Little about lexical analysis

Long time ago, when the sky was blue, the grass was greener and dinosaurs roamed the Earth ... No, forget about dinosaurs. Well, in general, once the thought occurred to take a break from standard web programming and do something more insane. It was possible, of course, anything, but the choice fell on the writing of his interpreter. What can I say ... Never write your programming languages . But I learned some experience from all this, so I decided to share it. Let's start with the very basics - lexer.
Foreword
Before you begin to understand what kind of animal a “lexer” is, it is worth figuring out what a PL consists of.
In the modern world, each compiler / interpreter / transpiler / something-there-yet-like (let's, I just call it “the compiler”, without any distinctions on types) is divided into two pieces. In the terminology of smart uncles, such pieces are called "frontend" and "backend". No, it’s not at all working with the web that we used to call and the front is not written in JS with HTML. Although ... Okay.
')
The first task, the frontend, is to take the text and turn it into an AST (abstract syntax tree), checking the correctness of the syntax (and sometimes semantics) along the way. The task of the second, backend - to make it all work. If the code is collected inside the interpreter, then a set of commands for the virtual processor (virtual machine) is created from AST, if the compiler, then a set of commands for the real processor. In life, everything is quite complicated and can be realized not quite. For example, in the case of the GCC compiler, everything is intermixed, but Clang is more canonical, LLVM is a typical representative of the backend for compilers.
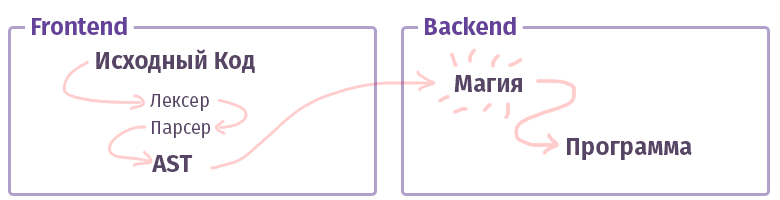
And now let's get acquainted with the piece called the "frontend".
Lexical analysis
The task of the lexer and the stage of lexical analysis is to get a lot of letters to the input and group them into some categories - “tokens”. Therefore, lexical analysis is also called “tokenization”. This is the very first stage of text processing that each existing compiler produces.
Like this:
$tokens = ['class', '\w+', '}', '{']; var_dump(lex('class Example {}', $tokens)); // array(4) { // [0] => string(5) "class" // [1] => string(7) "Example" // [2] => string(1) "{" // [3] => string(1) "}" // } By the way, here we have already written a lot of tools to make life easier. The same preg functions that we used to use to parse text cope well with this task. However, there are more convenient tools for this business:
- Phlexy , written by Nikita Popov.
- Hoa is a toolkit consisting of Lexer + Parser + Grammar.
- The port of Yacc , written by Anthony Ferrara, which is also a comprehensive toolkit, and on which is written the well-known PHP parser Popov, used in tools that use code analysis.
- Railt Lexer is my implementation for PHP 7.1+
- Parle is an extension for PHP that allows a limited set of PCRE expressions (no lookahead and some other syntactic constructs).
- And finally, the standard function php token_get_all , which is designed directly for lexical analysis of PHP.
Okay, it's clear that things that can divide text into tokens are plenty, maybe I even forgot something, like Doctrine lexer. But what next?
Types of lexers
And as always, things are not as simple as they seemed. There are at least two different categories of lexers. There is the usual option, quite trivial, which you slip the rules, and he already divides everything into tokens. The configuration of this is not much different from the example shown by me above. However, there is another option called multistate . Such lexers are a little harder to understand, so I want to talk about them in a bit more detail.
The multistate lexer task is to display different tokens depending on the previous state. Well, for example, in PHP such “transitional” states are formed with the help of <? Php +?> Tags, within lines, comments, and HEREDOC / NOWDOC constructs.
