MIT course "Computer Systems Security". Lecture 21: "Tracking data", part 3
Massachusetts Institute of Technology. Lecture course # 6.858. "Security of computer systems". Nikolai Zeldovich, James Mykens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security methods based on the latest scientific work. Topics include operating system (OS) security, capabilities, information flow control, language security, network protocols, hardware protection and security in web applications.
Lecture 1: "Introduction: threat models" Part 1 / Part 2 / Part 3
Lecture 2: "Control of hacker attacks" Part 1 / Part 2 / Part 3
Lecture 3: "Buffer overflow: exploits and protection" Part 1 / Part 2 / Part 3
Lecture 4: "Separation of privileges" Part 1 / Part 2 / Part 3
Lecture 5: "Where Security Errors Come From" Part 1 / Part 2
Lecture 6: "Opportunities" Part 1 / Part 2 / Part 3
Lecture 7: "Sandbox Native Client" Part 1 / Part 2 / Part 3
Lecture 8: "Model of network security" Part 1 / Part 2 / Part 3
Lecture 9: "Web Application Security" Part 1 / Part 2 / Part 3
Lecture 10: "Symbolic execution" Part 1 / Part 2 / Part 3
Lecture 11: "Ur / Web programming language" Part 1 / Part 2 / Part 3
Lecture 12: "Network Security" Part 1 / Part 2 / Part 3
Lecture 13: "Network Protocols" Part 1 / Part 2 / Part 3
Lecture 14: "SSL and HTTPS" Part 1 / Part 2 / Part 3
Lecture 15: "Medical Software" Part 1 / Part 2 / Part 3
Lecture 16: "Attacks through the side channel" Part 1 / Part 2 / Part 3
Lecture 17: "User Authentication" Part 1 / Part 2 / Part 3
Lecture 18: "Private Internet browsing" Part 1 / Part 2 / Part 3
Lecture 19: "Anonymous Networks" Part 1 / Part 2 / Part 3
Lecture 20: “Mobile Phone Security” Part 1 / Part 2 / Part 3
Lecture 21: “Data Tracking” Part 1 / Part 2 / Part 3
Student: So, the ideal solution would be architectural support?
')
Professor: yes, there are methods for this too. However, this is a bit tricky, because, as you can see, we have highlighted the taint state next to the variable itself. Therefore, if you think about the support that the equipment itself provides, it can be very difficult to change the layout of the “iron”, because here everything is baked into silicon. But if this is possible at a high level in the Dalvic virtual machine, you can imagine that it will be possible to place a number of variables and their infection at the hardware level. So if you change the layout in silicon, then you can probably do this work.

Student: What does TaintDroid do with information that builds on git branch permissions, Branch permissions?
Professor: we will come back to this in a second, so just hold on to this thought until we get to it.
Student: curious, can there be a buffer overflow, because these things — variables and their infections — are added together?
Professor: this is a good question. One would hope that in a language like Java, there is no buffer overflow. But in the case of the C language, something catastrophic can happen, because if you somehow made a buffer overflow, and then rewrote taint tags for variables, their zero values will be set to the stacks and the data will freely leak into the network.
Student: I think all this can be predicted?
Professor: quite right. The issue of buffer overflow can be solved with the help of “canaries” - stack indicators, because if you have this data in the stack, then you do not want to make it not rewritable or you do not want the overwritten values to be hacked in some way. So you are absolutely right - you can simply avoid buffer overflow.
In short, at this low x86 / ARM level, taint can be tracked, although it can be a little expensive and a bit difficult to implement correctly. You may ask why we first of all solve the issue of tracking infections instead of watching how the program tries to send something over the network, simply by performing a scan of data that seems confidential to us. This seems pretty easy, because then we don’t need to dynamically track everything the program does.

