Efficient memory management in Node.js
Programs, in the course of work, use the RAM of computers. In JavaScript, in the Node.js environment, you can write server projects of various scales. The organization of work with memory is always a difficult and responsible task. At the same time, if in languages such as C and C ++, programmers are quite tightly involved in memory management, JS has automatic mechanisms that, as it may seem, completely remove from the programmer the responsibility for efficient work with memory. However, in reality it is not. Badly written code for Node.js can interfere with the normal operation of the entire server on which it runs.

In the material, the translation of which we are publishing today, the discussion will deal with efficient work with memory in the Node.js environment. In particular, such concepts as streams, buffers, and the
If someone is asked to create a program for copying files in the Node.js environment, he will most likely immediately write about what is shown below. Name the file containing this code,
')
This program creates handlers to read and write a file with the specified name and tries to write the file data after reading it. For small files, this approach turns out to be quite working.
Suppose that our application needs to copy a huge file (we will consider “huge” files that are larger than 4 GB) during the backup process. I, for example, have a video file of 7.4 GB in size, which I, with the help of the above-described program, will try to copy from my current directory to the
In Ubuntu, after executing this command, an error message related to the buffer overflow was displayed:
As you can see, the file read operation failed because Node.js allows only 2 GB of data to be read into the buffer. How to overcome this limitation? When performing operations that intensively use the I / O subsystem (copying files, processing, compressing them), it is necessary to take into account the capabilities of the systems and the limitations associated with memory.
