up better. But Aiohttp uvloop helps much more. Aiohttp 2300-2400 RPS, uvloop . , .
, .
( ) Aiohttp c Tornado Python .
. , . Thank you all for your attention. , .
As you know, Avito is a fairly large ad service. We have a lot of data and workload, 35 million users every month and 45 million active ads daily. I work as a technical recommendation team. My team writes microservices, now we have about twenty of them. All this is filled with the top load - like 5k RPS.
Choosing an asynchronous framework
First, I will tell you how we got to where we are now. In 2015, we had to choose an asynchronous framework, because we knew:
')
- that you have to make many requests to other microservices: http, json, rpc;
- that it will be necessary to collect data all the time from different sources: Redis, Postgres, MongoDB.
Thus, we have a lot of network tasks, and the application is mainly busy with I / O. The actual version of python at that time - 3.4, async and await did not yet appear. Aiohttp was also in version 0.x. Asynchronous Tornado from Facebook appeared in 2010. For him, written a lot of drivers to the databases that we need. On the benchmarks Tornado showed stable results. Then we stopped our choice on this framework.
Three years later we understood a lot.
First, there was Python 3.5 with async / await mechanics. We figured out what is the difference between yield and yield from and how Tornado fits in with await (spoiler: not very good).
Secondly, we are faced with strange performance problems when there is a large amount of coruntine in the scheduler, even when the CPU is not fully occupied.
Thirdly, we found that when performing a large number of http requests to other Tornado services, it is necessary to be friendly with the asynchronous dns resolver, it does not respect the timeouts for establishing a connection and sending a request, which we specify. And in general, the best way to do http requests in Tornado is curl, which is rather strange in itself.
In his report on PyCon Russia 2018, Andrey Svetlov said: “If you want to write some kind of asynchronous web application, please just write async, await. Event loop, probably, you will not need any soon. Do not climb into the wilds of frameworks, so as not to get confused. Do not use low-level primitives, and everything will be fine with you ... ". Over the past three years, we, unfortunately, had to quite often get into the inside of the Tornado, learn from there a lot of interesting things and see giant trainings for 30-40 calls.
Yield vs yield from
One of the biggest problems to understand in an asynchronous python is the difference between yield from and yield.
Guido Van Rossum wrote more about this. I enclose a translation with small cuts.
I was asked several times why PEP 3156 insists on using yield-from instead of yield, which eliminates the possibility of backporting in Python 3.2 or even 2.7.It turns out that yield from is almost the same as await.
(...)
whenever you want a future result, you use yield.
This is implemented as follows. The function containing yield is (obviously) a generator, so there must be some iteration code. Let's call it a scheduler. In fact, the scheduler does not “iterate” in the classical sense (with for-loop); instead, it maintains two collections of the future.
I will call the first collection an “executable” sequence. These are the future whose results are available. While this list is not empty, the scheduler selects one item and takes one iteration step. This step calls the generator method .send () with the result from the future (which may be data that has just been read from the socket); in the generator, this result appears as the return value of the yield expression. When send () returns a result or completes, the scheduler analyzes the result (which can be StopIteration, another exception, or some object).
(If you're confused, you probably should read about how generators work, in particular, the .send () method. Perhaps PEP 342 is a good starting point).
(...)
The second collection of the future, supported by the scheduler, consists of the future, which are still awaiting I / O. They are somehow transmitted to the select / poll / etc shell. which gives a callback when the file descriptor is ready for I / O. The callback actually performs the I / O operation requested by the future, sets the resulting future value to the result of the I / O operation, and moves the future to the execution queue.
(...)
Now we have reached the most interesting. Suppose you are writing a complex protocol. Inside your protocol, you read the bytes from the socket using the recv () method. These bytes fall into the buffer. The recv () method is wrapped in an async shell, which sets up I / O and returns the future, which is executed when I / O completes, as I explained above. Now suppose that some other part of your code wants to read data from the buffer one line at a time. Suppose you used the readline () method. If the buffer size is larger than the average length of the line, your readline () method can simply get the next line from the buffer without blocking; but sometimes the buffer does not contain the whole line, and readline () in turn calls recv () on the socket.
Question: should readline () return the future or not? It would not be very good if it sometimes returned a byte string, and sometimes future, forcing the caller to perform type checking and conditional yield. Therefore, the answer is that readline () should always return future. When readline () is called, it checks the buffer, and if it finds at least a whole line there, it creates the future, sets the result to the future line taken from the buffer, and returns the future. If the buffer does not have a whole line, it initiates I / O and waits for it, and when I / O is completed, it starts again.
(...)
But now we are creating many future that do not require blocking I / O, but still force the call to the scheduler - because readline () returns the future, the caller is required to yield, and that means calling the scheduler.
The scheduler can transfer control directly to the coruntine if he sees that a future that is already completed is displayed, or can return the future to the execution queue. The latter will slow down the work greatly (provided that there is more than one executable coroutine), since not only waiting at the end of the queue is required, but the locality of the memory (if it exists at all) is also likely to be lost.
