Quintet as a basic entity for describing the subject area
A quintet is a way to record atomic data fragments with an indication of their role in our life. Quintets can describe any data, each of which contains comprehensive information about themselves and about the links with other quintets. It represents subject terms, regardless of the platform used. Its task is to simplify data storage and improve the visibility of their presentation.

I will talk about the new approach to storing and processing information and share thoughts about creating a development platform in this new paradigm.
A quintet has properties: type, value, parent, order among brothers. With the identifier, only 5 components are obtained. This is the simplest universal form of recording information, a new standard that can potentially suit everyone. Quintets are stored in the file system of a single structure, in a continuous monotonous indexed information field.
')
To record information there is an infinite number of standards, approaches and rules, knowledge of which is necessary for working with these records. Standards are described separately and have no direct connection with the data. In the case of quintets, taking any of them, you can get relevant information about its nature, properties and rules of work with its subject area. Its standard is one and unchanged for all areas. The quintet is hidden from the user - metadata and data are available to him in a form familiar to many.
A quintet is not only information, but also executable commands. But first of all it is the data that is required to be stored, recorded and retrieved. Since in our case they are directly addressable, linked and indexed, we will keep them in a kind of database. To test the prototype data storage system with quintets, for example, we used a regular relational database.
The main idea of this article is to replace machine types with human terms and replace variables with objects. Not those objects that need a constructor, destructor, interfaces and garbage collector, but pure-crystal units of information that the customer operates on. That is, if the customer says "Application", then to save the essence of this information on the media would not require the expertise of the programmer.
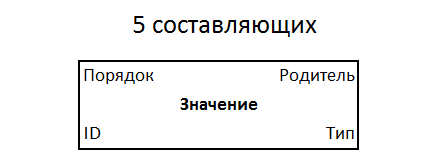
It is useful to focus the user's attention only on the value of the object, and its type, parent, order (among equals in subordination) and identifier should be obvious from the context or simply hidden. This means that the user does not know anything about quintets at all , he simply sets out his task, makes sure that it is accepted correctly, and then starts its execution.
There is a set of data types that can be understood by anyone: string, number, file, text, date, and so on. Such a simple set is quite sufficient for formulating the problem, and “programming” it and the types necessary for its implementation. The basic types represented by quintets might look like this:

In this case, part of the components of the quintet are not used, and he himself is used as the base type. This allows the system kernel to more easily navigate when navigating metadata.
Due to the analytical gap between the user and the programmer, at the stage of problem statement, a significant deformation of concepts occurs. The lack of clarity, incomprehensibility and unsolicited initiative often turn the customer’s simple and understandable thought into a logically impossible mess, judging from the user's point of view.

The transfer of knowledge must occur without loss and distortion. Moreover, in the future, when organizing the storage of this knowledge, it is necessary to get rid of the restrictions imposed by the selected data management system.
On the server, as a rule, there are many databases, each of them contains a description of the structure of entities with a specific set of details - interrelated data. They are stored in a specific order, ideally optimal for sampling.
The proposed storage system is a kind of compromise between various well-known methods: columnar, string, and NoSQL. It is designed to solve problems usually performed by one of these methods.
For example, the theory of column databases looks beautiful: we read only the desired column, and not all the rows of records entirely. However, in practice it is unlikely to place the data on the carrier so that it is applicable for dozens of different analysis cuts. Note that attributes and analytical metrics can be added and removed, and sometimes faster than we can rebuild this column economy. Not to mention that the data in the database can be adjusted, which will also violate the beauty of the sampling plan due to the inevitable fragmentation.
We have introduced a concept - a term - to describe any objects with which we operate: entity, props, request, file, etc. We will define all the terms that we use in our subject area. And with their help, we describe all the entities that have details, including in the form of connections between entities. For example, a prop is a link to a status reference record. The term is recorded with a data quintet.
A set of term descriptions is metadata that defines the structure of tables and fields of a conventional database. For example, there is the following data structure: an application from some date, which has content (application text) and State, to which participants in the production process add comments with the date. In the constructor of a traditional database, it will look something like this:

Since we decided to hide from the user all irrelevant details, such as binding IDs, for example, the scheme will be somewhat simplified: the references to IDs are removed and the names of entities and their key values are combined.
