Wii, Wai, Wai, Frond - “difficulties of translation”, or what lies behind the new platform SAS Viya (Frond)

On the net you can find a huge number of various articles about the methods of using algorithms of mathematical statistics, about neural networks and in general about the benefits of machine learning. These directions contribute to a significant improvement in human life and a bright future for robots. For example, plants of a new generation, capable of working in whole or in part without human intervention or autopilot.
Developers combine combinations of these approaches and machine learning methods in different directions. These directions subsequently receive names, original and not so, for example: IOT (Internet Of Things), WOT (Web Of Things), Industry 4.0 (Industry 4.0), Artificial Intelligence (AI) and others. These concepts are united by the fact that their description is top-level, that is, neither specific tools and technologies, nor systems that are already ready for implementation, are considered, and the main goal is to visualize the desired result. But technologies already exist, although they often do not have a single platform.
Solutions provide both large software vendors: SAS, SAP, Oracle, IBM, and small startups that make up strong competition for major players, as well as open source solutions - open source solutions. All this diversity greatly complicates the quick and effective implementation of the task, as it requires time-consuming integration of various systems among themselves, the enormous work of developers to create good models of machine learning and the future implementation of these solutions in production. But at the same time, the main criterion for the success of any innovative project that changes the company's approach to business often requires quick proof of success and viability, otherwise no one will risk launching it. And this is impossible without using a single platform that allows you to quickly complete the entire training cycle (search, collect, clean up, consolidate) data and get final results in the form of high-quality analytics (including using machine learning algorithms), and, as a result, profits For the company.
About SAS
Many may agree that SAS has a high position in the market for advanced analytics solutions. Reviews of SAS solutions may be different, but not indifferent, as evidenced by the presence of a large number of customers in Russia and in the world. Largely due to ready-made algorithms and models that can be easily and quickly implemented in the company and quickly get the result. Much has been written about this in the first article in the SAS company blog - you can read it here . This article describes the prerequisites for the success of SAS and its history. But the IT and business community is rapidly developing and becoming more demanding of tools, so SAS has released a new analytical platform SAS Viya. This platform includes all the best that has been created in the company SAS since its inception to the present, in order to predetermine the current trends of the class of solutions for advanced analytics. Returning to the beautiful names and definitions, SAS Viya provides a single platform for such a direction as self-service data science using in-memory capabilities, which was developed using distributed (cloud) computing approaches and micro-service architecture. So, this article opens a series of articles about the SAS Viya platform, in order to sort out what Viya is, what it can and how to use it.
Difficulties of choice
We have already found out that there are now a huge number of products from well-known vendors and smaller players on the market, as well as open source, which allows us to solve various analytical tasks in all areas of business. What criteria, other than price, should be taken into account when deciding on the choice of a particular platform?

Let's start with the fact that now the business user is becoming increasingly involved in a full analytical cycle and requires more independence from IT. Criteria that are understandable to these users come to the forefront - ease of use (common interfaces), minimization of learning for new systems (less code, more graphics), performance (in terms of analytics, the ability to quickly get results on large arrays of data) for work. The time of the “black” screens is running out, the terminal windows, although in a different form, are still available and allow you to write and debug the code on the go, but most of the functions can already be implemented as blocks in the graphical user interface, which opens the door for users levels to work with advanced analytics (although mathematics is still desirable to know).
The second trend that inevitably conquers the markets is cloud technologies. From the point of view of companies, this is an opportunity for flexible management of available resources for any projects. There is a lot of research about the time of complete replacement of classical solutions by cloud technologies. But here it is important to understand that cloud computing is not only iron, which lives somewhere far away in external data centers, but also the approach itself of flexible provision of various services in the form of services that can be obtained quickly and without the need to build or rebuild a complex IT infrastructure.
Another trend is the use of Big Data technologies. Yes, and the use of the entire Hadoop ecosystem as a whole with its own languages and technologies, as well as other available open source systems that provide interfaces for working with data, such as R, Python, and others. In this area there is no point in competing, but it makes sense to have technologies for integration with this ecosystem. Or not just integrate, but use the capabilities of this ecosystem as in the case of the SAS Hadoop Embedded Process or using Kafka to build High Availability for ESP systems (SAS Event Stream Processing). And sometimes even improve and accelerate, such as the ability to run the code on R on the CAS engine in SAS Viya.
