Distributor ok.ru/music

I work in a team of the Odnoklassniki platform and today I’ll tell you about the architecture, design and implementation details of the music distribution service.
The article is a transcript of the report on Joker 2018 .
Some statistics
First, a few words about OK. This is a giant service that is used by more than 70 million users. They are served by 7 thousand machines in 4 data centers. Recently, on traffic, we broke through the 2 TB / s mark without counting numerous CDN sites. We squeeze the maximum out of our hardware, the most loaded services serve up to 100,000 requests per second from a four core node. At the same time, almost all services are written in Java.
In OK, many sections, one of the most popular - "Music". In it, users can upload their tracks, buy and download music in different qualities. The section has a wonderful catalog, recommendation system, radio and much more. But the main purpose of the service, of course, is to play music.
')
The distributor of music is engaged in data transfer to user players and mobile applications. It can be caught in the web inspector, if you look at requests to the domain musicd.mycdn.me. API distributor is extremely simple. It responds to HTTP
GET requests and issues the requested track range.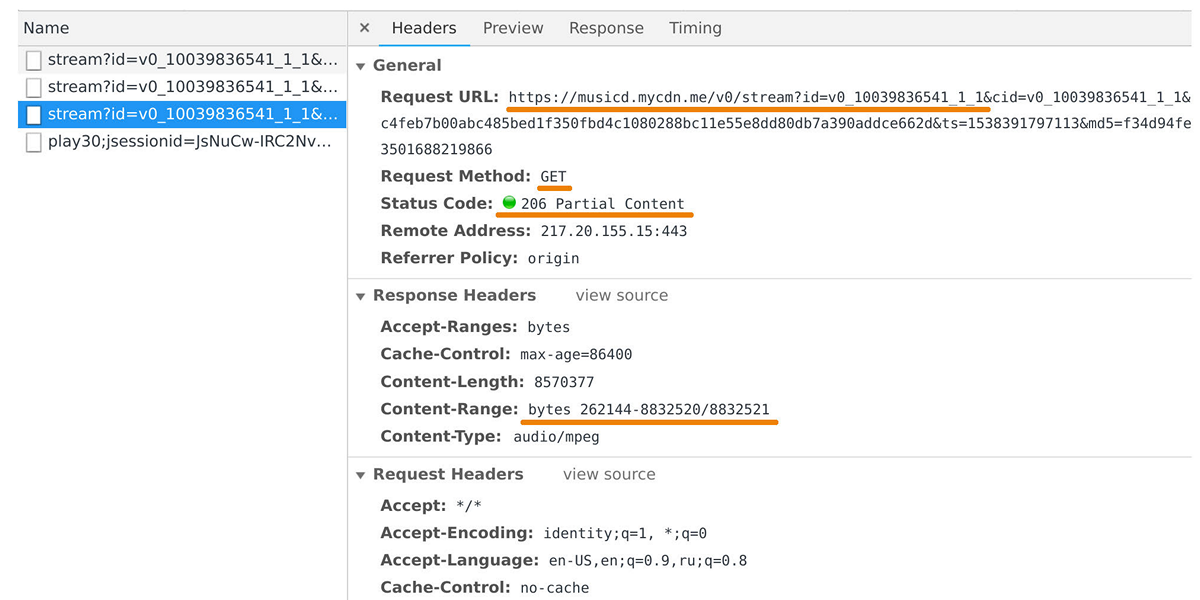
At peak load reaches 100 Gb / s through half a million connections. In fact, the music distributor is a cache front-end in front of our internal storage of tracks, which is based on One Blob Storage and One Cold Storage and contains petabytes of data.
Since I started talking about caching, let's look at the playback statistics. We see a pronounced TOP.
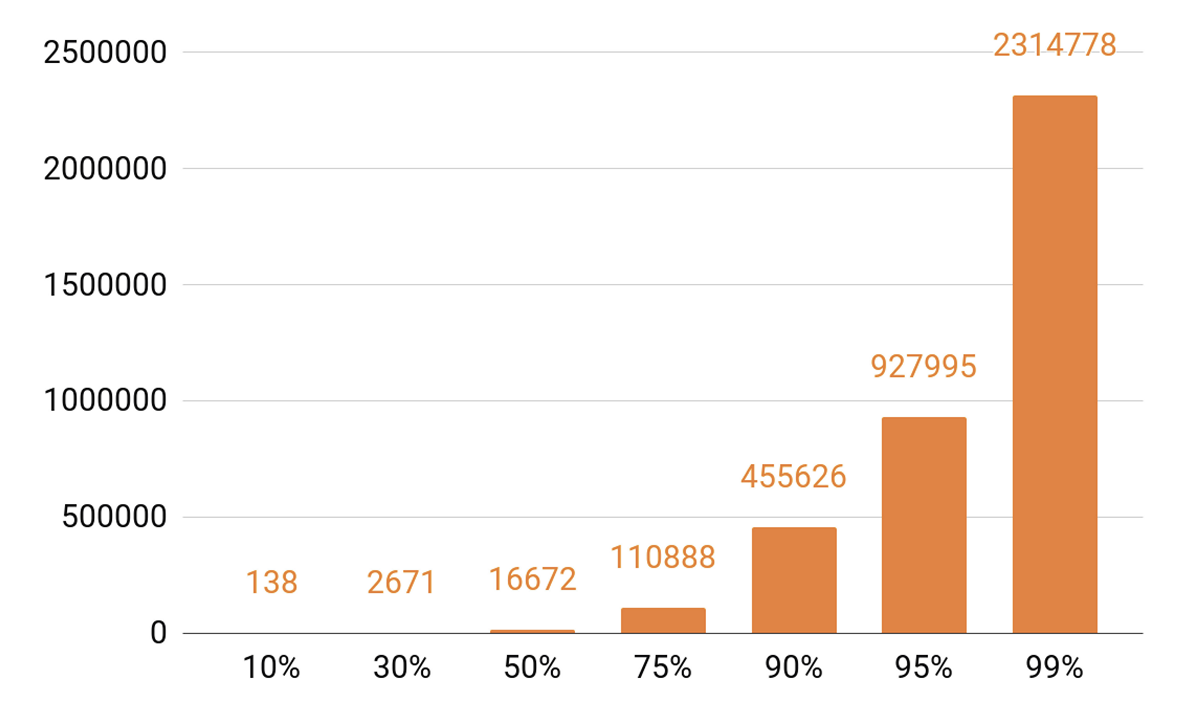
About 140 tracks cover 10% of all auditions in a day. If we want our caching server to have a hit hit of at least 90%, then we need to put half a million tracks into it. 95% - almost a million tracks.
