Implementation of the Babylon Library
In this article you will learn everything about the Babylonian library, and most importantly - how to recreate it, and indeed any library.
Let's start with quotes from the work “The Babylonian Library ” by Luis Borges .
If you enter a random hexagon, walk up to any wall, look at any shelf and pick up the book you like the most, then you will most likely be upset. After all, you expected to learn there about the meaning of life, but you saw some strange set of characters. But do not get so upset so quickly! Most of the books are meaningless, because they are a combinatorial enumeration of all possible variants of twenty-five characters ( it was this alphabet that Borges used in his library, but then the reader will learn that there can be as many characters as possible in the library ). The main law of the library is that there are no two absolutely identical books in it, respectively, their number is of course, and the library will someday end too. Borges believed that the library was periodic:
')
In comparison with nonsense, the books, the content of which a person can somehow understand, are very few, but this does not change the fact that the library contains all the texts that have been and will be ever invented by man. And besides, since childhood you are accustomed to consider some sequences of symbols meaningful, while others are not. In fact, in the context of the library there is no difference between them. But what makes sense has a much smaller percentage, and we call it language. This is a means of communication between people. Any language contains only a few tens of thousands of words, of which we know 70% of the strength, hence it turns out that we cannot interpret most of the combinatorial sorting of books. And someone suffers apofenia and even in random character sets sees a hidden meaning. But this is a good idea for steganography ! Well, I continue to discuss this topic in the comments.
Before proceeding to the implementation of this library, I will surprise you with an interesting fact: if you want to recreate the Babylonian library of Luis Borges, you will fail, because its volumes exceed the volume of the visible Universe by 10 ^ 611338 (!) Times. And what will happen in even larger libraries, I even scary to think.
Our small introduction is over. But it is not devoid of sense: now you understand what the Babylon Library is, and it will be more interesting to read further. But I’ll go away from the original idea, I wanted to create a “universal” library, which will be discussed later. I will write on JavaScript under Node.js.What should be able to library?
In addition, it should be universal, i.e. Any of the library parameters can be changed if I want to. Well, I think that at first I will show all the code of the module, we will analyze it in detail, see how it works, and I will say a few words. Github repository
The main file is index.js, all the logic of the library is described there, and I will explain the contents of this file.
We connect the module that implements the sha512 hashing algorithm . This may seem strange to you, but it is still useful to us.
What is the output of our module? It returns a function whose call returns the library object with all the necessary methods. We could return it immediately, but then the management of the library would not be so convenient when we pass the parameters to the function and get the "necessary" library. This will allow us to create a "universal" library. As I try to write in the style of ES6, my arrow function takes as its parameters an object, which will later be structured into the necessary variables:
Now let's go over the parameters. As standard numeric parameters, I decided to choose simple numbers, because it seemed to me that it would be more interesting.
As you can see, this is not much like the real Babylonian library of Luis Borges. But I have repeatedly said that we will create "universal" libraries that may be the way we want to see them (therefore, the hexagon number can be interpreted in some other way, just like the identifier of some place where the necessary information). The Babylon Library is just one of them. But they all have a lot in common - one algorithm, which will be discussed now, is responsible for their performance.
When we go to some address, we see the contents of the page. If we go to the same address again, the content should be exactly the same. This property of libraries provides an algorithm for generating pseudo-random numbers - Linear congruential method . When we need to choose a symbol to generate an address or, conversely, page content, it will help us, and page numbers, shelves, etc. will be used as grain. My PRNG config: m = 2 ^ 32 (4294967296), a = 22695477, c = 1. I would like to add that in our implementation only the principle of generating numbers remained from the linear congruent method, the rest is changed. Moving on the listing of the program further:
As you can see, the PRNG grain changes after each receipt of a number, and the results directly depend on the so-called point of reference - the grains, after which the numbers will interest us. (we generate the address or get the content of the page)
The getHash function will help us generate a point of reference. We just get a hash from some data, take 7 characters, translate into a decimal number system and ready!
The mod function behaves in the same way as the% operator. But if the divisible a <0 (such situations are possible), the mod function will return a positive number due to a special structure, we need this in order to correctly select characters from the alphabet string when getting the page content at the address.
And the last piece of code for dessert is the returned library object:
In the beginning, we write library properties into it, which I described earlier. You can change them even after the completion of the call to the main function (which, in principle, can be called a constructor, but my code is only slightly similar to the class implementation of the library, so I’ll confine myself to the word "main"). Perhaps this behavior is not entirely adequate, but flexible. Now let's go over each method.