The user "draws" the task: a request from today's date that has a state (reference value) and to which you can add comments with the date:

Now we see 6 different data fields instead of 9, and the whole scheme suggests us to read and comprehend 7 words instead of 13. Although this is far from important, of course.
The following are quintets generated by the controlling kernel to describe this structure:

Explanations in place of the values of quintets, highlighted in gray, are given for clarity. These fields are not filled, because all the necessary information is uniquely determined by the other components.
Consider storing such a data set for the task described above:

The data itself is stored in quintets according to the structure with an indication of belonging to certain terms in the form of such a set:
We see a hierarchical structure familiar to many, stored by the method of a list of adjacent vertices (aka Adjacency List).
The above example is very simple, but what will happen when the structure is encountered thousands of times more complicated, and the data will be gigabytes?
We will need:
Thus, all records in our database will be indexed, including both data and metadata. This indexing is necessary to preserve the properties of the relational database - the simplest and most popular tool. The parent index is actually a composite (parent ID + type). The index by type is also composite (type + value) for quick search of objects of a given type.
Metadata allows us to get rid of recursion: for example, to find all the details of a given object, we use the index by parent ID. If a search for objects of a particular type is required, then an index by type ID is used. A type is an analogue of a table name and a field in a relational DBMS.

In any case, we do not scan the entire data set, and even with a large number of values of any type, the desired value is found in a small number of steps.
By itself, such a database is not self-sufficient for application programming, not complete, as they say, according to Turing. But we are not only talking about the database here, but we are trying to cover all aspects: objects are, among other things, arbitrary control algorithms that can be run, and they will work.
As a result, instead of complex database structures and separately stored source code of control algorithms, we get a uniform information field, limited by the volume of the media and marked up with metadata. The data itself is presented to the user in a form understandable to him — the structure of the subject area and the corresponding entries in it. The user arbitrarily changes the structure and data, including making bulk operations with them.
To work with such data representation, a very compact kernel will be needed - our database engine is an order of magnitude smaller than the computer BIOS, and therefore it can be made, if not in hardware, then at least fast and in the most polished form. For security reasons, also readable.
By adding a new class to my favorite .Net assembly, we can observe a loss of 200-300 MB of RAM to the description of this class only. These megabytes will not fit into the cache of the correct level, causing the system to get stuck with the consequences. The situation is similar with Java. The description of the same class by quintets will occupy tens or hundreds of bytes, since the class uses only primitive methods of working with data that are already familiar to the kernel.
The use of the described approach is not limited to quintets, but promotes a different paradigm than the one programmers are used to. In place of an imperative, declarative, or object language, a query language is proposed as more familiar to humans and allowing the task to be set directly to a computer, bypassing programmers and the impenetrable layer of existing development environments.
Of course, a translator from a free user language to a language of clear requirements will still be needed in most cases.
This topic will be discussed in more detail in separate articles with examples and existing developments.
So, in short, it works like this:
Turing completeness of the entire system is ensured by the implementation of the basic requirements: the kernel is able to perform sequential operations, branching by condition, processing data sets and stopping work upon achieving a certain result.
For a person, the benefit is simplicity of perception, for example, instead of declaring a cycle using variables
a more human-readable construction is used
We dream of abstracting from the low-level subtleties of implementing an information system: cycles, constructors, functions, manifestos, libraries — all of this takes up too much space in the programmer’s brain, leaving little room for creative work and development.
A modern application is unthinkable without scaling tools: an unlimited ability to expand the load capacity of an information system is required. In the described approach, in view of the extreme simplicity of data organization, scaling turns out to be organized is no more difficult than in existing architectures.
In the example with the requests above, you can divide them, for example, by their ID, making ID generation with fixed high bytes for different servers. That is, when using 32 bits for storing IDs, the upper two or three or four or more bits, as needed, will indicate the server on which these requests are stored. Thus, each server will have its own pool ID.
The core of a separate server can function independently of other servers without knowing anything about them. When creating an application, it will with a high priority get to the server with the minimum number of IDs used, ensuring even load distribution.
Given the limited set of possible variations of requests and responses with a unified data organization, a sufficiently compact dispatcher is needed that distributes requests across servers and aggregates their results.
I will talk about the new approach to storing and processing information and share thoughts about creating a development platform in this new paradigm.
A quintet has properties: type, value, parent, order among brothers. With the identifier, only 5 components are obtained. This is the simplest universal form of recording information, a new standard that can potentially suit everyone. Quintets are stored in the file system of a single structure, in a continuous monotonous indexed information field.