Distributor Requirements
What goals did we set when developing the next version of the distributor?
We wanted one node to hold 100 thousand connections. And these are slow client connections: a bunch of browsers and mobile applications via networks with varying speeds. At the same time, the service, like all our systems, must be scalable and fault-tolerant.
First of all, we need to scale the bandwidth of the cluster in order to keep up with the growing popularity of the service and be able to give more and more traffic. You also need to be able to scale the total capacity of the cluster cache, because cache hit directly depends on it and the share of requests that will go into the track repository.
Today it is necessary to be able to scale any distributed system horizontally, that is, add machines and data centers. But we wanted to implement and vertical scaling. Our typical modern server contains 56 cores, 0.5-1 TB of RAM, a 10 or 40 Gbps network interface and a dozen SSD disks.
Speaking of horizontal scalability, an interesting effect arises: when you have thousands of servers and tens of thousands of disks, something constantly breaks. Failure of the discs is a routine, we change them for 20-30 pieces a week. And server failures do not surprise anyone, 2-3 machines a day go under replacement. We had to face data center failures, for example, in 2018 there were three such failures, and this is probably not the last time.
Why am I all this? When we design any systems, we know that they will break sooner or later. Therefore, we always carefully study the failure scenarios of all system components. The main way to deal with failures is to backup using data replication: several copies of data are stored on different nodes.
We also reserve network bandwidth. This is important, because if a component of the system fails, the load on the other components should not be allowed to collapse the system.
Balancing
First you need to learn how to balance user requests between data centers, and to do this automatically. This is in case you need to conduct network work, or if the data center has failed. But balancing is also needed inside data centers. Moreover, we want to distribute requests between nodes not randomly, but with weights. For example, when we post a new version of the service and we want to introduce a new node smoothly into the rotation. Weights also help a lot with load testing: we increase the weight and get much more workload on the node to understand the limits of its capabilities. And when the node fails under load, we quickly zero the weight and remove it from the rotation, using the mechanisms of balancing.
How does the query path from the user to the node, which will return the data, taking into account the balancing?

The user logs in through the website or mobile application and receives the URL of the track:
musicd.mycdn.me/v0/stream?id=...To get the IP address from the host name in the URL, the client refers to our GSLB DNS, which knows about all our data centers and CDN sites. GSLB DNS gives the client the IP address of the balancer of one of the data centers, and the client establishes a connection with it. The balancer knows about all the nodes inside the data centers and their weight. He on behalf of the user establishes a connection with one of the nodes. We use L4 balancers based on NFWare . The node gives the user data directly, bypassing the balancer. In services like a distributor, outgoing traffic significantly exceeds incoming traffic.
If a data center fails, GSLB DNS detects this and promptly takes it out of rotation: it stops giving users the IP address of the balancer of this data center. If a node fails in the data center, then its weight is reset, and the balancer inside the data center stops sending requests to it.
Now consider the balancing of tracks on the nodes inside the data center. We will consider data centers as independent autonomous units, each of them will live and work, even if all the others died. Tracks need to be balanced on the machines evenly, so that there is no load imbalance, and replicate them to different nodes. If one node fails, the load should be distributed equally among the rest.
This problem can be solved in different ways . We stopped at consistent hashing . The entire possible range of track identifier hashes is wrapped in a ring, and then each track is mapped to a point on this ring. Then we more or less evenly distribute the ring ranges between the nodes in the cluster. The nodes that will store the track are selected by hashing the tracks to a point on the ring and moving clockwise.
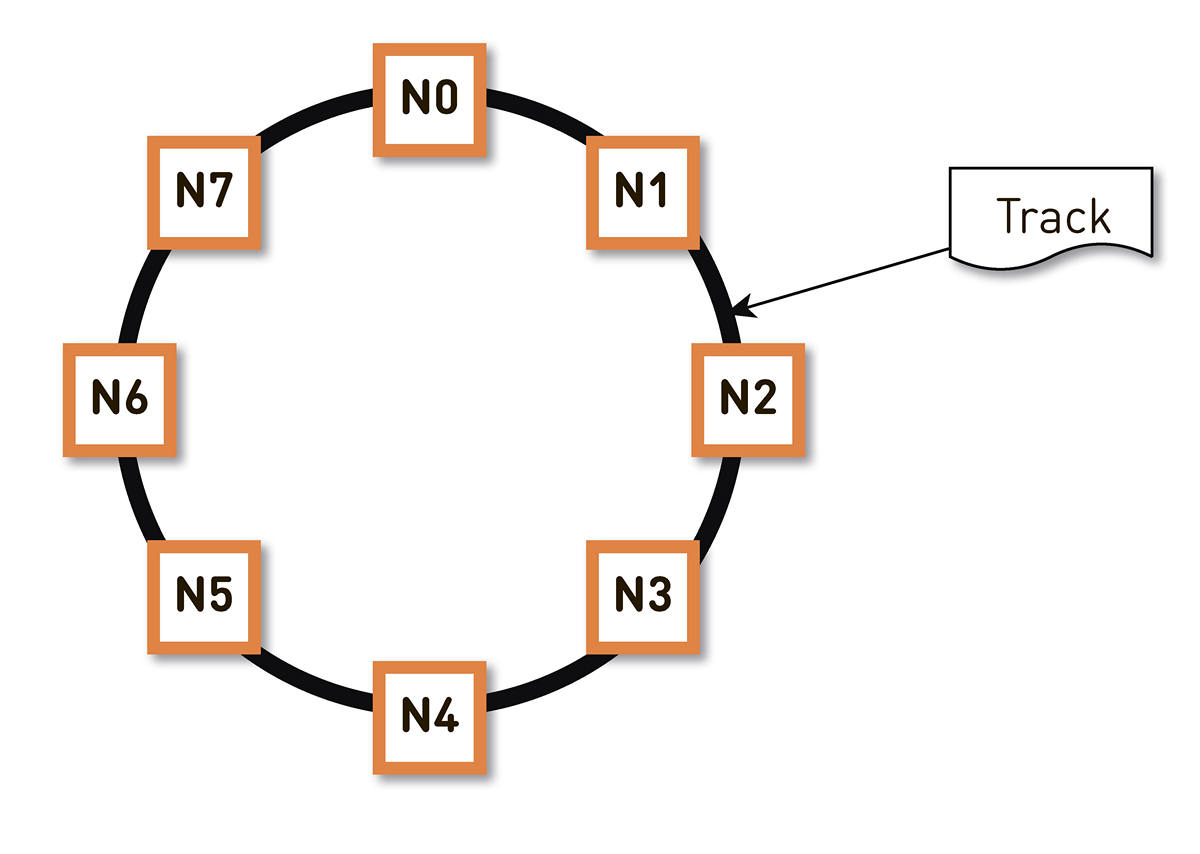
But such a scheme has a drawback: in case of failure of the N2 node, for example, its entire load will fall on the next replica on the ring - N3. And if it does not have a double performance margin - and this is not economically justified - then, most likely, the second node will also have to be bad. N3 with a high degree of probability will develop, the load will be transferred to N4 and so on - a cascade failure will occur along the entire ring.