(...)
The net effect of all this is that the authors of coroutines need to know about the yield future, and therefore there is a greater psychological barrier to reorganizing complex code into more readable corutins — much stronger than the existing resistance, because the function calls in Python are rather slow. And I remember from a conversation with Glyph that speed is important in a typical asynchronous I / O structure.
Now let's compare this to yield-from.
(...)
You may have heard that “yield from S” is roughly equivalent to “for i in S: yield i”. In the simplest case, this is true, but for understanding korutin this is not enough. Consider the following (don't think about async I / O yet):def driver(g): print(next(g)) g.send(42) def gen1(): val = yield 'okay' print(val) driver(gen1())
This code will print two lines containing "okay" and "42" (and then will give an unprocessed StopIteration, which you can suppress by adding yield at the end of gen1). You can see this code in action at pythontutor.com via the link .
Now consider the following:def gen2(): yield from gen1() driver(gen2())
It works the same way . Now think. How it works? Here, a simple yield-from extension in for-loop cannot be used, since in this case the code would give out None. (Try) . Yield-from acts as a “transparent channel” between driver and gen1. That is, when gen1 gives the value “okay”, it leaves gen2, through yield-from, to the driver, and when the driver sends the value 42 back to gen2, this value is returned back through yield-from to gen1 again (where it becomes the result of yield ).
The same thing would happen if the driver gave an error to the generator: the error passes through the yield-from to the internal generator that processes it. For example:def throwing_driver(g): print(next(g)) g.throw(RuntimeError('booh')) def gen1(): try: val = yield 'okay' except RuntimeError as exc: print(exc) else: print(val) yield throwing_driver(gen1())
The code will issue "okay" and "bah", as well as the following code:def gen2(): yield from gen1() # unchanged throwing_driver(gen2())
(See here: goo.gl/8tnjk )
Now I would like to introduce simple (ASCII) graphics to be able to talk about this kind of code. I use [f1 -> f2 -> ... -> fN) to represent the stack with f1 at the bottom (oldest call frame) and fN at the top (newest call frame), where each item in the list is a generator, and -> yield-from . The first example, driver (gen1 ()), does not have a yield-from, but has a gen1 generator, so it looks like this:[ gen1 )
In the second example, gen2 calls gen1 using yield-from, so it looks like this:[ gen2 -> gen1 )
I use the mathematical designation of the half-open interval [...) to show that another frame can be added to the right when the right-most generator uses yield-from to call another generator, while the left ending is more or less fixed. The left ending is what the driver sees (i.e., the scheduler).
Now I'm ready to go back to the readline () example. We can rewrite readline () as a generator that calls read (), another generator, using yield-from; the latter in turn calls recv (), which performs the actual I / O from the socket. On the left we have an application that we also view as a generator that calls readline (), again using yield-from. The scheme is as follows:[ app -> readline -> read -> recv )
Now the recv () generator sets the I / O, binds it to the future and sends it to the scheduler using * yield * (not yield-from!). The future passes to the left along both arrows from the yield-from planner (located to the left of the "["). Note that the scheduler does not know that it contains a stack of generators; all he knows is that he contains the leftmost generator and that he has just issued a future. When I / O is complete, the scheduler sets the result to the future and sends it back to the generator; the result moves to the right along both yiled-from arrows to the recv generator, which receives the bytes that it wanted to read from the socket as a result of the yield.
In other words, the yield-from-based framework scheduler handles I / O operations just like the yield-based framework scheduler I described earlier. * But: * it does not need to worry about optimization when the future is already completed, since the scheduler does not participate at all in the transfer of control between readline () and read () or between read () and recv (), and back. Therefore, the scheduler is not involved at all when app () calls readline (), and readline () can satisfy the request from the buffer (without calling read ()) - the interaction between app () and readline () is completely processed by the byte-code interpreter in this case. Python. The scheduler can be simpler, and the number of futures created and managed by the scheduler is smaller, because there are no futures that are created and destroyed with each call to the coroutine. The only futures that are still needed are those that are actual I / O, for example, created recv ().
If you have read this far, you deserve a reward. I have omitted many details of the implementation, but the above illustration essentially reflects the picture.
One more thing I would like to point out. * You can * make part of the code use yield-from and the other part yield. But yield requires that every link in the chain have a future, and not just a quortin. Since there are several advantages to using yield-from, I want the user not to remember when to use yield, and when yield-from, it’s easier to always use yield-from. A simple solution even allows recv () to use yield-from to transfer future I / O to the scheduler: the __iter__ method is actually a generator that issues a future.
(...)
And something else. What value does yield-from return? It turns out that this is the return value * of the external * generator.
(...)
