Seamless client server
 Any client-server project implies a clear separation of the code base into 2 parts (sometimes more) - client and server. Often, each such part is made out in the form of a separate independent project, supported by its team of developers.
Any client-server project implies a clear separation of the code base into 2 parts (sometimes more) - client and server. Often, each such part is made out in the form of a separate independent project, supported by its team of developers.In this article, I propose to take a critical look at the standard rigid separation of code into backend and frontend. And consider an alternative where in the code there is no clear line between the client and the server.
')
Cons of the standard approach
The main disadvantage of the standard division of the project into 2 parts is the blurring of business logic between the client and the server. We edit the data in the form in the browser, verify it in the client code and send it to the village of the grandfather (to the server). The server is another project. There, too, you need to check the correctness of the incoming data (ie, duplicate the client's functionality), make some additional manipulations (save in the database, send an e-mail, etc.).
Thus, in order to track the entire path of information from the form in the browser to the database on the server, we will have to dig into two diverse systems. If the team has separate roles and different specialists are responsible for the backend and front-end, additional organizational problems arise due to their synchronization.
Let's dream
Suppose that we can describe the entire data path from the form on the client to the database on the server in one model. In code, it might look something like this (code is not working):
class MyDataModel { // verifyData(data) { // .... return true; } // client saveData(data) { if(this.verifyData(data)) this.writeDataToDb(data) else consol.log('error') } // . server writeDataToDb(data) { if(this.verifyData(data)) this.db.insert(data) else consol.log('error') } } Thus, the entire business logic of the model is before our eyes. Maintain this code easier. Here are the advantages that the combination of client-server methods in one model can bring:
- Business logic is concentrated in one place, there is no need to separate it between the client and the server.
- You can easily transfer functionality from server to client or from client to server during project development.
- There is no need to duplicate the same methods for the backend and the frontend.
- A single set of tests for the entire business logic of the project.
- Replacing horizontal lines of responsibility in the project on the vertical.
The last item will reveal more. Imagine a regular client-server application in the form of such a scheme:
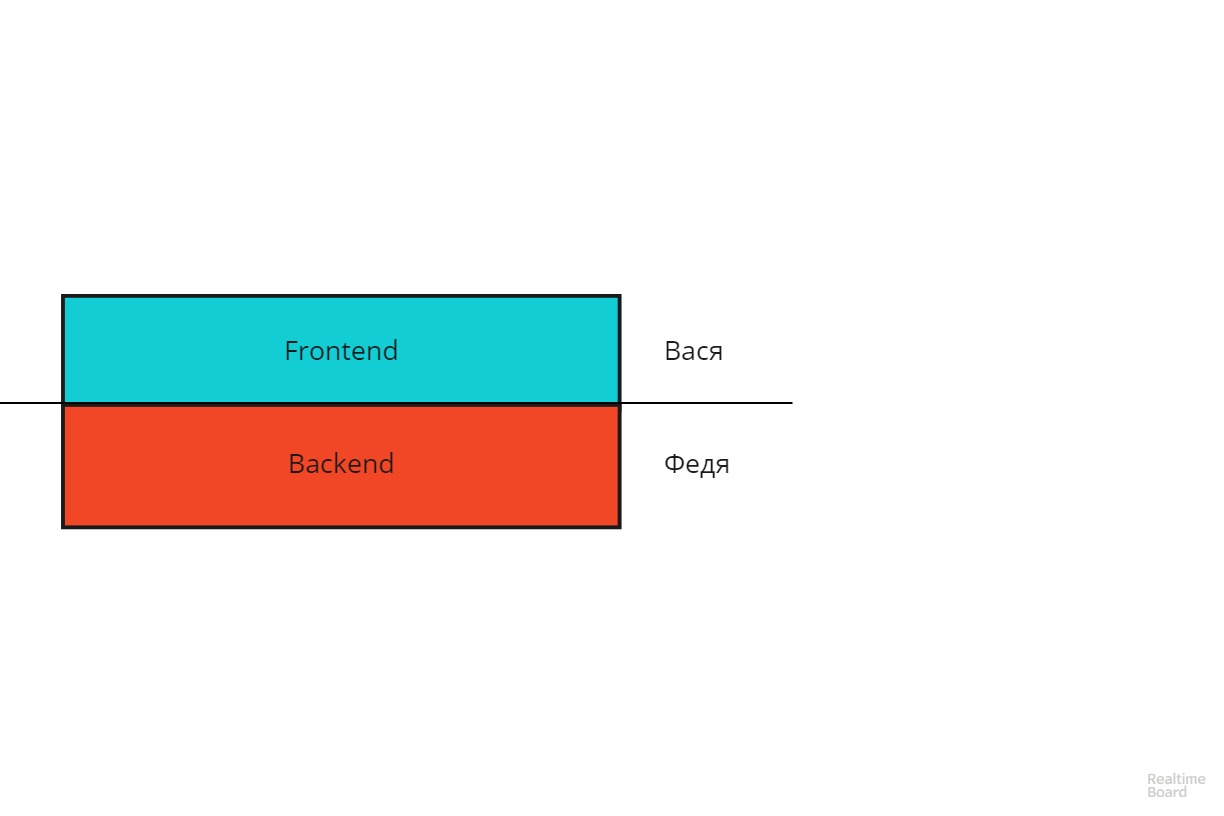
Vasya is responsible for the frontend, Fedya for the backend. The line of responsibility is held horizontally. This scheme has the disadvantages of any vertical structure - it is difficult to scale and has low fault tolerance. If the project expands, you will have to make quite a difficult choice: who will Vasya or Fedya strengthen? Or if Fedya fell ill or quit, Vasya could not replace him.
