A needle in a stack of sessions, or regular expression bytecode

17 billion events, 60 million user sessions and a huge number of virtual dates occur in Badoo every day. Each event is carefully stored in relational databases for subsequent analysis in SQL and not only.
Modern distributed transactional databases with dozens of terabytes of data is a real engineering marvel. But SQL as the embodiment of relational algebra in most standard implementations does not yet allow formulating queries in terms of ordered tuples.
In the last article in the virtual machines series, I’ll talk about an alternative approach to finding interesting sessions — the regular expression engine ( “The Pig Matcher” ) defined for sequences of events.
Virtual machine, bytecode and compiler are attached for free!
About events and sessions
Suppose we already have a data warehouse that allows us to quickly and consistently view the events of each of the user sessions.
We want to find sessions based on requests like “count all sessions where there is a specified subsequence of events”, “find parts of a session described by a given pattern”, “return that portion of a session that happened after a given pattern” or “calculate how many sessions have reached certain parts template. " This can be useful for various types of analysis: search for suspicious sessions, funnel analysis, etc.
The required subsequences must somehow be described. In its simplest form, this task is similar to finding a substring in the text; we want to have a more powerful tool - regular expressions. Modern implementations of regular expression engines most often use (you guessed it!) Virtual machines.
Creating small virtual machines for matching sessions with regular expressions will be discussed below. But first let's clarify the definition.
An event consists of an event type, a time, a context, and a set of attributes specific to each type.
The type and context of each of the events are integers from predefined lists. If everything is clear with the types of events, then the context is, for example, the number of the screen on which the specified event occurred.
An event attribute is an arbitrary integer whose meaning is determined by the type of event. There may be no attributes of the event, or there may be several of them.
A session is a sequence of events sorted by time.
But let's finally get down to business. The buzz, as they say, subsided, and I went to the stage.
Compare by piece of paper
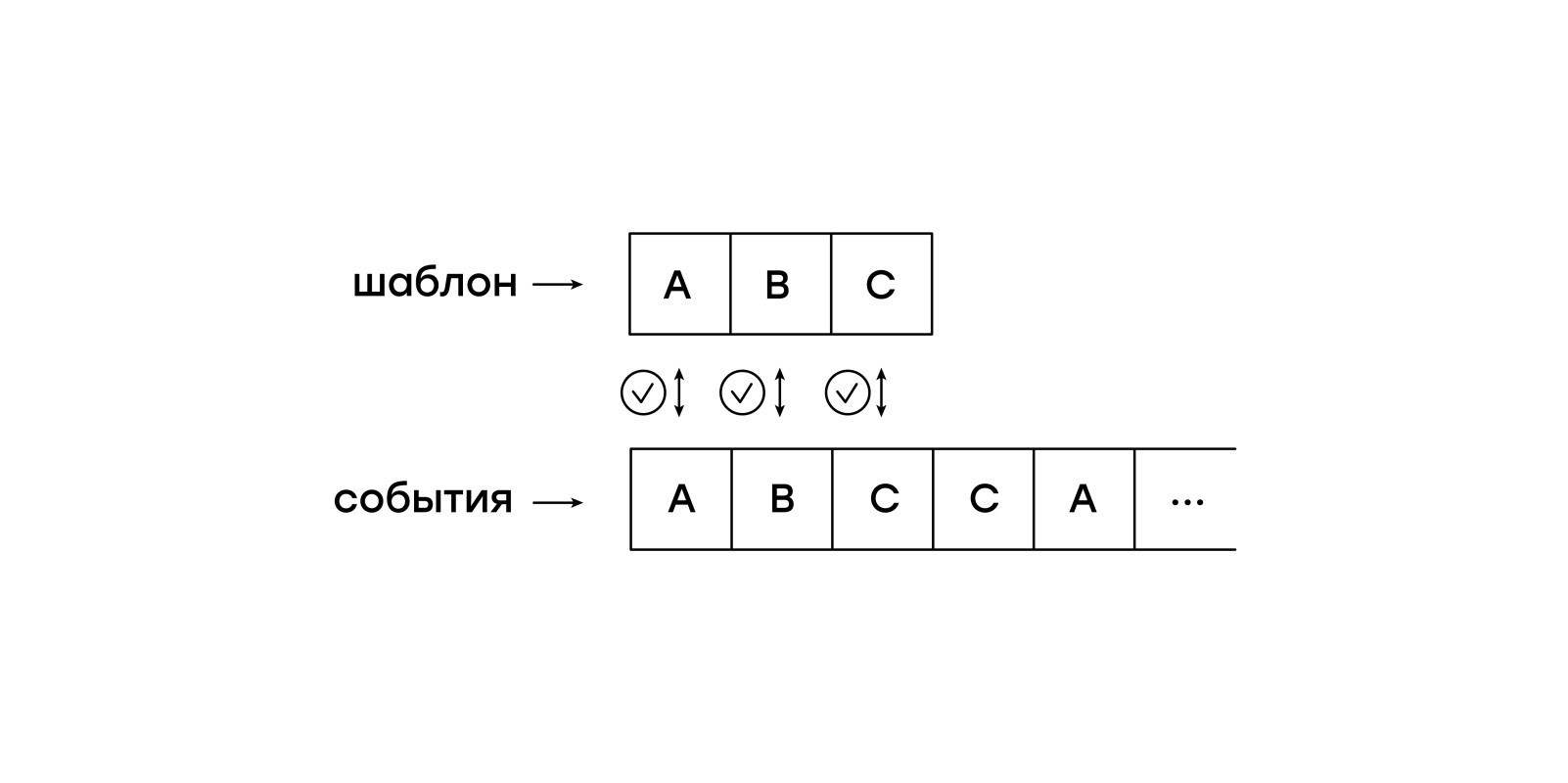
