Sharding theory
It seems that we have plunged so deeply into the jungle of highload development that we simply do not think about basic problems. Take sharding, for example. What to understand it, if you can write conditionally shards = n in the database settings, and everything will be done by itself. So, he is like that, but if, rather, when something goes wrong, the resources really start to be missed, I would like to understand what the reason is and how to fix it.
In short, if you contribute your alternative implementation of hashing in Cassandra, then there are hardly any revelations for you here. But if the load on your services is already arriving, and the system knowledge does not keep up with it, then you are welcome. The great and terrible Andrei Aksyonov ( shodan ), in his characteristic manner, will tell you that sharding is bad, not sharding is also bad , and how it is arranged inside. And quite by accident, one of the parts of the story about sharding is not really about sharding, but the devil knows what - like objects on shards mapit.

A photo of cats (although they happened to be puppies) already answers the question why this is all, but we will begin sequentially.
What is "sharding"
If you persistently google, it turns out that there is a fairly blurred border between the so-called partitioning and the so-called sharding. Everyone calls everything he wants, what he wants. Some people distinguish horizontal partitioning and sharding. Others say that sharding is a certain kind of horizontal partitioning.
I did not find a single terminological standard that would be approved by the founding fathers and is ISO certified. Personal inner conviction is approximately like this: Partitioning on average is “cutting the base into pieces” in an arbitrary manner.
')
The awkward moment here is in the subtle difference between horizontal partitioning and sharding. You can cut me into pieces, but I surely will not tell you what it is. There is a feeling that sharding and horizontal partitioning are about the same thing.
Sharding is generally when a large table in terms of databases or a collection of documents, objects, if you do not have a database at all, but a document store, is cut by objects. That is, out of 2 billion objects, pieces are selected no matter what size. The objects themselves inside each object are not cut into pieces; we do not lay them out into separate columns, but lay them out in different places in bundles.
Link to the presentation to complete the picture.
Next came the subtle terminological differences. For example, relatively speaking, the developers at Postgres can say that horizontal partitioning is when all the tables into which the main table is divided lie in the same schema, and when on different machines it is sharding.
In a general sense, without being tied to the terminology of a specific database and a specific data management system, there is a feeling that sharding is just cutting by lines and documents and so on — and that’s all:
I emphasize typically. In the sense that we are doing all this for a reason, so as to cut 2 billion documents into 20 tables, each of which would be more manageable, but in order to distribute it into many cores, many disks or many different physical or virtual servers .
The implication is that we do this so that every shard — every bit of data — replicates many times. But really, no.
In fact, if you do this data cutting, you will generate 16 small tablets from one giant SQL table on MySQL on your glorious laptop, without going beyond a single laptop, a single schema, a single database, etc. etc. - everything, you have sharding.
Remembering the illustration with the puppies, this leads to the following:
Why bandwidth? We sometimes can have such amounts of data that do not interpose - it’s not clear where, but not intermediation - per 1 {core | disk | server | ...}. Just not enough resources and everything. In order to work with this big dataset, you need to cut it.
Why latency? On one core, scanning a table of 2 billion rows is 20 times slower than scanning 20 tables on 20 cores, making it parallel. Data is too slowly processed on one resource.
Why high availability? Or we cut the data in order to do both one and the other at the same time, and at the same time several copies of each shard - replication ensures high availability.
A simple example of "how to make hands"
Conditional sharding can be cut using the test table test.documents for 32 documents, and by generating 16 test tables from this table for approximately 2 documents test.docs00, 01, 02, ..., 15.
Why about? Because a priori, we do not know how id is distributed, if from 1 to 32 inclusively, then there will be exactly 2 documents each, otherwise - no.
We do this for what it is. After we have made 16 tables, we can “grab” 16 of what we need. Regardless of where we stand, we can parallelize these resources. For example, if there is not enough disk space, it would make sense to decompose these tables into separate disks.
All this, unfortunately, is not free. I suspect that in the case of the canonical SQL standard (I haven’t reread the SQL standard for a long time, perhaps it hasn’t been updated for a long time), there is no official standardized syntax for any SQL server to say: “Dear SQL server, make me 32 shards and decompose them into 4 disks. ” But in individual implementations, there is often a specific syntax in order to do the same thing in principle. PostgreSQL has mechanisms for partitioning, MySQL has MariaDB, Oracle probably did it all a long time ago.
However, if we do it by hand, without database support and within the standard, we conditionally pay for the complexity of data access . Where there was a simple SELECT * FROM documents WHERE id = 123, now 16 x SELECT * FROM docsXX. And well, if we tried to get the record by key. Much more interesting if we tried to get an early range of records. Now (if we, I emphasize, like fools, and remain within the standard) the results of these 16 SELECT * FROM will have to be combined in the application.
What performance changes to expect?
In fact, the correct answer is unknown. With dexterous use of the sharding technique, you can achieve a significant superlinear degradation of your application, and DBA will come running with a hot poker.
Let's see how this can be achieved. It is clear that simply putting the setting in PostgreSQL shards = 16, and then it itself took off - it is not interesting. Let's think about how we can ensure that we can slow down 32 times from sharding - this is interesting from the point of view how not to do this.
Our attempts to accelerate or slow down will always rest on the classics - in the good old Amdahl law, which says that there is no perfect parallelization of any query, there is always some consistent part.
Amdahl law
There is always a part of the execution of the request that is parallel, and there is always a part that does not parallel. Even if it seems to you that there is a perfectly parallel query, at least the collection of the result string that you are going to send to the client, from the strings received from each shard, is always there, and it is always consistent.
There is always some consistent part. It can be tiny, completely imperceptible on the general background, it can be gigantic and, accordingly, strongly affecting parallelization, but it always is.
In addition, its influence is changing and can significantly grow, for example, if we cut our table - let's raise the rates - from 64 entries to 16 tables with 4 entries, this part will change. Of course, judging by such gigantic amounts of data, we work on a mobile phone and an 86 2 MHz processor, and we don’t have enough files that can be kept open at the same time. Apparently, with such input, we open one file at a time.