The problem is that this will only work at the heuristic level. In fact, if the attacker knows that you are acting in this way, he can easily hack you. If you are just sitting there and trying to do a grep for social security numbers, an attacker can simply use base 64 encoding or do some other stupid thing, such as compression. Bypassing this type of filter is rather trivial, so in practice this is completely inadequate for security.
Now let's go back to your question about how we can track the flow through Branch. This will lead us to a topic called Implicit Flows, or Implicit Flows. An implicit flow usually occurs when you have an infected value that will affect the way you assign another variable, even if this implicit flow variable does not assign variables directly. I will give a specific example.
Suppose you have an if statement that looks at your IMEI and says: “if it is greater than 42, then I will assign x = 0, otherwise I will assign x = 1”.
Interestingly, we first consider the confidential IMEI data and compare it with a certain number, but then, by assigning x, we do not assign anything that would be obtained directly from this confidential data.
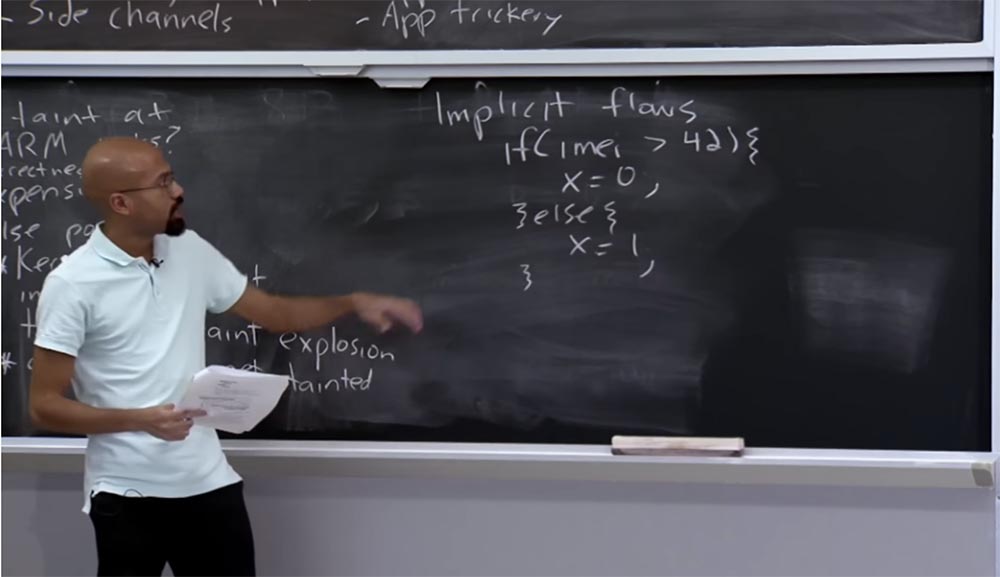
This is an example of one of the implicit flows. The value of x really depends on the comparison above, but an adversary, if he is smart, can build his code in such a way that no direct connection can be traced in it.
Note that even here, instead of simply assigning x = 0, x = 1, you can simply put a command to send something over the network, that is, you can say on the network that x = 0 or x = 1, or something like that. This is an example of one of these implicit flows that a system like TaintDroid cannot control. So, this is called an implicit stream, unlike an explicit stream, for example, an assignment operator. So developers know about this problem.
If I understood correctly, I was asked what would happen, if we have some kind of machine function that does something similar to the given example, and therefore the TaintDroid system does not need to know this, because TaintDroid cannot look into this machine code and see things this kind. By the way, the developers claim that they will manage this using computer-oriented methods, which are determined by the virtual machine itself, and they will consider the way this method is implemented. For example, we take these two numbers and then return their average value. In this case, the TaintDroid system will trust the engine function, so we need to figure out what the appropriate taint infection policy should be.
Nevertheless, you are right that if something like that was hidden inside the machine code and for some reason was not subjected to an open revision, then the manual policies that the authors of TaintDroid have come up with may not catch this implicit flow. In fact, this may allow information to somehow leak out. Moreover, there may even be a direct stream, which was not noticed by the authors of TaintDroid, and we may even have a more direct leak.

