5 lessons that we learned by writing over 300,000 lines of infrastructure code
Short master class on the development of infrastructure code

In October of this year, I gave a presentation at the HashiConf 2018 conference, where I talked about 5 key lessons that I and my colleagues at Gruntwork learned in the process of creating and maintaining a library of more than 300,000 lines of infrastructure code used in production systems by hundreds of companies. In this publication, I will share videos and slides from the presentation, as well as an abbreviated textual version of the description of the 5 main lessons.
Video and slides
Entry: DevOps Now - in the “Stone Age”
Despite the fact that the industry is full of fashionable progressive words: Kubernetes, microservices, service grids, unchangeable infrastructure, big data, data lakes, etc., the reality is that when you are immersed in creating infrastructure, you don’t feel yourself so fashionable and progressive.
Personally, DevOps reminds me more of this:




Creating a production-level infrastructure is difficult. This is real stress. And eats a lot of time. A lot of time.
It shows how much time it will take to implement the next infrastructure project. We relied on empirical data that we collected in the course of working with hundreds of different companies:
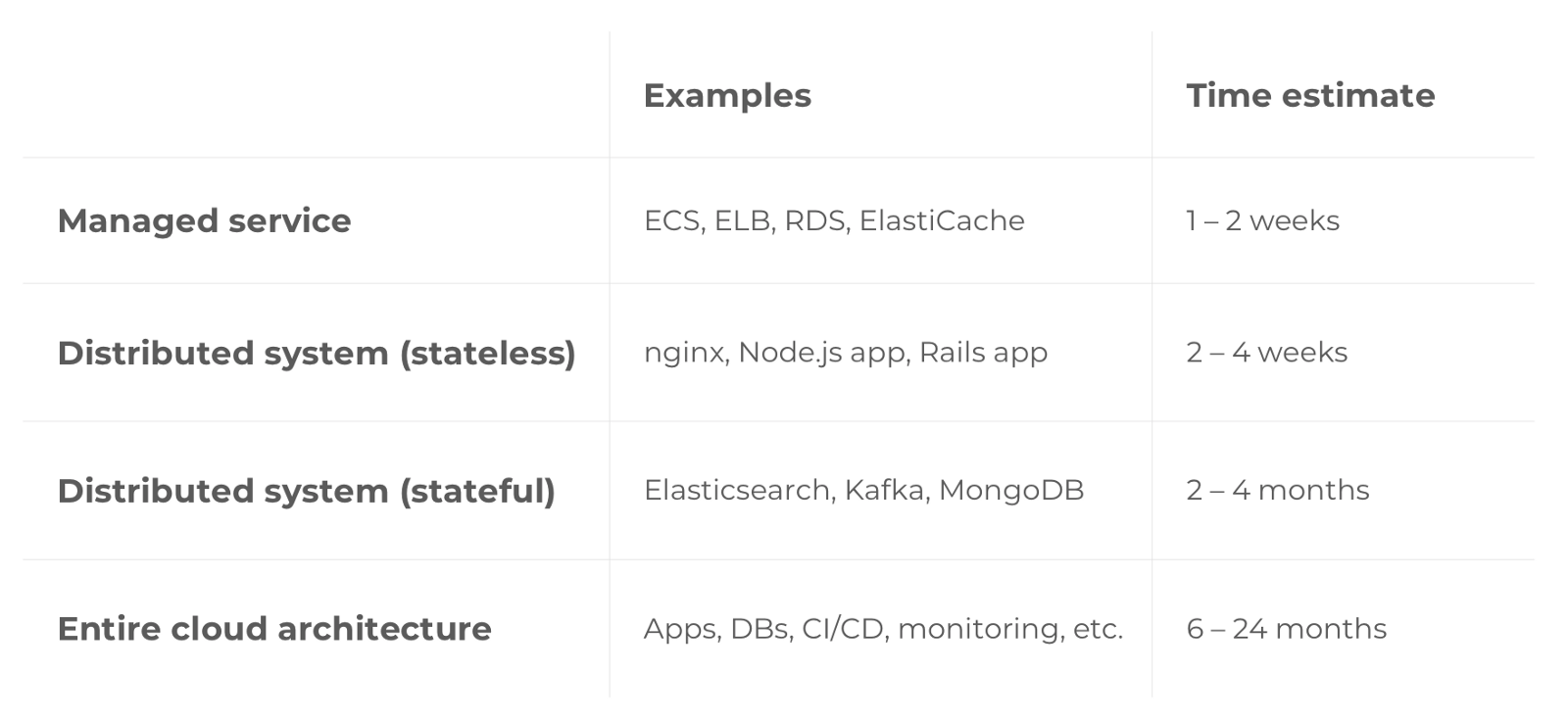
Lesson 1. Checklist for production level infrastructure
DevOps projects always take longer than you expect. Is always. Why is that?