With this simple example, I'm trying to show that some kind of Xserial appears. In addition to the fact that there is always a serialized part, and the fact that we are trying to work with data in parallel, an additional part appears to provide this data slicing. Roughly speaking, we may need:
Any out-of-sync effects will still appear. They may be insignificant and take one billion dollars from the total time, but they are always non-zero and always are. With their help, we can dramatically lose in performance after sharding.
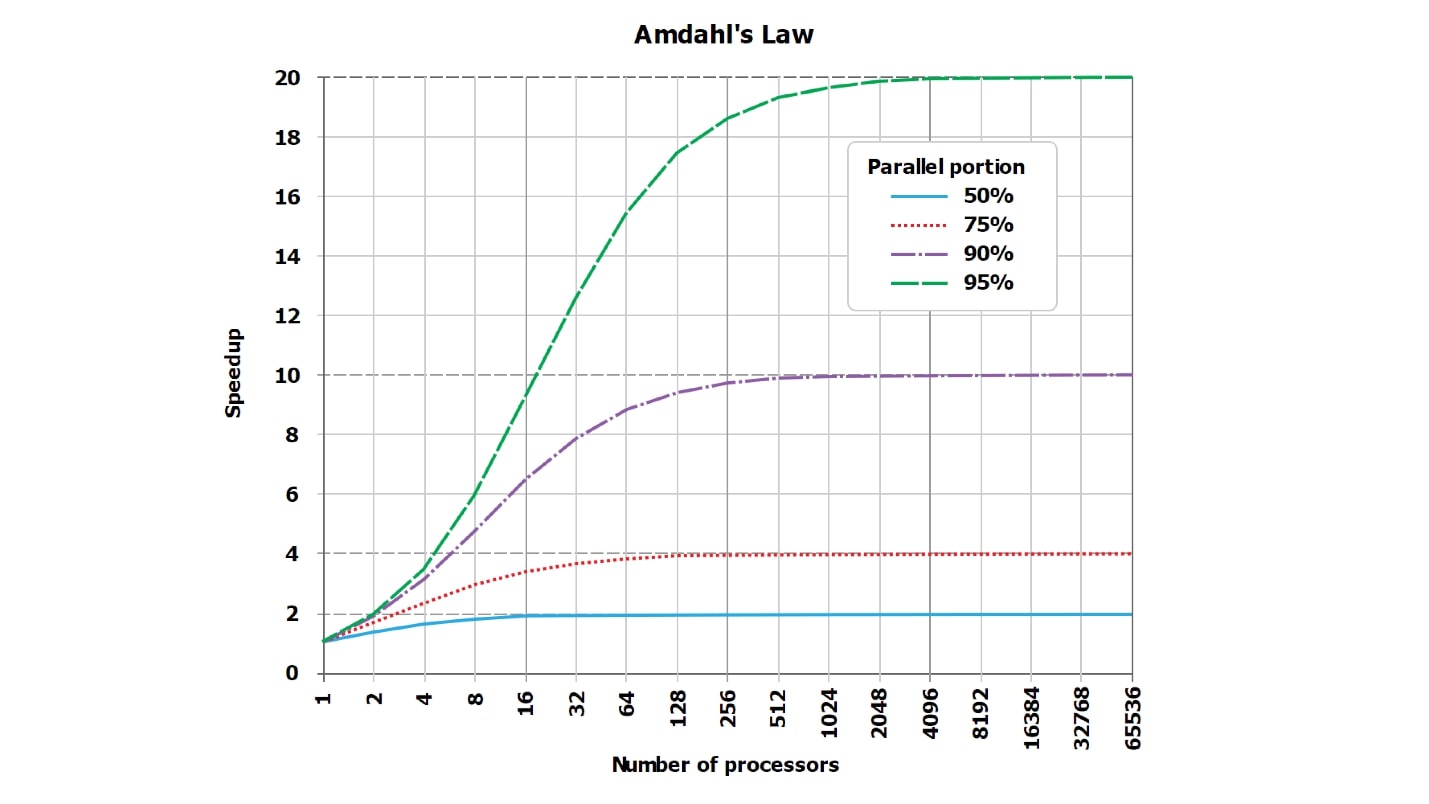
This is a standard picture about the law of Amdal. It is not very readable, but it is important that the lines, which should ideally be straight and linearly grow, abut on the asymptote. But since the schedule from the Internet is unreadable, I have made, in my opinion, more visual tables with numbers.
Suppose that we have a certain serialized part of the request processing, which takes only 5%: serial = 0.05 = 1/20.
Intuitively, it would seem that with the serialized part, which takes only 1/20 of the request processing, if we parallelize the processing of the request for 20 cores, it will become approximately 20, at worst 18, times faster.
In fact, mathematics is heartless :
It turns out that if you carefully calculate, with the serialized part of 5%, the acceleration will be 10 times (10.3), and this is 51% compared with the theoretical ideal.
Using 20 cores (20 disks, if you like) for the task on which one worked earlier, we even theoretically will never get more than 20 times the acceleration, and in practice much less. Moreover, with an increase in the number of parallels, inefficiency is greatly increasing.
When only 1% of the serialized work remains and 99% are parallelized, the acceleration values are somewhat improved:
For a completely thermonuclear query that is naturally executed for hours, and the preparatory work and the assembly of the result take very little time (serial = 0.001), we will see already good efficiency:
Please note 100% we will never see . In particularly good cases, you can see, for example, 99.999%, but not exactly 100%.
How to chuff and repeat N times?
It is possible to fool and repeat exactly N times:
In this case, the serialized part (serial) occupies not 1% and not 5%, but approximately 20% in modern databases. You can also get 50% of the serialized part by accessing the database using a wildly efficient binary protocol or linking it as a dynamic library to a Python script.
The rest of the processing time of a simple request will be occupied by non-parallelized operations of parsing the request, preparing the plan, etc. That is, it does not read the record.