In order to circumvent the above problem, we need a mechanism by which we can break large data arrays into small pieces. We also need data structures that allow us to store these fragments and work with them. A buffer is a data structure that allows you to store binary data. Next, we need to be able to read data fragments from the disk and write them to disk. This opportunity can give us the flow. Talk about buffers and streams.
A buffer can be created by initializing a
In versions of Node.js, newer than the 8th, it is best to use the following construction to create buffers:
If we already have some data, like an array or something like that, a buffer can be created based on that data.
The buffers have methods that allow you to “look in” and find out what data is in there — the
In the process of optimizing the code, we will not create buffers ourselves. Node.js creates these data structures automatically when working with streams or network sockets.
Flows, if we turn to the language of science fiction, can be compared with portals to other worlds. There are four types of threads:
We need streams because the vital purpose of the stream API in Node.js, and in particular the
In other words, we need a mechanism to solve the problem of copying a large file, which allows us not to overload the system.
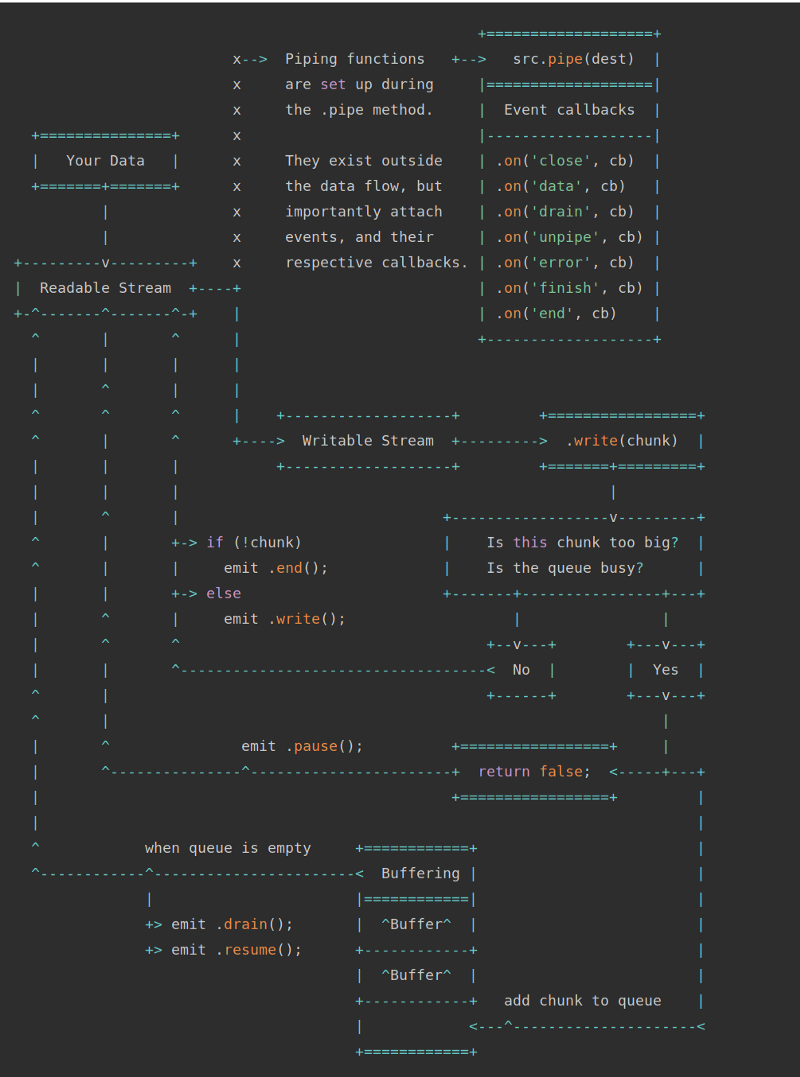
Streams and Buffers (based on Node.js documentation)
The previous diagram shows two types of streams - Readable Streams and Writable Streams. The
Consider the solution to the problem of copying a huge file, which we talked about above. This solution can be based on two streams and will look like this:
Let's call the program that implements this idea,