The approach proposed here allows you to expand the line of responsibility demarcation by 90 degrees and turn the vertical architecture into a horizontal one.
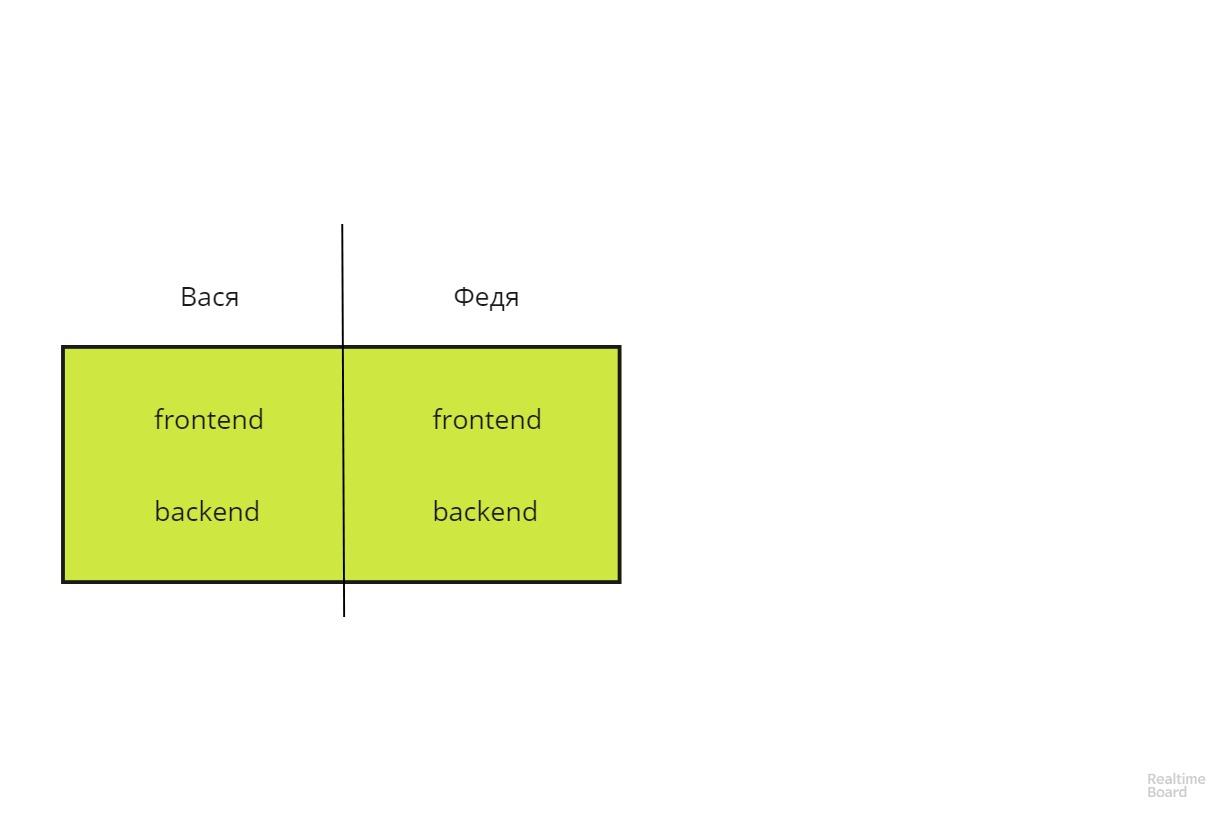
Such architecture is much easier to scale and more fault tolerant. Vasya and Fedya become interchangeable.