The first reason is the yak cut . Below is a vivid illustration of this phenomenon, (this is an excerpt from the “Malcolm in the Spotlight” series)
The second reason is that the process of creating a production level infrastructure (for example, the infrastructure on which you would put your company) consists of thousands of small details. The overwhelming majority of developers are not aware of these details, therefore, when evaluating a project, you usually forget about many critical (and time-consuming) tasks.
To avoid this, each time you start working on a new infrastructure sector, use this checklist:
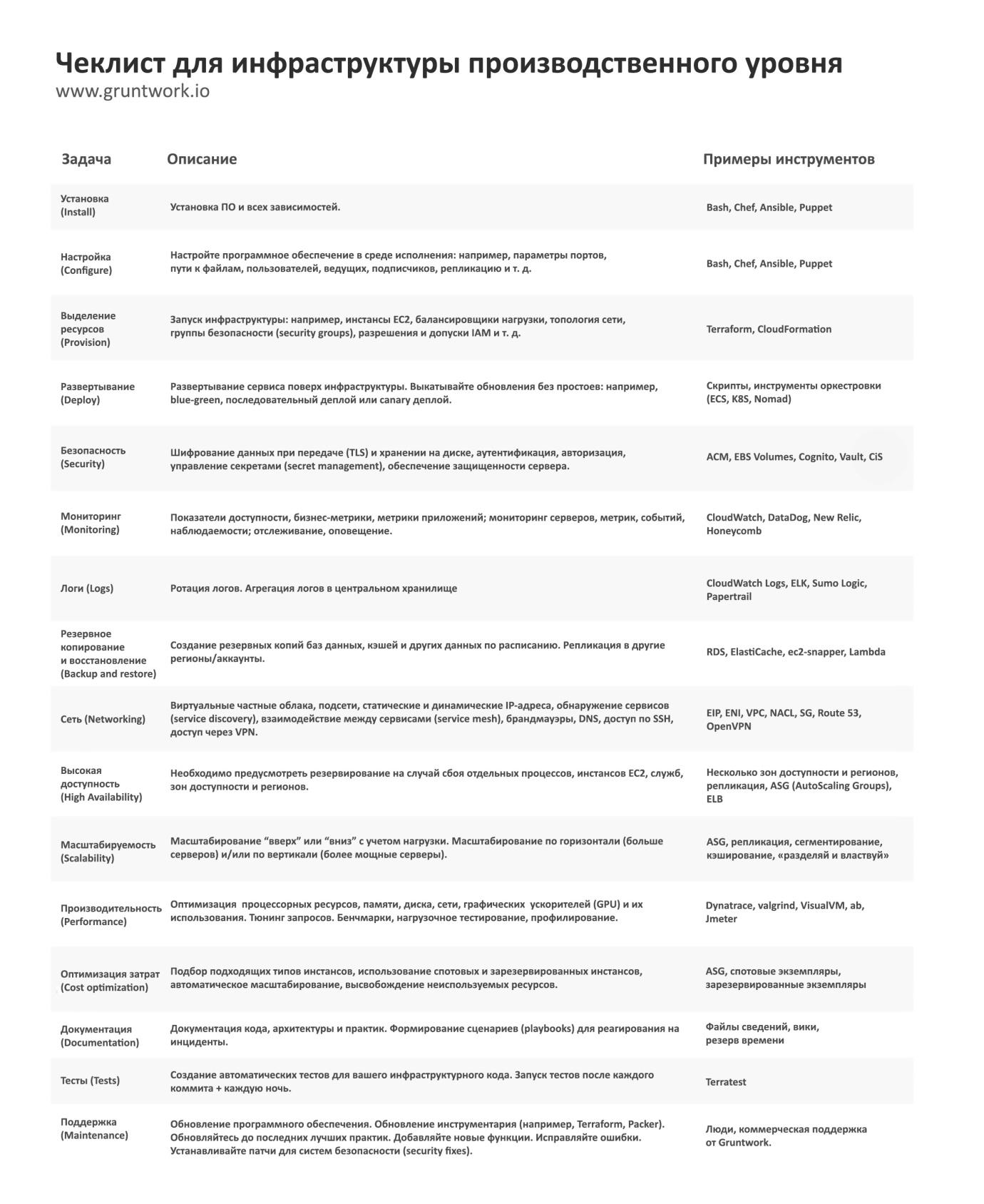
Not all the elements of the list will be needed for each individual section of the infrastructure, but you must consciously and explicitly document which elements you implemented and which ones you decided to skip and why.
