Christmas story
We want to share a story that happened on one of our projects on New Year's Eve. The essence of the project is that it automates the work of doctors in medical institutions. During the patient's visit, the doctor records information on a dictaphone, then the audio recording is transcribed. After the transcription process - i.e. making audio recordings into text - a medical document is compiled according to the relevant standards and sent back to the clinic where the audio recording came from, where the sending doctor receives it, checks and approves After passing the mandatory checks, the document is sent to the final patients.
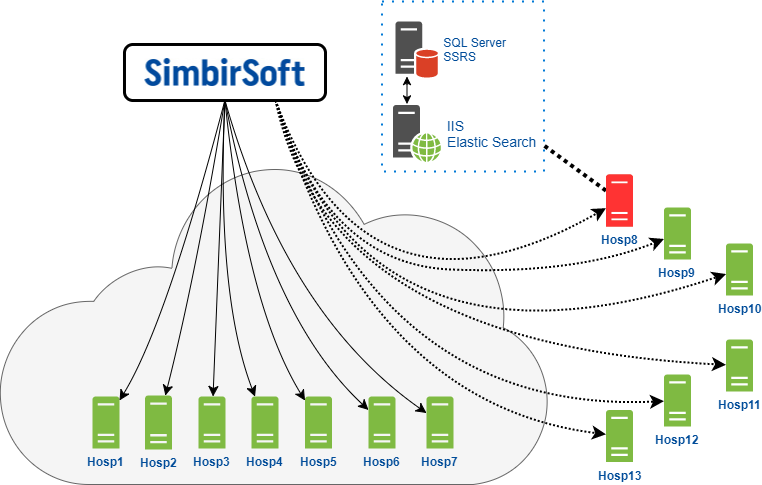
All medical institutions using the product can be divided into two large groups:
This is how our team interacts with end servers hosted directly in our client’s cloud.

')
We have access to these servers to carry out all the planned work and maintenance that is required.
The second group is self-hosted clients - for them the client cloud acts as a gateway through which we connect to these servers. We have limited rights in this case, and often we cannot perform any operations due to security settings. We connect to the servers via RDP - Remote Desktop Protocol on Windows OS. Naturally, this all works through VPN.
Here we must bear in mind that each server represented in the diagram is in fact a bundle of an application server and a database server. On the database server, MS SQL Server DBMS and SSRS reporting service are installed respectively. Moreover, the MSSQL Server version is different in all clinics: 2008, 2012, 2014. In addition to the versions themselves, different Service Packs and patches are installed everywhere. In general, a complete zoo.
We have an IIS web server and ElasticSearch installed on the application server. ElasticSearch is a search engine, which also implements full-text search.
The main entity in terms of our product is “job” (job). Work is an abstract entity that binds together all the information related to a particular patient's reception. This information includes:
This diagram shows a simplified database schema, from which you can see the relationships between the main tables. This is only the base part, in fact in the database of more than 200 tables.

A little about the clinic where the incident happened:
DB:
Here I want to make a little explanation. There are 3 recovery models in SQL Server: simple, bulk-logged, and full. I will not speak about the third now, I will explain about the first and second. The main difference is that in the simple model, we do not keep a transaction history in the log — once the transaction has been committed, the record from the transaction log will be deleted. When using the full recovery mode, the entire history of data changes is stored in the transaction log. What does this give us? In case of some unforeseen situation, when we need to roll back the database from the backup, we can return not only to some specific backup, but we can return to any point in time, up to a certain transaction, i.e. In backups, not only is a certain state of the database at the time of backup, but also the whole is a history of data changes.
I think it’s not worth explaining that the simple mode is used only in development, on test servers and its use in production is unacceptable. Not at all.
But the clinic, apparently, had its own thoughts on this subject;)
A few days later, the New Year, everyone is preparing for the holiday, buying presents, decorating Christmas trees, holding corporate parties and are waiting for a long weekend.