')
To record information there is an infinite number of standards, approaches and rules, knowledge of which is necessary for working with these records. Standards are described separately and have no direct connection with the data. In the case of quintets, taking any of them, you can get relevant information about its nature, properties and rules of work with its subject area. Its standard is one and unchanged for all areas. The quintet is hidden from the user - metadata and data are available to him in a form familiar to many.
A quintet is not only information, but also executable commands. But first of all it is the data that is required to be stored, recorded and retrieved. Since in our case they are directly addressable, linked and indexed, we will keep them in a kind of database. To test the prototype data storage system with quintets, for example, we used a regular relational database.
Quintet structure
The main idea of this article is to replace machine types with human terms and replace variables with objects. Not those objects that need a constructor, destructor, interfaces and garbage collector, but pure-crystal units of information that the customer operates on. That is, if the customer says "Application", then to save the essence of this information on the media would not require the expertise of the programmer.
It is useful to focus the user's attention only on the value of the object, and its type, parent, order (among equals in subordination) and identifier should be obvious from the context or simply hidden. This means that the user does not know anything about quintets at all , he simply sets out his task, makes sure that it is accepted correctly, and then starts its execution.
Basic concepts
There is a set of data types that can be understood by anyone: string, number, file, text, date, and so on. Such a simple set is quite sufficient for formulating the problem, and “programming” it and the types necessary for its implementation. The basic types represented by quintets might look like this:
In this case, part of the components of the quintet are not used, and he himself is used as the base type. This allows the system kernel to more easily navigate when navigating metadata.
Prerequisites
Due to the analytical gap between the user and the programmer, at the stage of problem statement, a significant deformation of concepts occurs. The lack of clarity, incomprehensibility and unsolicited initiative often turn the customer’s simple and understandable thought into a logically impossible mess, judging from the user's point of view.
The transfer of knowledge must occur without loss and distortion. Moreover, in the future, when organizing the storage of this knowledge, it is necessary to get rid of the restrictions imposed by the selected data management system.
How to store data
On the server, as a rule, there are many databases, each of them contains a description of the structure of entities with a specific set of details - interrelated data. They are stored in a specific order, ideally optimal for sampling.
The proposed storage system is a kind of compromise between various well-known methods: columnar, string, and NoSQL. It is designed to solve problems usually performed by one of these methods.
For example, the theory of column databases looks beautiful: we read only the desired column, and not all the rows of records entirely. However, in practice it is unlikely to place the data on the carrier so that it is applicable for dozens of different analysis cuts. Note that attributes and analytical metrics can be added and removed, and sometimes faster than we can rebuild this column economy. Not to mention that the data in the database can be adjusted, which will also violate the beauty of the sampling plan due to the inevitable fragmentation.
Metadata
We have introduced a concept - a term - to describe any objects with which we operate: entity, props, request, file, etc. We will define all the terms that we use in our subject area. And with their help, we describe all the entities that have details, including in the form of connections between entities. For example, a prop is a link to a status reference record. The term is recorded with a data quintet.
A set of term descriptions is metadata that defines the structure of tables and fields of a conventional database. For example, there is the following data structure: an application from some date, which has content (application text) and State, to which participants in the production process add comments with the date. In the constructor of a traditional database, it will look something like this:
Since we decided to hide from the user all irrelevant details, such as binding IDs, for example, the scheme will be somewhat simplified: the references to IDs are removed and the names of entities and their key values are combined.
The user "draws" the task: a request from today's date that has a state (reference value) and to which you can add comments with the date:
Now we see 6 different data fields instead of 9, and the whole scheme suggests us to read and comprehend 7 words instead of 13. Although this is far from important, of course.
The following are quintets generated by the controlling kernel to describe this structure:
Explanations in place of the values of quintets, highlighted in gray, are given for clarity. These fields are not filled, because all the necessary information is uniquely determined by the other components.