This problem can be solved by increasing the number of replicas, but then the total useful capacity of the cluster in the ring decreases. Therefore, we do otherwise. With the same number of nodes, the ring is divided into a much larger number of ranges, which are randomly scattered around the ring. Replicas for the track are selected by the above algorithm.

In the example above, each node is responsible for two ranges. If one of the nodes fails, its entire load will fall not on the next node around the ring, but will be distributed between two other nodes of the cluster.
The ring is calculated on the basis of a small set of parameters algorithmically and deterministically at each node. That is, we do not store it in some kind of config. We have more than one hundred thousand of these ranges in production, and in case of failure of any of the nodes, the load is distributed absolutely evenly among all other live nodes.
How does track output to a user in a consistent hashing system look like?
The user through the L4-balancer falls on a random node. The choice of the node is random, because the balancer knows nothing about the topology. But then every replica in the cluster knows about it. The node that receives the request determines whether it is a replica for the requested track. If not, it switches to proxy mode from one of the replicas, establishes a connection with it, and it searches for data in its local storage. If the track is not there, the replica pulls it out of the track repository, saves it to the local repository and gives the proxy, which forwards the data to the user.
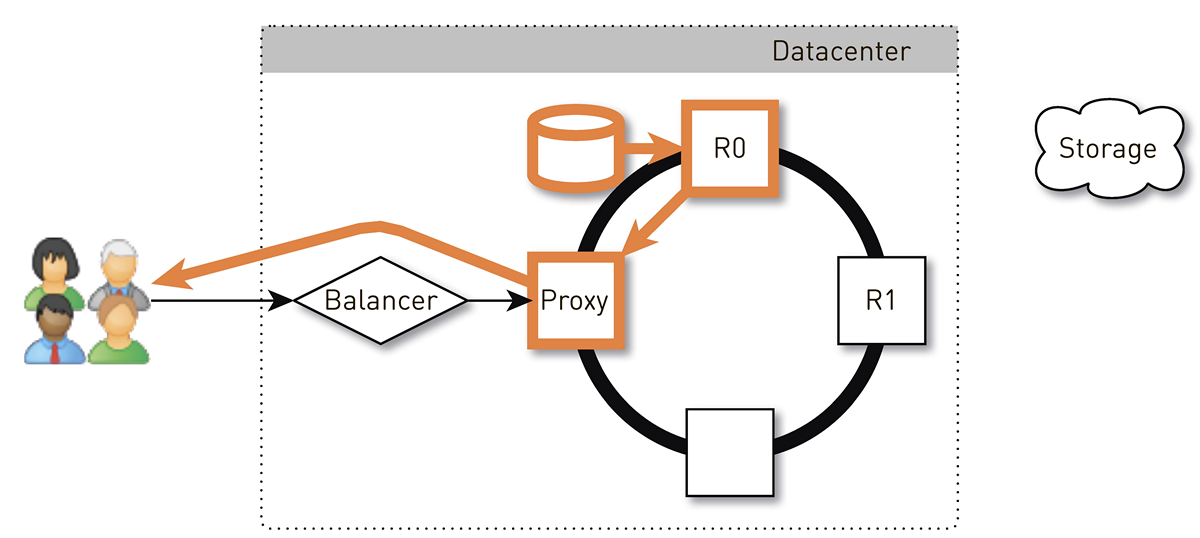
If the disk in the replica fails, the data from the storage will be transferred to the user directly. And if the replica fails, then the proxy knows about all the other replicas for this track, it will establish a connection with another live replica and receive data from it. So we guarantee that if a user has requested a track and at least one replica is alive, he will receive an answer.
How does the node
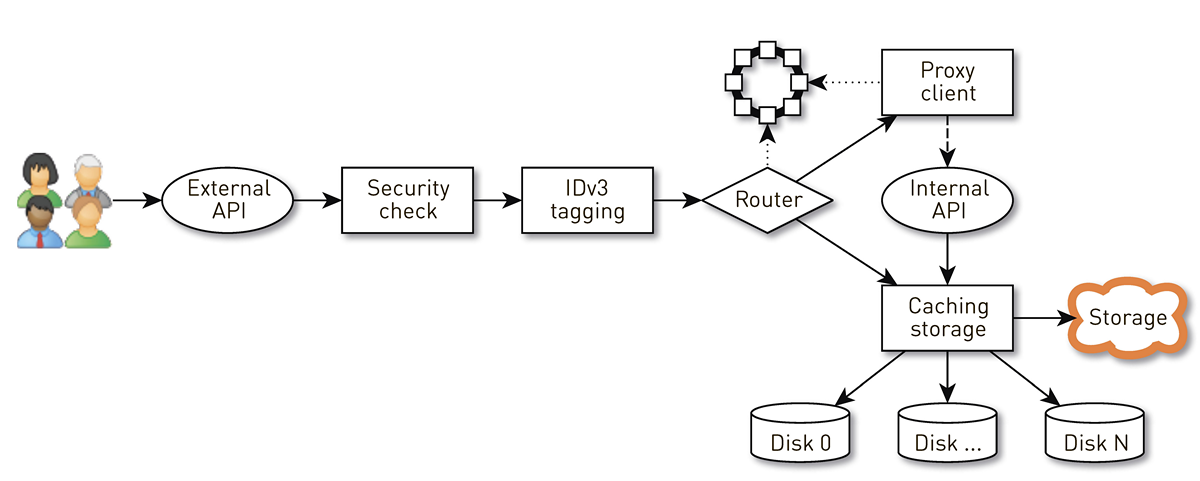
A node is a pipeline from a set of stages through which a user request passes. First, the request goes to the external API (we give everything via HTTPS). Further validation of the request is performed - signatures are checked. Then IDv3 tags are constructed, if necessary, for example, when purchasing a track. The request goes to the routing stage, where, based on the cluster topology, it is determined how the data will be given: either the current node is a replica for this track, or we will be proxying from another node. In the second case, the node through the proxy client establishes a connection with the replica via the internal HTTP API without checking signatures. The replica searches for data in the local storage, if it finds a track, it returns it from its disk; and if it does not find it, it pulls up tracks from the repository, caches and gives them away.