If we divide the data into 16 tables and start sequentially, as is customary in the PHP programming language, for example, (he is not very good at starting asynchronous processes), then we’ll get a slowdown 16 times. And maybe even more, because network round-trips will also be added.
Remember about the choice of programming language, because if you send queries to the database (or search server) sequentially, then where does the acceleration come from? Rather, there will be a slowdown.
Bike from life
If you choose C ++, write to POSIX Threads , not Boost I / O. I saw an excellent library from experienced developers from Oracle and MySQL, who wrote a conversation with the MySQL server on Boost. Apparently, at work they were forced to write on pure C, and then they managed to turn around, take Boost with asynchronous I / O, etc. One problem is that this asynchronous I / O, which theoretically should have driven 10 requests in parallel, for some reason it had an imperceptible synchronization point inside. When you run 10 queries in parallel, they were executed exactly 20 times slower than one, because 10 times for the queries themselves and again for the synchronization point.
Conclusion: write in languages that implement parallel execution and waiting for different requests well. I do not know, to be honest, what exactly is there to advise, besides Go. Not only because I love Go, but because I don’t know anything more suitable.
Do not write in useless languages in which you will not be able to run 20 parallel queries to the database. Or at every opportunity do not do it all by hand - understand how it works, but do not do it manually.
A / B dough
Still sometimes you can slow down, because you are used to, that everything works, and did not notice that the serialized part, firstly, is, secondly, large.
This is a bike from the production, when the search queries were changed a little and they started to choose a lot more documents from the 60 shards of the search index. Everything worked quickly and according to the principle: “It works — don't touch it”, they all forgotten that there are actually 60 shards inside. Increased the sampling limit for each shard from a thousand to 50 thousand documents. Suddenly it began to slow down and the parallel ceased. The requests themselves, which were performed by shards, flew quite well, and the stage slowed down, when 50 thousand documents were collected from 60 shards. These 3 million final documents on one core merged together, sorted, the top of 3 million was selected and given to the client. The same serial part slowed down, the same merciless Amdal law worked.
So maybe you should not do sharding with your hands, but just like a human
say database: "do it!"
Disclaimer: I do not really know how to do something right. I type from the wrong floor !!!
I have all my life promoting a religion called "algorithmic fundamentalism." It is briefly stated very simply:
Let's consider the options:
It is difficult to tell something about an automaton, except for how to send to the documentation on the corresponding database (MongoDB, Elastic, Cassandra, ... in general, the so-called NoSQL). If you are lucky, then you just pull the switch “make me 16 shards” and everything will work. At the moment when it does not work itself, the rest of the article may be necessary.
Pro semiautomatic
Mostly, the delights of information technology inspire chthonic horror. For example, MySQL out of the box did not have a sharding implementation to certain versions exactly, nevertheless, the sizes of the bases used in battle grow to indecent values.
Suffering humanity in the face of individual DBA has been tormented for years and writes several bad sharding solutions, built incomprehensibly on what. After that, one more or less decent sharding solution is written under the name ProxySQL (MariaDB / Spider, PG / pg_shard / Citus, ...). This is a well-known example of this same snip.
ProxySQL as a whole, of course, is a complete enterprise-class solution for open source, for routing and so on. But one of the tasks to be solved is the sharding for the database, which in itself cannot be human shard. You see, there is no “shards = 16” switch, you have to either rewrite each request in the application, and there are many of them in places, or put some intermediate layer between the application and the database: “Hmm ... SELECT * FROM documents? Yes, it should be broken to 16 small SELECT * FROM server1.document1, SELECT * FROM server2.document2 - to this server with the same login / password, to this with another. If one did not answer, then ... "etc.
Intermediate hooks can do this exactly. They are a little less than for all databases. For PostgreSQL, as I understand it, at the same time there are some built-in solutions (PostgresForeign Data Wrappers, in my opinion, built into PostgreSQL itself), there are external patches.
Configuring each specific patch is a separate giant topic that does not fit in one report, so we will discuss only the basic concepts.
Let's talk the best about the theory of buzz.
Absolute perfect automatics?
The whole theory of buzz in the case of sharding in this letter F (), the basic principle is always the same roughly:
Sharding is all about what? We have 2 billion records (or 64). We want to split them into several pieces. There is an unexpected question - how? According to what principle should I scatter my 2 billion records (or 64) on the 16 servers available to me?
The latent mathematician in us must suggest that in the end there is always some kind of magic function that, for each document (object, line, etc.), determines in which piece to put it.
If you go deeper into mathematics, this function always depends not only on the object itself (the line itself), but also on external settings such as the total number of shards. The function, which for each object should tell where to put it, cannot return a value greater than there are servers in the system. And the functions are slightly different:
But further we will not dig in these jungle of separate functions, we will just talk what magic functions F () are.
What are F ()?
They can come up with many different and many different implementation mechanisms. Sample summary:
An interesting fact - you can naturally scatter all data randomly - we throw the next entry on an arbitrary server, on an arbitrary kernel, into an arbitrary table. There will be no happiness in this, but it will work.
There are slightly more intelligent methods of sharding by reproducible or even consistent hash functions, or sharding by some attribute. Let's go through each method.
F = rand ()
Scattering radomom - not very correct method. One problem: we scattered our 2 billion records per thousand servers randomly, and we don’t know where the record is. We need to pull out user_1, but we don’t know where it is. We go to a thousand servers and go through everything - somehow it is inefficient.
F = somehash ()
Let's scatter users in an adult way: read the reproducible hash function from user_id, take the remainder by dividing by the number of servers and access the right server immediately.
And why are we doing this? And then, that we have highload and we don’t have anything else in one server. If intermeddle, life would be so simple.
Great, the situation has already improved, to get one entry, we are going to one previously known server. But if we have a range of keys, then in all of this range we have to go through all the key values and, in the limit, go either to as many shards as we have keys in the range, or to each server in general. The situation, of course, improved, but not for all requests. Some requests suffered.