We expect the user, running this program, to provide her with two file names. The first is the source file, the second is the name of its future copy. We create two streams - a stream for reading and a stream for writing, transferring data fragments from the first to the second. There are some auxiliary mechanisms. They are used to monitor the copying process and to display the relevant information in the console.
We use the event mechanism here, in particular, we are talking about subscribing to the following events:
With this program, the file size of 7.4 GB is copied without error messages.
However, there is one problem. It can be revealed if you look at the data on the use of system resources by various processes.
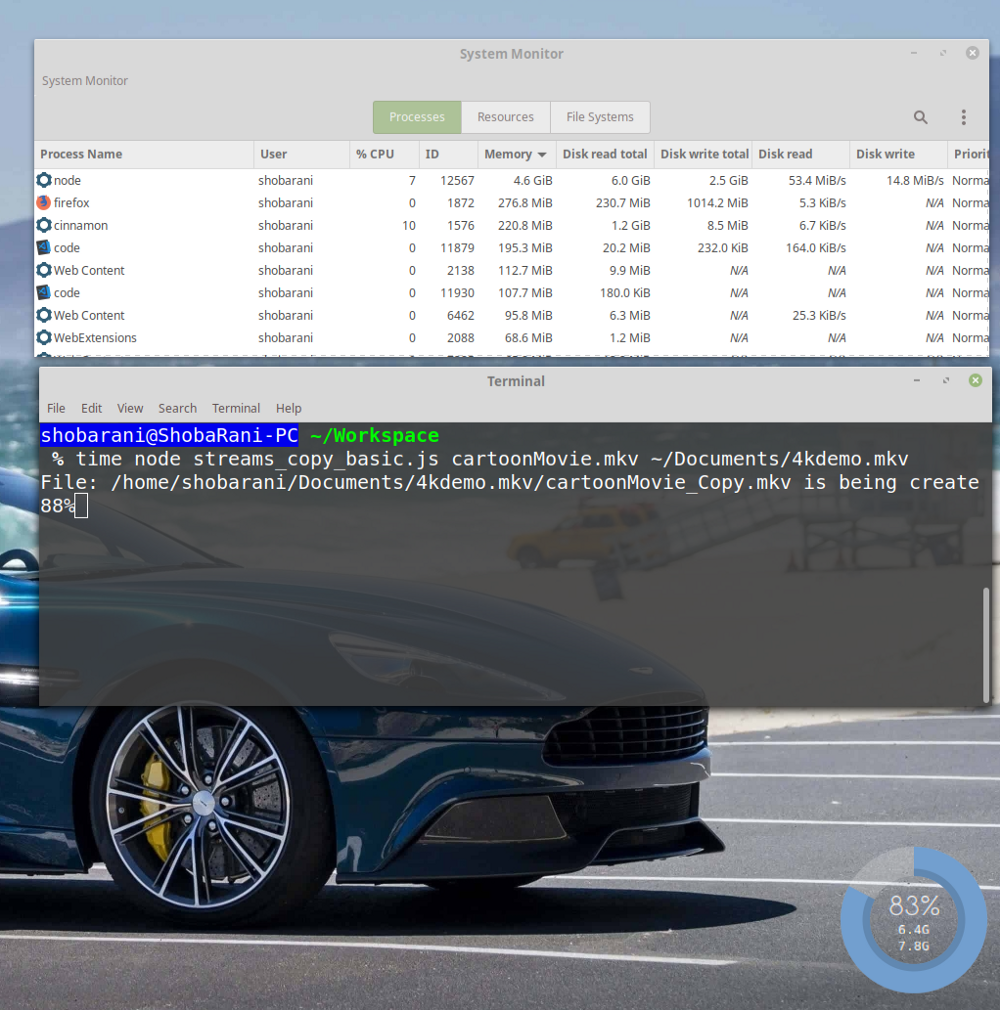
System Resource Usage Data
Please note that the
Note the speed of reading data from disk and writing data to disk from the previous illustration (
Such a difference in the read speeds from the data record means that the data source issues them much faster than the receiver can receive and process them. The computer has to keep in memory the read data fragments until they are written to disk. As a result, we see such indicators of memory usage.
On my computer, this program was executed 3 minutes 16 seconds. Here are the details of its progress:
In order to cope with the above described problem, we can modify the program so that during the copying of files the read and write speeds of data are adjusted automatically. This mechanism is called back pressure. In order to use it, we do not need to do anything special. It is enough, using the
The main difference of this program from the previous one is that the code for copying data fragments is replaced with the following line:
The basis of all that is happening here is the
Run the program.
We are copying the same huge file. Now let's look at how the work with memory and disk looks like.
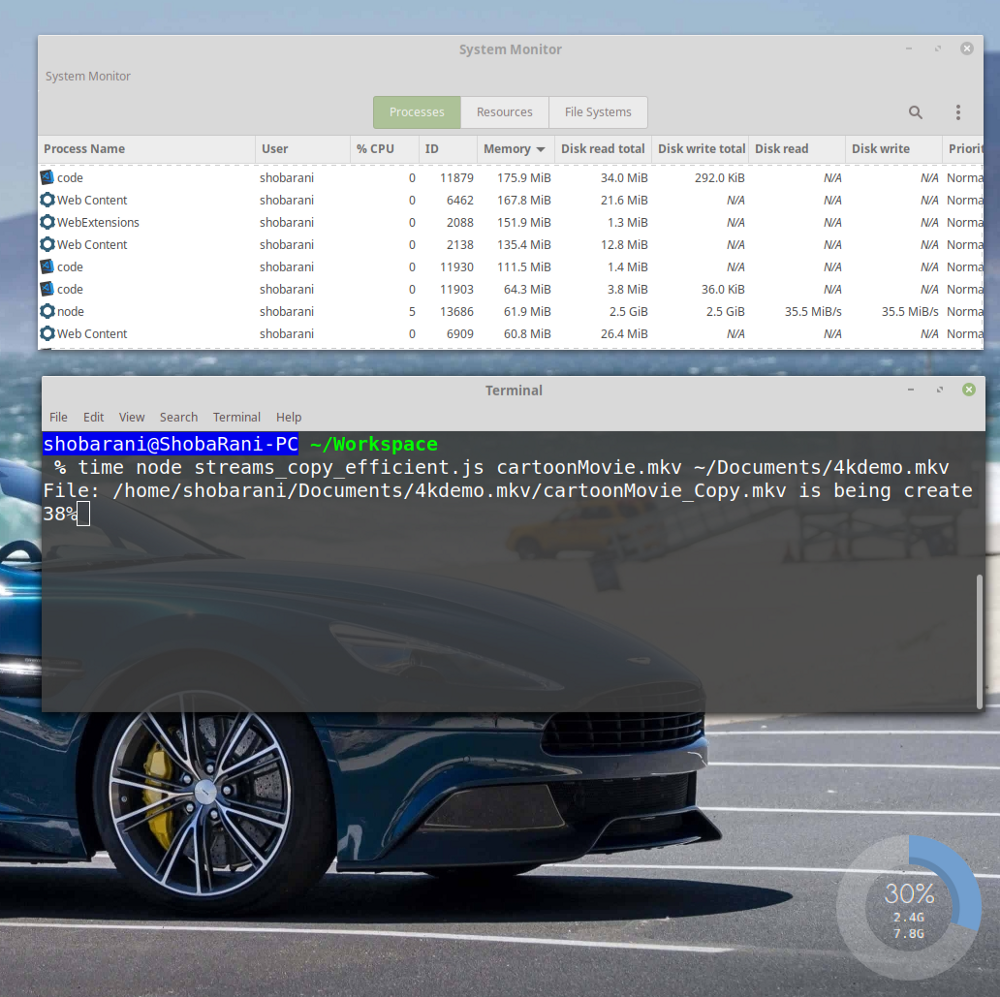
Using pipe (), read and write speeds are automatically adjusted.