Remember the previous example with 4 tokens above? Let's modify it a bit to understand what these states are:
class Example { // class Example {} } In this case, if we have the simplest lexer without the wide capabilities of PCRE, then we get the following set of tokens:
var_dump(lex(...)); // array(9) { // [0] => string(5) "class" // [1] => string(7) "Example" // [2] => string(1) "{" // [3] => string(2) "//" // [4] => string(5) "class" // [5] => string(7) "Example" // [6] => string(1) "{" // [7] => string(1) "}" // [8] => string(1) "}" //} As you can see, we got a completely banal jamb on elements 3-5: The comment was perceived quite unexpectedly and itself was divided into tokens, although it had to be considered as a solid piece.
Of course, with the PCRE functional, such a token could be ripped out with the help of the simple regular " // [^ \ n] * \ n ", but if it is not? Well, or do we want to gash with our hands? In short, in the case of the multistate lexer, we can say that all tokens must be in group No1 , as soon as the token " // " is found, then a transition to group No2 should occur. And inside the second group there is a reverse transition if the token " \ n " is found - the transition back to the first group.
Something like this:
$tokens = [ 'group-1' => [ 'class', '\w+', '{', '}', '//' => 'group-2' // 2 ], 'group-2' => [ "\n" => 'group-1', // 1 '.*' ] ]; I think now it becomes clearer how some HEREDOC is parsed, because even with all the power of PCRE, writing a regular schedule for this business is extremely problematic, given that this HEREDOC syntax supports interpolation of variables. Just try parsing something with the built-in token_get_all function (note the> 12 token):
<?php $example = 42; $a = <<<EOL Your answer is $example !!! EOL; var_dump(token_get_all(file_get_contents(__FILE__))); Okay, it seems we are ready to begin the practice.
Practice
Let's remember what we have in PHP for such cases? Well, of course, preg_match! Okay, come down. The preg_match based algorithm is implemented in Hoa and here in this Phelxy implementation . Its task is quite simple:
- We have on hand the source text and an array of regularies.
- Match until something is right.
- Once found a piece, cut it out of the text and match it further.
As code, it will look something like this:
Code sheet
<?php class SimpleLexer { /** * @var array<string> */ private $tokens = []; /** * @param array<string> $tokens */ public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[$name] = \sprintf('/\G%s/isSum', $definition); } } /** * @param string $sources * @return iterable&\Traversable<string> * @throws RuntimeException */ public function lex(string $sources): iterable { [$offset, $length] = [0, \strlen($sources)]; while ($offset < $length) { [$name, $token] = $this->next($sources, $offset); yield $name => $token; $offset += \strlen($token); } } /** * @param string $sources * @param int $offset * @return array<string,string> * @throws RuntimeException */ private function next(string $sources, int $offset): array { foreach ($this->tokens as $name => $pcre) { \preg_match($pcre, $sources, $matches, 0, $offset); $token = \reset($matches); if (\count($matches) && \strpos($sources, $token, $offset) === $offset) { return [$name, $token]; } } throw new \RuntimeException('Unrecognized token at offset ' . $offset); } } Using Code Sheets
$lexer = new SimpleLexer([ 'T_CLASS' => 'class', 'T_CONST' => '\w+', 'T_BRACE_OPEN' => '{', 'T_BRACE_CLOSE' => '}', 'T_WHITESPACE' => '\s+', ]); echo \sprintf('| %-10s | %-20s |', 'VALUE', 'NAME') . "\n"; foreach ($lexer->lex('class Example {}') as $name => $token) { echo \sprintf('| %-10s | %-20s |', '"' . \trim($token, "\n") . '"', $name) . "\n"; } Such an approach is rather trivial and allows a pair of pokes on the keyboard to modify the lexer in the area of the next () method, adding the transition between states and turning this section of hand-hopping into a primitive multistate lexer. In the $ this-> tokens area, it’s enough to add something like $ this-> tokens [$ this-> state] .
However, besides primitivism itself, there is one more drawback, not fatal as it could turn out to be, but still ... Such an implementation works incredibly slowly. On i7 7600k, the owner of which I by chance turned out to be - a similar algorithm processes approximately 400 tokens per second, and with an increase in their variations (i.e. definitions that we passed to the designer) - it can slow down to the speed of changing presidents in the Russian Federation ... ahem , sorry. I wanted to say, of course, that it would work very slowly .