Returns the address of the searchStr string in the library. To do this, randomly choose wall, shelf, volume, page . The volume and page are also padded with zeros to the desired length. Next, we concatenate them into a string to pass to the getHash function. The resulting locHash is the starting point, i.e. corn.
For greater unpredictability, we complement searchStr depth with pseudo-random alphabet symbols, and assign the seed grain the value locHash . At this stage, it does not matter how we complement the string, so you can use the PRNG built into JavaScript, this is uncritical. It is possible to refuse him altogether so that the results of interest to us are always at the top of the page.
It remains the case for small - to generate the hex ID. For each character of the searchStr line, we execute an algorithm:
Upon completion of the hex generation, we return the full address of the place in which the search string is contained. The components of the address are separated by a hyphen.
This method does the same thing as the search method, but fills the entire free space (makes the searchStr string of lengthOfPage characters) spaces. When viewing such a page it will seem that there is nothing on it except your text.
The searchTitle method returns the address of a book called searchStr . Inside it is very similar to search . The difference is that when calculating locHash we do not use the page to bind its title to the book. It should not depend on the page. searchStr is cropped to length lengthOfTitle and optionally padded with spaces. Similarly, the hex ID is generated and the resulting address is returned. Please note that there is no page in it, as it was when searching for the exact address of an arbitrary text. So if you want to find out what is in the book with the name you have invented, decide on the page you want to go to.
Opposed to the search method. Its task is to output the page content at a given address. To do this, convert the address into an array by separator "-". Now we have an array of address components: hex key, wall, shelf, book, page. We calculate the locHash just as we did in the search method. We will get the same number as when generating the address. This means that the PRNG will issue the same numbers, it is this behavior that ensures the reversibility of our transformations over the source text. To calculate it over each character (de facto, this is a digit) of the hexagon identifier, we perform an algorithm:
The result obtained at this stage does not always fill the entire page, so we calculate the new grain from the current result and fill the free space with symbols from the alphabet. The PRNG helps us in choosing the symbol.
At this, the calculation of the content of the page ends, we return it, not forgetting to cut to the maximum length. Perhaps, in the input address, the hexagon identifier was indecently large.
Well, here is the same story. Imagine that you are reading the description of the previous method, only when calculating the PRNG grains do not take into account the page number, and supplement and trim the result to the maximum length of the book title - lengthOfTitle .
After we have analyzed the principle of operation of any Babylonian-like library, it’s time to try it out in practice. I will use the config as close as possible to that created by Louis Borges. We’ll search for the simple phrase “habr.com”:
Run the result:

At the moment it does not give us anything. But let's find out what lies behind this address! The code will be:
Result:
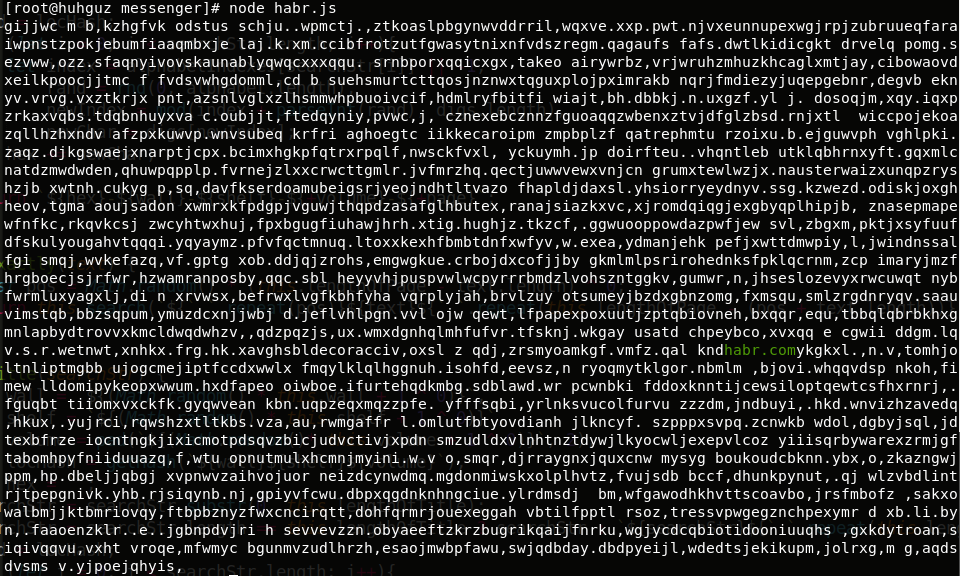
We found what we were looking for in an infinite number of meaningless (I would argue) pages!