Natural sharding (F = object.date% num_shards)
Sometimes, that is often, 95% of the traffic and 95% of the load are requests that have some kind of natural sharding. , 95% - 1 , 3 , 7 , 5% . 95% , , , .
, , , - .
— , . , , , , . 5 % .
, :
, — , - .
, , , , . « - ».
«». , .
1. :
, , .
, / , , , PM ( , PM ), . .
, . , , 100 . .
, , , , - .
2. «» : , join
, ?
: , !
, , , . . (, , document store ), , .
— - . . , . , , , . - , , , , — .
, .
3. / :
: , .
, , , . , , , 10 , - 30, 100 . . — , - — , - .
, : 16 -, 32. , 17, 23 — . , , - ?
: , , .
, «», « ».
#1.
, 2 , , . : 17 , 6 , 2 , 17 23 . 10 , , . .
#2.
— — 17 23, 16 32 ! , .
, , . , , .
, . , 16 16, — .
, — .
#3. Consistent hashing
, consistent hashing
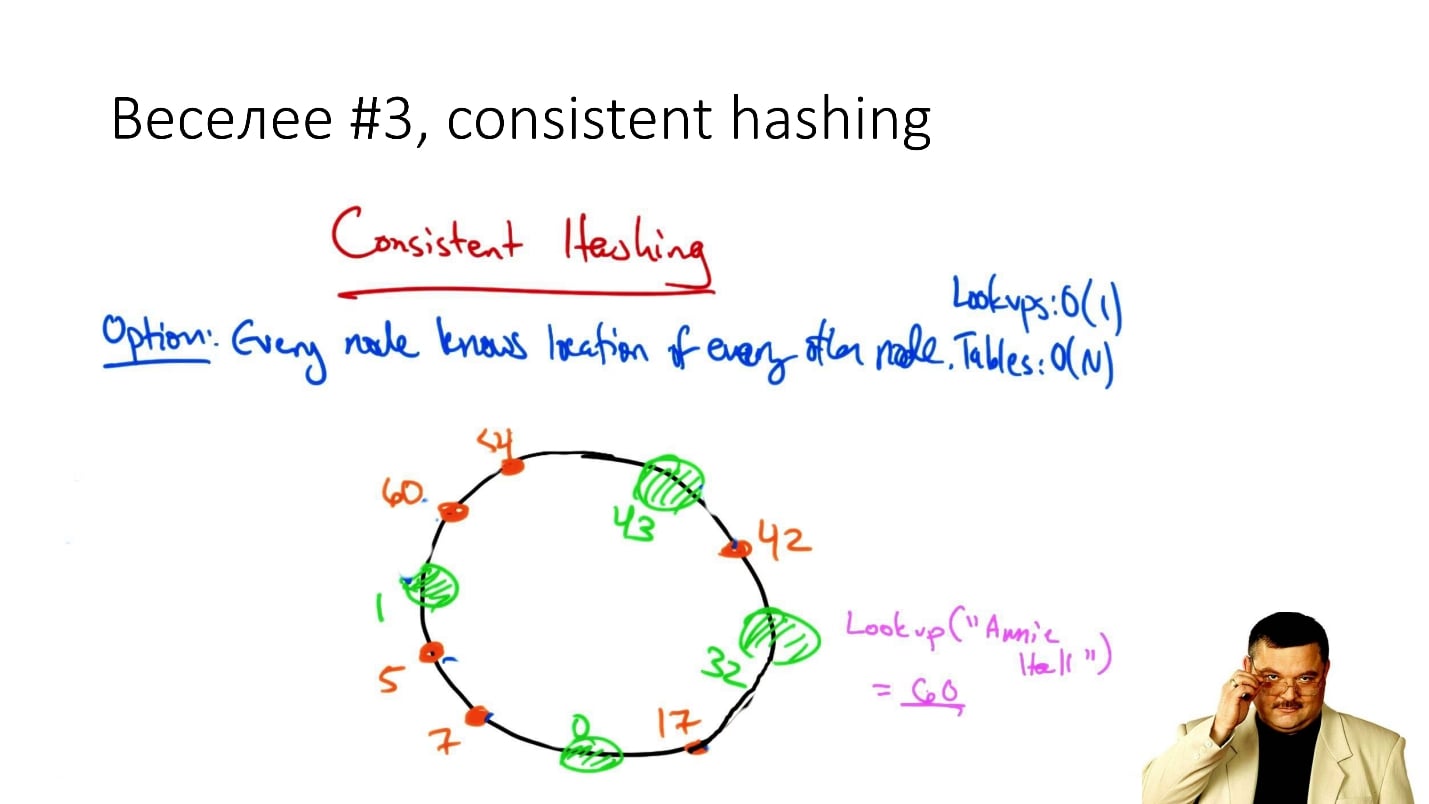
«consistent hashing», , .
: () , . , , , ( , ), .
, . , , , : , .
. , . , .., . , - , , .
, , , Cassandra . , , , , , .
, — / , , .
, : ? ? — , !
#4. Rendezvous/HRW
( , ): shard_id = arg max hash(object_id, shard_id).