Okay, what can we do? For a start, you can understand what is going wrong. The fact is that every time we call preg_match , the compiler with its JIT, called PCRE, rises inside the wilds of the language (And since PHP 7.3 is already PCRE2). Each time it parses the regulars itself and builds a parser for them, with which we parse the text to create tokens. It sounds a bit strange and tautological. But in short, each token requires a compilation of 1 to N regulars, where N is the number of definitions of these tokens. In this case, it is worth noting that even the applied flag " S " and optimization with the help of " \ G " in the constructor, where regular expressions for tokens are formed, do not help.
One way out of this situation suggests itself - it is necessary to parse all this text in one pass, i.e. using just one preg_match function. It remains to solve two problems:
- How to indicate that the result of the regular expression N1 corresponds to the token N2? Those. how to denote that " \ w + ", for example - this is T_CONST .
- How to determine the sequence of tokens as a result. As you know, the result of preg_match or preg_match_all will contain everything mixed up. And even with the help of flags passed as the fourth argument, the situation will not change.
Here you can pause and think a little. Well or not.
The solution to the first problem is PCRE named groups , which are also referred to as “submasks”. With the help of the rules: " (? <T_WHITESPACE> \ s + | <T_WORD> \ w + | ...) " you can get all the tokens in one pass by matching them with their names. As a result of the match, an associative array consisting of pairs " [TOKEN_NAME => TOKEN_VALUE] " will be formed.
With the second a bit more complicated. But here you can use tactical trick and use the function preg_replace_callback . Its peculiarity is that the anonymous text passed as the second argument will be called strictly sequentially, for each token, from first to last.
In order not to torment - the implementation is as follows:
Another code footcloth
class PregReplaceLexer { /** * @var array<string> */ private $tokens = []; /** * @param array<string> $tokens */ public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[] = \sprintf('(?<%s>%s)', $name, $definition); } } /** * @param string $sources * @return iterable&\Traversable<string,string> */ public function lex(string $sources): iterable { $result = []; \preg_replace_callback($this->compilePcre(), function (array $matches) use (&$result) { foreach (\array_reverse($matches) as $name => $value) { if (\is_string($name) && $value !