How Artificial Intelligence Learning Scales
We at OpenAI found that the gradient noise scale, a simple statistical method, predicts the parallelism of learning a neutral network on a wide range of tasks. Since for more complex tasks the gradient usually becomes more noisy, increasing the size of the packages available for simultaneous processing will be useful in the future and eliminate one of the potential limitations of AI systems. In general, these results show that the training of neural networks should not be regarded as mysterious art, and that it can be given accuracy and systematized.
Over the past few years, AI researchers have become increasingly successful in accelerating the learning of a neural network with the help of data parallelization, which breaks large data packets into several computers. Researchers have successfully used packages of tens of thousands of units for image classification and language modeling , and even millions of reinforcement training agents playing Dota 2. Such large packages can increase the amount of computing power that is effectively involved in teaching one model of the forces driving growth in the field of learning AI. However, with too large data packets, a rapid decrease in algorithmic recoil occurs, and it is not clear why these restrictions turn out to be larger for some tasks and smaller for others.

The scaling of the gradient noise, averaged over the approaches to learning, explains most of the (r 2 = 80%) variations in the size of the critical data packet for various tasks, differing by six orders of magnitude. Packet sizes are measured in the number of images, tokens (for language models) or observations (for games).
We found that by measuring the scale of gradient noise, simple statistics that numerically determine the signal-to-noise ratio in network gradients, we can approximately predict the maximum packet size. Heuristically, the noise scale measures the variation of data from the point of view of the model (at a certain stage of learning). When the noise scale is small, parallel learning on large amounts of data quickly becomes redundant, and when it is large, we can learn a lot from large data sets.
')
Statistics of this kind are widely used to determine the sample size , and it was suggested to be used in in- depth training , but it was not used systematically for modern neural network training. We confirmed this prediction for a large range of machine learning tasks depicted in the graph above, including pattern recognition, language modeling, Atari and Dota games. In particular, we conducted training for neural networks designed to solve each of these tasks on data packets of various sizes (separately adjusting the learning rate for each of them), and compared the learning acceleration to what the noise scale predicts. Since large data packages often require careful and costly adjustments or a special training rate schedule in order for training to be effective, knowing the upper limit in advance, you can gain a significant advantage when learning new models.
We found it useful to visualize the results of these experiments as a compromise between the actual training time and the total amount of calculations required for training (proportional to its value in money). On very small data packets, doubling the size of the packet allows you to conduct training twice as fast without using additional computing power (we run twice as many individual threads that work twice as fast). On very large data layouts, parallelization does not accelerate learning. The curve in the middle bends, and the scale of the gradient noise predicts exactly where the deflection occurs.
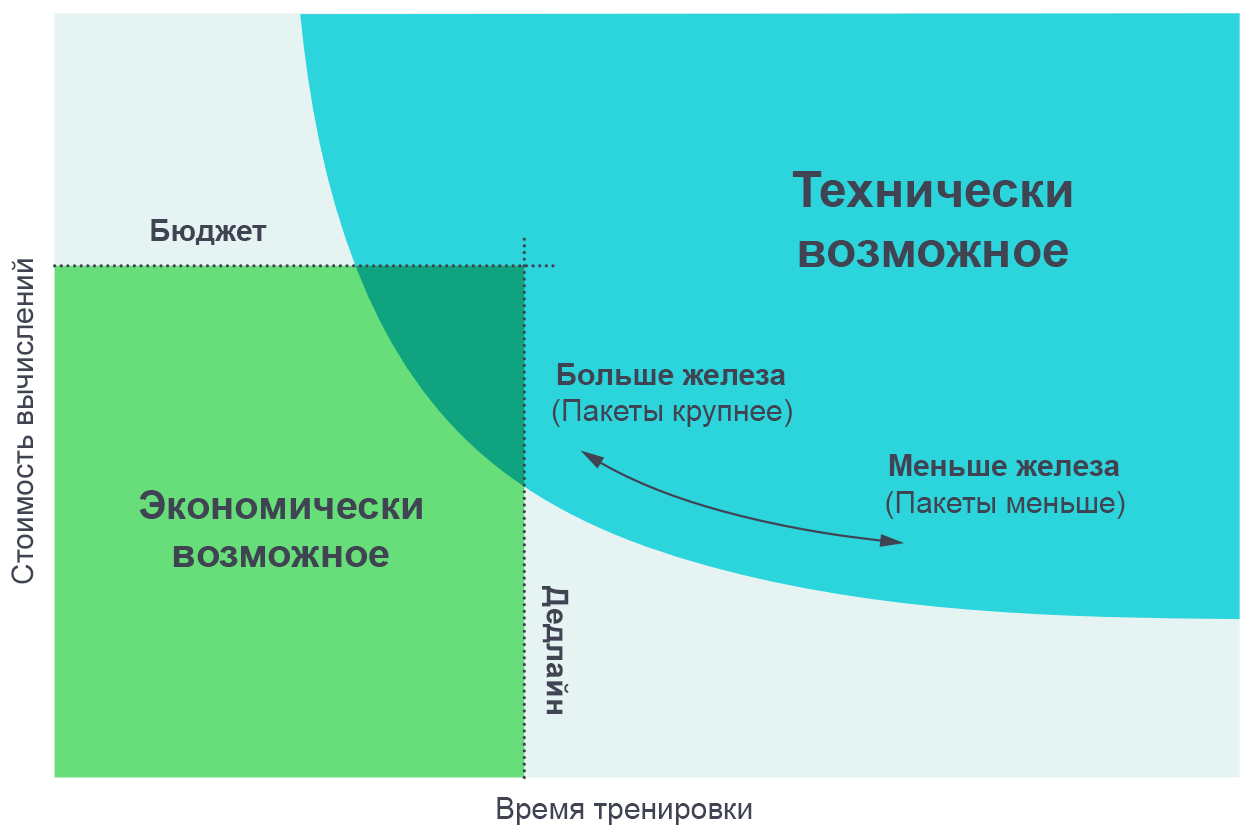 Increasing the number of parallel processes allows you to train more complex models at a reasonable time. Pareto border chart is the most intuitive way to visualize the comparison of algorithms and scales.