The peculiarity of this virtual machine is passivity in relation to input events. We do not want to keep the entire session in memory and allow the virtual machine to go from event to event independently. Instead, we will, one after another, submit events from the session to the virtual machine.
Define interface functions:
matcher *matcher_create(uint8_t *bytecode); match_result matcher_accept(matcher *m, uint32_t event); void matcher_destroy(matcher *matcher); If everything is clear with the functions matcher_create and matcher_destroy, then the matcher_accept should be commented. The matcher_accept function receives an instance of the virtual machine and the next event (32 bits, where 16 bits are for the type of event and 16 bits are for the context), and returns a code explaining what to do next to the user code:
typedef enum match_result { // MATCH_NEXT, // , MATCH_OK, // , MATCH_FAIL, // MATCH_ERROR, } match_result; Virtual machine opcodes:
typedef enum matcher_opcode { // , OP_ABORT, // ( - ) OP_NAME, // ( - ) OP_SCREEN, // OP_NEXT, // OP_MATCH, } matcher_opcode; The main loop of the virtual machine:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP() \ (*m->ip++) #define NEXT_ARG() \ ((void)(m->ip += 2), (m->ip[-2] << 8) + m->ip[-1]) for (;;) { uint8_t instruction = NEXT_OP(); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(); if (event_name(next_event) != name) return MATCH_FAIL; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(); if (event_screen(next_event) != screen) return MATCH_FAIL; break; } case OP_NEXT:{ return MATCH_NEXT; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } #undef NEXT_OP #undef NEXT_ARG } In this simple version, our virtual machine sequentially matches the pattern described by the byte code with the incoming events. In this form, it is simply not too concise a comparison of the prefixes of two lines: the desired pattern and the input string.
Prefixes are prefixes, but we want to find the required templates not only at the beginning, but also in an arbitrary place of the session. A naive solution is to restart the mapping from each session event. But this implies a multiple viewing of each of the events and the eating of algorithmic babies.
The example from the first article of the series, in effect, simulates the restart of the mapping with the help of rollback (eng. Backtracking). The code in the example looks, of course, slimmer given here, but the problem has not gone away: each of the events will have to check many times.
So you can not live.
I, I again and I again

Let's once again denote the task: it is necessary to match the pattern with the incoming events, starting from each of the events a new mapping. So why don't we do that? Let the virtual machine go through the incoming events in several threads!