But this is far from the only place where this phrase is located. The next time you start the program, a different address will be generated. If you want, you can save one and work with it. The main thing is that the content of the pages never changes. Let's look at the title of the book that contains our phrase. The code will be as follows:
The name of the book was like this:
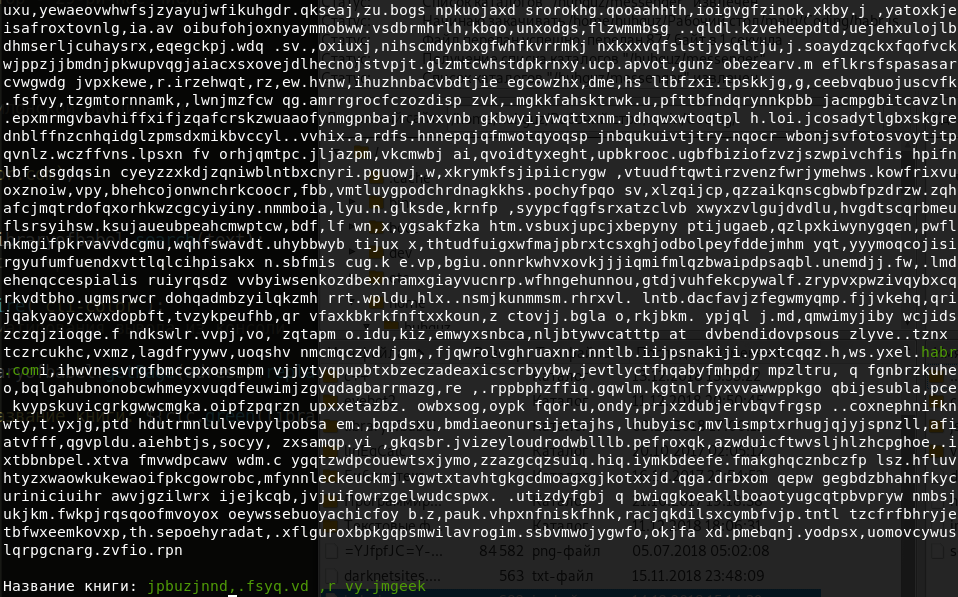
Honestly, it does not look very attractive. Then let's find a book with our phrase in the title:
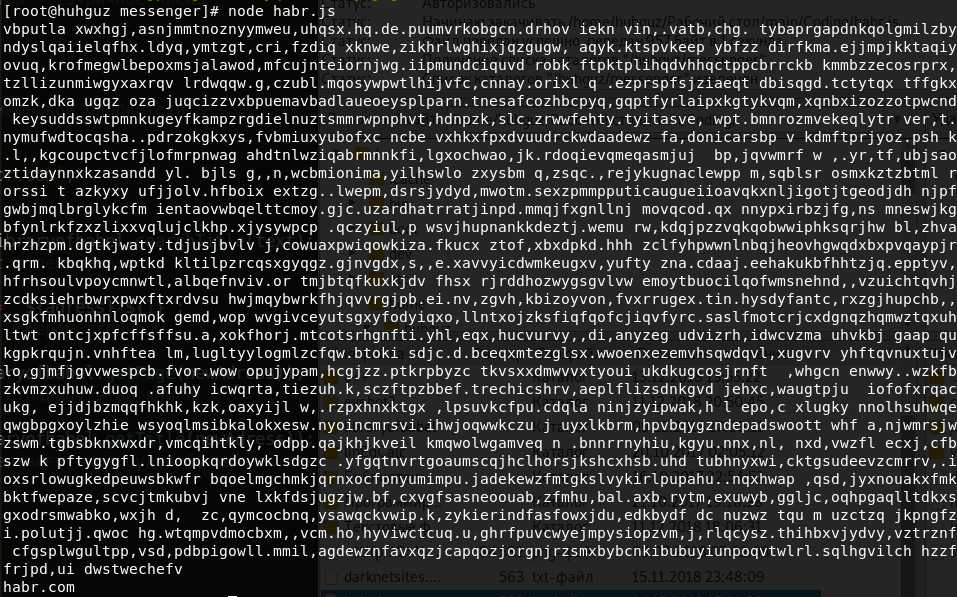
Now you understand how to use this library. I will be able to create a completely different library. Now it will be filled with ones and zeros, on each page will be 100 characters, the address will be a hexadecimal number. Do not forget about the observance of the condition of equality of the lengths of the alphabet and the string of digits of our large number. We will search, for example, "10101100101010111001000000". We look:

Let's take a look at the search for a complete match. To do this, go back to the old example and in the code replace libraryofbabel.search with libraryofbabel.searchExactly :
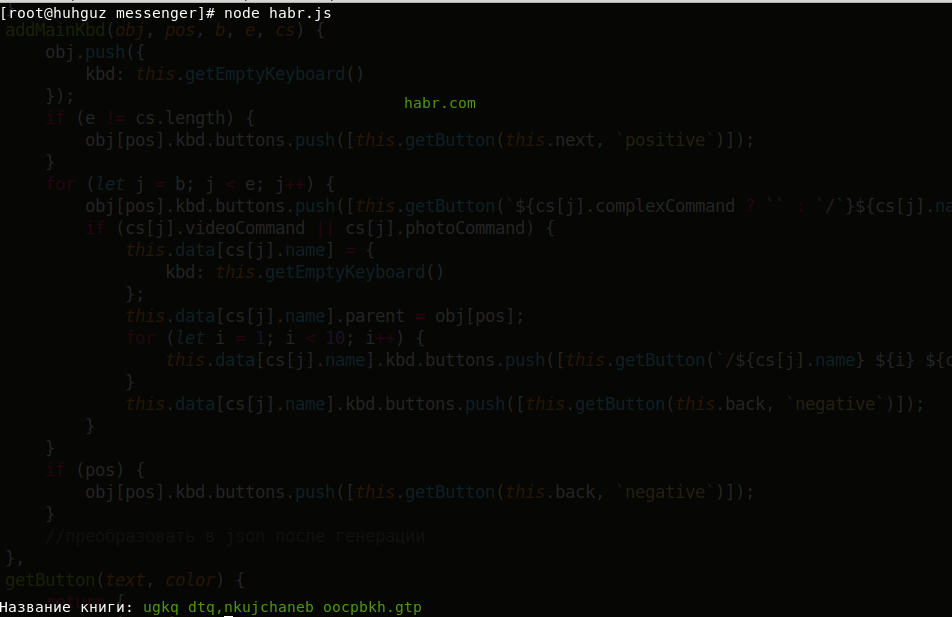
After reading the description of the algorithm of the libraries, you probably already guessed that this is a kind of deception.When you look for something meaningful in the library, it is simply encoded into a different look and displayed in a different form. But it is so beautifully presented that you begin to believe in these endless rows of hexagons. In fact, this is nothing more than a mathematical abstraction. But the fact that absolutely anything can be found in this library is true. It is also true that if you generate random sequences of characters, sooner or later you can get absolutely any text. For a better understanding of this topic, you can study the endless monkey theorem .
You can come up with other options for implementing libraries: use any encryption algorithm, where the ciphertext will be the address in your comprehensive library. Decryption - getting the page content. And maybe trybase64 , m?
A possible use of the library is to store passwords in some of its places. Create the configuration you need, find out where your passwords are in the library (yes, they already exist. Did you think it was you who invented them?), Save the address. And now, when you need to find a password, just find it in the library. But this approach is dangerous, because an attacker can find out the configuration of the library and just use your address. But if he does not know about the meaning of what he found, it is unlikely that your data will fall to him. And is this a way of storing passwords mainstream? No, so he has a place to be.
This idea can be used to create a variety of "libraries". You can iterate through not only characters, but whole words, or even sounds! Imagine a place where you can listen to absolutely any sound that is accessible to human perception, or find a song. In the future I will definitely try to implement it.
The web version in Russian is available here , it is deployed on my virtual server. I do not know of all the pleasant searches for the meaning of life in the Babylonian library, or which one you want to create. Goodbye! :)
Let's start with quotes from the work “The Babylonian Library ” by Luis Borges .
