How using computer vision to assess the condition of the car. Experience Yandex.Taxi

We strive to ensure that after ordering a taxi to the user came a clean, serviceable car of the brand, the color and number that are displayed in the application. And for this we use remote quality control (DCC).
Today I will tell Habr's readers how to use machine learning to reduce the cost of quality control in a rapidly growing service with hundreds of thousands of machines and not to release a machine that does not comply with the rules of service.
How DCC was arranged before the arrival of machine learning
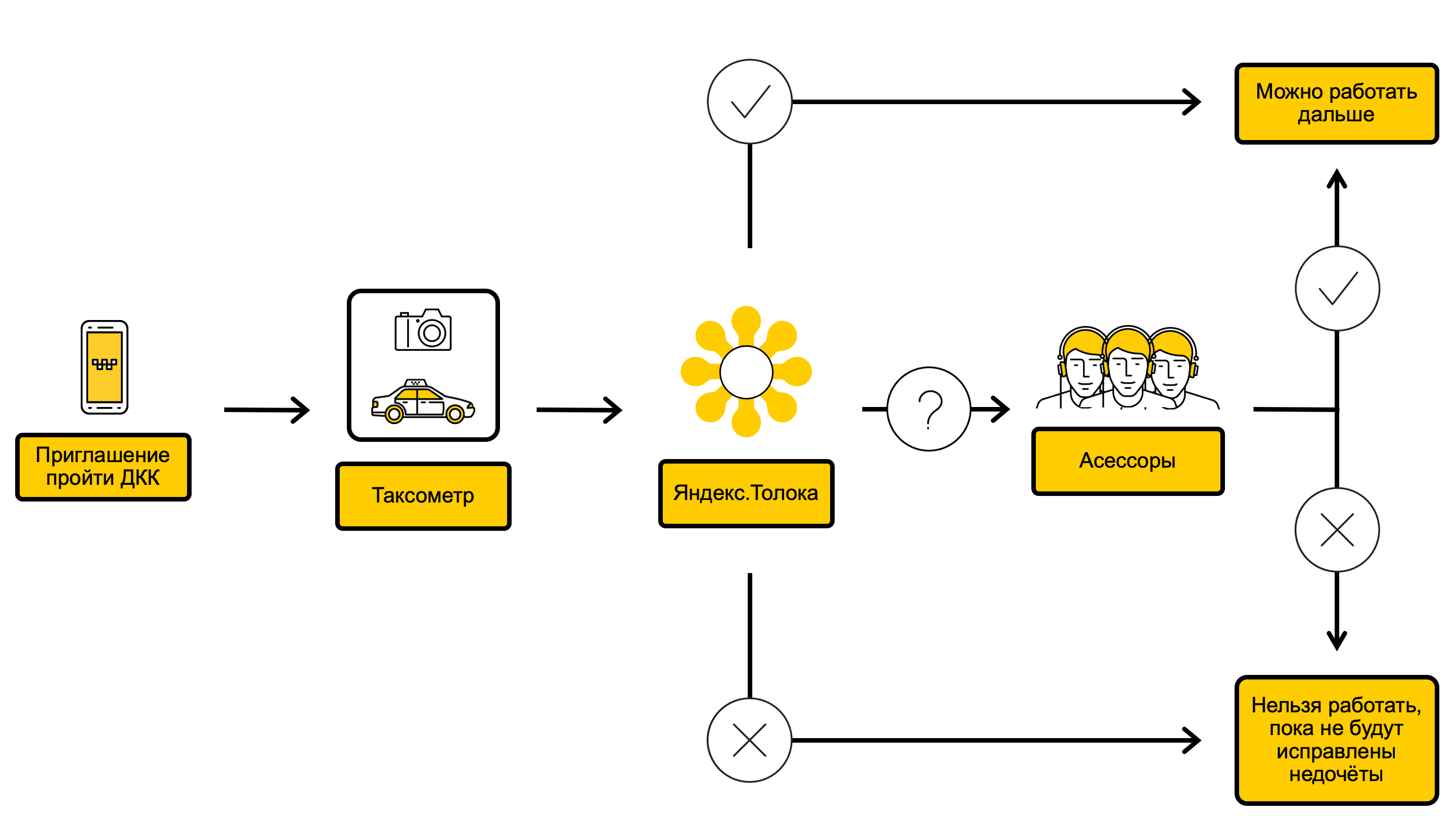
DCC process diagram
In the process of DCC, we check the photos of the car and decide whether it is possible to carry out orders for such a car or, for example, it is worth washing it before. It all starts with the fact that through the driver's application Taximeter we call the driver on the DCC. This usually happens once every 10 days, but sometimes less often or more often, depending on how well the driver passed the previous checks. Immediately after the call to the DCC, the driver receives a message inviting him to pass photo control. As soon as the driver accepted the invitation, in the same application he photographs the exterior and interior of the car from different angles and sends the photos to Yandex.Taxi. The driver can take orders while the DCC is in progress.

