We shoot in the foot, processing the input data

The link of today's article is different from the usual. This is not one project for which the source code was analyzed, but a series of positives of the same diagnostic rule in several different projects. What is the interest here? The fact that some of the considered code fragments contain errors that are reproduced during the work with the application, while others contain vulnerabilities (CVE). In addition, at the end of the article we discuss a bit about security defects.
Brief introduction
All errors that will be considered today in the article have a similar pattern:
- the program receives data from the stdin stream;
- checks the success of reading data;
- if the data is read successfully, the hyphen is removed from the string.
Nevertheless, all the fragments that will be considered contain errors and are vulnerable to adjusted input. Since the data is received from the user, which may violate the logic of the application execution, there was a great temptation to try to break something. What I did.
All the problems listed below were detected by the PVS-Studio static analyzer , which looks for errors in the code not only for C, C ++, but also for C #, Java.
')
Of course, finding a problem with a static analyzer is good, but finding and reproducing is a completely different level of pleasure. :)
FreeSWITCH
The first suspicious code snippet was found in the code of the fs_cli.exe module included in the FreeSWITCH distribution:
static const char *basic_gets(int *cnt) { .... int c = getchar(); if (c < 0) { if (fgets(command_buf, sizeof(command_buf) - 1, stdin) != command_buf) { break; } command_buf[strlen(command_buf)-1] = '\0'; /* remove endline */ break; } .... } PVS-Studio warning : V1010 CWE-20 Unchecked tainted data is used in index: 'strlen (command_buf)'.
The analyzer warns of a suspicious index access to the command_buf array. It is considered suspicious for the reason that unchecked external data is used as an index. External - because they are received through the fgets function from the stdin stream. Untested - since no verification was performed prior to use. The expression fgets (command_buf, ....)! = Command_buf doesn’t count, because in this way we check only the fact of receiving the data, but not its contents.
The problem with this code is that under certain conditions, writing '\ 0' outside the bounds of the array will occur, which will lead to the appearance of undefined behavior. To do this, enter a zero-length string (a zero-length string from the point of view of the C language, that is, one in which the first character is '\ 0').
Let's estimate what happens if you pass a zero-length string to the input:
- fgets (command_buf, ....) -> command_buf ;
- fgets (....)! = command_buf -> false ( then the branch of the if statement is ignored);
- strlen (command_buf) -> 0 ;
- command_buf [strlen (command_buf) - 1] -> command_buf [-1] .
Oops!
The interesting thing here is that this analyzer warning is quite possible to “touch with your hands”. In order to repeat the problem, you need:
- bring the execution of the program to this function;
- adjust the input so that the call to getchar () returns a negative value;
- pass to the fgets function a string with a terminal zero at the beginning, which it should successfully read.
Having a little rummaged in source codes, I made a specific sequence of reproduction of a problem:
- Run fs_cli.exe in batch mode ( fs_cli.exe -b ). I note that to perform further steps, connecting fs_cli.exe to the server should be successful. For this, it suffices, for example, to run FreeSwitchConsole.exe locally as an administrator.
- We enter so that the call to getchar () returns a negative value.
- Enter a string with a terminal zero at the beginning (for example, '\ 0Oooops').
- ....
- PROFIT!
Below is a video of the playback problem:
NcFTP
A similar problem was discovered in the NcFTP project, it only met in two places already. Since the code looks similar, we consider only one problem place:
static int NcFTPConfirmResumeDownloadProc(....) { .... if (fgets(newname, sizeof(newname) - 1, stdin) == NULL) newname[0] = '\0'; newname[strlen(newname) - 1] = '\0'; .... } PVS-Studio warning : V1010 CWE-20 Unchecked tinted data is used in index: 'strlen (newname)'.
Here, unlike the example from FreeSWITCH, the code is written worse and more prone to problems. For example, writing '\ 0' happens regardless of whether the read was successful using fgets or not. That is, there is even more possibilities of how to break the normal execution logic. Let's go the checked way - through lines of zero length.