Now we see that the
Thanks to the back pressure mechanism, read and write speeds are now always equal to each other. In addition, the new program runs 13 seconds faster than the old one.
Through the use of the
In this case, 61.9 MB is the size of the buffer created by the data read stream. We can easily set this size by ourselves, using the
Here we copied the file to the local file system, but the same approach can be used to optimize many other data input / output tasks. For example, this is the work with data streams, the source of which is Kafka, and the receiver is the database. According to the same scheme, it is possible to organize data reading from a disk, their compression, as they say, “on the fly”, and writing back to disk already compressed. In fact, you can find many other applications for the technology described here.
One of the goals of writing this article was to demonstrate how easy it is to write bad programs on Node.js, even though this platform gives the developer a great API. Paying some attention to this API, you can improve the quality of server software projects.
Dear readers! How do you work with buffers and threads in Node.js?

In the material, the translation of which we are publishing today, the discussion will deal with efficient work with memory in the Node.js environment. In particular, such concepts as streams, buffers, and the
pipe() flow method will be considered here. Node.js v8.12.0 will be used in the experiments. A repository with sample code can be found here .Task: copying a huge file
If someone is asked to create a program for copying files in the Node.js environment, he will most likely immediately write about what is shown below. Name the file containing this code,
basic_copy.js .')
const fs = require('fs'); let fileName = process.argv[2]; let destPath = process.argv[3]; fs.readFile(fileName, (err, data) => { if (err) throw err; fs.writeFile(destPath || 'output', data, (err) => { if (err) throw err; }); console.log('New file has been created!'); }); This program creates handlers to read and write a file with the specified name and tries to write the file data after reading it. For small files, this approach turns out to be quite working.
Suppose that our application needs to copy a huge file (we will consider “huge” files that are larger than 4 GB) during the backup process. I, for example, have a video file of 7.4 GB in size, which I, with the help of the above-described program, will try to copy from my current directory to the
Documents directory. Here is the command to start copying: $ node basic_copy.js cartoonMovie.mkv ~/Documents/bigMovie.mkv In Ubuntu, after executing this command, an error message related to the buffer overflow was displayed:
/home/shobarani/Workspace/basic_copy.js:7 if (err) throw err; ^ RangeError: File size is greater than possible Buffer: 0x7fffffff bytes at FSReqWrap.readFileAfterStat [as oncomplete] (fs.js:453:11) As you can see, the file read operation failed because Node.js allows only 2 GB of data to be read into the buffer. How to overcome this limitation? When performing operations that intensively use the I / O subsystem (copying files, processing, compressing them), it is necessary to take into account the capabilities of the systems and the limitations associated with memory.
Streams and Buffers in Node.js
In order to circumvent the above problem, we need a mechanism by which we can break large data arrays into small pieces. We also need data structures that allow us to store these fragments and work with them. A buffer is a data structure that allows you to store binary data. Next, we need to be able to read data fragments from the disk and write them to disk. This opportunity can give us the flow. Talk about buffers and streams.