See how quintets are connected.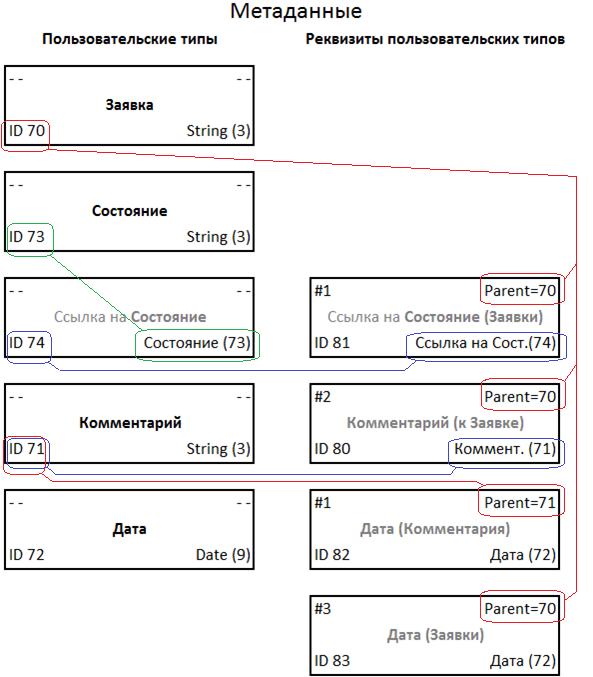
User Data
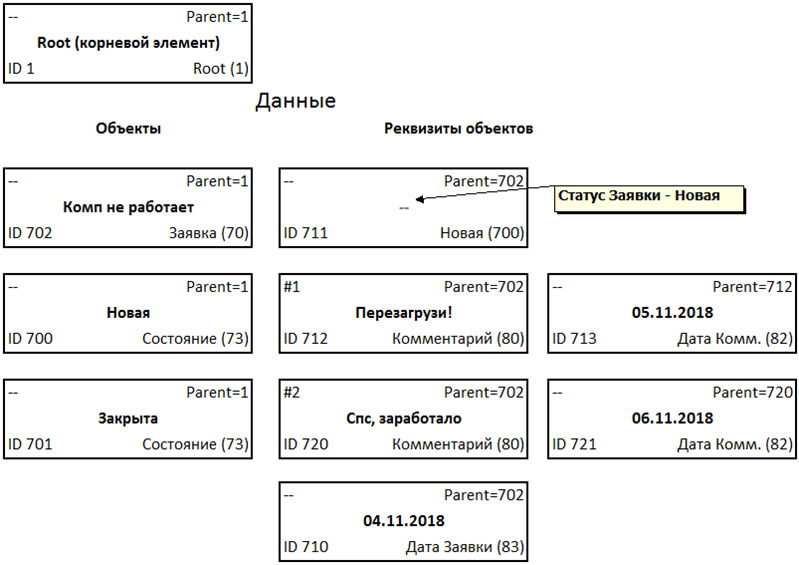
Consider storing such a data set for the task described above:
The data itself is stored in quintets according to the structure with an indication of belonging to certain terms in the form of such a set:
We see a hierarchical structure familiar to many, stored by the method of a list of adjacent vertices (aka Adjacency List).
Speed performance
The above example is very simple, but what will happen when the structure is encountered thousands of times more complicated, and the data will be gigabytes?
We will need:
- The above hierarchical structure - 1 pc.
- B-tree for searching by ID, parent and type - 3 pcs.
Thus, all records in our database will be indexed, including both data and metadata. This indexing is necessary to preserve the properties of the relational database - the simplest and most popular tool. The parent index is actually a composite (parent ID + type). The index by type is also composite (type + value) for quick search of objects of a given type.
Metadata allows us to get rid of recursion: for example, to find all the details of a given object, we use the index by parent ID. If a search for objects of a particular type is required, then an index by type ID is used. A type is an analogue of a table name and a field in a relational DBMS.
In any case, we do not scan the entire data set, and even with a large number of values of any type, the desired value is found in a small number of steps.
Basis for development platform
By itself, such a database is not self-sufficient for application programming, not complete, as they say, according to Turing. But we are not only talking about the database here, but we are trying to cover all aspects: objects are, among other things, arbitrary control algorithms that can be run, and they will work.
As a result, instead of complex database structures and separately stored source code of control algorithms, we get a uniform information field, limited by the volume of the media and marked up with metadata. The data itself is presented to the user in a form understandable to him — the structure of the subject area and the corresponding entries in it. The user arbitrarily changes the structure and data, including making bulk operations with them.
We have not invented anything new: all data is already stored in the file system and search in them is carried out with the help of B-trees, in the file system, in the databases. We only reorganized the presentation of the data to make it easier and more visually to work with them.