Universal platform
Demand creates supply and SAS Viya is not an exception to the rule. If you refer to the official definition of SAS Viya, which was given by Jim Goodnight (very much reduced, but the meaning is preserved) during the announcement in 2016 at the global SAS forum, SAS Viya is: "A cloud system that uses distributed computing approaches ... and gives single platform for analytics "
Well, if you briefly formulate the idea and goals of the SAS Viya platform, then this is a universal platform for any kind of analysis at all stages of a project, from data preparation to the application of complex machine learning algorithms. There are 4 blocks of tasks:
1. Data preparation
2. Visualization and data exploration
3. Predictive analytics
4. Advanced analytics in the form of machine learning algorithms
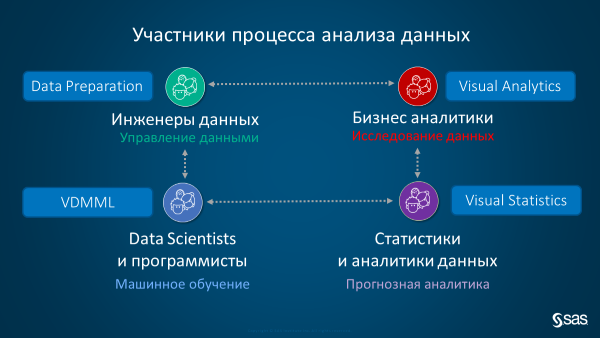
Information for readers
Since it is rather difficult to tell everything within one article without harming important nuances, these steps will be discussed in the following articles with examples. In this article, we will look at the important topic of the SAS Viya engine, which provides fast analytical tools. Articles about modern and beautiful interfaces are next in line.
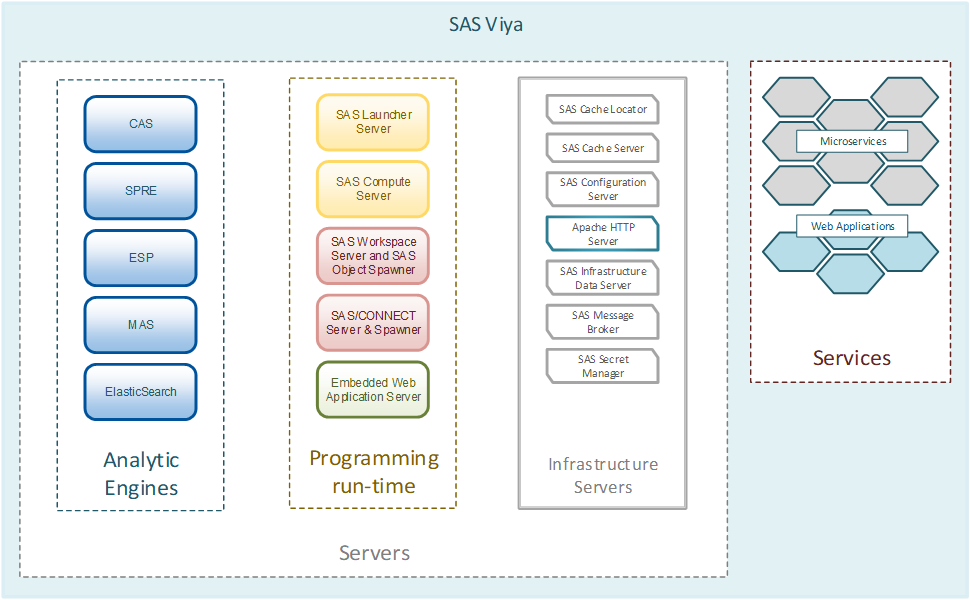
The basis of the platform SAS Viya
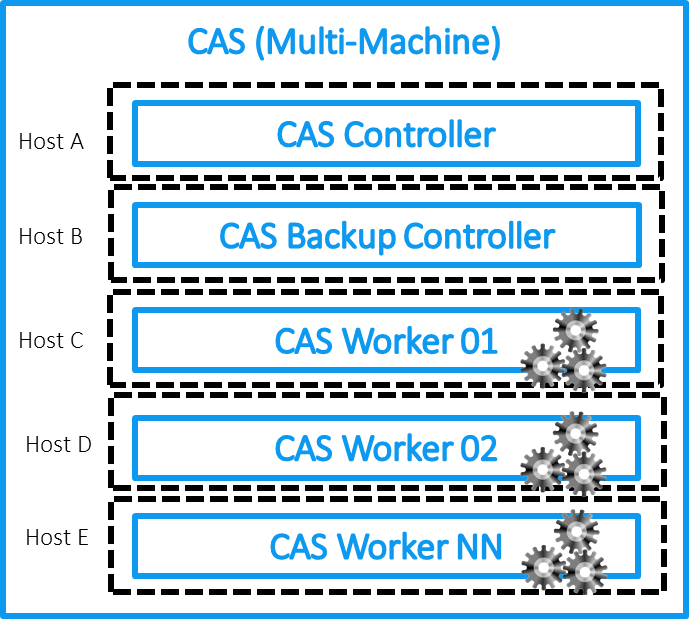
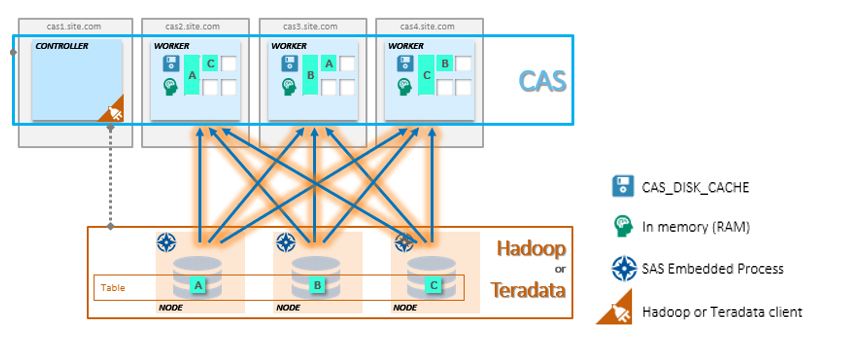
SAS Viya has several key features to start with. Those who have worked with SAS solutions know that the SAS Base is based on the special analytical language SAS Base, which performs analytical tasks on its engine. It can be used in a Grid configuration on a cluster or on one powerful computer. Here lies the main difference between SAS Viya and the classic analytics solutions SAS 9. At the heart of SAS Viya is a new unique CAS (Cloud Analytics Service) data processing engine. Two key features: the first is in-memory technology, which performs all operations with data in RAM, and the second is the distributed computing approach. CAS can work on the same host, but is optimized to work on a cluster of machines - a controller and data processing servers, which allows you to store and process data on different cluster nodes to parallelize the load (ideologically, the approach is very close to the concept of Hadoop systems). If you map the CAS architecture, we get the following image for an MPP or SMP installation:

Why Cloud?
SAS in developing the platform Viya and CAS in particular, took advantage of the concept of cloud computing. They can be divided into 4 groups:
1. Accessibility through a large set of APIs for different clients. For SAS, this is a big step forward. There are no more restrictions on using SAS Base for analytics only. You can use Python (for example, from Jupiter Notebook), R, Lua, etc., which will be executed in CAS on the SAS Viya platform.
2. Elasticity. You can easily scale the system by connecting / disconnecting CAS cluster nodes. Applications are accessible via the web and organized as microservices. They are independent of each other in terms of installation, upgrade and operation.
3. High availability. CAS uses a system of data mirroring between cluster nodes. One data set is stored on multiple nodes, which reduces the risk of data loss. Switching in case of failure of one of the nodes occurs automatically with preservation of the status of the task, which is often critical for heavy analytical calculations.
4. Enhanced security. Since the cloud can be obtained from a public provider, the implementation must meet more stringent requirements for the reliability of data transmission channels.
You can deploy the Viya platform anywhere - in the cloud, on a dedicated machine in your data center, in a cluster of any number of machines. Resiliency of the solution is automatically provided.
')
How does CAS work?
I will analyze the work of CAS using the example of an MPP installation. SMP simplifies, but keeps the CAS working principles. In real life, SMP can be used as test local environments for model testing and then transferring development to an MPP platform for better performance.
Let's look again at the high-level CAS architecture on SAS Viya:
If we talk about CAS, then it consists of a controller, in a different way, a master node (plus there is an opportunity to allocate one more node for the backup node of the controller) and working nodes. The master node stores meta information about data located on cluster nodes, and is responsible for distributing requests to these nodes (CAS Workers) that process and store data. Separately, a server is allocated that hosts analytical services and additional modules necessary for the operation of the platform. They can also be several, depending on the tasks. For example, you can use on a separate machine as part of the Viya installation a server for SPRE (SAS Programming Runtime Environment), which will allow you to run classic SAS 9 tasks on the Viya platform using both CAS and SPRE.