Load on node
Let us estimate what load one node should hold in such a configuration. Suppose we have three data centers of four nodes.

The entire service should serve 120 Gbit / s, that is, 40 Gbit / s per data center. For example, networkers arranged maneuvers or an accident occurred, and two data centers DC1 and DC3 remained. Now each of them should give 60 Gbit / s. But here the developers wanted to roll out some kind of update, in each data center there are 3 live nodes left and each of them should give 20 Gbit / s.
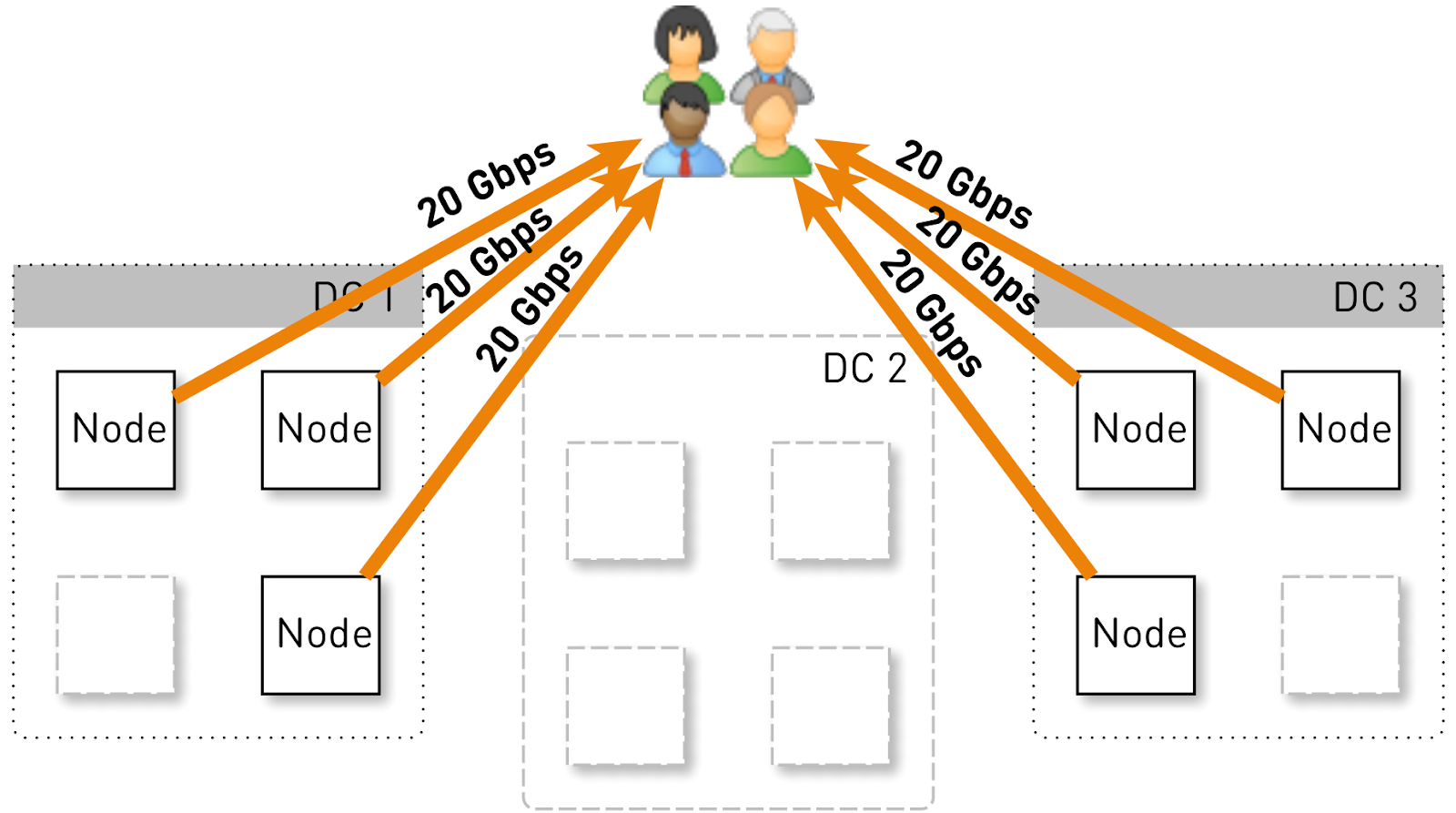
But initially there were 4 nodes in each data center. And if we store two replicas in the data center, then with a probability of 50%, the node that received the request will not be a replica for the requested track and will begin to proxy the data. That is, half of the traffic inside the data center is proxied.