Rendezvous hashing, , , Highest Random Weight. :
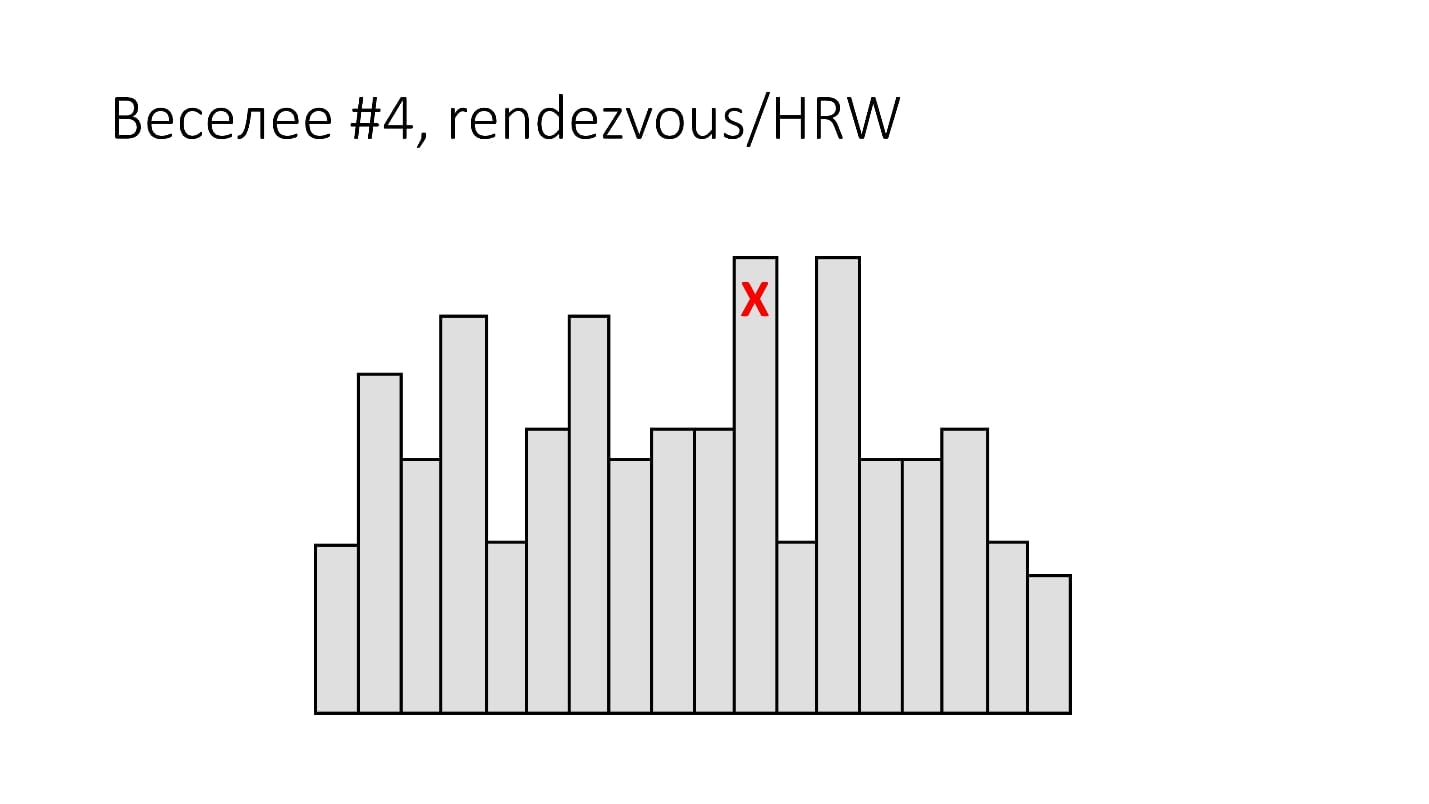
, , 16 . (), - , 16 , . -, .
HRW-hashing, Rendezvous hashing. , -, , .
, . , - - . .
, .
#5.
, Google - :
, . , , , -, . .
#6. Lists
— . ? , 2 , object_id 2 , .
, ? ?
. , - , , . , , , , .
:
2 - 16 — 100 - . : , , — 1 . , , .
, , , - , .
findings
: « , !». , 20 .
, , . , — . 100$ , . -, . — .
, , «» (, DFS, ...) . , , highload - . , , - . — , .
F() , , , .. , , 2 .
, , . HighLoad++ , , —Sphinx—highload , .
Highload User Group. , .
, , HighLoad++ . , , . , , . highload-, .
, , , . , , , .
24 - «», « ». , . , .
In short, if you contribute your alternative implementation of hashing in Cassandra, then there are hardly any revelations for you here. But if the load on your services is already arriving, and the system knowledge does not keep up with it, then you are welcome. The great and terrible Andrei Aksyonov ( shodan ), in his characteristic manner, will tell you that sharding is bad, not sharding is also bad , and how it is arranged inside. And quite by accident, one of the parts of the story about sharding is not really about sharding, but the devil knows what - like objects on shards mapit.
A photo of cats (although they happened to be puppies) already answers the question why this is all, but we will begin sequentially.
What is "sharding"
If you persistently google, it turns out that there is a fairly blurred border between the so-called partitioning and the so-called sharding. Everyone calls everything he wants, what he wants. Some people distinguish horizontal partitioning and sharding. Others say that sharding is a certain kind of horizontal partitioning.
I did not find a single terminological standard that would be approved by the founding fathers and is ISO certified. Personal inner conviction is approximately like this: Partitioning on average is “cutting the base into pieces” in an arbitrary manner.
')
- Vertical partitioning - pokolonochno. For example, there is a giant table for a couple of billion entries in 60 columns. Instead of holding one such gigantic table, we hold 60 not less giant tables of 2 billion records - and this is not a column basis, but vertical partitioning (as an example of terminology).
- Horizontal partitioning - we cut line by line, maybe, inside the server.
The awkward moment here is in the subtle difference between horizontal partitioning and sharding. You can cut me into pieces, but I surely will not tell you what it is. There is a feeling that sharding and horizontal partitioning are about the same thing.
Sharding is generally when a large table in terms of databases or a collection of documents, objects, if you do not have a database at all, but a document store, is cut by objects. That is, out of 2 billion objects, pieces are selected no matter what size. The objects themselves inside each object are not cut into pieces; we do not lay them out into separate columns, but lay them out in different places in bundles.
Link to the presentation to complete the picture.
Next came the subtle terminological differences. For example, relatively speaking, the developers at Postgres can say that horizontal partitioning is when all the tables into which the main table is divided lie in the same schema, and when on different machines it is sharding.
In a general sense, without being tied to the terminology of a specific database and a specific data management system, there is a feeling that sharding is just cutting by lines and documents and so on — and that’s all:
Sharding (~ =, \ in ...) Horizontal Partitioning == is typical.