To do this, we need to create a new entity - a stream. Each stream stores a single pointer — to the current instruction:
typedef struct matcher_thread { uint8_t *ip; } matcher_thread; Naturally, we will not store an explicit pointer in the virtual machine itself either. It will be replaced by two lists of threads (about them below):
typedef struct matcher { uint8_t *bytecode; /* Threads to be processed using the current event */ matcher_thread current_threads[MAX_THREAD_NUM]; uint8_t current_thread_num; /* Threads to be processed using the event to follow */ matcher_thread next_threads[MAX_THREAD_NUM]; uint8_t next_thread_num; } matcher; And here is the updated main loop:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP(thread) \ (*(thread).ip++) #define NEXT_ARG(thread) \ ((void)((thread).ip += 2), ((thread).ip[-2] << 8) + (thread).ip[-1]) /* - */ add_current_thread(m, initial_thread(m)); // for (size_t thread_i = 0; thread_i < m->current_thread_num; thread_i++ ) { matcher_thread current_thread = m->current_threads[thread_i]; bool thread_done = false; while (!thread_done) { uint8_t instruction = NEXT_OP(current_thread); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(current_thread); // , , // next_threads, if (event_name(next_event) != name) thread_done = true; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(current_thread); if (event_screen(next_event) != screen) thread_done = true; break; } case OP_NEXT:{ // , .. // next_threads add_next_thread(m, current_thread); thread_done = true; break; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } } /* , */ swap_current_and_next(m); return MATCH_NEXT; #undef NEXT_OP #undef NEXT_ARG } At each received event, we first add the current_threads new stream to the list, checking the pattern from the very beginning, and then we begin to crawl the current_threads list, for each of the threads, following the instructions on the pointer.
If the NEXT instruction is encountered, the thread is placed in the list of next_threads, that is, waiting for the next event to be received.
If the thread template does not match the event received, then such a thread is simply not added to the next_threads list.
The MATCH instruction immediately exits the function, telling the return code that the pattern matches the session.
When the thread list traversal is complete, the current and next lists are swapped.
Actually, everything. We can say that we literally do what we wanted: we simultaneously check several templates, launching one new matching process for each of the session events.
Multiple personalities and branches in patterns
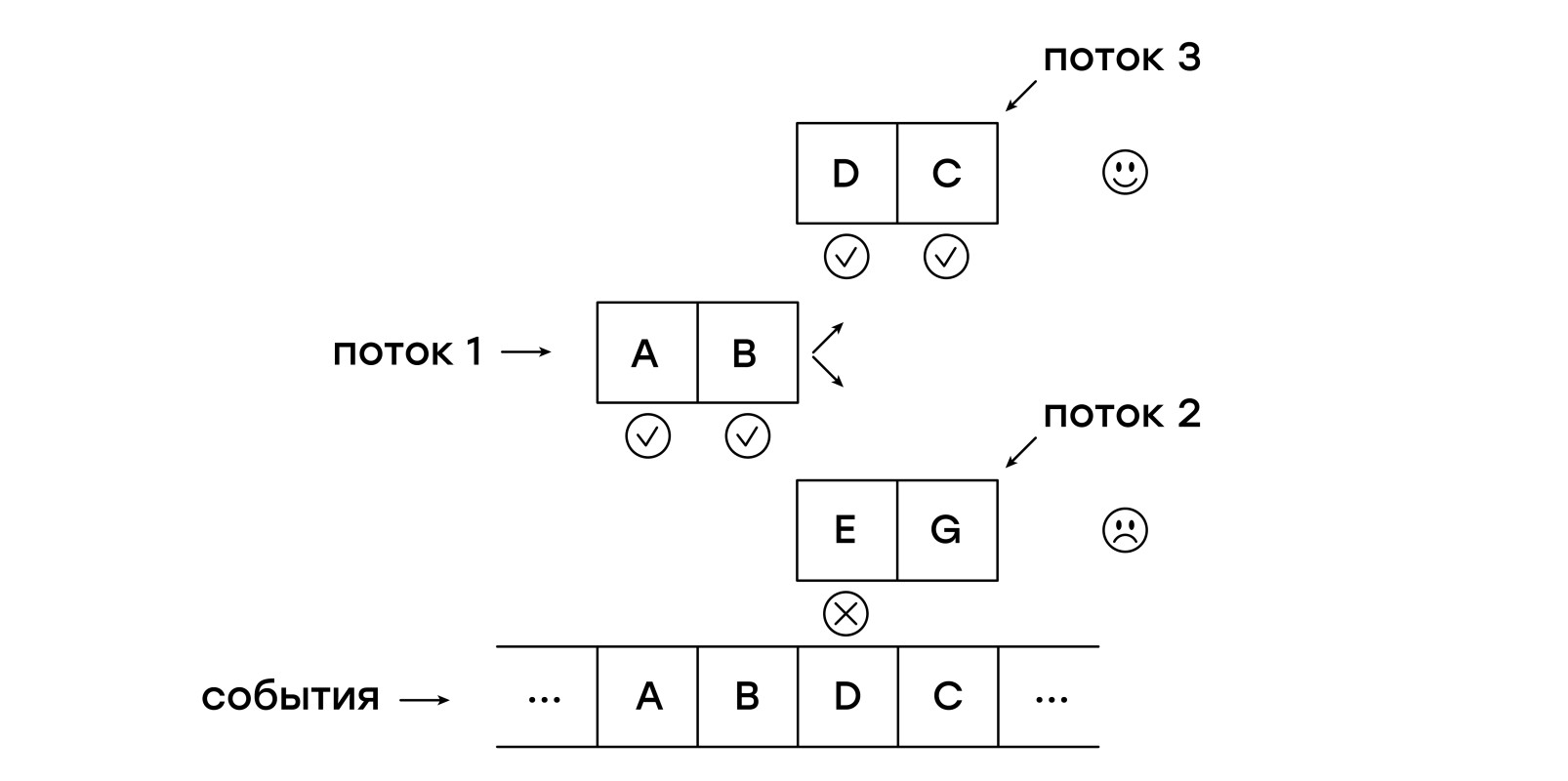
Looking for a template that describes a linear sequence of events is, of course, useful, but we want to get full-fledged regular expressions. And the streams that we created in the previous step will also be useful here.
Suppose we want to find a sequence of two or three events of interest to us, something like a regular expression on the strings: "a? Bc". In this sequence, the character "a" is optional. How to express it in bytecode? Easy!