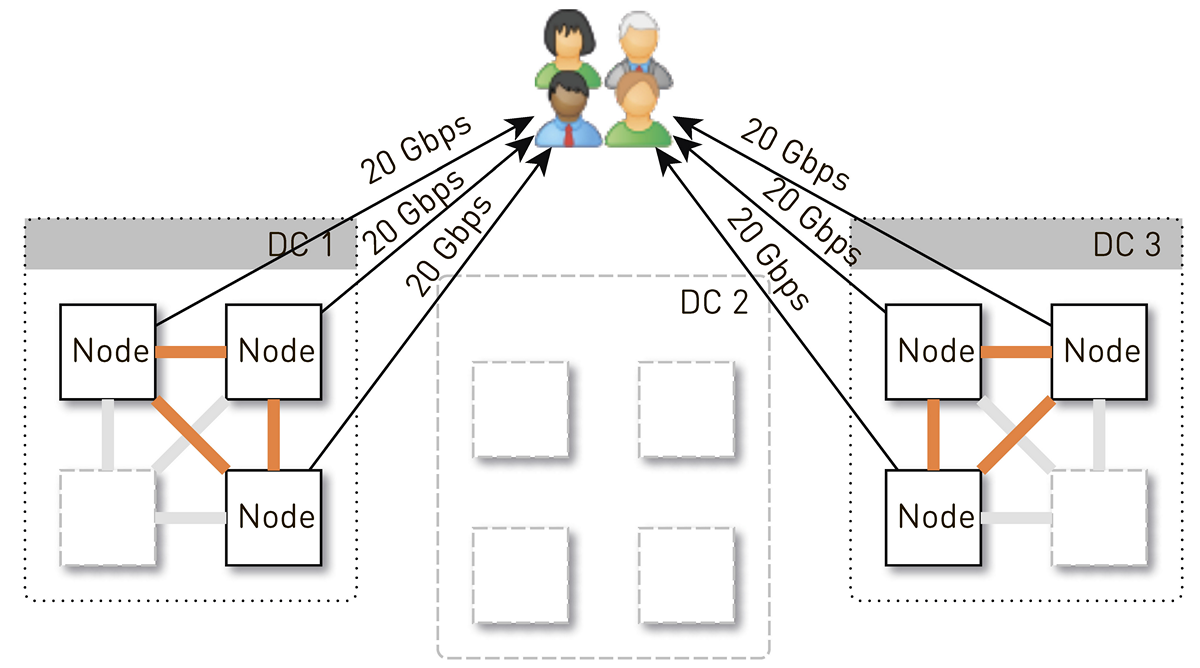
So, one node should give users 20 Gbit / s. Of these, 10 Gbps it pulls from its neighbors in the data center. But the scheme is symmetrical: the same 10 Gbit / s node gives its neighbors in the data center. It turns out that 30 Gbps comes from the node, of which 20 Gbps should serve itself, since it is a replica of the requested data. And the data will go either from the disks or from the RAM, where about 50 thousand "hot" tracks fit. Taking into account our statistics of playing this allows you to remove 60-70% of the load from the discs, and it will remain about 8 Gbit / s. This thread is quite capable of giving a dozen SSD.
Data storage on node
If each track is put in a separate file, then the overhead of managing these files will be huge. Even restarting the node and scanning the data on the disks will take minutes, if not tens of minutes.
There are less obvious limitations in this scheme. For example, you can load tracks only from the very beginning. And if the user requested playback from the middle and there was a cache miss, then we will not be able to give a single byte until we load the data to the desired location from the track repository. Moreover, we can also store the tracks only as a whole, even if it is a gigantic audiobook, which is already abandoned in the third minute. It will still lie like a dead weight on the disk, waste expensive space and reduce the cache hit of this node.
Therefore, we do it in a completely different way: we split up tracks into blocks of 256 KB each, because this correlates with the size of the block in the SSD, and we are already operating with these blocks. On a disk in 1 TB 4 million blocks are located. Each disk in the node is an independent storage, and all blocks of each track are distributed across all disks.
We did not immediately come to such a scheme, at first all the blocks of one track lay on one disc. But this led to severe load imbalances between the disks, since if one of the disks had hit a popular track, all requests for its data would fall on one disk. To avoid this, we distributed the blocks of each track across all discs, equalizing the load.
In addition, do not forget that we have a lot of RAM, but we decided not to do the samopisny cache, since we have a wonderful page cache in Linux.
How to store blocks on disks?
First, we decided to create one giant XFS file on the disk and place all the blocks in it. Then came the idea to work directly with the block device. We implemented both options, compared them and it turned out that when working directly with a block device, the recording is 1.5 times faster, the response time is 2-3 times lower, the overall system load is 2 times lower.
Index
But it is not enough to be able to store blocks, it is necessary to maintain an index from blocks of music tracks to blocks on a disk.

It turned out to be quite compact, one index record takes up only 29 bytes. For a storage size of 10 TB, the index takes a little more than 1 GB.
There is an interesting point. Each such record has to keep the total size of the entire track. This is a classic example of denormalization. The reason is that, according to the specification in the HTTP range response, we must return the total size of the resource, as well as form the Content-length header. If it were not for this, then everything would have been even more compact.
To the index, we formulated a number of requirements: to work quickly (preferably stored in RAM), so that it was compact and did not take up space from page cache. Another index must be persistent. If we lose it, we will lose information about where in the disk which track is stored, and this is equivalent to cleaning the disks. And in general, I would like the old blocks, which have not been addressed for a long time, were somehow supplanted, freeing up space for more popular tracks. We chose the LRU crowding policy : the blocks are crowded out once a minute, we keep 1% of the blocks free. Of course, the index structure must be thread-safe, because we have 100 thousand connections per node.
SharedMemoryFixedMap from our open source one-nio library ideally satisfies all these conditions.We put the index on
tmpfs , it works quickly, but there is a nuance. When the machine is restarted, everything that was on tmpfs , including the index, is lost. In addition, if because of the sun.misc.Unsafe our process collapsed, it is unclear in what condition the index remained. Therefore, we make an impression of it once an hour But this is not enough: once we use block crowding, we have to maintain WAL , in which we write information about the crowded blocks. The block entries in the casts and the WAL need to be somehow streamlined during restoration. For this we use block generation. It plays the role of a global transaction counter and is incremented every time the index changes. Let's look at an example of how this works.Take an index with three entries: two blocks of track # 1 and one block of track # 2.