Start screen DCC in the application Taximeter

Screen photographing the car in the application Taximeter
The resulting photos get into Yandex. Toloku - a service where you can quickly perform simple, but large tasks using crowdsourcing. About how it is arranged and why Yandex.Tolok is needed, we wrote in our blog .
In Yandex.Talock, in the course of a single check, at least three performers answer questions about the condition of the car, and if the performers reach a consensus, based on their answers, a decision is made whether the driver can take orders. There are two outcomes for checking in Yandex.Stalk:
- If visually with the car everything is in order, the driver continues to take orders.
- If the car is dirty, damaged, or its brand, color or number does not correspond to those indicated in the driver card, Yandex.Taxi temporarily limits the driver’s ability to accept orders.
If the performers do not come to a common opinion, the photos are sent to the employees of Yandex.Taxi - assessors who check the car more carefully and then make the final decision. Assessors go through a special training program and have more experience.

So DCC sees Yandex.Toloki
Task
With the growth of Yandex.Taxi, the number of DCC checks is growing, which means that costs for toloker and assessors are rising. In addition, the speed of checking the car drops. While the DCC is underway, it is possible both to allow drivers to take orders and not to allow them. Both options have their drawbacks: in the first case, an unscrupulous driver will have time to take several orders for a car that does not meet the standards, in the second case, all drivers called to the photo control will not be able to work until the check is completed. Therefore, it is important to check cars quickly so that users and drivers do not experience any inconvenience.
Observing how cost charts and average test times grow, we realized that we want to reduce Toloka’s costs, unload assessors and shorten the average test time, in other words, automate some checks. Naturally, we did not want to sacrifice the quality of service and skip more inconsistent with the quality standards of cars on the line, and also did not want to limit the acceptance of orders by bona fide drivers. We needed to automate the DCC and at the same time not increase the proportion of errors in the general flow of checks.