There is an interesting configuration that extends the use of CAS on the Viya platform, and justifies the first letter of its name Cloud:
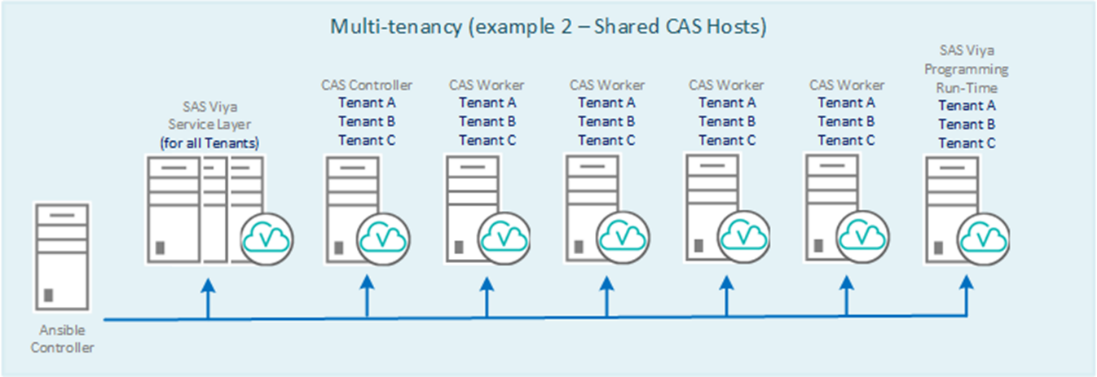
Multi-tenancy (multitenancy) makes it possible to share resources and data between departments. At the same time, "tenants" are given a single interface to access the platform and provide a logical separation of the various functions of the Viya platform. There are a lot of options. Perhaps this issue will be discussed in a separate article.
How to deal with the reliability of the RAM and how to load data into the CAS?
Since we are talking about analytics, and even more so about advanced solutions for advanced analytics, it is clear that we are talking about large amounts of data. And an important part of the process is the fast loading of data into RAM to perform operations with them and ensuring high availability of this data.
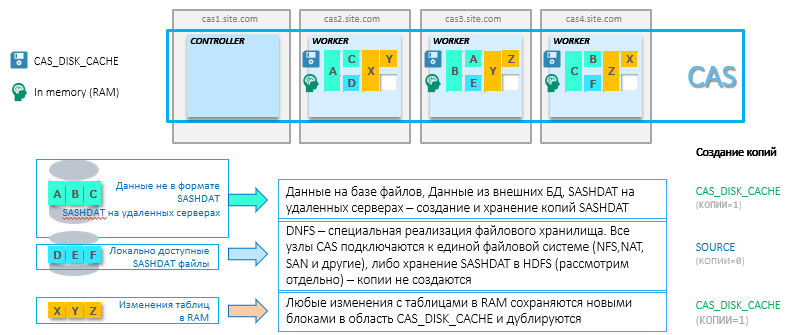
Any in-memory system for reliability requires backup data that are in RAM. RAM does not know how to maintain a state when the power is turned off, plus all data may not fit in the RAM area, and a mechanism is needed to quickly reload data into RAM. Therefore, for tables that are loaded into CAS for analytics, copies are made in the permanent memory area of a special SASHDAT format. To ensure high availability, these files are mirrored on several cluster nodes. This parameter can be customized. The idea is that if a node is lost, the data will be automatically loaded into the RAM on the neighboring node from a copy of the SASHDAT file. The storage area for these copies in the CAS structure is called CAS_DISK_CACHE .
CAS_DISK_CACHE is an important part of the CAS, which is needed not only to ensure fault tolerance, but also to optimize memory usage. The diagram below shows the different ways of storing SASHDAT and the principle of loading data into RAM. For example, datasset A is obtained from an Oracle database and is stored on one CAS node in RAM and on disk. Plus this dataset A is duplicated on another node only on the hard disk. There are many options (some of them do not require additional backup - this will be discussed below), but the main idea is to always have a copy for quick recovery of previously loaded data into RAM. By the way, if two parameters are set: MAXTABLEMEM = 0 and COPIES = 0 at the session level, the data will live only in RAM.