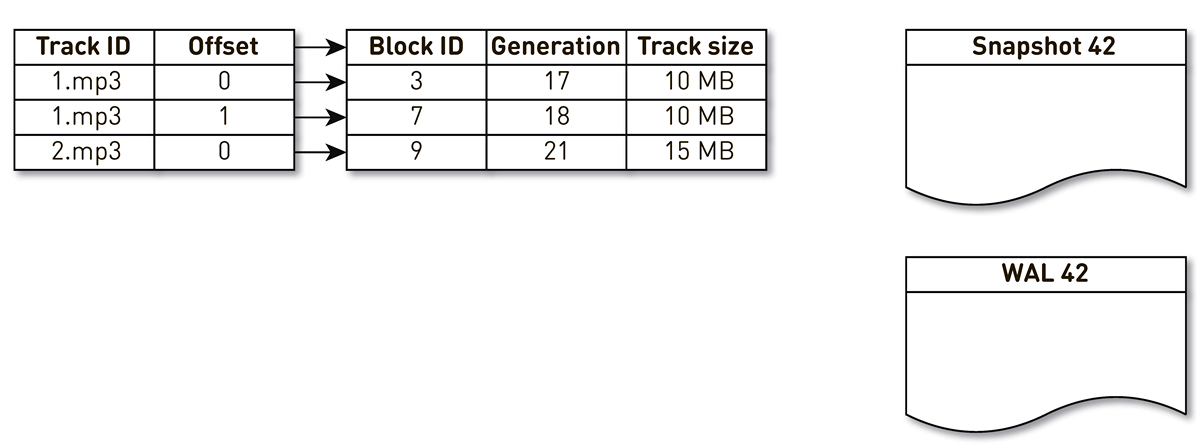
The stream of creation of impressions is awakened and is iterated on this index: the first and second tuples fall into the impression. Then the displacement stream addresses the index, realizes that the seventh block has not been addressed for a long time, and decides to use it for something else. The process displaces the block and writes an entry to WAL. He gets to block 9, sees that he, too, has not been contacted for a long time, and also marks him as repressed. Here the user accesses the system and a cache miss occurs - a track is requested that we don’t have. We save the block of this track in our storage, having overwritten the 9th block. At the same time, the generation is incremented and becomes equal to 22. Next, the process of creating the cast is activated, which has not completed its work, reaches the last record and writes it to the cast. As a result, we have two live recordings in the index, a cast and a WAL.
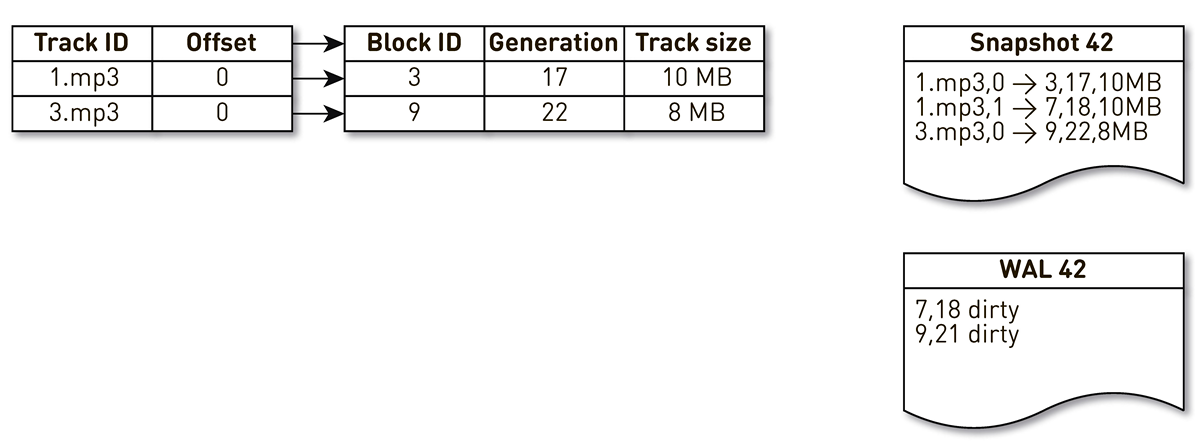
When the current node falls, it will restore the initial state of the index as follows. First, we scan the WAL and build a map of dirty blocks. The map stores the mapping from the block number to the generation when this block was supplanted.

After that, we begin to iterate over the image, using the map as a filter. We look at the first record of the cast, it concerns the block №3. He is not mentioned among the dirty, so he is alive and falls into the index. We get to block number 7 with the eighteenth generation, but the map of dirty blocks tells us that just in the 18th generation, the block was ousted. Therefore, it does not enter the index. We reach the last entry, which describes the contents of the 9th block with 22 generation. This block is mentioned in the map of dirty blocks, but it was supplanted before. This means that it has been reused for new data and is indexed. The goal is achieved.
Optimization
But that's not all, we go down deeper.
Let's start with page cache. We were counting on it initially, but when we started to conduct load testing of the first version, it turned out that page cache hit rate does not reach 20%. We assumed that the problem is in read ahead: we do not store files, but blocks, while serving a bunch of connections, and in such a configuration it is efficient to work with the disk randomly. We almost never read anything consistently. Fortunately, in Linux there is a
posix_fadvise call that allows you to tell the kernel how we are going to work with the file descriptor - in particular, we can say that we don’t need to read ahead by passing the POSIX_FADV_RANDOM flag. This system call is available through one-nio . In operation, our cache hit is 70-80%. 2 , HTTP 20%.. heap. TLB- , Huge Pages Java-. (GC Time/Safepoint Total Time 20-30% ), , HTTP latency .
Incident
( ) .
. , , , , . , - . , . , , . , Daft Punk №2 sdc, sdd.