I emphasize typically. In the sense that we are doing all this for a reason, so as to cut 2 billion documents into 20 tables, each of which would be more manageable, but in order to distribute it into many cores, many disks or many different physical or virtual servers .
The implication is that we do this so that every shard — every bit of data — replicates many times. But really, no.
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15 In fact, if you do this data cutting, you will generate 16 small tablets from one giant SQL table on MySQL on your glorious laptop, without going beyond a single laptop, a single schema, a single database, etc. etc. - everything, you have sharding.
Remembering the illustration with the puppies, this leads to the following:
- Increases bandwidth - bandwidth.
- Latency does not change, that is, everyone, so to speak, a worker or consumer in this case, gets his own. It is not known what puppies get in the picture, but requests are serviced in about one time, as if the puppy were alone.
- Either the one and the other, and more high availability (replication).
Why bandwidth? We sometimes can have such amounts of data that do not interpose - it’s not clear where, but not intermediation - per 1 {core | disk | server | ...}. Just not enough resources and everything. In order to work with this big dataset, you need to cut it.
Why latency? On one core, scanning a table of 2 billion rows is 20 times slower than scanning 20 tables on 20 cores, making it parallel. Data is too slowly processed on one resource.
Why high availability? Or we cut the data in order to do both one and the other at the same time, and at the same time several copies of each shard - replication ensures high availability.
A simple example of "how to make hands"
Conditional sharding can be cut using the test table test.documents for 32 documents, and by generating 16 test tables from this table for approximately 2 documents test.docs00, 01, 02, ..., 15.
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15 Why about? Because a priori, we do not know how id is distributed, if from 1 to 32 inclusively, then there will be exactly 2 documents each, otherwise - no.
We do this for what it is. After we have made 16 tables, we can “grab” 16 of what we need. Regardless of where we stand, we can parallelize these resources. For example, if there is not enough disk space, it would make sense to decompose these tables into separate disks.
All this, unfortunately, is not free. I suspect that in the case of the canonical SQL standard (I haven’t reread the SQL standard for a long time, perhaps it hasn’t been updated for a long time), there is no official standardized syntax for any SQL server to say: “Dear SQL server, make me 32 shards and decompose them into 4 disks. ” But in individual implementations, there is often a specific syntax in order to do the same thing in principle. PostgreSQL has mechanisms for partitioning, MySQL has MariaDB, Oracle probably did it all a long time ago.
However, if we do it by hand, without database support and within the standard, we conditionally pay for the complexity of data access . Where there was a simple SELECT * FROM documents WHERE id = 123, now 16 x SELECT * FROM docsXX. And well, if we tried to get the record by key. Much more interesting if we tried to get an early range of records. Now (if we, I emphasize, like fools, and remain within the standard) the results of these 16 SELECT * FROM will have to be combined in the application.
What performance changes to expect?
- Intuitively linear.
- Theoretically sublinear because Amdahl law .
- Practically - maybe, almost linearly, maybe not.
In fact, the correct answer is unknown. With dexterous use of the sharding technique, you can achieve a significant superlinear degradation of your application, and DBA will come running with a hot poker.
Let's see how this can be achieved. It is clear that simply putting the setting in PostgreSQL shards = 16, and then it itself took off - it is not interesting. Let's think about how we can ensure that we can slow down 32 times from sharding - this is interesting from the point of view how not to do this.
Our attempts to accelerate or slow down will always rest on the classics - in the good old Amdahl law, which says that there is no perfect parallelization of any query, there is always some consistent part.
Amdahl law
There is always a serialized part.
There is always a part of the execution of the request that is parallel, and there is always a part that does not parallel. Even if it seems to you that there is a perfectly parallel query, at least the collection of the result string that you are going to send to the client, from the strings received from each shard, is always there, and it is always consistent.
There is always some consistent part. It can be tiny, completely imperceptible on the general background, it can be gigantic and, accordingly, strongly affecting parallelization, but it always is.
In addition, its influence is changing and can significantly grow, for example, if we cut our table - let's raise the rates - from 64 entries to 16 tables with 4 entries, this part will change. Of course, judging by such gigantic amounts of data, we work on a mobile phone and an 86 2 MHz processor, and we don’t have enough files that can be kept open at the same time. Apparently, with such input, we open one file at a time.
- It was Total = Serial + Parallel . Where, for example, parallel is all the work inside the DB, and serial is sending the result to the client.
- It became Total2 = Serial + Parallel / N + Xserial. For example, when a generic ORDER BY, Xserial> 0.
With this simple example, I'm trying to show that some kind of Xserial appears. In addition to the fact that there is always a serialized part, and the fact that we are trying to work with data in parallel, an additional part appears to provide this data slicing. Roughly speaking, we may need:
- find these 16 tables in the internal database dictionary;
- open files;
- allocate memory;
- delocate memory;
- results;
- synchronize between the cores;
Any out-of-sync effects will still appear. They may be insignificant and take one billion dollars from the total time, but they are always non-zero and always are. With their help, we can dramatically lose in performance after sharding.
This is a standard picture about the law of Amdal. It is not very readable, but it is important that the lines, which should ideally be straight and linearly grow, abut on the asymptote. But since the schedule from the Internet is unreadable, I have made, in my opinion, more visual tables with numbers.
Suppose that we have a certain serialized part of the request processing, which takes only 5%: serial = 0.05 = 1/20.
Intuitively, it would seem that with the serialized part, which takes only 1/20 of the request processing, if we parallelize the processing of the request for 20 cores, it will become approximately 20, at worst 18, times faster.
In fact, mathematics is heartless :
wall = 0.05 + 0.95/num_cores, speedup = 1 / (0.05 + 0.95/num_cores)It turns out that if you carefully calculate, with the serialized part of 5%, the acceleration will be 10 times (10.3), and this is 51% compared with the theoretical ideal.
| 8 cores | = 5.9 | = 74% |
| 10 cores | = 6.9 | = 69% |
| 20 cores | = 10.3 | = 51% |
| 40 cores | = 13.6 | = 34% |
| 128 cores | = 17.4 | = 14% |
Using 20 cores (20 disks, if you like) for the task on which one worked earlier, we even theoretically will never get more than 20 times the acceleration, and in practice much less. Moreover, with an increase in the number of parallels, inefficiency is greatly increasing.
