How we recovered a corrupted .wav file
It was an interesting experience when a .wav file was restored with a friend. I decided to describe our tormenting process, suddenly someone will come in handy.
Prehistory
There are sad stories when a voice recorder hangs / or gives an error when saving a file. Consequently, when we try to open a damaged file, we get errors like: the format could not be decoded, the format was incorrect, or the program did not recognize the file format .
We are trying to figure it out.
Since we did not manage to open the file, we decided to google it. We wanted to figure out how to feed the .wav file to the player. Found a bunch of tips: load it in Raw (raw format), play around with settings, etc. All these attempts failed.
We decided to study what wav is, find information about the headlines and their description :

Install the hex editor (wxHexEditor), open and try to at least find something similar to the title.
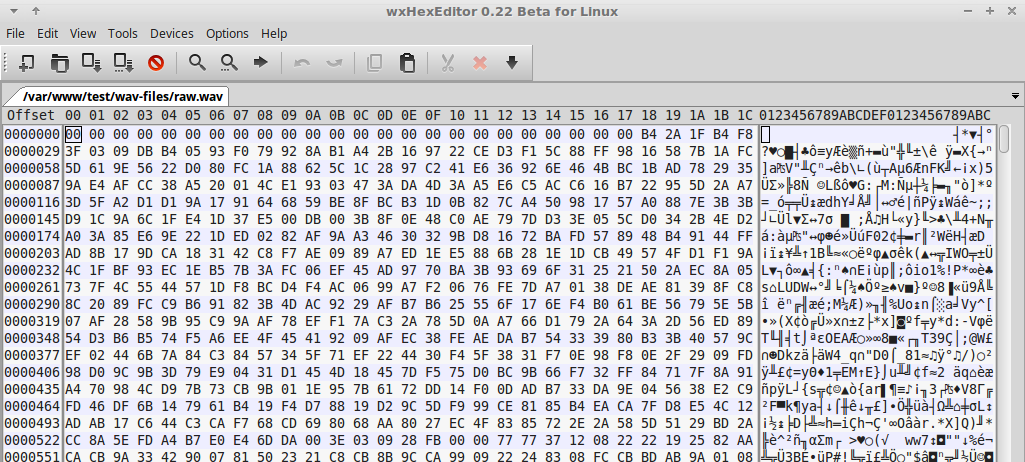
Failure ... they were not.
We decided to write a new record with good preservation. Opened it in the editor and see the headers.
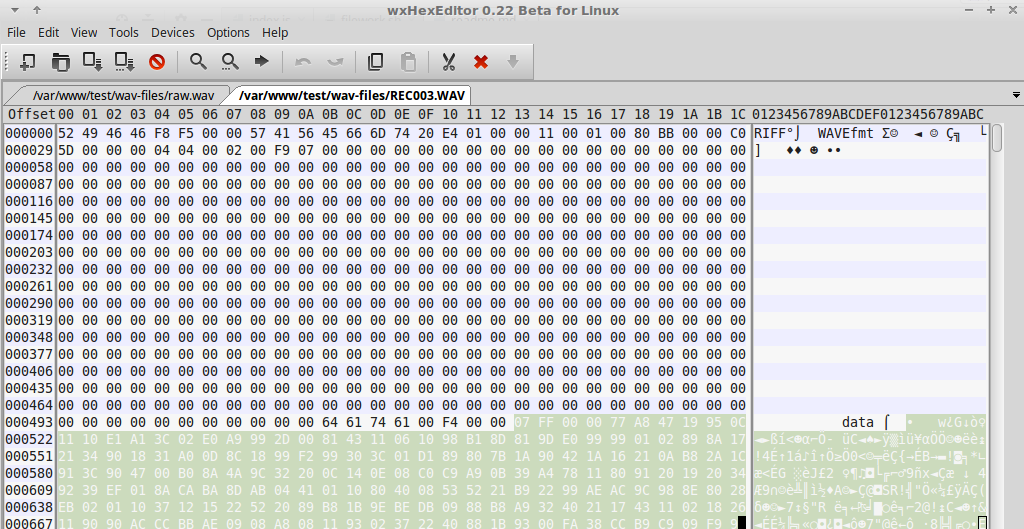
Copy the headers and paste into our broken file (hereinafter BF)! We convulsively save and run the file in the player, and nothing works! (I, like a real man, began to sob in the corner of the room)
Before you build something, you need to break something.
We decided to figure out how to break a normal file and get such a ugly picture as a damaged file.
Figure: glued BF on top, normal recording below.