Increasing the number of parallel processes allows you to train more complex models at a reasonable time. Pareto border chart is the most intuitive way to visualize the comparison of algorithms and scales.
We get these curves by assigning a goal in a task (say, 1000 points in the Atari Beam Rider game), and watching how long a neural network needs to learn in order to achieve this goal at different packet sizes. The results quite accurately coincide with the predictions of our model, taking into account the different values of the goals we set.
[ On the page with the original article , interactive graphs of a compromise between experience and learning time are presented to achieve a given goal. ]
We came across several patterns in the scale of gradient noise, based on which we can make assumptions about the future of AI training.
First, in our experiments in the process of learning, the scale of noise usually increases by an order of magnitude or more. Apparently, this means that the network learns more “obvious” features of the task at the very beginning of training, and then studies smaller details. For example, in the task of classifying images a neural network can first learn to identify features of a small scale, such as edges or textures represented on most images, and only later compare these little things together, creating more general concepts like cats or dogs. To get an idea of all the variety of faces and textures, neural networks need to see a small number of images, so the scale of noise is smaller; Once the network knows more about larger objects, it will be able to process many more images at the same time, without considering duplicate data.
We saw several preliminary indications that a similar effect works on other models dealing with the same data set — for more powerful models, the scale of the gradient noise is higher, but only because they have less loss. Therefore, there is some evidence that the increase in noise during training is not just an artifact of convergence, but is due to an improvement in the model. If so, then we can expect that future, improved models will have a larger noise scale and will be more amenable to parallelization.
Secondly, tasks that are objectively more complex are more amenable to parallelization. In the context of learning with a teacher, there is clear progress in the transition from MNIST to SVHN and ImageNet. In the context of reinforcement learning, there is clear progress in the transition from Atari Pong to Dota 1v1 and Dota 5v5 , with the size of the optimal data packet varying 10,000 times. Therefore, as AIs cope with increasingly complex tasks, it is expected that models will cope with larger data sets.
The degree of data parallelization seriously affects the speed of development of AI capabilities. Acceleration of learning makes it possible to create more capable models and accelerates research, allowing you to shorten the time of each iteration.
In an earlier study, AI and Calculations , we saw that calculations for training the largest models double every 3.5 months, and noted that this trend is based on a combination of the economy (the desire to spend money on calculations) and algorithmic possibilities for parallelizing training . The last factor (algorithmic parallelizability) is more difficult to predict, and its limitations have not yet been fully studied, but our current results represent a step forward in its systematization and numerical expression. In particular, we have evidence that more complex tasks, or more powerful models aimed at a known task, will allow us to more parallelly work with data. This will be a key factor supporting the exponential growth of learning-related computing. And we do not even consider the recent developments in the field of parallel models, which may allow us to further strengthen the parallelization by adding it to the existing parallel data processing.
The continued growth of the field of educational computing and its predictable algorithmic base suggest the possibility of an explosive increase in the capabilities of AI in the next few years, and emphasize the need for the earliest research into the safe and responsible use of such systems. The main difficulty in creating a policy of using AI will be to decide how such measures can be used to predict the characteristics of future AI systems, and use this knowledge to create rules that allow society to maximize useful properties and minimize the harm of these technologies.
The OpenAI organization plans to conduct rigorous analysis to predict the future of AI, and work proactively on the issues raised by this analysis.
Over the past few years, AI researchers have become increasingly successful in accelerating the learning of a neural network with the help of data parallelization, which breaks large data packets into several computers. Researchers have successfully used packages of tens of thousands of units for image classification and language modeling , and even millions of reinforcement training agents playing Dota 2. Such large packages can increase the amount of computing power that is effectively involved in teaching one model of the forces driving growth in the field of learning AI. However, with too large data packets, a rapid decrease in algorithmic recoil occurs, and it is not clear why these restrictions turn out to be larger for some tasks and smaller for others.