Thus, although the arrows link the left and right frames to * yielding *, they also transfer the usual return values in the usual way, one stack frame at a time. Exceptions are moved in the same way; Of course, every level requires try / except to catch them.
yield from vs async
def coro () ^ y = yield from a | async def async_coro (): y = await a |
| 0 load_global | 0 load_global |
| 2 get_yield_from_iter | 2 get_awaitable |
| 4 load_const | 4 load_const |
| 6 yield_from | 6 yield_from |
| 8 store_fast | 8 store_fast |
| 10 load_const | 10 load_const |
| 12 return_value | 12 return_value |
The two old and new school korutin have only one minor difference - get yield from iter vs get awaitable.
What is this all about? Tornado uses simple yield. Prior to version 5, it connects all of this call chain through yield, which is poorly compatible with the new cool yield from / await paradigm.
The simplest asynchronous benchmark
It is difficult to find a really good framework, choosing it only according to the synthetic tests. In real life, a lot of things can go wrong.
I took Aiohttp version 3.4.4, Tornado 5.1.1, uvloop 0.11, took the server processor Intel Xeon, CPU E5 v4, 3.6 GHz, and with Python 3.6.5 I started checking the web servers for competitiveness.
A typical problem that we solve with the help of microservices, and which works on asynchronous, looks like this. We will receive requests. For each of them we will do one request to some microservice, receive data from there, then go to another two or three microservice, also asynchronously, then write the data somewhere to the database and return the result. It turns out many moments where we will wait.
We perform a simpler operation. Turn on the server, make him sleep 50 ms. Create a corutin and complete it. We will not have a very large RPS (it may not coincide by an order of magnitude with what is seen in fully synthetic benchmarks) with an acceptable delay due to the fact that a lot of coroutines will simultaneously rotate in a competitive server.
@tornado.gen.coroutine def old_school_work(): yield tornado.gen.sleep(SLEEP_TIME) async def work(): await tornado.gen.sleep(SLEEP_TIME) Load - GET http requests. Duration - 300s, 1s - warmup, 5 repetitions of the load.
Results on service response time percentiles.
What are percentiles?
You have some big set of numbers. 95th percentile X means that 95% of the values in this sample are less than X. With a probability of 5%, your number will be more than X.
We see that Aiohttp on such a simple test did a great job on 1000 RPS. All while without uvloop .
Compare Tornado with the old and new async schools. Authors are strongly advised to use async. We can make sure that they are really much faster.
At 1200 RPS, the Tornado, even with the new school korutinami, is already beginning to give up, and the Tornado with the old school korutinami has completely blown away. If we sleep 50 ms, and microservice is responsible for 80 ms, it does not go into any gate at all.
The new Tornado school for the 1500 RPS completely surrendered, and Aiohttp is still far from the 3000 RPS limit. The most interesting is yet to come.
Pyflame, profiling a working microservice
Let's see what is happening at this moment with the processor.
When we figured out how asynchronous Python microservices work in production, they tried to understand what was going on. In most cases, the problem was with the CPU or with descriptors. There is a great profiling tool created in Uber, the Pyflame profiler, which is based on the ptrace system call.
We start some service in the container and start throwing a combat load on it. Often, this is not a very trivial task - to create just such a load that is in combat, because it often happens that you run synthetic tests on load testing, you look, and everything works fine. You are pushing a combat load onto it, and now microservice starts to blunt.
During operation, this profiler does snapshots of the call stack for us. You can not change the service at all, just run pyflame next to it. It will collect the stack trace once in a while, and then does a cool visualization. This profiler gives very little overhead, especially when compared with cProfile. Pyflame also supports multithreaded programs. We ran this thing right in the market, and the performance was not degraded.
Here on the X axis is the amount of time, the number of calls when the stack frame was in the list of all the stack of Python frames. This is the approximate amount of CPU time that we spent in this particular stack frame.
As you can see, most of the time in aiohttp is spent on idle. Great: this is what we want from an asynchronous service, so that it will deal with network calls most of the time. In this case, the stack depth is about 15 frames.
In Tornado (the second picture) with the same load, much less time is spent on idle and the stack depth in this case is about 30 frames.
Here is a link to svg , you can twist it yourself.
More sophisticated asynchronous benchmark
async def work(): # await asyncio.sleep(SLEEP_TIME) class HardWorkHandler(tornado.web.RequestHandler): timeout_time = datetime.timedelta(seconds=SLEEP_TIME / 2) async def get(self): await work() # await tornado.gen.multi([work(), work()]) # try: await tornado.gen.with_timeout(self.timeout_time, work()) except tornado.util.TimeoutError: # pass You should expect a runtime of 125 ms.
Tornado with uvloop holds up better. But Aiohttp uvloop helps much more. Aiohttp 2300-2400 RPS, uvloop . , .
Results
, .
- -, , . Aiohttp 2,5 , Tornado.
- . Uvloop Aiohttp (, Tornado).
- Pyflame, .
- yield from (await) yield.
( ) Aiohttp c Tornado Python .
- CPU 2 .
- http-.
- 2 5 .
. , . Thank you all for your attention. , .
Source: https://habr.com/ru/post/435532/
All Articles