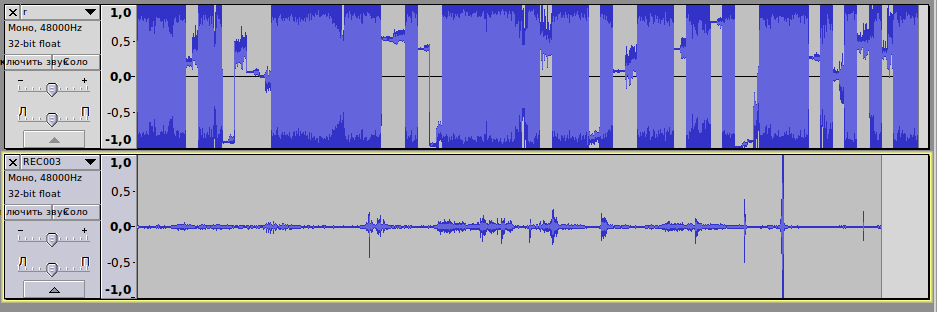
It turned out that if you delete 1 byte in the normal file and save it, the picture becomes similar. And if you return a byte, even an empty one with zeros, then everything becomes normal.
Writing a bash script
We decided to delete and save the file by-byte in order to get a normal picture, as in the figure above. Created 2 files, one only headers, and another damaged file (after cutting it a little less than a megabyte).
They wrote a small script that deletes one byte from the file and sticks together with the header, and then saves it with a sequence number.
#!/bin/bash for i in {1..1000} do cat header.wav > "./wav/$i.wav" tail -c +$i raw.wav >> "./wav/$i.wav" done Run the script and with awe, on the edge of the chair, waiting for the result. Unfortunately, we had to look through these files manually, but we didn’t know how to do it differently. Threw 250 files in audacity and looked through the tracks:
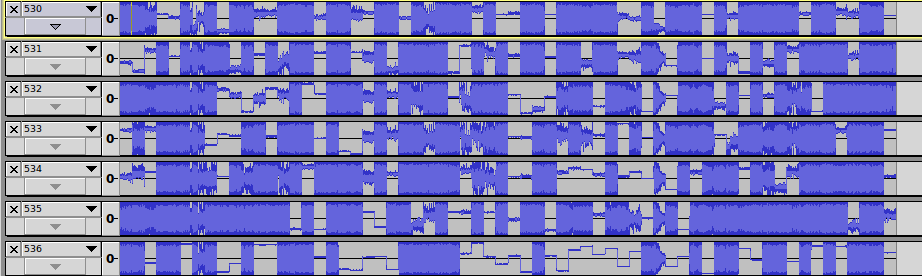
Scrolling had not long, because on the 537 file we found what we were looking for:
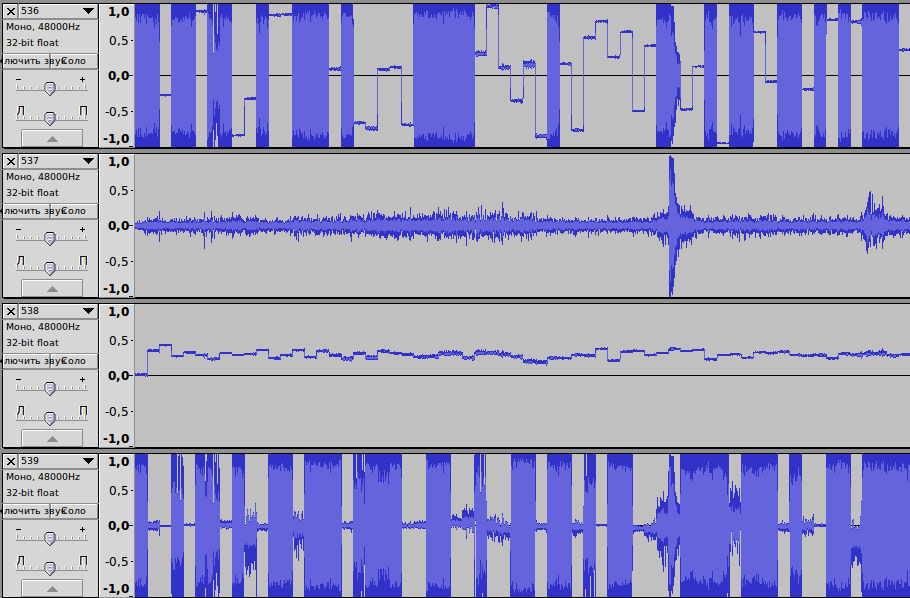
It remains the case for small. We look at this file in the hash of the editor, where it stopped. Open the BF in the editor and delete after the header we need the length of bytes. That's it, the two-hour file plays normally.
PS
Most likely, it could be made easier. Who knows how to facilitate the work or somehow optimize it, write, add to this "guide".
Thank you all for your attention.
')
Source: https://habr.com/ru/post/433178/
All Articles