Replicating the problem is a bit more complicated than in the case of FreeSWITCH. The sequence of steps is described below:
- start and connect to the server from which you can download the file. For example, I used speedtest.tele2.net (as a result, the application launch command looks like this: ncftp.exe speedtest.tele2.net );
- download file from server. Locally there should already be a file with the same name, but with different properties. You can, for example, download a file from the server, change it, and try the download command again (for example, get 512KB.zip );
- to the question about choosing an action, answer with a line beginning with the character 'N' (for example, Now let's have some fun );
- enter '\ 0' (or something more interesting);
- ....
- PROFIT!
Reproduction of the problem is also recorded on video:
Openldap
In the OpenLDAP project (more precisely, in one of the associated utilities), they stepped on the same rake as in FreeSWITCH. An attempt to delete a newline character occurs only under the condition that the line was read successfully, but there is also no protection against zero-length lines.
Code snippet:
int main( int argc, char **argv ) { char buf[ 4096 ]; FILE *fp = NULL; .... if (....) { fp = stdin; } .... if ( fp == NULL ) { .... } else { while ((rc == 0 || contoper) && fgets(buf, sizeof(buf), fp) != NULL) { buf[ strlen( buf ) - 1 ] = '\0'; /* remove trailing newline */ if ( *buf != '\0' ) { rc = dodelete( ld, buf ); if ( rc != 0 ) retval = rc; } } } .... } PVS-Studio warning : V1010 CWE-20 Unchecked tainted data is used in index: 'strlen (buf)'.
Let's throw out the excess, so that the essence of the problem becomes more obvious:
while (.... && fgets(buf, sizeof(buf), fp) != NULL) { buf[ strlen( buf ) - 1 ] = '\0'; .... } This code is better than in NcFTP, but it is still vulnerable. If, when requesting fgets, pass a zero length string to the input:
- fgets (buf, ....) -> buf ;
- fgets (....)! = NULL -> true (the body of the while loop starts to execute);
- strlen (buf) - 1 -> 0 - 1 -> -1 ;
- buf [-1] = '\ 0' .
libidn
Despite the fact that the errors analyzed above are quite interesting (they are consistently reproduced and can be 'touched' (except that I didn’t reach my hand to reproduce the problem on OpenLDAP)), they can’t be named as vulnerabilities because problems are not assigned CVE identifiers.
However, some of these vulnerabilities have the same pattern of problems. Both code snippets below are for the libidn project.
Code snippet:
int main (int argc, char *argv[]) { .... else if (fgets (readbuf, BUFSIZ, stdin) == NULL) { if (feof (stdin)) break; error (EXIT_FAILURE, errno, _("input error")); } if (readbuf[strlen (readbuf) - 1] == '\n') readbuf[strlen (readbuf) - 1] = '\0'; .... } PVS-Studio warning : V1010 CWE-20 Unchecked trite data is used in index: 'strlen (readbuf)'.
The situation is similar, except that unlike the previous examples, where the recording was performed on the index -1 , reading occurs here. However, this is still an undefined behavior. This error received its own CVE identifier ( CVE-2015-8948 ).
After finding the problem, this code was changed as follows:
int main (int argc, char *argv[]) { .... else if (getline (&line, &linelen, stdin) == -1) { if (feof (stdin)) break; error (EXIT_FAILURE, errno, _("input error")); } if (line[strlen (line) - 1] == '\n') line[strlen (line) - 1] = '\0'; .... } A little surprised? It happens. New Vulnerability Corresponding CVE ID: CVE-2016-6262 .
PVS-Studio warning : V1010 CWE-20 Unchecked tainted data is used in index: 'strlen (line)'.
With the next attempt, the problem was corrected by adding a check of the length of the input line:
if (strlen (line) > 0) if (line[strlen (line) - 1] == '\n') line[strlen (line) - 1] = '\0'; Let's take a look at the dates. The commit, 'closing' CVE-2015-8948 - 08/10/2015. The commit closing CVE-2016-62-62 - 01/14/2016. That is, the difference between the corrections is 5 months ! It is here that you remember such an advantage of static analysis as the detection of errors at the early stages of writing code ...