We can run two streams, one for each case: with and without the "a" symbol. To do this, we introduce an additional instruction (of the form SPLIT addr1, addr2), which starts two streams from the specified addresses. In addition to SPLIT, we can also use JUMP, which simply continues execution with the instruction specified in the argument directly:
typedef enum matcher_opcode { OP_ABORT, OP_NAME, OP_SCREEN, OP_NEXT, // OP_JUMP, // OP_SPLIT, OP_MATCH, // OP_NUMBER_OF_OPS, } matcher_opcode; The loop itself and the remaining instructions do not change - we will simply add two new handlers:
// ... case OP_JUMP:{ /* , */ uint16_t offset = NEXT_ARG(current_thread); add_current_thread(m, create_thread(m, offset)); break; } case OP_SPLIT:{ /* */ uint16_t left_offset = NEXT_ARG(current_thread); uint16_t right_offset = NEXT_ARG(current_thread); add_current_thread(m, create_thread(m, left_offset)); add_current_thread(m, create_thread(m, right_offset)); break; } // ... Notice that the instructions add threads to the current list, that is, they continue to work in the context of the current event. The thread within which a branch has occurred is no longer in the list of the following threads.
The most surprising thing about this virtual machine for regular expressions is that our threads and this pair of instructions are enough to express almost all the constructs that are common when matching strings.
Regular expressions on events
Now that we have the right virtual machine and the tools for it, we can deal with the syntax for our regular expressions.
Manual recording opcodes for more serious programs quickly tires. Last time I didn’t make a full-fledged parser, but the user true-grue showed the capabilities of his raddsl library using the example of the mini-language PigletC . I was so impressed with the brevity of the code that with the help of raddsl I wrote a small compiler of regular expressions of lines a hundred or two hundred in Python. The compiler and instructions for its use are on GitHub. The result of the compiler's work in assembly language is understood by the utility that reads two files (a program for a virtual machine and a list of session events for verification).
To begin with, we limit ourselves to the type and context of the event. Event type is denoted by a single number; if you need to specify a context, we specify it through a colon. The simplest example is:
> python regexp/regexp.py "13" # , 13 NEXT NAME 13 MATCH Now an example with context:
python regexp/regexp.py "13:12" # 13, 12 NEXT NAME 13 SCREEN 12 MATCH Sequential events must be somehow separated (for example, by spaces):
> python regexp/regexp.py "13 11 10:9" 08:40:52 NEXT NAME 13 NEXT NAME 11 NEXT NAME 10 SCREEN 9 MATCH The template is more interesting:
> python regexp/regexp.py "12|13" SPLIT L0 L1 L0: NEXT NAME 12 JUMP L2 L1: NEXT NAME 13 L2: MATCH Note the lines ending with a colon. These are tags. The SPLIT instruction creates two threads that continue execution from the L0 and L1 tags, and the JUMP at the end of the first branch of execution just goes to the end of the branch.