When only 1% of the serialized work remains and 99% are parallelized, the acceleration values are somewhat improved:
| 8 cores | = 7.5 | = 93% |
| 16 cores | = 13.9 | = 87% |
| 32 cores | = 24.4 | = 76% |
| 64 cores | = 39.3 | = 61% |
For a completely thermonuclear query that is naturally executed for hours, and the preparatory work and the assembly of the result take very little time (serial = 0.001), we will see already good efficiency:
| 8 cores | = 7.94 | = 99% |
| 16 cores | = 15.76 | = 99% |
| 32 cores | = 31.04 | = 97% |
| 64 cores | = 60.20 | = 94% |
Please note 100% we will never see . In particularly good cases, you can see, for example, 99.999%, but not exactly 100%.
How to chuff and repeat N times?
It is possible to fool and repeat exactly N times:
- Send requests docs00 ... docs15 sequentially , not in parallel.
- In simple queries to make a selection by key , WHERE something = 234.
In this case, the serialized part (serial) occupies not 1% and not 5%, but approximately 20% in modern databases. You can also get 50% of the serialized part by accessing the database using a wildly efficient binary protocol or linking it as a dynamic library to a Python script.
The rest of the processing time of a simple request will be occupied by non-parallelized operations of parsing the request, preparing the plan, etc. That is, it does not read the record.
If we divide the data into 16 tables and start sequentially, as is customary in the PHP programming language, for example, (he is not very good at starting asynchronous processes), then we’ll get a slowdown 16 times. And maybe even more, because network round-trips will also be added.
Suddenly, when sharding, the choice of programming language is important.
Remember about the choice of programming language, because if you send queries to the database (or search server) sequentially, then where does the acceleration come from? Rather, there will be a slowdown.
Bike from life
If you choose C ++, write to POSIX Threads , not Boost I / O. I saw an excellent library from experienced developers from Oracle and MySQL, who wrote a conversation with the MySQL server on Boost. Apparently, at work they were forced to write on pure C, and then they managed to turn around, take Boost with asynchronous I / O, etc. One problem is that this asynchronous I / O, which theoretically should have driven 10 requests in parallel, for some reason it had an imperceptible synchronization point inside. When you run 10 queries in parallel, they were executed exactly 20 times slower than one, because 10 times for the queries themselves and again for the synchronization point.
Conclusion: write in languages that implement parallel execution and waiting for different requests well. I do not know, to be honest, what exactly is there to advise, besides Go. Not only because I love Go, but because I don’t know anything more suitable.
Do not write in useless languages in which you will not be able to run 20 parallel queries to the database. Or at every opportunity do not do it all by hand - understand how it works, but do not do it manually.
A / B dough
Still sometimes you can slow down, because you are used to, that everything works, and did not notice that the serialized part, firstly, is, secondly, large.
- Immediately ~ 60 search index shards, categories
- These are correct and true shards, under the subject area.
- There were up to 1000 documents, and there were 50,000 documents.
This is a bike from the production, when the search queries were changed a little and they started to choose a lot more documents from the 60 shards of the search index. Everything worked quickly and according to the principle: “It works — don't touch it”, they all forgotten that there are actually 60 shards inside. Increased the sampling limit for each shard from a thousand to 50 thousand documents. Suddenly it began to slow down and the parallel ceased. The requests themselves, which were performed by shards, flew quite well, and the stage slowed down, when 50 thousand documents were collected from 60 shards. These 3 million final documents on one core merged together, sorted, the top of 3 million was selected and given to the client. The same serial part slowed down, the same merciless Amdal law worked.
So maybe you should not do sharding with your hands, but just like a human
say database: "do it!"
Disclaimer: I do not really know how to do something right. I type from the wrong floor !!!
I have all my life promoting a religion called "algorithmic fundamentalism." It is briefly stated very simply:
You do not want to do anything really with your hands, but it is extremely useful to know how it is arranged inside. So that at the moment when something goes wrong in the database, you at least understand what went wrong there, how it is arranged inside and around, how it can be repaired.
Let's consider the options:
- "Hands" . Previously, we manually split the data into 16 virtual tables, we rewrote all queries with our hands - this is extremely uncomfortable to do. If you can not shard hands - do not shuffle hands! But sometimes this is not possible, for example, you have MySQL 3.23, and then you have to.
- "Automatic". It happens that you can shard with an automaton or almost with an automaton, when the database is able to distribute the data itself, you only have to roughly write a certain setting somewhere. There are a lot of bases, and they have a lot of different settings. I am sure that in every database in which there is an opportunity to write shards = 16 (whatever the syntax), a lot of other settings are glued to this case by a steam locomotive.
- The “semi-automat” is an absolutely cosmic, in my opinion, brutal mode. That is, the base itself doesn’t seem to know how, but there are external additional patches.
It is difficult to tell something about an automaton, except for how to send to the documentation on the corresponding database (MongoDB, Elastic, Cassandra, ... in general, the so-called NoSQL). If you are lucky, then you just pull the switch “make me 16 shards” and everything will work. At the moment when it does not work itself, the rest of the article may be necessary.
Pro semiautomatic
Mostly, the delights of information technology inspire chthonic horror. For example, MySQL out of the box did not have a sharding implementation to certain versions exactly, nevertheless, the sizes of the bases used in battle grow to indecent values.
Suffering humanity in the face of individual DBA has been tormented for years and writes several bad sharding solutions, built incomprehensibly on what. After that, one more or less decent sharding solution is written under the name ProxySQL (MariaDB / Spider, PG / pg_shard / Citus, ...). This is a well-known example of this same snip.