Lesson 2. A set of tools
We list the main tools that we at Gruntwork use to create and manage infrastructure (as of 2018):
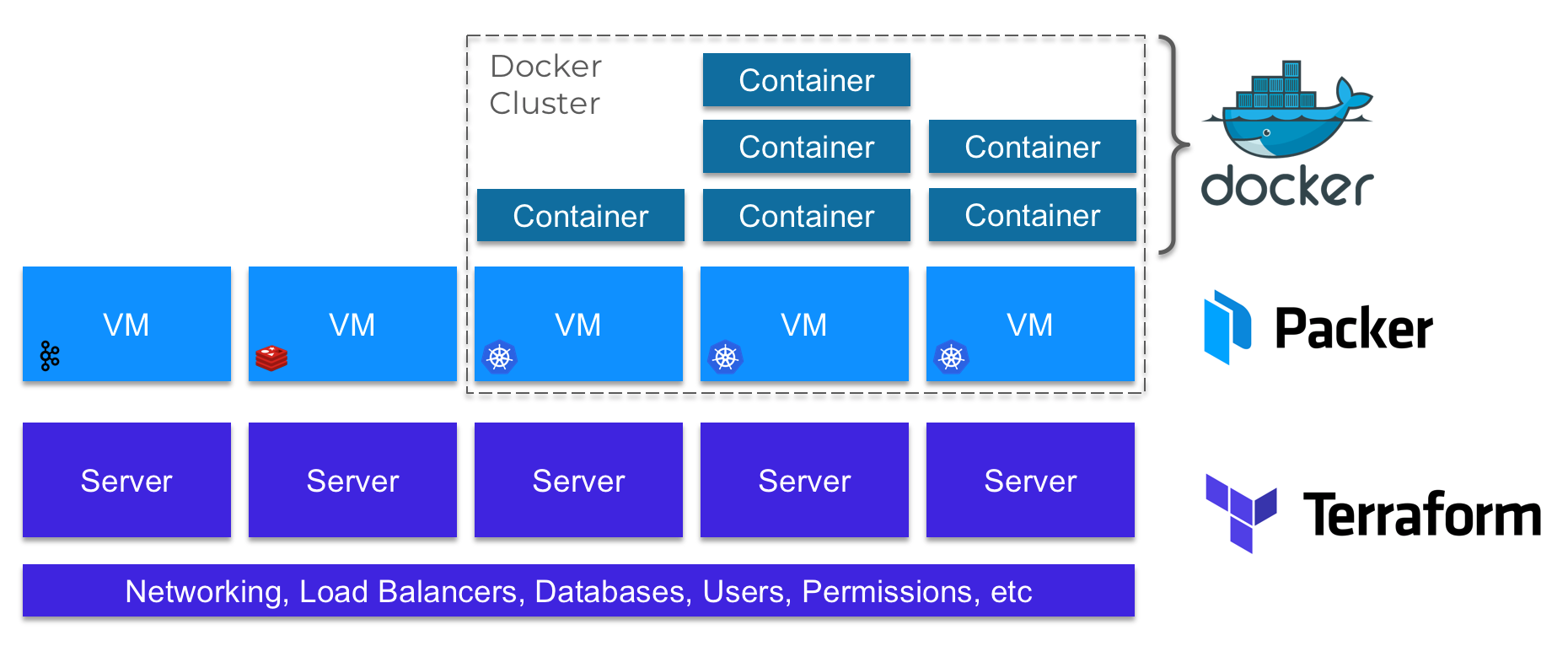
- Terraform . We use Terraform to deploy all the underlying infrastructure, including the network, load balancers, databases, user and permissions management tools, and all of our servers.