Static analysis and security
There will be no further code examples, instead statistics and reasoning. In this section, the opinion of the author may not coincide with the opinion of the reader much more than before in this article.
Note I recommend to familiarize yourself with another article on a similar topic - " How can PVS-Studio help in the search for vulnerabilities? ". There are interesting examples of vulnerabilities that look like simple errors. Additionally, in that article I talked a bit about terminology and why static analysis is a must have if you are concerned about the topic of security.
Let's look at the statistics on the number of vulnerabilities detected in the last 10 years to assess the situation. I took the data from the CVE Details site.
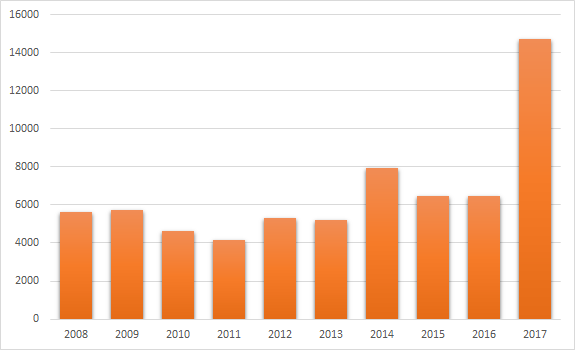
An interesting situation emerges. Until 2014, the number of CVEs recorded did not exceed the mark of 6,000 units, and since, it no longer fell below. But the most interesting here, of course, is the statistics for 2017 - the absolute leader (14,714 units). As for the current - 2018 - year, it has not ended yet, but it is already breaking records - 15310 units.
Does this mean that all new software is full of holes like a sieve? I do not think, and here's why:
- Increased interest in the topic of vulnerabilities. Surely, even if you are not very close directly to the topic of security, you repeatedly had to stumble upon articles, notes, reports and videos on the topic of security. In other words, a certain “HYIP” was created. Is it bad? I think no. In the end, it all comes down to the fact that developers care more about application security, which is good.
- Increase the number of applications being developed. More code - more likelihood of any vulnerability that will replenish the statistics.
- Improved vulnerability search tools and code quality assurance. More demand -> more supply. Analyzers, fuzzers and other tools are becoming more sophisticated, which plays into the hands of those who want to look for vulnerabilities (regardless of which side of the barricades they are on).
So, the emerging trend cannot be called exclusively negative - publishers care more about information security, tools for finding problems are improving, and all this is undoubtedly positive.
Does this mean that you can relax and "not to bathe"? I think no. If you are concerned about the security of your applications, you should take as much safety measures as possible. This is especially true if the source code is in the public domain, as it is:
- more susceptible to embedding vulnerabilities;
- more susceptible to 'sounding' by those 'gentlemen' who are interested in holes in your application for the purpose of their exploitation. Although well-wishers in this case will be able to help you more.
I do not want to say that you do not need to translate your projects for open source. Just do not forget about proper quality control / safety measures.
Is static analysis such an extra measure? Yes. Static analysis copes well with the detection of potential vulnerabilities that may later become quite real.
It seems to me (I admit that I am mistaken) that many consider vulnerabilities to be a high-level phenomenon. Yes and no. Problems in the code that seem to be simple programming errors can also be serious vulnerabilities. Again, some examples of such vulnerabilities are given in the previously mentioned article . Don't underestimate 'simple' mistakes.
Conclusion
Do not forget that the input data may have zero length, and this must also be taken into account.
Conclusions about whether all the hype with vulnerabilities just hype, or the problem exists, do it yourself.
For my part, unless I suggest to try on your PVS-Studio project, if you have not done it yet.
All the best!

If you want to share this article with an English-speaking audience, then please use the link to the translation: Sergey Vasiliev. Shoot yourself in the foot when handling input data
Source: https://habr.com/ru/post/433932/
All Articles