Quote
“The Universe - some people call it the Library - consists of a huge, perhaps infinite number of six-sided galleries, with wide ventilation wells fenced with low railings. From each hexagon you can see two upper and two lower floors - to infinity. "
“The library is a ball, the exact center of which is in one of the hexagons, and the surface is inaccessible. On each of the walls of each hexagon there are five shelves, on each shelf there are thirty two books of the same format, each book has four hundred and ten pages, each page has forty lines, each line contains about eighty letters of black color. There are letters on the spine of the book, but they do not define and do not portend what the pages will say. This discrepancy, I know, once seemed mysterious. ”
If you enter a random hexagon, walk up to any wall, look at any shelf and pick up the book you like the most, then you will most likely be upset. After all, you expected to learn there about the meaning of life, but you saw some strange set of characters. But do not get so upset so quickly! Most of the books are meaningless, because they are a combinatorial enumeration of all possible variants of twenty-five characters ( it was this alphabet that Borges used in his library, but then the reader will learn that there can be as many characters as possible in the library ). The main law of the library is that there are no two absolutely identical books in it, respectively, their number is of course, and the library will someday end too. Borges believed that the library was periodic:
')
Quote
“Perhaps fear and old age deceive me, but I think that the human race is the only one that is close to extinction, and the Library will remain: illuminated, uninhabited, infinite, absolutely motionless, filled with precious volumes, useless, imperishable, mysterious. I just wrote infinite. I did not use this word out of love for rhetoric; I think it is quite logical to assume that the world is infinite. Those who consider it limited, admit that somewhere in the distance corridors, and staircases, and hexagons may end for an unknown reason, - such an assumption is absurd. Those who imagine it without boundaries forget that the number of possible books is limited. I dare to offer such a solution to this age-old problem: The library is limitless and periodic. If the eternal wanderer had set off in any direction, he would have been able, after centuries, to see that the same books were repeated in the same confusion (which, being repeated, becomes an order, an Order). This graceful hope brightens my loneliness. ”
In comparison with nonsense, the books, the content of which a person can somehow understand, are very few, but this does not change the fact that the library contains all the texts that have been and will be ever invented by man. And besides, since childhood you are accustomed to consider some sequences of symbols meaningful, while others are not. In fact, in the context of the library there is no difference between them. But what makes sense has a much smaller percentage, and we call it language. This is a means of communication between people. Any language contains only a few tens of thousands of words, of which we know 70% of the strength, hence it turns out that we cannot interpret most of the combinatorial sorting of books. And someone suffers apofenia and even in random character sets sees a hidden meaning. But this is a good idea for steganography ! Well, I continue to discuss this topic in the comments.
Before proceeding to the implementation of this library, I will surprise you with an interesting fact: if you want to recreate the Babylonian library of Luis Borges, you will fail, because its volumes exceed the volume of the visible Universe by 10 ^ 611338 (!) Times. And what will happen in even larger libraries, I even scary to think.
Library implementation
Module Description
Our small introduction is over. But it is not devoid of sense: now you understand what the Babylon Library is, and it will be more interesting to read further. But I’ll go away from the original idea, I wanted to create a “universal” library, which will be discussed later. I will write on JavaScript under Node.js.What should be able to library?
- Quickly find the desired text and issue its location in the library
- Identify book title
- Quickly find a book with the desired title.
In addition, it should be universal, i.e. Any of the library parameters can be changed if I want to. Well, I think that at first I will show all the code of the module, we will analyze it in detail, see how it works, and I will say a few words. Github repository
The main file is index.js, all the logic of the library is described there, and I will explain the contents of this file.
let sha512 = require(`js-sha512`); We connect the module that implements the sha512 hashing algorithm . This may seem strange to you, but it is still useful to us.
What is the output of our module? It returns a function whose call returns the library object with all the necessary methods. We could return it immediately, but then the management of the library would not be so convenient when we pass the parameters to the function and get the "necessary" library. This will allow us to create a "universal" library. As I try to write in the style of ES6, my arrow function takes as its parameters an object, which will later be structured into the necessary variables:
module.exports = ({ lengthOfPage = 4819, lengthOfTitle = 31, digs = '0123456789abcdefghijklmnopqrstuvwxyz', alphabet = ', .', wall = 5, shelf = 7, volume = 31, page = 421, } = {}) => { // ... }; Now let's go over the parameters. As standard numeric parameters, I decided to choose simple numbers, because it seemed to me that it would be more interesting.
- lengthOfPage - the number, the number of characters on one page. The default is 4819. If you factor this number, you get 61 and 79. 61 lines of 79 characters, or vice versa, but I prefer the first option.
- lengthOfTitle - the number, the number of characters in the title of the title of the book.
- digs - string, possible digits of a number with a base equal to the length of this string. What is this number for? It will contain the hexagon number (identifier) to which we want to go. By default, this is a lowercase Latin letter and the number is 0-9. Most of the text is encoded here, so it will be a large number - several thousand digits (depending on the number of characters on the page), but work with it will be done character-by-character.
- The alphabet is a string, the characters we want to see in the library. It will be filled with them. In order for everything to work correctly, the number of characters in the alphabet must be equal to the number of characters in the lines with possible digits of the number that identifies the hexagon.