- Packer We use Packer to configure and create images of virtual machines that we run on our servers.
- Docker . Some of our servers form clusters where we run applications as Docker containers. For Docker clusters, we mainly use the following tools: Kubernetes , ECS and Fargate .
All of these tools are useful, but this is not the lesson. You need to understand that some tools are not enough. It is also necessary to change the behavior of the team.
In particular, even the best tools in the world will not help your team if it does not want to use them or it does not have enough time to learn how to use them. Thus, the key conclusion is that the use of “infrastructure as a code” is an investment, that is, you will be required to incur certain initial costs. If you invest wisely, you will get big dividends in the long run.
Lesson 3. Large modules are evil.
Newcomers to using “infrastructure as a code” often define their entire infrastructure for all their environments (development environment, intermediate environment, production environment, etc.) in a single file or set of files that are deployed as a whole. In vain.
Here are just some of the disadvantages of this approach:
- Low speed If the entire infrastructure is defined in one place, then the execution of any command will take a long time. We were faced with situations in companies when the
terraform plancommand took 5-6 minutes to complete! - Low security . If you manage the entire infrastructure together, then to change anything you need permissions to access everything. That is, almost every user must be an administrator, and this is also very inconvenient.
- High risks . If you put all the eggs in one basket, then create a situation where one local error can disrupt the entire infrastructure. For example, when making minor changes to an external application in the development environment, a single typo or incorrect command may lead to the deletion of the production database.
- Difficult to understand . The more code is placed in one place, the more difficult it is for one person to understand all this. And when all this is connected, the incomprehensible parts will play a cruel joke with you.
- Difficult to test . Testing infrastructure code is difficult; testing large amounts of infrastructure code is almost impossible. Let's come back to this later.
- Difficult to analyze . The output of commands such as terraform plan becomes useless, as no one bothers to look at thousands of lines. Moreover, code analysis becomes useless.
In short, you must form your code from small autonomous and reusable composite modules. This is not news or discovery. You have heard it a thousand times, albeit in slightly different situations:
“Do one thing and do it well” - Unix philosophy.
“The first rule of functions is that they should be small. The second rule says that functions should be even smaller. " - “Clean Code”
Lesson 4. Infrastructure code without automatic tests is defective.
If your infrastructure code does not have automatic tests, it does not work correctly. You just do not know about it. But testing the infrastructure code is difficult. You do not have a “local host” (for example, you cannot deploy an AWS VPC virtual private cloud on your laptop), or real “unit tests” (for example, you cannot isolate Terraform code from the “outside” world, because times and is intended to communicate with the outside world).