You can choose between chains of expressions more genuinely by grouping subsequences with parentheses:
> python regexp/regexp.py "(1 2 3)|4" SPLIT L0 L1 L0: NEXT NAME 1 NEXT NAME 2 NEXT NAME 3 JUMP L2 L1: NEXT NAME 4 L2: MATCH An arbitrary event is indicated by a period:
> python regexp/regexp.py ". 1" NEXT NEXT NAME 1 MATCH If we want to show that the subsequence is optional, then we put a question mark after it:
> python regexp/regexp.py "1 2 3? 4" NEXT NAME 1 NEXT NAME 2 SPLIT L0 L1 L0: NEXT NAME 3 L1: NEXT NAME 4 MATCH Of course, regular repeated expressions are also supported in regular expressions (plus or asterisk):
> python regexp/regexp.py "1+ 2" L0: NEXT NAME 1 SPLIT L0 L1 L1: NEXT NAME 2 MATCH Here we simply repeatedly execute the SPLIT instruction, launching new threads on each cycle.
Similarly with an asterisk:
> python regexp/regexp.py "1* 2" L0: SPLIT L1 L2 L1: NEXT NAME 1 JUMP L0 L2: NEXT NAME 2 MATCH 
Perspective
Other extensions of the described virtual machine may be useful.
For example, it can easily be extended by checking the attributes of events. For a real system, I intend to use a syntax like “1: 2 {3: 4, 5:> 3}”, which means: event 1 in context 2 with attribute 3 having a value of 4 and attribute value 5 exceeding 3. Attributes here you can simply pass the array to the function matcher_accept.
If you also pass the time interval between events to matcher_accept, then you can add a syntax to the template language that allows you to skip the time between events: "1 mindelta (120) 2", which means: event 1, then the interval of at least 120 seconds, event 2 In combination with the preservation of a subsequence, this allows you to collect information about user behavior between two subsequences of events.
Other useful things that are relatively easy to add are: retaining regular expression subsequences, separating the "greedy" and ordinary asterisk and plus operators, and so on. Our virtual machine in terms of the theory of automata is a non-deterministic finite-state machine, for the realization of which such things are easy to do.
Conclusion
Our system is developed for fast user interfaces, so the session storage engine is self-written and optimized for all sessions. All billions of events broken into sessions are checked for compliance with the patterns in seconds on a single server.
If speed is not so critical for you, then a similar system can be arranged as an extension for some more standard data storage system like a traditional relational database or a distributed file system.
By the way, in recent versions of the SQL standard , a feature similar to that described in the article has already appeared, and some databases ( Oracle and Vertica ) have already implemented it. In turn, Yandex ClickHouse implements its own SQL-like language, but there are similar functions there as well .
Aside from events and regular expressions, I want to repeat that the applicability of virtual machines is much broader than it might seem at first glance. This technique is suitable and widely used in all cases when there is a need to clearly separate the primitives that the system's engine understands, and the “front” subsystem, that is, for example, some DSL or programming language.
This concludes a series of articles on various applications of bytecode interpreters and virtual machines. I hope, Habr's readers liked the series and, of course, I will be glad to answer any questions on the topic.
Informal bibliography
Bytecode interpreters for programming languages is a specific topic, and there is relatively little literature on them. I personally liked the book “Virtual Machines” by Ayan Craig, although it describes not so much the implementation of interpreters as the abstract machines — the mathematical models that underlie various programming languages.
In a broader sense, another book is devoted to virtual machines - “Virtual Machines: Flexible Platforms for Systems and Processes” (“Virtual Machines: Versatile Platforms for Systems and Processes”). This is an introduction to the various applications of virtualization, encompassing the virtualization of both languages, processes and computer architectures in general.
Practical aspects of developing regular expression engines are rarely discussed in popular compiler literature. The Pig Matcher and the example from the first article are based on ideas from the stunning series of articles by Russ Cox, one of the developers of the Google RE2 engine.
The theory of regular expressions is presented in all academic compiler textbooks. It is customary to refer to the famous "Book of the Dragon" , but I would recommend to start with the above link.
Working on an article, for the first time I used an interesting system for the rapid development of Python compilers raddsl , owned by the user of true-grue (thanks, Peter!). If you are faced with the task of prototyping a language or quickly developing some DSL, you should pay attention to it.
')
Source: https://habr.com/ru/post/433054/
All Articles