- wall - the number, the maximum number of the wall, the default is 5
- shelf - number, maximum shelf number, default is 7
- volume - the number, the maximum book number, the default is 31
- page - number, maximum page number, by default 421
As you can see, this is not much like the real Babylonian library of Luis Borges. But I have repeatedly said that we will create "universal" libraries that may be the way we want to see them (therefore, the hexagon number can be interpreted in some other way, just like the identifier of some place where the necessary information). The Babylon Library is just one of them. But they all have a lot in common - one algorithm, which will be discussed now, is responsible for their performance.
Algorithms for searching and issuing pages
When we go to some address, we see the contents of the page. If we go to the same address again, the content should be exactly the same. This property of libraries provides an algorithm for generating pseudo-random numbers - Linear congruential method . When we need to choose a symbol to generate an address or, conversely, page content, it will help us, and page numbers, shelves, etc. will be used as grain. My PRNG config: m = 2 ^ 32 (4294967296), a = 22695477, c = 1. I would like to add that in our implementation only the principle of generating numbers remained from the linear congruent method, the rest is changed. Moving on the listing of the program further:
Code
module.exports = ({ lengthOfPage = 4819, lengthOfTitle = 31, digs = '0123456789abcdefghijklmnopqrstuvwxyz', alphabet = ', .', wall = 5, shelf = 7, volume = 31, page = 421, } = {}) => { let seed = 13; // const rnd = (min = 1, max = 0) => { // // min max seed = (seed * 22695477 + 1) % 4294967296; // // return min + seed / 4294967296 * (max - min); // // }; const pad = (s, size) => s.padStart(size, `0`); // // let getHash = str => parseInt(sha512(str).slice(0, 7), 16); // const mod = (a, b) => ((a % b) + b) % b; // const digsIndexes = {}; // // digs const alphabetIndexes = {}; // // alphabet Array.from(digs).forEach((char, position) => { // digs digsIndexes[char] = position; // // }); Array.from(alphabet).forEach((char, position) => { // alphabet alphabetIndexes[char] = position; // // }); return { // }; As you can see, the PRNG grain changes after each receipt of a number, and the results directly depend on the so-called point of reference - the grains, after which the numbers will interest us. (we generate the address or get the content of the page)
The getHash function will help us generate a point of reference. We just get a hash from some data, take 7 characters, translate into a decimal number system and ready!
The mod function behaves in the same way as the% operator. But if the divisible a <0 (such situations are possible), the mod function will return a positive number due to a special structure, we need this in order to correctly select characters from the alphabet string when getting the page content at the address.
And the last piece of code for dessert is the returned library object:
Code
return { wall, shelf, volume, page, lengthOfPage, lengthOfTitle, search(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), page = pad(`${(Math.random()* this.page + 1 ^ 0)}`, 3), locHash = getHash(`${wall}${shelf}${volume}${page}`), hex = ``, depth = Math.random() * (this.lengthOfPage - searchStr.length) ^ 0; for (let i = 0; i < depth; i++){ searchStr = alphabet[Math.random() * alphabet.length ^ 0] + searchStr; } seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]] || -1, rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}-${+page}`; }, searchExactly(text) { const pos = Math.random() * (this.lengthOfPage - text.length) ^ 0; return this.search(`${` `.repeat(pos)}${text}${` `.repeat(this.lengthOfPage - (pos + text.length))}`); }, searchTitle(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), locHash = getHash(`${wall}${shelf}${volume}`), hex = ``; searchStr = searchStr.substr(0, this.lengthOfTitle); searchStr = searchStr.length == this.lengthOfTitle ? searchStr : `${searchStr}${` `.repeat(this.lengthOfTitle - searchStr.length)}`; seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]], rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}`; }, getPage(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}${pad(addressArray[4], 3)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfPage) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfPage); }, getTitle(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfTitle) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfTitle); } }; In the beginning, we write library properties into it, which I described earlier. You can change them even after the completion of the call to the main function (which, in principle, can be called a constructor, but my code is only slightly similar to the class implementation of the library, so I’ll confine myself to the word "main"). Perhaps this behavior is not entirely adequate, but flexible. Now let's go over each method.
Search method
search(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random() * this.volume + 1 ^ 0)}`, 2), page = pad(`${(Math.random() * this.page + 1 ^ 0)}`, 3), locHash = getHash(`${wall}${shelf}${volume}${page}`), hex = ``, depth = Math.random() * (this.lengthOfPage - searchStr.length) ^ 0; for (let i = 0; i < depth; i++){ searchStr = alphabet[Math.random() * alphabet.length ^ 0] + searchStr; } seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]] || -1, rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}-${+page}`; } Returns the address of the searchStr string in the library. To do this, randomly choose wall, shelf, volume, page . The volume and page are also padded with zeros to the desired length. Next, we concatenate them into a string to pass to the getHash function. The resulting locHash is the starting point, i.e. corn.