How we implemented machine learning in DCC
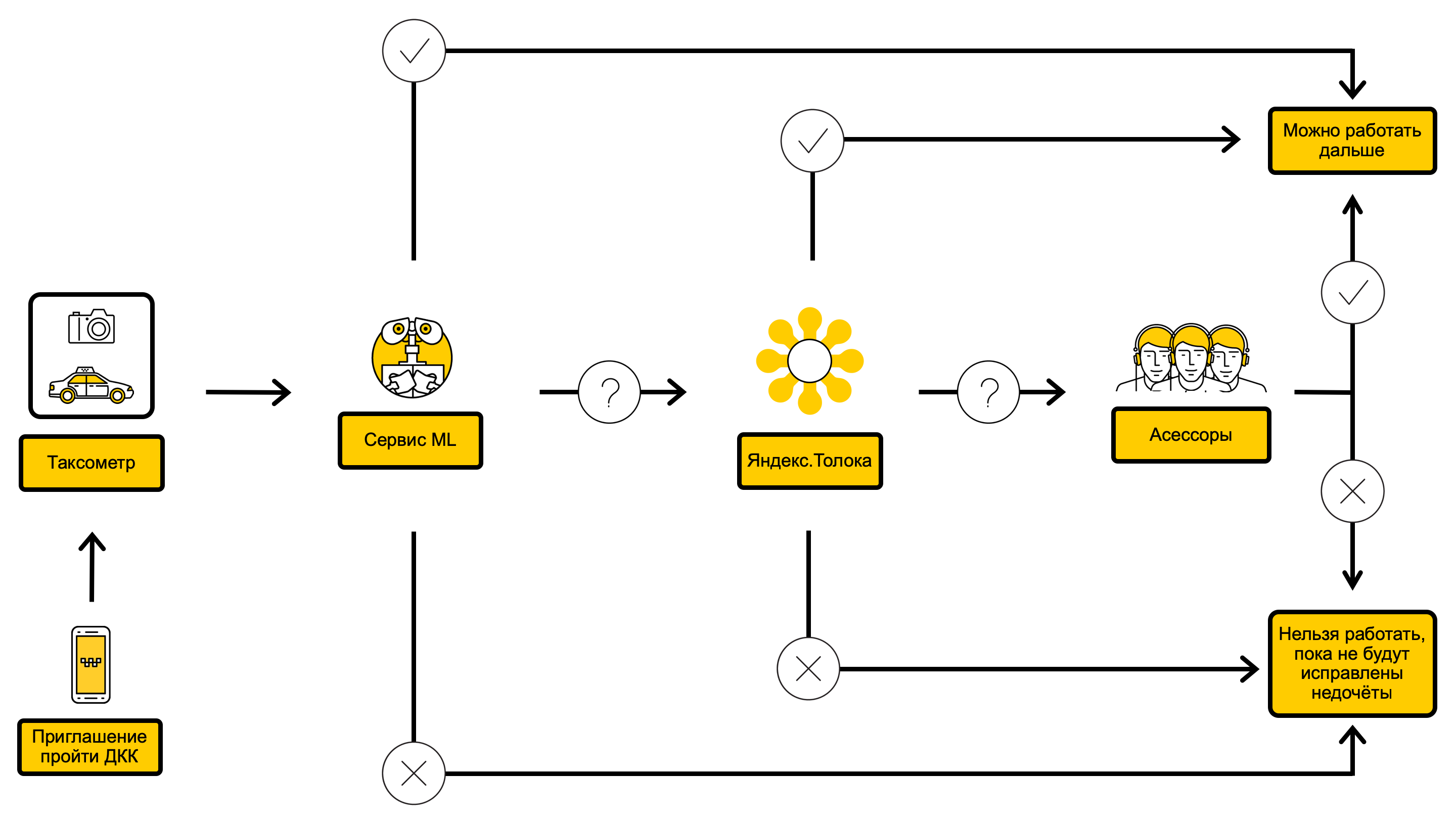
DCC process diagram with ML inside
For a start, we decided on the problem statement: to automate as many checks as possible without increasing the error rate in the general flow.
Let's deal with the fact that there are errors in our problem. They come in two forms: false positive and false negative . In our terminology, negative is the result of a check with which the driver can continue to work, and positive is the result that entails a temporary restriction on accepting orders. Then false negative is a case in which we were forced to allow a driver with a bad car to take orders, and false positive - on the contrary, when we were not allowed to work for a driver who is doing well with the car. It turns out that False Negative Rate (FNR) is the share of drivers with “bad” cars that we are allowed to accept orders, and False Positive Rate (FPR) is the proportion of drivers that we are not allowed to work with, although they are fine with cars. Thus, from the introduction of machine learning into the system we would like the following: to automate as many checks as possible, without increasing FPR and FNR in comparison with the system without machine learning.
Further, it was necessary to understand which metrics to focus on when choosing models and thresholds for making decisions based on their predictions. From the conditions of the problem it is clear that we are interested in three quantities:
- The fraction of the thread to which machine learning models can answer automatically.
- FNR system.
- FPR system.
We maximize the first value while respecting the limits for the second and third.