▍ Buffers
A buffer can be created by initializing a
Buffer object. let buffer = new Buffer(10); // 10 - console.log(buffer); // <Buffer 00 00 00 00 00 00 00 00 00 00> In versions of Node.js, newer than the 8th, it is best to use the following construction to create buffers:
let buffer = new Buffer.alloc(10); console.log(buffer); // <Buffer 00 00 00 00 00 00 00 00 00 00> If we already have some data, like an array or something like that, a buffer can be created based on that data.
let name = 'Node JS DEV'; let buffer = Buffer.from(name); console.log(buffer) // <Buffer 4e 6f 64 65 20 4a 53 20 44 45 5> The buffers have methods that allow you to “look in” and find out what data is in there — the
toString() and toJSON() methods.In the process of optimizing the code, we will not create buffers ourselves. Node.js creates these data structures automatically when working with streams or network sockets.
▍ Threads
Flows, if we turn to the language of science fiction, can be compared with portals to other worlds. There are four types of threads:
- Stream for reading (data can be read from it).
- Stream for writing (data can be sent to it).
- Duplex stream (it is open both for reading data from it and for sending data to it).
- Transforming stream (a special duplex stream that allows you to process data, for example, compress it or verify its correctness).
We need streams because the vital purpose of the stream API in Node.js, and in particular the
stream.pipe() method, is to limit data buffering to acceptable levels. This is done in order to work with data sources and data recipients that differ in different data processing speeds, would not overflow the existing memory.In other words, we need a mechanism to solve the problem of copying a large file, which allows us not to overload the system.
Streams and Buffers (based on Node.js documentation)
The previous diagram shows two types of streams - Readable Streams and Writable Streams. The
pipe() method is a very simple mechanism to attach streams for reading to streams for writing. If the above scheme is not particularly clear to you, that's okay. After analyzing the following examples, you can easily figure it out. In particular, we will now consider examples of data processing using the pipe() method.Solution 1: Copy files using streams.
Consider the solution to the problem of copying a huge file, which we talked about above. This solution can be based on two streams and will look like this:
- We expect the next data fragment to appear in the stream for reading.
- We write the received data to the stream for recording.
- We track the progress of the copy operation.
Let's call the program that implements this idea,
streams_copy_basic.js . Here is its code: /* . : Naren Arya */ const stream = require('stream'); const fs = require('fs'); let fileName = process.argv[2]; let destPath = process.argv[3]; const readable = fs.createReadStream(fileName); const writeable = fs.createWriteStream(destPath || "output"); fs.stat(fileName, (err, stats) => { this.fileSize = stats.size; this.counter = 1; this.fileArray = fileName.split('.'); try { this.duplicate = destPath + "/" + this.fileArray[0] + '_Copy.' + this.fileArray[1]; } catch(e) { console.exception('File name is invalid! please pass the proper one'); } process.stdout.write(`File: ${this.duplicate} is being created:`); readable.on('data', (chunk)=> { let percentageCopied = ((chunk.length * this.counter) / this.fileSize) * 100; process.stdout.clearLine(); // process.stdout.cursorTo(0); process.stdout.write(`${Math.round(percentageCopied)}%`); writeable.write(chunk); this.counter += 1; }); readable.on('end', (e) => { process.stdout.clearLine(); // process.stdout.cursorTo(0); process.stdout.write("Successfully finished the operation"); return; }); readable.on('error', (e) => { console.log("Some error occurred: ", e); }); writeable.on('finish', () => { console.log("Successfully created the file copy!"); }); }); We expect the user, running this program, to provide her with two file names. The first is the source file, the second is the name of its future copy. We create two streams - a stream for reading and a stream for writing, transferring data fragments from the first to the second. There are some auxiliary mechanisms. They are used to monitor the copying process and to display the relevant information in the console.
We use the event mechanism here, in particular, we are talking about subscribing to the following events:
data- called when reading a piece of data.end- called when the end of reading data from the stream for reading.error- called in case of an error in the data reading process.
With this program, the file size of 7.4 GB is copied without error messages.
$ time node streams_copy_basic.js cartoonMovie.mkv ~/Documents/4kdemo.mkv However, there is one problem. It can be revealed if you look at the data on the use of system resources by various processes.