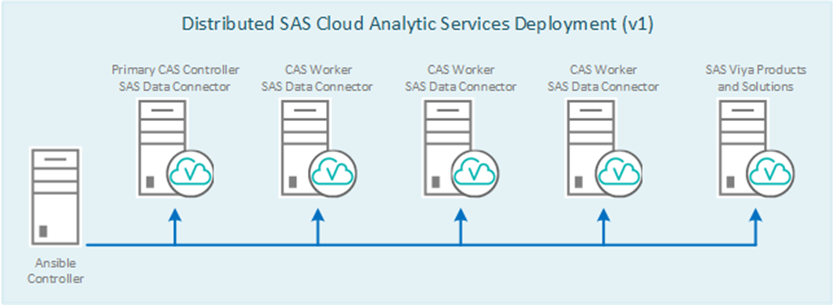
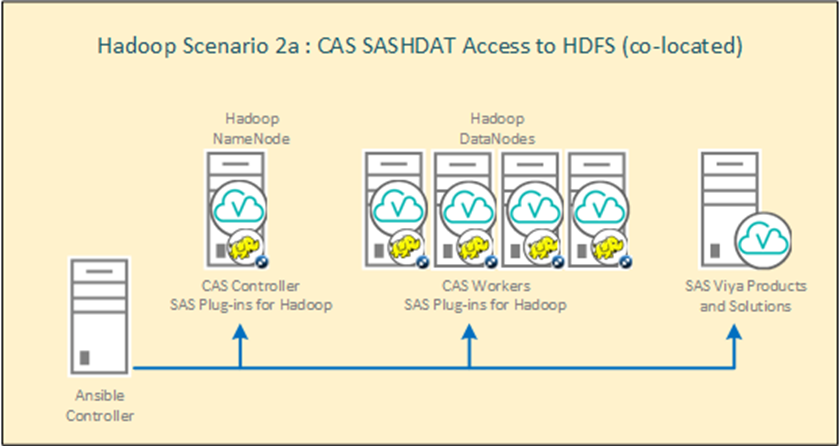
Separately, I want to consider an interesting configuration of CAS with Hadoop. To use this CAS configuration with Hadoop, the system requires the installation of SAS Plugins for Hadoop. The main idea of the approach is that the nodes of the Hadoop cluster become also the working nodes of the CAS. Data is drawn into RAM directly from files in hdfs without a network load. This is the best option in terms of performance. You can use Hadoop either only for storing SASHDAT files (HDFS on a cluster will play the role of CAS_DISK_CACHE –reservation at HDFS level), or together with other data. Resource allocation on the Hadoop cluster is done via YARN. The scheme for installing CAS on a Hadoop cluster:
Loading
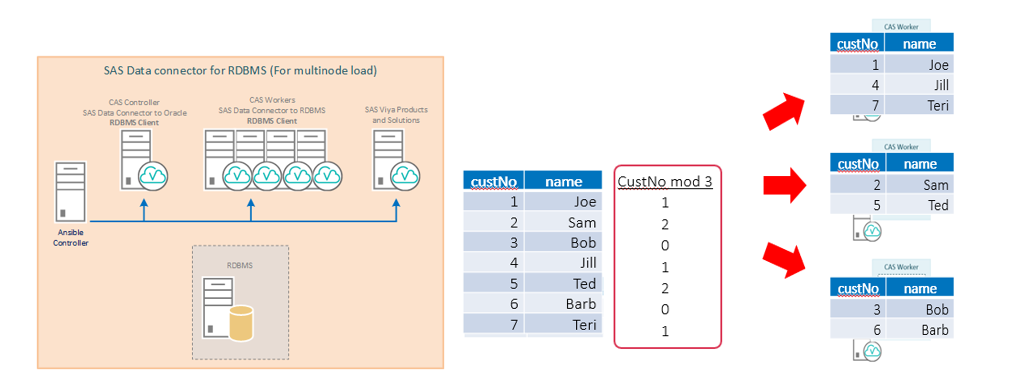
Data loading is simple. We can point various sources to the CAS input. They can be loaded either in one stream or in parallel. Since relational databases are used much more often as sources, we will look at the topic of loading data into a CAS from an RDBMS. To optimize data loading in a CAS cluster, it is advisable to install the source database client software on each node of the cluster. In this case, each cluster CAS node will receive its portion of data in parallel mode. When installing the client only on the controller, all data will be transmitted through the CAS controller.