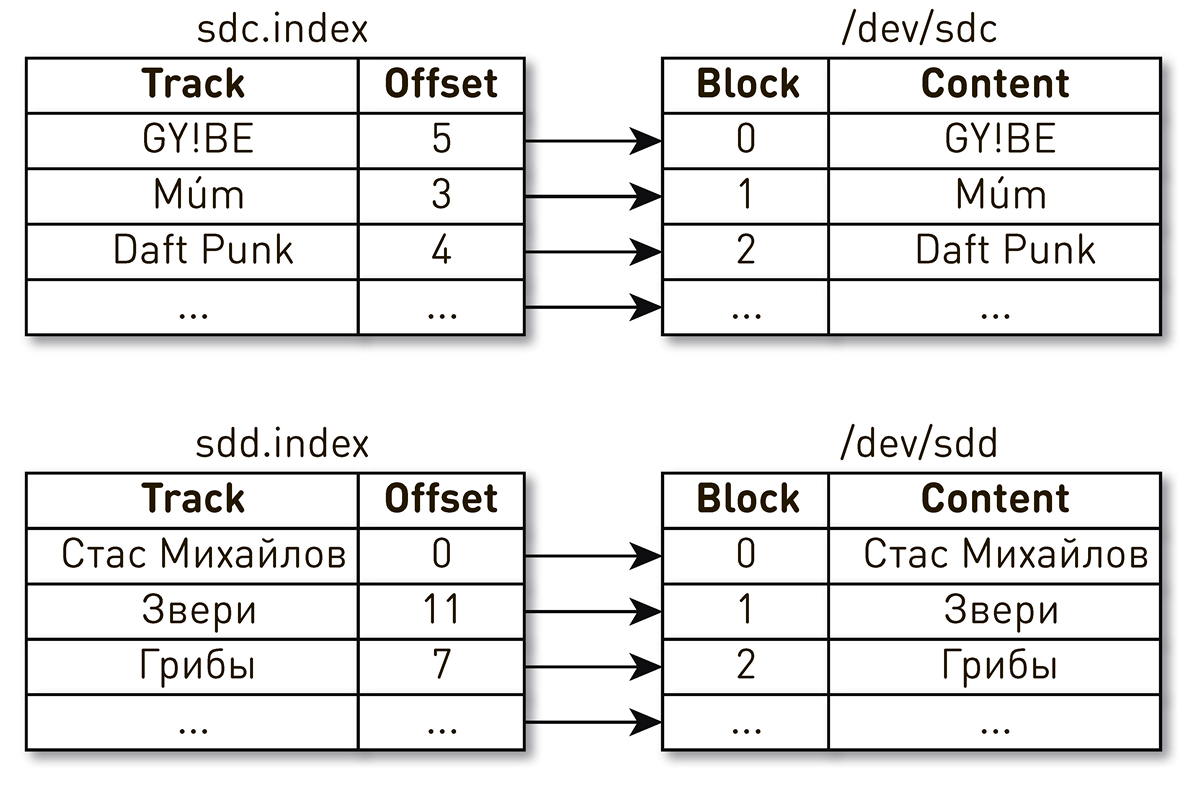
, . Linux : , .

. ID. WWN , WAL. , , .
, . CDN , CDN -. . . , , .
. Open Tracing Zipkin . , . , , HTTP- . , , , , , , .
. , : , , .
ByteBuffer buffer = ByteBuffer.allocate(size); int count = fileChannel.read(buffer, position); if (count <= 0) { // ... } buffer.flip(); socketChannel.write(buffer); , :
FileChannel.read()kernel space user space;SocketChannel.write(), user space kernel space.
, Linux
sendfile() , , user space. , one-nio . , sendfile() — 10 / sendfile() 0.user-space SSL-
sendfile() , . . SocketChannel FileChannel , Async Profiler , sun.nio.ch.IOUtil , read() write() . . ByteBuffer bb = Util.getTemporaryDirectBuffer(dst.remaining()); try { int n = readIntoNativeBuffer(fd, bb, position, nd); bb.flip(); if (n > 0) dst.put(bb); return n; } finally { Util.offerFirstTemporaryDirectBuffer(bb); } . heap
ByteBuffer , , , heap ByteBuffer , . .. one-nio .
MallocMT — , . SSL , Java heap, ByteBuffer , FileChannel . . final Allocator allocator = new MallocMT(size, concurrency); int write(Socket socket) { if (socket.getSslContext() != null) { long address = allocator.malloc(size); ByteBuffer buf = DirectMemory.wrap(address, size); int available = channel.read(buf, offset); socket.writeRaw(address, available, flags); 100 000
. . 100 . . ?
, — . , . , . .
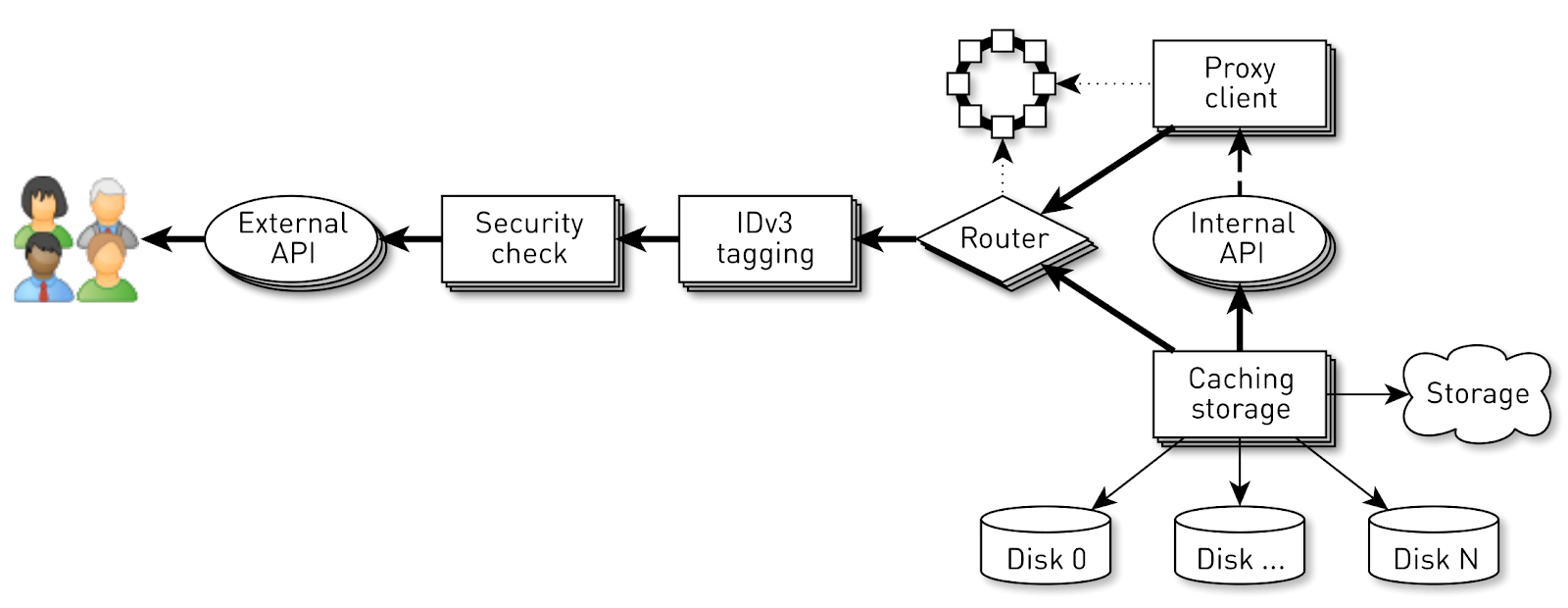
, , . , . . , , . .
. . , , .. . . , , . , . back pressure.