Then the question may arise: why not maximize the savings of money or minimize the average scan time directly, and not through the share of automated checks? Optimizing money is a very attractive idea, but usually difficult to implement. In our case, the savings consist of two factors: the first is the savings from each automated check, because each check at the assessors or at Yandex.Talk is worth the money; the second is savings from reducing the number of errors, because each error costs Yandex.Taxi money. Objectively, calculating how much mistakes cost us is a very difficult task, so we are limited to calculating savings only for the first factor. Such a value monotonously increases in the proportion of automated checks, so that it is possible to maximize this share instead of saving. The same reasoning applies to the average time of the DCC, it also monotonously decreases in terms of the proportion of automated checks.
Model selection
It can be said that checking the DCC is reduced to the choice of answer options for a number of questions about the condition of the car from its photographs, and this sounds like a problem of image classification. Such tasks are solved by computer vision, and in our time - a specific tool, convolutional neural networks. We decided to use them to automate the DCC.
The first solution or the “all at once” approach
Now that we understand what to optimize and why, it is time to collect data and train models on them. It was easy to collect data, because all DCC checks are logged and stored in the storage in a convenient form. In the first variant of the solution, the photos of the exterior and interior of the car from four angles, the make, model and color of the car, as well as the results of 10 previous DCC checks, served as signs. As target variables, we took answers to all verification questions, for example: “Is the car damaged?” Or “Does the color of the car match the one specified in the driver card?”. The main target variable was the answer to the main question: “Is it necessary to limit the ability of the driver to take orders?”. We learned one big model, very similar to VGG with SENet attention, to answer all the questions at the same time and as a result we ran into several problems.

“All at once” approach
Problems of the “all at once” approach:
- We could not answer the question about the compliance of the car number on the photo indicated in the driver card. A large network for classifying images could not cope with such a task, for this we need a special Optical Character Recognition (OCR) model, which is sharpened to recognize license plates.
- The target variable was incomplete and noisy. Finding a serious flaw in the appearance of the car, which was enough to make a decision, assessors often forgot to answer other questions. So, if the car in the photo was both dirty and broken, then with a high probability we observed only one of the marks: “dirty car” or “car with damages”, while for our model both were required.
- There was no interpretability of the model solution. The model could with an accuracy higher than the random answer the main question of verification, but this answer weakly correlated with the answers to other questions. In other words, if the answer was: “It is necessary to limit the ability to take orders”, we almost never saw the reason for such a decision in the rest of the model’s responses. In general, the accuracy of the answers to all questions, except the main one, was close to random. We could not explain to the driver what exactly needs to be corrected in order to take orders again, which means we could not restrict the driver’s ability to accept orders.
- The number of false negative errors in the answer to the question: “Is it necessary to limit the ability of the driver to take orders?” Was too large to begin to automatically approve the checks. We could not provide the same FNR, as in the system working without machine learning, and this was one of the requirements in our problem.
Together, these four reasons did not allow us to apply the first solution in practice, but we did not lose heart and came up with a second option.
The second solution, or the “all but gradually” approach
We decided to focus on the checks of the exterior of the car, because they make up about 70% of the total flow. In addition, we decided to split the general task into subtasks and learn how to answer all the DCC questions separately.

“Everything but gradually” approach
Once upon a time, our service already engaged in DCC automation and managed to implement a model that allows filtering dark and irrelevant photos. We continued to use this model further to answer the question: “Are the following real photos of the car present: front, left side, right side, rear?”.
Our work on the second solution began with the fact that we used the Yandex.Search computer vision service model (from the very people who made DeepHD ) to recognize license plates on cars. So we were able to answer the question: “Do the car’s region number and code correspond fully to the driver’s card?” In more detail, we compared the recognition result with the number indicated in the driver’s card and, depending on the Levenshtein distance between them, chose one of answer options: “the number is the same,” “the number does not match,” or “the question cannot be accurately answered”.
Next, we trained car classifiers to recognize brands and models, as well as colors. From this point on, we could answer the question: “Do the make, model and color of the car match the driver’s one?”