For greater unpredictability, we complement searchStr depth with pseudo-random alphabet symbols, and assign the seed grain the value locHash . At this stage, it does not matter how we complement the string, so you can use the PRNG built into JavaScript, this is uncritical. It is possible to refuse him altogether so that the results of interest to us are always at the top of the page.
It remains the case for small - to generate the hex ID. For each character of the searchStr line, we execute an algorithm:
- Get index symbol number from alphabetIndexes object. If not, return -1, but if this happens, you are definitely doing something wrong.
- Generate a pseudo-random number rand using our PRNG, ranging from 0 to the length of the alphabet.
- Calculate the new index, which is calculated as the sum of the index character number and the pseudo-random number rand , divided by the module by the length of the digs .
- Thus, we obtained the digit of the hexagon identifier - newChar (taking it from digs ).
- Add newChar to hex hex id
Upon completion of the hex generation, we return the full address of the place in which the search string is contained. The components of the address are separated by a hyphen.
SearchExactly method
searchExactly(text) { const pos = Math.random() * (this.lengthOfPage - text.length) ^ 0; return this.search(`${` `.repeat(pos)}${text}${` `.repeat(this.lengthOfPage - (pos + text.length))}`); } This method does the same thing as the search method, but fills the entire free space (makes the searchStr string of lengthOfPage characters) spaces. When viewing such a page it will seem that there is nothing on it except your text.
SearchTitle method
searchTitle(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), locHash = getHash(`${wall}${shelf}${volume}`), hex = ``; searchStr = searchStr.substr(0, this.lengthOfTitle); searchStr = searchStr.length == this.lengthOfTitle ? searchStr : `${searchStr}${` `.repeat(this.lengthOfTitle - searchStr.length)}`; seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]], rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}`; } The searchTitle method returns the address of a book called searchStr . Inside it is very similar to search . The difference is that when calculating locHash we do not use the page to bind its title to the book. It should not depend on the page. searchStr is cropped to length lengthOfTitle and optionally padded with spaces. Similarly, the hex ID is generated and the resulting address is returned. Please note that there is no page in it, as it was when searching for the exact address of an arbitrary text. So if you want to find out what is in the book with the name you have invented, decide on the page you want to go to.
GetPage method
getPage(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}${pad(addressArray[4], 3)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfPage) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfPage); } Opposed to the search method. Its task is to output the page content at a given address. To do this, convert the address into an array by separator "-". Now we have an array of address components: hex key, wall, shelf, book, page. We calculate the locHash just as we did in the search method. We will get the same number as when generating the address. This means that the PRNG will issue the same numbers, it is this behavior that ensures the reversibility of our transformations over the source text. To calculate it over each character (de facto, this is a digit) of the hexagon identifier, we perform an algorithm:
- Calculate the index in the string digs . Take it from digsIndexes .
- Using the PRNG, we generate a pseudo-random number rand in the range 0 to the base of the number system of a large number equal to the length of the string containing the digits of this beautiful number. Everything is obvious.
- We calculate the position of the source text symbol newIndex as the difference between the index and rand , divided modulo the length of the alphabet. It is possible that the difference is negative, then the usual modulo division will give a negative index, which does not suit us, so we use a modified version of the modulo division. (you can try the option of taking the absolute value of the above formula, it also solves the problem of negative numbers, but in practice it has not been tested yet)
- The symbol of the text of the page - newChar , we get by index from the alphabet.
- Add a text symbol to the result.
The result obtained at this stage does not always fill the entire page, so we calculate the new grain from the current result and fill the free space with symbols from the alphabet. The PRNG helps us in choosing the symbol.
At this, the calculation of the content of the page ends, we return it, not forgetting to cut to the maximum length. Perhaps, in the input address, the hexagon identifier was indecently large.
GetTitle method
getTitle(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfTitle) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfTitle); } Well, here is the same story. Imagine that you are reading the description of the previous method, only when calculating the PRNG grains do not take into account the page number, and supplement and trim the result to the maximum length of the book title - lengthOfTitle .
Test module for creating libraries
After we have analyzed the principle of operation of any Babylonian-like library, it’s time to try it out in practice. I will use the config as close as possible to that created by Louis Borges. We’ll search for the simple phrase “habr.com”:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`, //, , , digs: `0123456789abcdefghijklmnopqrs`, // - 29- wall: 4, shelf: 5, volume: 32, page: 410 // }); // console.log(libraryofbabel.search(`habr.com`)); Run the result:
At the moment it does not give us anything. But let's find out what lies behind this address! The code will be:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`, //, , , digs: `0123456789abcdefghijklmnopqrs`, // - 29- wall: 4, shelf: 5, volume: 32, page: 410 // }); const text = `habr.com`; // const adress = libraryofbabel.search(text); // const clc = require(`cli-color`); // console.log(libraryofbabel.getPage(adress).replace(text, clc.green(text))); Result:
We found what we were looking for in an infinite number of meaningless (I would argue) pages!