Student: that is, in practice, this seems very dangerous, right? Because you can literally erase all infected values just by looking at the last 3 lines.
Professor: we had several sessions where it was considered how implicit flows do such things. There are several ways to fix this. One way to prevent such things is to assign a taint tag to a PC; essentially, you infect it with the Branch test. The idea is that from a human point of view, we can examine this code and say that this implicit flow exists here, because in order to get here we had to delve into confidential data.
So what does this mean at the implementation level? This means that in order to get here, there must be something in the PC that has been infected by confidential data. That is, we can say that we obtained this data because the PC was installed here - x = 0 - or here - x = 1.
In general, you can imagine that the system will conduct some analysis and find out that in this place Implicit flows PC is not infected at all, then it picks up an infection from IMEI, and in this place, where x = 0, the PC is already infected. In the end, what happens is that if x is a variable that is initially displayed without taint, then we say: “OK, in this place x = 0, we get an infection from a PC that was actually infected above in IMEI”. There are some subtleties here, but in general it can be traced how the PC is installed and then tries to spread the infection to the target operators.
It's clear? If you want to learn more, then we can talk on this topic, because I have done a lot of research of this kind. However, the system I just described may again be too conservative. Imagine that instead of x = 1 here, like at the top, we also have x = 0. In this case, there is no point in infecting x with something related to IMEI, therefore no information can leak from these branches.
But if you use a PC infecting machine, you can overestimate how many x variables have been corrupted. There are some subtleties that you can do to try to get around some of these problems, but it will be a little difficult.
Student: when you exit the if statement, do you also exit the Branch, and are you cleansed of infection?
Professor: as a rule, yes, as soon as the set of variables ends, the PC will be cleared of infection. Infection is established only within these branches from x to x. The reason is that when you come down here, you do it no matter what IMEI was.
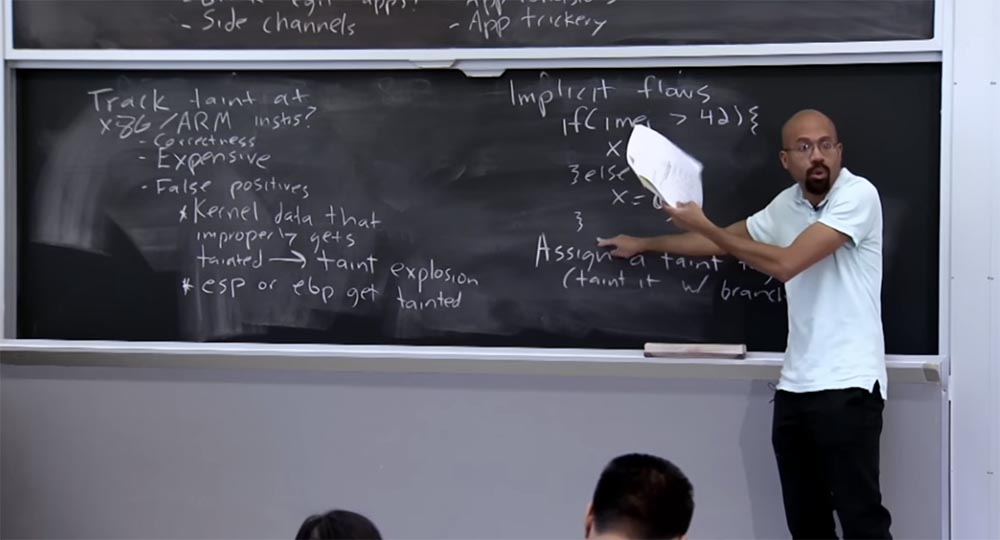
We said that tracking down infection at this very low level is useful, although quite expensive, because it will really allow you to see what your data has been like. A couple of lectures ago, we talked about the fact that quite often key data lives in memory much longer than you think.