System Resource Usage Data
Please note that the
node process, after copying 88% of the file, takes 4.6 GB of memory. This is a lot, such memory handling can interfere with the work of other programs.▍ Causes of excessive memory consumption
Note the speed of reading data from disk and writing data to disk from the previous illustration (
Disk Read and Disk Write columns). Namely, here you can see the following indicators: Disk Read: 53.4 MiB/s Disk Write: 14.8 MiB/s Such a difference in the read speeds from the data record means that the data source issues them much faster than the receiver can receive and process them. The computer has to keep in memory the read data fragments until they are written to disk. As a result, we see such indicators of memory usage.
On my computer, this program was executed 3 minutes 16 seconds. Here are the details of its progress:
17.16s user 25.06s system 21% cpu 3:16.61 total Solution 2: Copying files using streams and automatically setting the speed of reading and writing data
In order to cope with the above described problem, we can modify the program so that during the copying of files the read and write speeds of data are adjusted automatically. This mechanism is called back pressure. In order to use it, we do not need to do anything special. It is enough, using the
pipe() method, to connect the stream for reading to the stream for recording, and Node.js will automatically adjust the data transfer rates.streams_copy_efficient.js call this program streams_copy_efficient.js . Here is its code: /* pipe(). : Naren Arya */ const stream = require('stream'); const fs = require('fs'); let fileName = process.argv[2]; let destPath = process.argv[3]; const readable = fs.createReadStream(fileName); const writeable = fs.createWriteStream(destPath || "output"); fs.stat(fileName, (err, stats) => { this.fileSize = stats.size; this.counter = 1; this.fileArray = fileName.split('.'); try { this.duplicate = destPath + "/" + this.fileArray[0] + '_Copy.' + this.fileArray[1]; } catch(e) { console.exception('File name is invalid! please pass the proper one'); } process.stdout.write(`File: ${this.duplicate} is being created:`); readable.on('data', (chunk) => { let percentageCopied = ((chunk.length * this.counter) / this.fileSize) * 100; process.stdout.clearLine(); // process.stdout.cursorTo(0); process.stdout.write(`${Math.round(percentageCopied)}%`); this.counter += 1; }); readable.on('error', (e) => { console.log("Some error occurred: ", e); }); writeable.on('finish', () => { process.stdout.clearLine(); // process.stdout.cursorTo(0); process.stdout.write("Successfully created the file copy!"); }); readable.pipe(writeable); // ! }); The main difference of this program from the previous one is that the code for copying data fragments is replaced with the following line:
readable.pipe(writeable); // ! The basis of all that is happening here is the
pipe() method. It controls the speed of reading and writing, which leads to the fact that the memory is no longer overloaded.Run the program.
$ time node streams_copy_efficient.js cartoonMovie.mkv ~/Documents/4kdemo.mkv We are copying the same huge file. Now let's look at how the work with memory and disk looks like.
Using pipe (), read and write speeds are automatically adjusted.
Now we see that the
node process consumes only 61.9 MB of memory. If you look at the data on disk usage, you can see the following: Disk Read: 35.5 MiB/s Disk Write: 35.5 MiB/s Thanks to the back pressure mechanism, read and write speeds are now always equal to each other. In addition, the new program runs 13 seconds faster than the old one.
12.13s user 28.50s system 22% cpu 3:03.35 total Through the use of the
pipe() method, we were able to reduce program execution time and reduce memory consumption by 98.68%.In this case, 61.9 MB is the size of the buffer created by the data read stream. We can easily set this size by ourselves, using the
read() method of the stream to read the data: const readable = fs.createReadStream(fileName); readable.read(no_of_bytes_size); Here we copied the file to the local file system, but the same approach can be used to optimize many other data input / output tasks. For example, this is the work with data streams, the source of which is Kafka, and the receiver is the database. According to the same scheme, it is possible to organize data reading from a disk, their compression, as they say, “on the fly”, and writing back to disk already compressed. In fact, you can find many other applications for the technology described here.
Results
One of the goals of writing this article was to demonstrate how easy it is to write bad programs on Node.js, even though this platform gives the developer a great API. Paying some attention to this API, you can improve the quality of server software projects.
Dear readers! How do you work with buffers and threads in Node.js?
Source: https://habr.com/ru/post/433408/
All Articles