For example, if you set the parameter numreadnodes = 3, the table will be automatically split into 3 pieces of data to load into different CAS nodes - in this case, the distribution of data will be based on grouping by the first numeric column using the mod 3 operation.
If Hadoop or Teradata is used as the source, then using the Embedded Process for Hadoop or Teradata, the download will be performed directly from each node of the Hadoop or Teradata cluster. Note that in the case of a separate Hadoop cluster installation (CAS is not installed on Hadoop nodes), the CAS_DISK_CACHE area will be created on the CAS cluster.
How to start working with CAS?
Important terms in the work of CAS are libraries and sessions. When you start working with CAS, the first thing that is created is a session. It can be defined manually when working through SAS Studio, or it is automatically created through the available graphical interfaces on SAS Viya when connected to CAS. Within a session, all data and transformations that are defined in new libraries are created by default with a local scope. The data (defined in caslib) and the results of the steps of the local session are visible only in this session. In case we need to make the results public, we can override caslib with the global parameter and the promote operator, and the data will be available from other sessions. Libraries that are already defined with the global parameter will be available from any sessions. This is done for optimal resource sharing and data access rights management. After disconnecting from the local session, all temporary data is deleted if caslib was not redefined in global. We can configure the TIMEOUT parameter to delete data when disconnected from a session, to avoid possible losses during short-term network failures, or to return to this session for further analysis (for example, you can set the TIMEOUT parameter to 3600 seconds, which will give us 60 minutes of time to return to session). Plus, the data can be saved at any conversion step to a special SASHDAT format or to an available database to which the connection is configured with a simple SAVE operator.
The caslibs libraries describe the data sets that will be available in CAS. When creating a caslib, the connection type and connection parameters are indicated. In the caslib definition, we point directly to the data source and the target area in in-memory. Also at the caslib level it is convenient to set permissions for user groups to the data described in caslib. This is done in the graphical interface.
Example description of caslib for different types of sources:
caslib caspth path="/data/cust/" type=path; caspth – , path - caslib pgdvd datasource=( srctype="postgres", username="casdm", password="xxxxxx", server="sasdb.race.sas.com", database="dvdrental", schema="public", numreadnodes=3) ; caslib hivelib desc="HIVE Caslib" datasource=(SRCTYPE="HIVE",SERVER="gatekrbhdp01.gatehadoop.com", HADOOPCONFIGDIR="/opt/sas/hadoop/client_conf/", HADOOPJARPATH="/opt/sas/hadoop/client_jar/", schema="default",dfDebug=sqlinfo) GLOBAL ; After determining the caslib, we can load data into RAM for further processing. Example of data loading caslib hivelib:
proc casutil; load casdata="stocks" casout="stocks" outcaslib="hivelib" incaslib="hivelib" PROMOTE ; quit; /* casdata – ( hive), casout – CAS, outcaslib – caslib, , incaslib – caslib, .*/ /* in/out caslib , */ Within each session, requests (actions) are executed sequentially. This is important when writing code manually, but when using graphical interfaces available on Viya, you can not think about it. Client applications with a GUI themselves create separate sessions for performing steps in parallel mode.
Fully graphical interfaces and approaches to work through them, we will look at the following articles. Here I will add screenshots of steps to create caslib DM_ORAHR and load data into RAM via GUI:
This is just the beginning.
At this point I finish the part about CAS and return to the Viya platform. Since Viya is created for business users, in the process of work you will not need to deeply understand the specifics of the work of CAS. For all operations, there are convenient graphical interfaces, and CAS will ensure fast operation of all analytical steps through in-memory and distributed computing.
Now you can go to the user interfaces that are available on Viya. At the moment there are a lot of them, and the number of products is constantly increasing. At the beginning of the article they were divided into 4 groups, which are needed for a full analytical cycle. Coming back to the main idea, Viya is a unified platform for data research and advanced analytics. And work begins with the preparation and retrieval of this data. And in the next part of the series of articles about Viya, I will talk about the data preparation tools that are available to analysts.
Instead of the conclusion, the name Viya comes from the word Via (from English. “By” or “through”). The main idea of this name is in a simple transition from the classic SAS 9 solution to a new platform, which is designed to take analytics to a new level.
Source: https://habr.com/ru/post/434432/
All Articles