Therefore, in order to properly test the infrastructure code, you usually have to deploy it in a real environment, run the real infrastructure, test the code performance, and then break it (for a description of this testing style: see Terratest, this is an open source library that includes tools for testing the Terraform code , Packer and Docker, working with APIs AWS, GCP and Kubernetes, executing shell commands locally and on remote servers via SSH, and many other features). Thus, testing the infrastructure, we must slightly redefine the conditions:
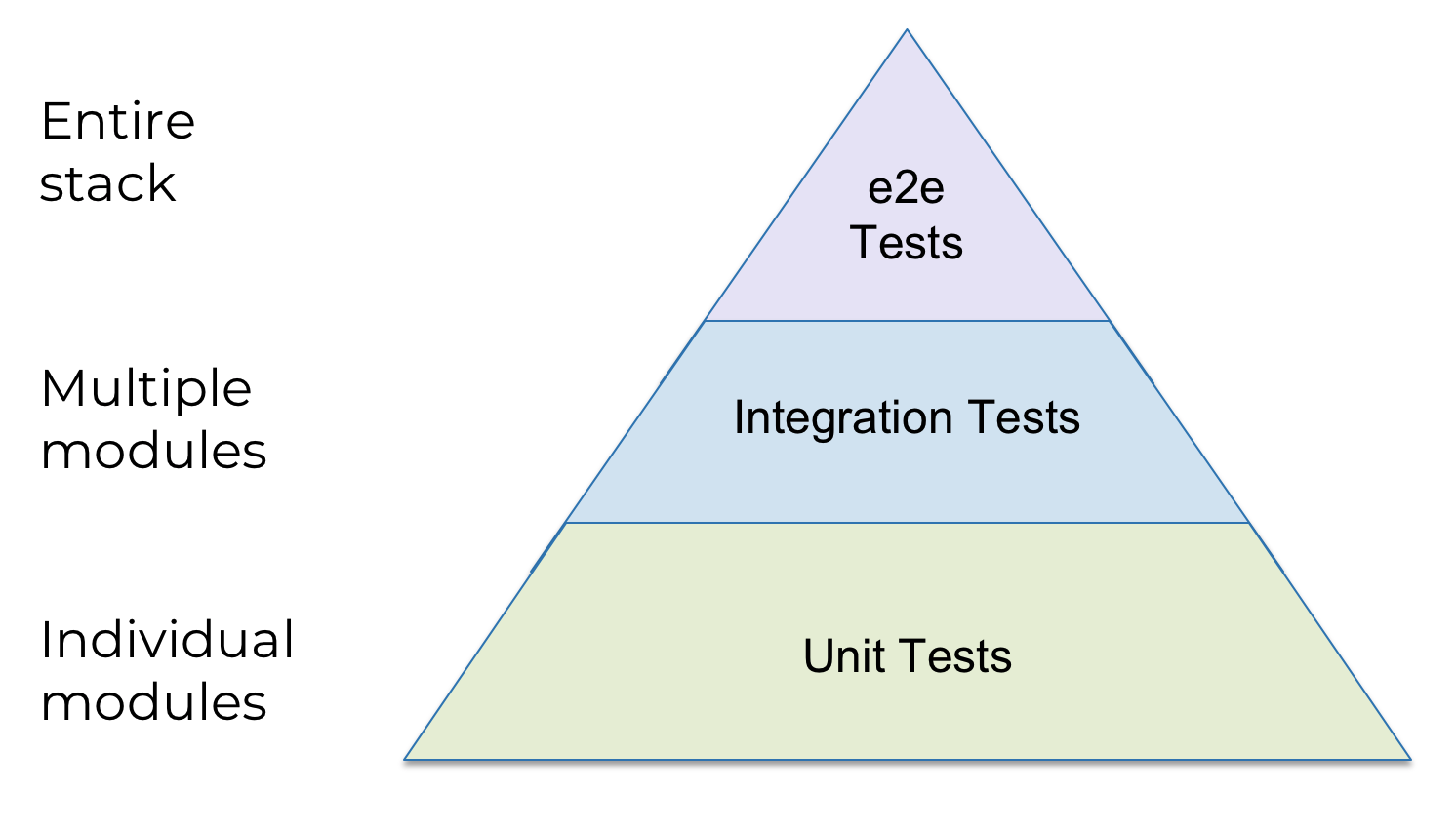
Unit tests deploy and test one or more closely related infrastructure modules of the same type (for example, modules for a single database).
Integration tests deploy and test several different types of infrastructure modules to verify that they work together correctly (for example, database modules and web service modules).
End-to-end tests (e2e) deploy and test the entire architecture.