In theory, it looks good, we will try to implement all this in practice, without losing on the road everything that gives us the separate existence of the client and server.
Formulation of the problem
We do not necessarily have to have an integrated client-server in production. On the contrary, such a decision would be extremely harmful from all points of view. The task is that in the development process we would have a single code base for data models for the backend and frontend, but the output would be an independent client and server. In this case, we will get all the advantages of the standard approach and gain convenience in the development and support of the project listed above.
Decision
I have been experimenting with the integration of client and server in a single file for quite some time. Until recently, the main problem was that in standard JS the connection of third-party modules on the client and the server was too different: require (...) in node.js, on the client any AJAX-magic. Everything has changed with the advent of ES-modules. In modern browsers, "import" has been supported for a long time. Node.js lags behind a bit in this respect and ES modules are supported only with the "--experimental-modules" flag enabled. It is hoped that in the foreseeable future, the modules will work out of the box and in node.js. In addition, it is unlikely that much will change, because In browsers, this functionality has long been the default. I think that now you can use ES modules not only on the client but also on the server side (if you have counter arguments on this subject, write in the comments).
The solution scheme looks like this:

The project contains three main catalogs:
protected - backend;
public - frontend;
shared - common client-server models.
A separate observer process monitors files in the shared directory and, with any changes, creates versions of the modified file separately for the client and separately for the server (in the protected / shared and public / shared directories).
Implementation
Consider the example of a simple real-time messenger. We need a fresh node.js (I have version 11.0.0) and Redis (their installation is not considered here).
Clone an example:
git clone https://github.com/Kolbaskin/both-example cd ./both-example npm i Install and run the process-observer (observer on the diagram):
npm i both-js -g both ./index.mjs If everything is in order, the observer will start the web server and start monitoring changes to files in the shared and protected directories. At changes in shared the corresponding versions of data models for the client and for the server are created. When changes to a protected observer will automatically restart the web server.
You can see the performance of the messenger in the browser by clicking on the link
http://localhost:3000/index.html?token=123&user=Vasya(token and user arbitrary). To emulate multiple users, open the same page in another browser specifying other token and user.
Now for some code.
Web server
protected / server.mjs
import express from 'express'; import bodyParser from 'body-parser'; // - // - import wsServer from './lib/wsServer.mjs'; const app = express(); // - wsServer(app); // mime mjs express.static.mime.define({'application/javascript': ['js','mjs']}); app.use( bodyParser.json() ); app.use(bodyParser.urlencoded({ extended: true })); // public app.use(express.static('public')); const server = app.listen(3000, () => { console.log('server is running at %s', server.address().port); }); This is an ordinary express-server, there is nothing interesting here. The mjs extension is needed for ES modules in node.js. For consistency, we will use this extension for the client.
Customer
public / index.html
<!DOCTYPE html> <html lang="en"> <head> ... <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script> <script src="/main.mjs" type="module"></script> </head> <body> ... <ul id="users"> <li v-for="user in users"> {{ user.name }} ({{user.id}}) </li> </ul> <div id="messages"> <div> <input type="text" v-model="msg" /> <button v-on:click="sendMessage()"></button> </div> <ul> <li v-for="message in messages">[{{ message.date }}] <strong>{{ message.text }}</strong></li> </ul> </div> </body> </html> For example, I use on the client Vue, but essentially it does not change. Instead of Vue there can be anything where you can separate the data model into a separate class (knockout, angular).
public / main.mjs
// - import ws from "/lib/Ws.mjs"; // import Messages from "./shared/messages/model/dataModel.mjs"; // import Users from "./shared/users/model/dataModel.mjs"; // - ( ) window.WS = new ws({ token: new URLSearchParams(document.location.search).get("token"), user: new URLSearchParams(document.location.search).get("user") }); // new Messages({ el: '#messages' }) // new Users({ el: '#users' }) main.mjs is a script that associates data models with corresponding views. To simplify the code of the sample view for the list of active users and message feeds are built right into index.html
Data model
shared / messages / model / dataModel.mjs
// // , // import Base from '@root/lib/Base.mjs'; export default class dataModel extends Base { //!#client constructor(attr) { attr.data = { msg: '', messages: [] } super(attr); // this.on('newmessage', (data) => { this.messages.push(data) }) } //!#client async sendMessage(e) { // await this.$sendMessage(this.msg); this.msg = ''; } //!#server async $sendMessage(text) { // newmessage this.fireEvent('newmessage', 'all', { date: new Date(), text }) return true; } } These several methods implement all the functionality of sending and receiving messages in real time. The! #Client and! #Server directives indicate to the monitoring process which method for which part (client or server) is intended. If before the definition of the method there are no these directives, this method is available both on the client and on the server. Comment slashes before the directive are not required and exist only so that the standard IDE does not swear for syntax errors.