The scaling of the gradient noise, averaged over the approaches to learning, explains most of the (r 2 = 80%) variations in the size of the critical data packet for various tasks, differing by six orders of magnitude. Packet sizes are measured in the number of images, tokens (for language models) or observations (for games).
We found that by measuring the scale of gradient noise, simple statistics that numerically determine the signal-to-noise ratio in network gradients, we can approximately predict the maximum packet size. Heuristically, the noise scale measures the variation of data from the point of view of the model (at a certain stage of learning). When the noise scale is small, parallel learning on large amounts of data quickly becomes redundant, and when it is large, we can learn a lot from large data sets.
')
Statistics of this kind are widely used to determine the sample size , and it was suggested to be used in in- depth training , but it was not used systematically for modern neural network training. We confirmed this prediction for a large range of machine learning tasks depicted in the graph above, including pattern recognition, language modeling, Atari and Dota games. In particular, we conducted training for neural networks designed to solve each of these tasks on data packets of various sizes (separately adjusting the learning rate for each of them), and compared the learning acceleration to what the noise scale predicts. Since large data packages often require careful and costly adjustments or a special training rate schedule in order for training to be effective, knowing the upper limit in advance, you can gain a significant advantage when learning new models.
We found it useful to visualize the results of these experiments as a compromise between the actual training time and the total amount of calculations required for training (proportional to its value in money). On very small data packets, doubling the size of the packet allows you to conduct training twice as fast without using additional computing power (we run twice as many individual threads that work twice as fast). On very large data layouts, parallelization does not accelerate learning. The curve in the middle bends, and the scale of the gradient noise predicts exactly where the deflection occurs.
Increasing the number of parallel processes allows you to train more complex models at a reasonable time. Pareto border chart is the most intuitive way to visualize the comparison of algorithms and scales.We get these curves by assigning a goal in a task (say, 1000 points in the Atari Beam Rider game), and watching how long a neural network needs to learn in order to achieve this goal at different packet sizes. The results quite accurately coincide with the predictions of our model, taking into account the different values of the goals we set.
[ On the page with the original article , interactive graphs of a compromise between experience and learning time are presented to achieve a given goal. ]
Gradient noise scale patterns
We came across several patterns in the scale of gradient noise, based on which we can make assumptions about the future of AI training.
First, in our experiments in the process of learning, the scale of noise usually increases by an order of magnitude or more. Apparently, this means that the network learns more “obvious” features of the task at the very beginning of training, and then studies smaller details. For example, in the task of classifying images a neural network can first learn to identify features of a small scale, such as edges or textures represented on most images, and only later compare these little things together, creating more general concepts like cats or dogs. To get an idea of all the variety of faces and textures, neural networks need to see a small number of images, so the scale of noise is smaller; Once the network knows more about larger objects, it will be able to process many more images at the same time, without considering duplicate data.
We saw several preliminary indications that a similar effect works on other models dealing with the same data set — for more powerful models, the scale of the gradient noise is higher, but only because they have less loss. Therefore, there is some evidence that the increase in noise during training is not just an artifact of convergence, but is due to an improvement in the model. If so, then we can expect that future, improved models will have a larger noise scale and will be more amenable to parallelization.
Secondly, tasks that are objectively more complex are more amenable to parallelization. In the context of learning with a teacher, there is clear progress in the transition from MNIST to SVHN and ImageNet. In the context of reinforcement learning, there is clear progress in the transition from Atari Pong to Dota 1v1 and Dota 5v5 , with the size of the optimal data packet varying 10,000 times. Therefore, as AIs cope with increasingly complex tasks, it is expected that models will cope with larger data sets.
Effects
The degree of data parallelization seriously affects the speed of development of AI capabilities. Acceleration of learning makes it possible to create more capable models and accelerates research, allowing you to shorten the time of each iteration.
In an earlier study, AI and Calculations , we saw that calculations for training the largest models double every 3.5 months, and noted that this trend is based on a combination of the economy (the desire to spend money on calculations) and algorithmic possibilities for parallelizing training . The last factor (algorithmic parallelizability) is more difficult to predict, and its limitations have not yet been fully studied, but our current results represent a step forward in its systematization and numerical expression. In particular, we have evidence that more complex tasks, or more powerful models aimed at a known task, will allow us to more parallelly work with data. This will be a key factor supporting the exponential growth of learning-related computing. And we do not even consider the recent developments in the field of parallel models, which may allow us to further strengthen the parallelization by adding it to the existing parallel data processing.
The continued growth of the field of educational computing and its predictable algorithmic base suggest the possibility of an explosive increase in the capabilities of AI in the next few years, and emphasize the need for the earliest research into the safe and responsible use of such systems. The main difficulty in creating a policy of using AI will be to decide how such measures can be used to predict the characteristics of future AI systems, and use this knowledge to create rules that allow society to maximize useful properties and minimize the harm of these technologies.
The OpenAI organization plans to conduct rigorous analysis to predict the future of AI, and work proactively on the issues raised by this analysis.
Source: https://habr.com/ru/post/434934/
All Articles