Please note that the diagram is a pyramid: we have a lot of unit tests, fewer integration tests and very few e2e tests. Why? It depends on the duration of each type of test:
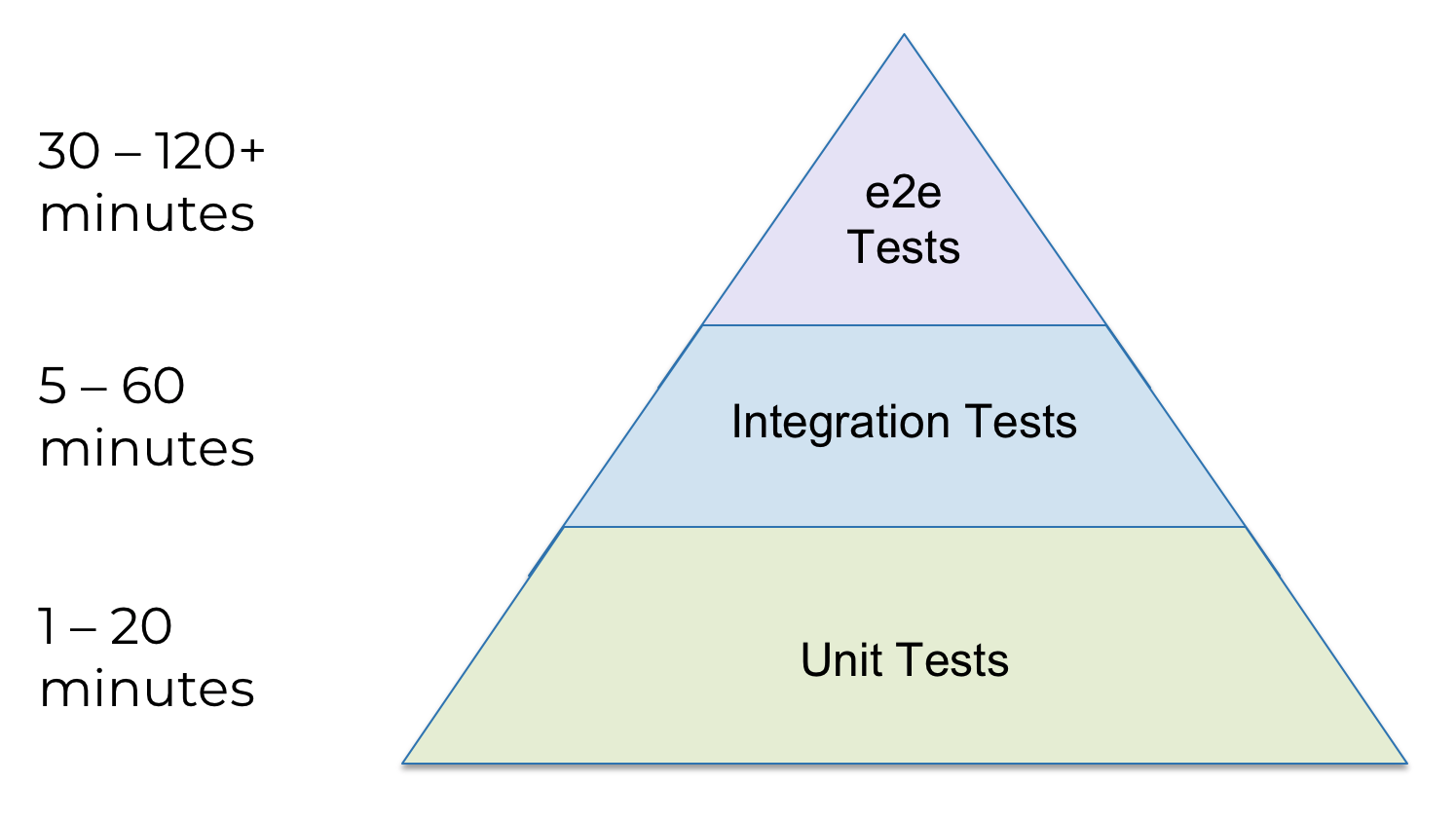
Infrastructure tests take a long time, especially at the upper levels of the pyramid, and, naturally, you will want to find and correct as many errors as possible at the very bottom. For this you need:
- Create small and simple stand-alone modules (see Lesson 3) and write a lot of unit tests for them — make sure they work correctly.
- Combine these small, simple and proven blocks to create a more complex infrastructure that you test with fewer integration and E2E tests.
Lesson 5. Release process
To summarize all of the above. Here is how you will create and manage the infrastructure:
- Check with the production level infrastructure checklist and make sure you are working in the right direction.
- Define your “infrastructure as code” using tools such as Terraform, Packer and Docker. Make sure your team has enough time to master these tools (see DevOps Resources ).