You can imagine that while tracking infection at x86 or ARM is quite expensive, you can use this to audit your system. For example, you can infect a certain secret key that the user entered, and trace where and how it moves throughout the system. This is an autonomous analysis, it does not affect users, so it’s normal that it can be slow. Such an analysis will help to find out that, for example, this data falls into the keyboard buffer, these are on an external server, these are somewhere else. So even if it is a slow process, it can still be very useful.
As I said before, a useful feature of TaintDroid is that it limits the “universe” of sources of infection and sinks of infected information. But as a developer, you probably want to have more precise control over the infection tags that your program interacts with. Therefore, as a programmer, you will want to do the following.
So, you declare some int of this kind and call it X, and then associate a label with it. The meaning of this tag is that Alice owns the information that she allows Bob to view, or this information is marked to be viewed by Bob. TaintDroid does not allow you to do this, because it essentially controls this universe of tags, but as a programmer, you may want to do this.
Suppose your program has input and output channels, and they are also tagged. These are the labels that you chose as a programmer, unlike the system itself, trying to say that such things are predetermined in advance. Let's say for input channels you set the read values that get the channel label.
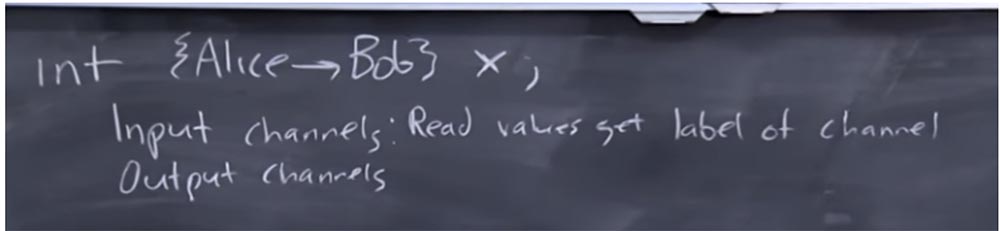
This is very similar to how TaintDroid works - if the GPS sensor values are read, they are marked with the taint tag of the GPS channel, but now you, as a programmer, choose these labels. In this case, the label of the output channel must match the value of the label that we recorded.

Here you can imagine other policies, but the main idea is that there are program managers that allow the developer to choose what these labels are and what their semantics can be. This will require a lot of work from the programmer, the result of which will be the ability to perform a static check. By static, I mean a check that is performed at compile time and can “catch” many types of information flow errors.
So if you carefully label all the network channels and screen channels with the appropriate permissions, and then carefully place your data, which is shown on the board as an example, then the compiler will tell you at the time of compilation: “hey, if you run this program, then you may leak information, because some of the data will pass through the channel, which is not trusted. "
At a high level, a static check will catch a lot of such errors, because such comments int {Alice Bob} x are a bit like types. Just as compilers can catch type-related errors in a type language, they can work just as well with code written in the above language, saying that if you run this program, it can be a problem. Therefore, you need to correct how the labels work, you may need to declassify something, and so on.
Thus, depending on the language, these tags can be associated with people, with I / O ports and things like that. TaintDroid gives you the opportunity to become familiar with the principles of information flow and information leakage, but there are more complex systems with more pronounced semantics of managing these processes.