The first line in the path uses the substitution & root. When generating the client and server versions, & root will be replaced with a relative path to the public and protected directories, respectively.
Another important point: from the client method, you can call only the server method, the name of which starts with "$":
... // async sendMessage(e) { await this.$sendMessage(this.msg); <- this.msg = ''; } ... This is done for security reasons: from the outside you can only apply to specially-designed methods.
Let's look at the versions of the data models that the observer (observer) generated for the client and server.
Client (public / shared / messages / model / dataModel.mjs)
import Base from '/lib/Base.mjs'; export default class dataModel extends Base { __getFilePath__() {return "messages/model/dataModel.mjs"} // constructor(attr) { attr.data = { msg: '', messages: [] } super(attr); // this.on('newmessage', (data) => { this.messages.push(data) }) } // async sendMessage(e) { // await this.$sendMessage(this.msg); this.msg = ''; } // ... async $sendMessage() {return await this.__runSharedFunction("$sendMessage",arguments)} } On the client side, the model is a descendant of the Vue class (via Base.mjs). Thus, you can work with it as with the usual Vue data model. The observer added the __getFilePath__ method to the client version of the model, which returns the path to the class file and replaced the $ sendMessage server method code with a construct that, in essence, through the rpc mechanism will call the required method on the server (__runSharedFunction is defined in the parent class).
Server (protected / shared / messages / model / dataModel.mjs)
import Base from '../../lib/Base.mjs'; export default class dataModel extends Base { __getFilePath__() {return "messages/model/dataModel.mjs"} ... ... // async $sendMessage(text) { // newmessage this.fireEvent('newmessage', 'all', { date: new Date(), text }) return true; } } The server version also added the __getFilePath__ method and removed client methods marked with the directive! #Client
In both model generated versions, all deleted lines are replaced with empty ones. This is done so that the debugger error message can easily find the problematic line in the model source code.
Client and server interaction
When we need to call a server method on the client, we just do it.
If the challenge is within one model, everything is simple:
... !#client async sendMessage(e) { await this.$sendMessage(this.msg); this.msg = ''; } !#server async $sendMessage(msg) { // - } ... You can "pull" another model:
import dataModel from "/shared/messages/model/dataModel.mjs"; var msg = new dataModel(); msg.$sendMessage('blah-blah-blah'); In the opposite direction, i.e. call on the server any client method does not work. Technically, this is feasible, but from a practical point of view, it makes no sense, because There is one server and many clients. If we need to initiate some actions on the server on the client, we use the event mechanism:
// ... //!#client constructor(attr) { .... // "newmessage" this.on('newmessage', (data) => { this.messages.push(data) }) } //!#server async $sendMessage(text) { // newmessage this.fireEvent('newmessage', 'all', { date: new Date(), text }) return true; } ... The fireEvent method takes 3 parameters: the name of the event, to whom it is addressed and the data. The addressee can be defined in several ways: “all” keyword - the event will be sent to all users or in the array to list session tokens of those clients to whom the event is addressed.
The event is not tied to a specific instance of the data model class and will trigger handlers in all instances of the class in which fireEvent was called.
Horizontal scaling backend
The solidity of client-server models in the proposed implementation, at first glance, should impose significant restrictions on the possibility of horizontal scaling of the server part. But this is not the case: technically, the server does not depend on the client. You can copy the “public” directory anywhere and share its contents through any other web server (nginx, apache, etc.).
The server part can be easily expanded by launching new instances of the backend. Redis and the Kue queue system are used to communicate the individual instances.
API and different clients to the same backend
In real projects, diversified clients - web sites, mobile applications, third-party services can use one server API. In the proposed solution, all this is available without any additional dances. Under the hood of calling server methods is the good old rpc. The web server itself is a classic express application. It is enough to add a wrapper for routes with calling the necessary methods of the same data models.
Post scriptum
The approach proposed in the article does not pretend to any revolutionary changes in client-server applications. He only adds a bit of comfort to the development process, allowing him to focus on the business logic gathered in one place.
This project is experimental, write in the comments if you think it is worth continuing this experiment.
Source: https://habr.com/ru/post/435494/
All Articles