To work with such data representation, a very compact kernel will be needed - our database engine is an order of magnitude smaller than the computer BIOS, and therefore it can be made, if not in hardware, then at least fast and in the most polished form. For security reasons, also readable.
By adding a new class to my favorite .Net assembly, we can observe a loss of 200-300 MB of RAM to the description of this class only. These megabytes will not fit into the cache of the correct level, causing the system to get stuck with the consequences. The situation is similar with Java. The description of the same class by quintets will occupy tens or hundreds of bytes, since the class uses only primitive methods of working with data that are already familiar to the kernel.
How to deal with different formats: RDBMS, NoSQL, column databases
The described approach covers two main areas: RDBMS and NoSQL. When solving problems that take advantage of column databases, we will need to tell the kernel that certain objects should be stored, taking into account the optimization of the mass sample of values of a certain data type (our term). So the kernel will be able to place the data on the disk most profitable.
Thus, for a column base, we can significantly save the space occupied by quintets: use only one or two of its components to store useful data instead of five, and also use an index only to indicate the beginning of data chains. In many cases, only the index will be used for samples from our analogue of the column database, without the need to refer to the data of the table itself.
It should be noted that the idea does not set goals to collect all the advanced development of these three types of databases. On the contrary, the engine of the new system will be maximally reduced, embodying only the necessary minimum of functions - everything that covers the DDL and DML queries in the concept described here.
Thus, for a column base, we can significantly save the space occupied by quintets: use only one or two of its components to store useful data instead of five, and also use an index only to indicate the beginning of data chains. In many cases, only the index will be used for samples from our analogue of the column database, without the need to refer to the data of the table itself.
It should be noted that the idea does not set goals to collect all the advanced development of these three types of databases. On the contrary, the engine of the new system will be maximally reduced, embodying only the necessary minimum of functions - everything that covers the DDL and DML queries in the concept described here.
Programming paradigm
The use of the described approach is not limited to quintets, but promotes a different paradigm than the one programmers are used to. In place of an imperative, declarative, or object language, a query language is proposed as more familiar to humans and allowing the task to be set directly to a computer, bypassing programmers and the impenetrable layer of existing development environments.
Of course, a translator from a free user language to a language of clear requirements will still be needed in most cases.
This topic will be discussed in more detail in separate articles with examples and existing developments.
So, in short, it works like this:
- With quintets, we once described primitive data types: string, number, file, text, and others, and also taught the core how to work with them. Training is reduced to the correct presentation of data and the implementation of simple operations with them.
- Now we describe user terms (data types) with quintets - in the form of metadata. The description boils down to specifying a primitive data type for each user type and defining the subordination.
- We transfer the data quintets according to the structure specified by the metadata. Each data quintet contains a link to its type and parent, which allows you to quickly find it in the data warehouse.
- The core tasks are reduced to sampling data and performing simple operations with them to implement as many complex algorithms as described by the user.
- The user manages data and algorithms using a visual interface that visually represents both the first and second.
Turing completeness of the entire system is ensured by the implementation of the basic requirements: the kernel is able to perform sequential operations, branching by condition, processing data sets and stopping work upon achieving a certain result.
For a person, the benefit is simplicity of perception, for example, instead of declaring a cycle using variables
for (i=0; i<length(A); i++) if A[i] meets a condition do something with A[i] a more human-readable construction is used
with every A, that match a condition, do something We dream of abstracting from the low-level subtleties of implementing an information system: cycles, constructors, functions, manifestos, libraries — all of this takes up too much space in the programmer’s brain, leaving little room for creative work and development.
Scaling
A modern application is unthinkable without scaling tools: an unlimited ability to expand the load capacity of an information system is required. In the described approach, in view of the extreme simplicity of data organization, scaling turns out to be organized is no more difficult than in existing architectures.
In the example with the requests above, you can divide them, for example, by their ID, making ID generation with fixed high bytes for different servers. That is, when using 32 bits for storing IDs, the upper two or three or four or more bits, as needed, will indicate the server on which these requests are stored. Thus, each server will have its own pool ID.
The core of a separate server can function independently of other servers without knowing anything about them. When creating an application, it will with a high priority get to the server with the minimum number of IDs used, ensuring even load distribution.
Given the limited set of possible variations of requests and responses with a unified data organization, a sufficiently compact dispatcher is needed that distributes requests across servers and aggregates their results.
Source: https://habr.com/ru/post/433058/
All Articles