At the end, we trained the classifiers to find damaged and dirty cars; this allowed us to close the questions: “Are there any damages or defects on the car body?” And “How dirty is the car body?”
The “everything but gradually” approach allowed us to solve the problem of checking the car number. We were also able to get rid of the incompleteness and noisiness of the target variable, because now we had a sample where objects of class negative were completely successful checks, and objects of class positive were checks, where the assessor or all three Yandex.Toloki performers found a certain defect, for example, damage to the body . After solving the first two problems, our models became interpretable, and we could explain to the driver the reason for the restriction, so that by the next test he would correct the shortcomings. The overall quality of the answers to the questions also greatly increased, and FPR and FNR for some combinations of model thresholds dropped to the level of Yandex.Toloki, which allowed the models to be introduced into production.
Implementation in production
We had a choice: to launch a regular process that will apply models to checks accumulated in the queue, or make a separate service where you can go through the API and receive model responses in real time. Since it is important for us to quickly find "bad" cars, we chose the second option. As soon as the main part of the service was written and it was able to support the necessary functionality, we began to add models to it.
To fully approve the check, you need to be able to answer all questions of the instructions, but in order to restrict an unscrupulous driver to access the service, in some cases it is enough to be able to answer at least one question. Therefore, we decided not to wait until all the models are ready, but to add them as soon as they are ready. Generally, the add-in model add-on looks like this:
- Collect the sample.
- To train a model.
- Measure the quality and pick up thresholds offline.
- Add the model to the service in the background and measure the quality online.
- Include the model in production and start making decisions based on its predictions.
This approach allowed us not only to instantly find more and more “bad” cars as new models were introduced, but also to measure the quality online without additional time, while the models were working in the background.
In the end, the moment came when we added to the service and tested the latest model. Now we could answer all questions of checks, and therefore automatically approve them. Since the “good” cars in Yandex.Taxi are much more than the “bad” ones, automatic approval of checks led to a sharp increase in our main metric - part of the stream of automated checks. We had only to choose the right thresholds that would maximize the proportion of automated checks, while maintaining the overall FPR and FNR of the entire system at the same level. To select the thresholds, we used a sample that was independently marked by the Yandex.Toloki performers, assessors and a Yandex.Taxi employee who trained assessors to check cars. We used its markup as the true values of the target variable.
results
As soon as we included the models in the production, it was necessary to measure the online quality of the decisions made on the basis of their answers. And what numbers we saw:
- 30% of vehicle exterior checks now received an automatic response.
- FNR remained at the same level, but FPR fell, and we began to limit access to the service to those who did not deserve it less often.
- The load on assessors decreased by 14%, and they were able to spend more time on complex checks that the machine learning service could not take on.
- The time of detection of vehicles with serious shortcomings during the test was reduced from several hours to several seconds.
Thus, the introduction of machine learning not only helped save money, but also made it possible to make the service safer and more comfortable for users. However, this is far from the end of the story. Our rapidly growing team will continue to work actively to automate even more checks and make Yandex.Taxi even more convenient, comfortable and secure.
Moral of the story
In working on DCC automation in Yandex.Taxi, we encountered many problems, found several successful solutions and made six important conclusions:
- It is not always possible to solve the problem in the forehead (even if you have deep learning).
- The model is as good as the data on which it was trained (sounds trite, but it is).
- In solving any problem, it is important to build on the real needs of the business, and not on minimizing cross-entropy.
- In solving some problems, people are still important, despite the introduction of machine learning (hello, Yandex.Toloka!).
- Decisions based on predictions of machine learning models may not be made in all cases, but only in the part where the models are very confident in their answers. In other cases, it is probably worth making decisions in the old way - with the help of people.
- In addition to the choice of architecture and training model, there are many stages of the project, which can greatly affect how well the business problem will be solved. These stages are: data collection, selection of quality metrics, model implementation options, product logic of decision making based on model predictions, and much more.
More from interesting about technology Taxi
')
Source: https://habr.com/ru/post/433386/
All Articles