. , subscriber publisher demand. Demand , subscriber demand, . Publisher , demand .
push pull. push subscriber , publisher, publisher demand subscriber, . , subscriber-. pull , publisher , subscriber. publisher , demand . subscriber , , publisher demand.
. publisher subscriber .
.
Publisher Subscriber , : interface Publisher<T> { void subscribe(Subscriber<? super T> s); } interface Subscriber<T> { void onSubscribe(Subscription s); void onNext(T t); void onError(Throwable t); void onComplete(); } interface Subscription { void request(long n); void cancel(); } Subscription demand . There is simply no place., , chunk. , heap , . Chunk — ,
ByteBuffer , . interface Chunk { int read(ByteBuffer dst); int write(Socket socket); void write(FileChannel channel, long offset); } :
- , cache hit ,
RandomAccessFile. , . ,sendfile(). . - cache miss : . , — , , — .
- , - heap.
ByteBuffer.
API, , . Typed Actor Model, . , , , . .
, .
. publisher subscriber , , executor, .
:
AtomicBoolean happens before . // Incoming messages final Queue<M> mailbox; // Message processing works here final Executor executor; // To ensure HB relationship between runs final AtomicBoolean on = new AtomicBoolean(); :
@Override void request(final long n) { enqueue(new Request(n)); } void enqueue(final M message) { mailbox.offer(message); tryScheduleToExecute(); } tryScheduleToExecute() : if (on.compareAndSet(false, true)) { try { executor.execute(this); } catch (Exception e) { ... } } run() : if (on.get()) try { dequeueAndProcess(); } finally { on.set(false); if (!messages.isEmpty()) { tryScheduleToExecute(); } } } dequeueAndProcess() : M message; while ((message = mailbox.poll()) != null) { // Pattern match if (message instanceof Request) { doRequest(((Request) message).n); } else { … } } . ,
volatile , Atomic* , contention . 100 000 200 .Eventually
production 12 , . 10 / . . Java one-nio .
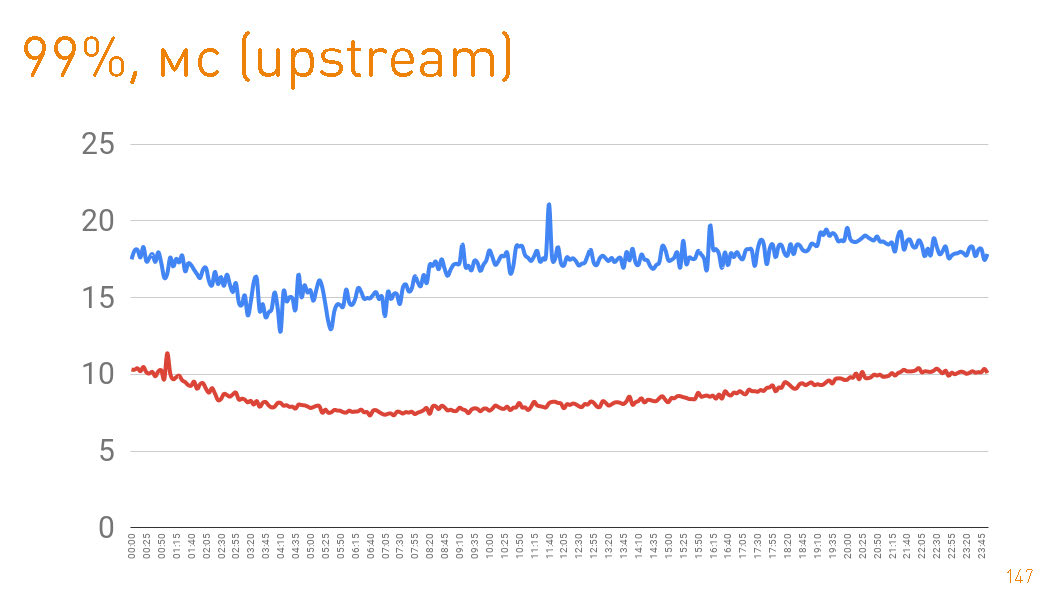
, . 99- 20 . — HTTPS-. —
sendfile() HTTP.cache hit production 97%, latency , , , .
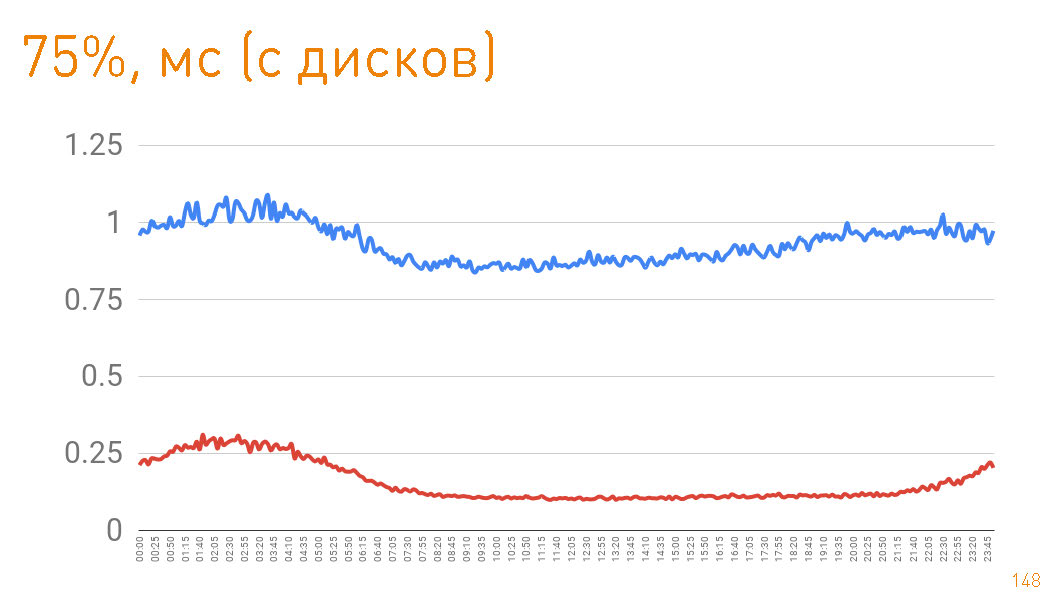
75- , 1 . — 300 . Those. 0.7 — .
, , , . , .
Source: https://habr.com/ru/post/434206/
All Articles