== '') { $result[] = [$name, $value]; break; } } }, $sources); foreach ($result as [$name, $value]) { yield $name => $value; } } /** * @return string */ private function compilePcre(): string { return \sprintf('/\G(?:%s)/isSum', \implode('|', $this->tokens)); } } And its use is no different from the previous version. At the same time, the speed of work increases from 400 to 57,000 tokens per second. It is this algorithm that I applied in my implementation , taking up the rewriting of Hoa source codes. By the way, if you use Parle, you can squeeze up to 600,000 tokens per second. And the overall picture looks something like this (with XDebug enabled in PHP 7.1, so the numbers are lower here, but the ratio can be approximated).
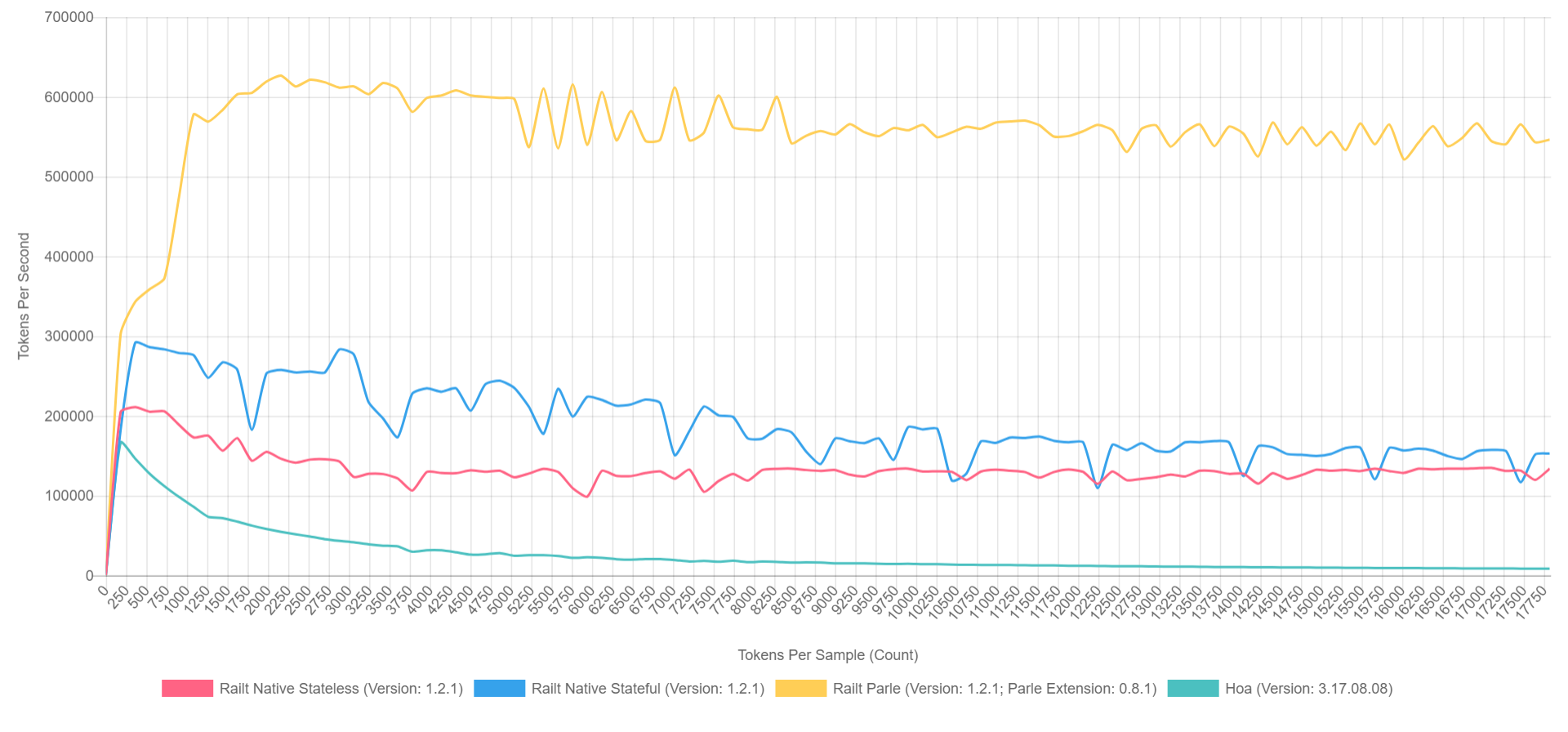
- Yellow is the native extension of Parle.
- Blue - implementation via preg_replace_callback with a pre-assembled regular schedule .
- Red - all the same, but with the generated regular during the call to preg_replace_callback .
- Green - implementation via preg_match .
What for?
Well, all this, of course, is wonderful, but impatient people are eager to ask the question: “Who needs this at all?”. In the abstract world of PHP, where the principle of “figak-figak-and-site-ready” dominates - such libraries are not needed, let's be honest. But if we talk about the ecosystem as a whole, then we can recall the well-known libraries, like symfony / yaml or Doctrine . Annotations in symfony are the same sublanguage inside PHP, requiring separate lexical and syntactic parsing. In addition, there are a little less well-known transporters CoffeeScript, Less and Scss / Sass, written in PHP. Well, or Yay and preprocess based on it. I will not even mention code analysis tools like phpmd or phpcs. And the documentation generators, like phpDocumentnor or Sami, are pretty trivial. Each of these projects to one degree or another uses lexical analysis at the first stage of text / code parsing.
This is not a complete list of projects and maybe, I hope, my story will help you discover something new and replenish it.
Afterword
Looking ahead, if there is anyone interested in the subject of parsers and compilers, then there are some interesting reports on this topic, in particular from the guys from JetBrains:
Video
Also, of course, most of the speeches of Andrei Breslav ( abreslav ), which can be found on YouTube, I advise you to watch.
Well, for lovers of reading, there is such a resource that was personally extremely useful to me.
Post Post Scriptum. If somewhere it was sealed in the vastness of this epic, then you can safely inform the author in any form convenient for you.
As a bonus, I would like to give an example of a simple PHP lexer , it seems not so scary now, and now it’s even clear what it does, right? Although whom I am deceiving, from the regulars the eyes bleed. =)
Thank!
Source: https://habr.com/ru/post/435102/
All Articles