ProxySQL as a whole, of course, is a complete enterprise-class solution for open source, for routing and so on. But one of the tasks to be solved is the sharding for the database, which in itself cannot be human shard. You see, there is no “shards = 16” switch, you have to either rewrite each request in the application, and there are many of them in places, or put some intermediate layer between the application and the database: “Hmm ... SELECT * FROM documents? Yes, it should be broken to 16 small SELECT * FROM server1.document1, SELECT * FROM server2.document2 - to this server with the same login / password, to this with another. If one did not answer, then ... "etc.
Intermediate hooks can do this exactly. They are a little less than for all databases. For PostgreSQL, as I understand it, at the same time there are some built-in solutions (PostgresForeign Data Wrappers, in my opinion, built into PostgreSQL itself), there are external patches.
Configuring each specific patch is a separate giant topic that does not fit in one report, so we will discuss only the basic concepts.
Let's talk the best about the theory of buzz.
Absolute perfect automatics?
The whole theory of buzz in the case of sharding in this letter F (), the basic principle is always the same roughly:
shard_id = F(object).Sharding is all about what? We have 2 billion records (or 64). We want to split them into several pieces. There is an unexpected question - how? According to what principle should I scatter my 2 billion records (or 64) on the 16 servers available to me?
The latent mathematician in us must suggest that in the end there is always some kind of magic function that, for each document (object, line, etc.), determines in which piece to put it.
If you go deeper into mathematics, this function always depends not only on the object itself (the line itself), but also on external settings such as the total number of shards. The function, which for each object should tell where to put it, cannot return a value greater than there are servers in the system. And the functions are slightly different:
- shard_func = F1 (object);
- shard_id = F2 (shard_func, ...);
- shard_id = F2 ( F1 (object), current_num_shards, ...).
But further we will not dig in these jungle of separate functions, we will just talk what magic functions F () are.
What are F ()?
They can come up with many different and many different implementation mechanisms. Sample summary:
- F = rand ()% nums_shards
- F = somehash (object.id)% num_shards
- F = object.date% num_shards
- F = object.user_id% num_shards
- ...
- F = shard_table [somehash () | ... object.date | ...]
An interesting fact - you can naturally scatter all data randomly - we throw the next entry on an arbitrary server, on an arbitrary kernel, into an arbitrary table. There will be no happiness in this, but it will work.
There are slightly more intelligent methods of sharding by reproducible or even consistent hash functions, or sharding by some attribute. Let's go through each method.
F = rand ()
Scattering radomom - not very correct method. One problem: we scattered our 2 billion records per thousand servers randomly, and we don’t know where the record is. We need to pull out user_1, but we don’t know where it is. We go to a thousand servers and go through everything - somehow it is inefficient.
F = somehash ()
Let's scatter users in an adult way: read the reproducible hash function from user_id, take the remainder by dividing by the number of servers and access the right server immediately.
And why are we doing this? And then, that we have highload and we don’t have anything else in one server. If intermeddle, life would be so simple.
Great, the situation has already improved, to get one entry, we are going to one previously known server. But if we have a range of keys, then in all of this range we have to go through all the key values and, in the limit, go either to as many shards as we have keys in the range, or to each server in general. The situation, of course, improved, but not for all requests. Some requests suffered.
Natural sharding (F = object.date% num_shards)
Sometimes, that is often, 95% of the traffic and 95% of the load are requests that have some kind of natural sharding. , 95% - 1 , 3 , 7 , 5% . 95% , , , .
, , , - .
— , . , , , , . 5 % .
, :
- , 95% .
- 95% , , . , . , .
, — , - .
, , , , . « - ».
«». , .
1. :
, , .
- , !
- () .
, / , , , PM ( , PM ), . .
, . , , 100 . .
, , , , - .
2. «» : , join
, ?
- «» … WHERE randcol BETWEEN aaa AND bbb?
- «» … users_32shards JOIN posts_1024 shards?
: , !
, , , . . (, , document store ), , .
— - . . , . , , , . - , , , , — .
, .
3. / :
: , .
, .
, , , . , , , 10 , - 30, 100 . . — , - — , - .
, : 16 -, 32. , 17, 23 — . , , - ?
: , , .
, «», « ».
#1.
- NewF(object), .
- NewF()=OldF() .
- .
- Oh.
, 2 , , . : 17 , 6 , 2 , 17 23 . 10 , , . .
#2.
— — 17 23, 16 32 ! , .
- NewF(object), .
- 2^N, 2^(N+1) .
- NewF()=OldF() 0,5.
- 50% .
- , .
, , . , , .
, . , 16 16, — .
, — .
#3. Consistent hashing
, consistent hashing
«consistent hashing», , .
: () , . , , , ( , ), .
- : , 2 «», 1/n.
- : , . .
, . , , , : , .
. , . , .., . , - , , .
, , , Cassandra . , , , , , .
, — / , , .
, : ? ? — , !
#4. Rendezvous/HRW
( , ): shard_id = arg max hash(object_id, shard_id).
Rendezvous hashing, , , Highest Random Weight. :
, , 16 . (), - , 16 , . -, .
HRW-hashing, Rendezvous hashing. , -, , .
, . , - - . .
, .
#5.
, Google - :
- Jump Hash — Google '2014.
- Multi Probe —Google '2015.
- Maglev — Google '2016.
, . , , , -, . .
#6. Lists
— . ? , 2 , object_id 2 , .
, ? ?
. , - , , . , , , , .
:
- 1 .
- / / / : min/max_id => shard_id.
- 8 4 (4 !) — 20 .
- - , 20 — .
- 20 — .
2 - 16 — 100 - . : , , — 1 . , , .
, , , - , .
findings
: « , !». , 20 .
, , . , — . 100$ , . -, . — .
, , «» (, DFS, ...) . , , highload - . , , - . — , .
F() , , , .. , , 2 .
, , . HighLoad++ , , —Sphinx—highload , .
Highload User Group. , .
, , HighLoad++ . , , . , , . highload-, .
, , , . , , , .
24 - «», « ». , . , .
, , 8 9 - HighLoad++ early bird .
Source: https://habr.com/ru/post/433370/
All Articles