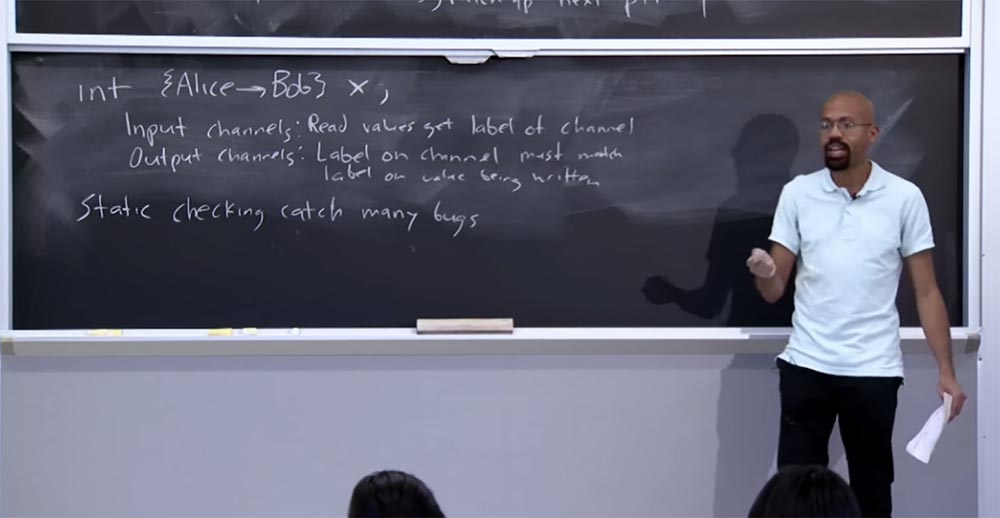
Consider that when we talk about static checking, it is preferable for us to catch as many failures and errors as possible with the help of statistical testing rather than dynamic checking. There is a very delicate reason for this. Suppose that we postpone all static checks for the duration of the program, which we can definitely do.
The problem is that the failure or success of these checks is an implicit channel. Thus, an attacker can provide the program with some information, and then check to see if this has caused the program to crash. If a failure occurs, the hacker can say: “aha, we have passed some dynamic testing of the flow of information, which means there is some secret here regarding the values that affect the calculation process”. Therefore, you will want to try to make these checks as static as possible.
If you want more information about these things, you should read Jif. This is a very powerful system that created methods for computing labels labels. You can start from there and move on in this direction. My colleague, Professor Zeldovich, did a lot of good in this area, so you can talk to him about it.
Interestingly, TaintDroid is very limited in the possibilities of viewing and describing tags. There are systems that allow you to do more powerful things.
Finally, I would like to talk about what we can do if we want to track information flows using traditional programs or using programs written in C or C ++ that do not support all these things during the execution of the code. There is a very reasonable TightLip system, and some of the authors of the same article are considering how to track information leaks in a system in which we don’t want to change anything in the application itself.
The basic idea is that the concept of doppelganger processes, or "process twins", is found here. System TightLip by default uses a twin process. The first thing it does is periodically scan the user's file system, looking for confidential file types. It could be something like email files, text documents, and so on. For each of these files, the system creates its “cleaned up” version. That is, in the email message file, it replaces the information “to” or “from whom” with a string of the same length containing dummy data, such as spaces. This is done as a background process.
The second thing TightLip does when it starts a process is that it determines if the process is trying to access the confidential file. If such access takes place, TightLip creates a twin of this process. This twin looks exactly the same as the original process that tries to affect confidential data, but the fundamental difference is that the twin, I will designate it as DG, reads the cleaned data.

Imagine a process is running that is trying to access your email file. The system spawns this new process, doppelganger, exactly the same as the original, but now it reads cleaned data instead of real confidential data. In fact, TightLip runs both of these processes in parallel and watches them to see what they are doing. , , , . , , - , , – , , , -, .

, , TightLip , . , . , , , , . , TaintDroid, , : «, , , , - ».
, , , - . TaintDroid, , - , . — , — . , , , , , .
: , - Word, , - .
: , . , . . Word. - , - , . .
: , , ? - .
: , . , , , - , . , . «» , , , .
, , , , , , , .

– , TightLip TCB, , -, . , . . , , . TightLip.
, . taint .
: , ? , ?
: ! - DG , , . , , , -, , .
, .
.
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until January free of charge if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?
Source: https://habr.com/ru/post/433380/
All Articles