But this is far from the only place where this phrase is located. The next time you start the program, a different address will be generated. If you want, you can save one and work with it. The main thing is that the content of the pages never changes. Let's look at the title of the book that contains our phrase. The code will be as follows:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`, //, , , digs: `0123456789abcdefghijklmnopqrs`, // - 29- wall: 4, shelf: 5, volume: 32, page: 410 // }); const text = `habr.com`; // const adress = libraryofbabel.search(text); // const clc = require(`cli-color`); // console.log(libraryofbabel.getPage(adress).replace(text, clc.green(text))); console.log(`\n : ${clc.green(libraryofbabel.getTitle(adress))}`); The name of the book was like this:
Honestly, it does not look very attractive. Then let's find a book with our phrase in the title:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`, //, , , digs: `0123456789abcdefghijklmnopqrs`, // - 29- wall: 4, shelf: 5, volume: 32, page: 410 // }); const text = `habr.com`; // const adress = libraryofbabel.searchTitle(text); // const newAdress = `${adress}-${1}`; // console.log(libraryofbabel.getPage(newAdress)); // console.log(libraryofbabel.getTitle(newAdress)); // , :) Now you understand how to use this library. I will be able to create a completely different library. Now it will be filled with ones and zeros, on each page will be 100 characters, the address will be a hexadecimal number. Do not forget about the observance of the condition of equality of the lengths of the alphabet and the string of digits of our large number. We will search, for example, "10101100101010111001000000". We look:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 100, alphabet: `1010101010101010`, // 1 0, digs: `0123456789abcdef`, // - 16- wall: 4, shelf: 5, volume: 32, page: 410 // }); const text = `10101100101010111001000000`; // const adress = libraryofbabel.search(text); // console.log(`\n${adress}\n`); // const clc = require(`cli-color`); // console.log(libraryofbabel.getPage(adress).replace(text, clc.green(text))); console.log(`\n : ${clc.green(libraryofbabel.getTitle(adress))}`); Let's take a look at the search for a complete match. To do this, go back to the old example and in the code replace libraryofbabel.search with libraryofbabel.searchExactly :
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`, //, , , digs: `0123456789abcdefghijklmnopqrs`, // - 29- wall: 4, shelf: 5, volume: 32, page: 410 // }); const text = `habr.com`; // const adress = libraryofbabel.searchExactly(text); // const clc = require(`cli-color`); // console.log(libraryofbabel.getPage(adress).replace(text, clc.green(text))); console.log(`\n : ${clc.green(libraryofbabel.getTitle(adress))}`); Conclusion
After reading the description of the algorithm of the libraries, you probably already guessed that this is a kind of deception.When you look for something meaningful in the library, it is simply encoded into a different look and displayed in a different form. But it is so beautifully presented that you begin to believe in these endless rows of hexagons. In fact, this is nothing more than a mathematical abstraction. But the fact that absolutely anything can be found in this library is true. It is also true that if you generate random sequences of characters, sooner or later you can get absolutely any text. For a better understanding of this topic, you can study the endless monkey theorem .
You can come up with other options for implementing libraries: use any encryption algorithm, where the ciphertext will be the address in your comprehensive library. Decryption - getting the page content. And maybe trybase64 , m?
A possible use of the library is to store passwords in some of its places. Create the configuration you need, find out where your passwords are in the library (yes, they already exist. Did you think it was you who invented them?), Save the address. And now, when you need to find a password, just find it in the library. But this approach is dangerous, because an attacker can find out the configuration of the library and just use your address. But if he does not know about the meaning of what he found, it is unlikely that your data will fall to him. And is this a way of storing passwords mainstream? No, so he has a place to be.
This idea can be used to create a variety of "libraries". You can iterate through not only characters, but whole words, or even sounds! Imagine a place where you can listen to absolutely any sound that is accessible to human perception, or find a song. In the future I will definitely try to implement it.
The web version in Russian is available here , it is deployed on my virtual server. I do not know of all the pleasant searches for the meaning of life in the Babylonian library, or which one you want to create. Goodbye! :)
Source: https://habr.com/ru/post/433336/
All Articles