- Create code from small and stand-alone composite modules (or use standard modules from the Infrastructure as Code Library ).
- Prepare automated tests for your modules using Terratest .
- Perform a request to include changes for reviewing your code.
- Release the new version of the code.
- Copy the new version of the code from one environment to another.
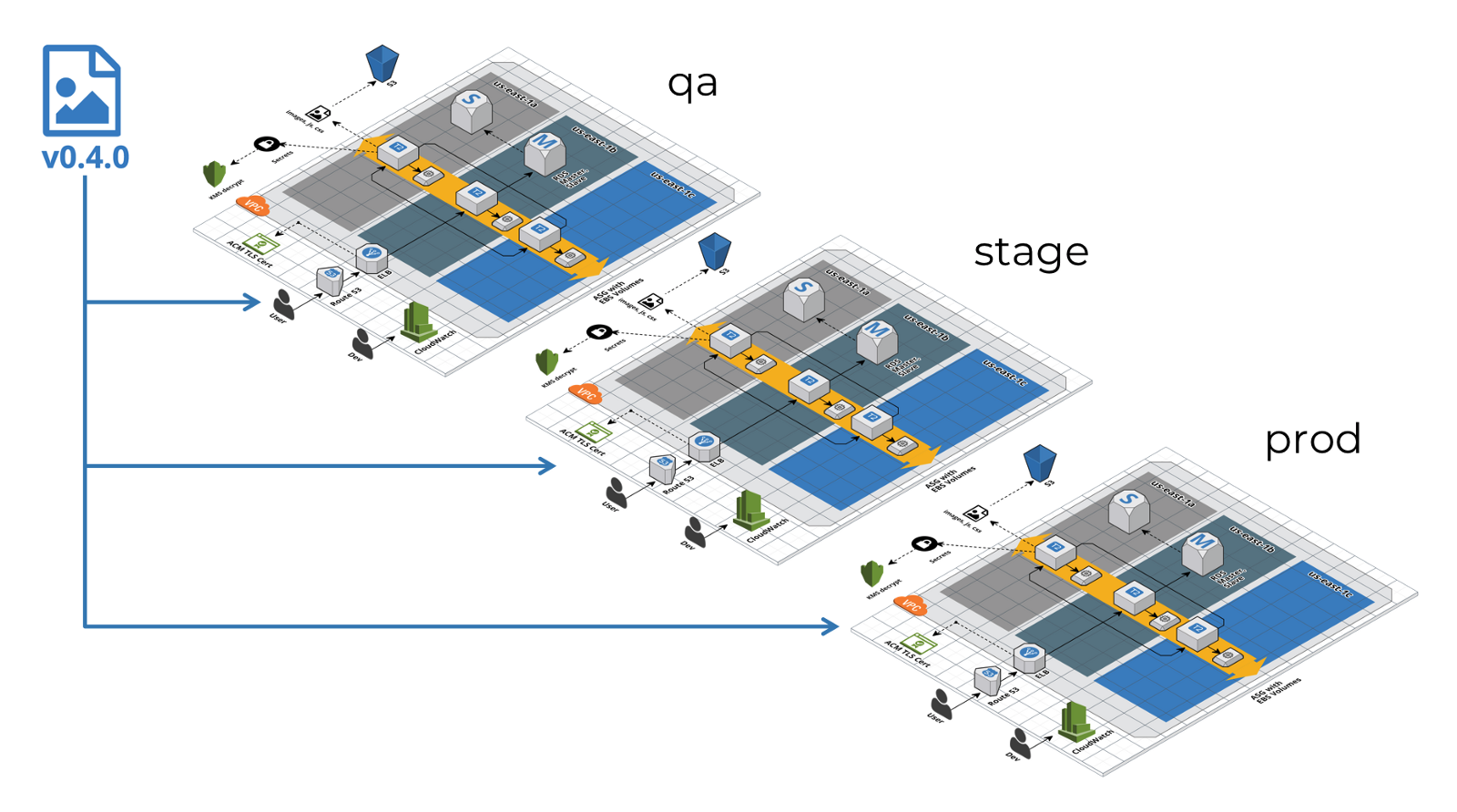
')
Source: https://habr.com/ru/post/434774/
All Articles