14:31 The client said that he had not received another daily report. The report arrives at the mail twice a day on a schedule; it is needed to control the sending of data to an external integration system, which is not too critical.
There could be several reasons:
16:03 The clinic sometimes changes the password to SMTP, without warning anyone about it, so after finishing the current tasks, we calmly check the report manually by launching through the web interface — we get an error that indicates problems in the database.
An example of an error that we received when running the report.
This indicates that there are damaged pages in the database. We had a slight feeling of anxiety.
20:53 In order to assess the extent of damage, we launch the database check using the special command DBCC CHECKDB . Depending on the size of the damage, the verification team can take quite a long time, so we launch the command in the night. Here we are lucky that this happened on Friday afternoon, that is, we had at least the whole weekend to solve this problem.
At that moment the situation was as follows:
10:02 In the morning, we find out that checking the database using CHECKDB has stopped - this was due to the lack of free disk space, since the tempdb temporary database is actively used in the verification process, and at some point the free disk space just ran out.
Therefore, instead of checking the entire database, we decide to immediately launch a public check. To do this, use the DBCC CHECKTABLE command .
10:46 We decide to start with the JobHistory table, which is probably damaged, because it was used to generate the report. This table, as can be understood from the title, keeps the history of all works, i.e., transitions of work between stages.
Run DBCC CHECKTABLE ('dbo.JobHistory') .
Checking this table reveals damaged tables in the database, which in principle was expected.
12:00 At the moment, if the database used the full recovery model, we could restore the damaged pages from the backup, and that would be the end of it, but our database was in simple mode. Therefore, the only option for repairing damage is to launch the same command with the special parameter REPAIR_ALLOW_DATA_LOSS . In this case, data loss is possible.
We start. The check again fails - we get an error that the recovery of this table is impossible until the linked tables are restored. The history table refers to the work table (Jobs) by the foreign key, therefore, we conclude that there is also damage in the main work table (Jobs).
13:30 The next step is to check the Jobs table, while hoping that the damage is in the index, not in the data. In this case, it will be enough for us to simply rebuild the index for data recovery.
17:33 After a while, we discover that our server is unavailable via RDP. It was probably turned off, the check was not completed, the work was suspended. We inform the clinic that the server is unavailable, please raise it.
Light anxiety takes very specific forms.
14:31 Closer to the dinner server is raised, re-start checking the Jobs table.
DBCC CHECKTABLE ('dbo.Jobs')
16:05 Verification is not complete, the server is unavailable. Again.
After some time, the server is again unavailable, before we could complete the check of the table. At this moment, the IT clinic service performs a series of server checks. We are waiting for the completion of work.
Due to holidays, communication between us and the client was slow - we were waiting for answers to questions for several hours.
16:00 The next day, the server was raised, the client has Christmas, and we again start checking the table, but this time we exclude the indexes from the check, and leave only the data check. And after a while the server is again unavailable.
What is going on?
At this moment, thoughts begin to creep in that this is not just a coincidence, and there is a suspicion that it could be damage at the level of iron (a hard disk fell down). We assume that there are bad sectors on the disk and when the check tries to read data from these sectors, the system crashes. We inform on the assumption to the client.
The client runs a disk check on the host machine.
17:19 IT clinic service reported that the virtual machine file is damaged - this is bad! (
We still can not work, and wait for the signal when they fix the problem and we can continue our work.
14:05 IT clinic service starts another disk recovery process. We were told that we can run CHECKTABLE in parallel to check the table. We start the scan again - the virtual is crashing again, we inform the client that the virtual machine file is still damaged.
These days all communications with the customer are very slow with a huge time lag due to holidays.
14:00 Run the disk check using Windows tools - checkdisk inside the virtual machine - no problems identified.
The database is in the Simple mode, so the chances of correcting the current database by means of the DBMS tend to zero, since we are unable to repair individual damaged pages.
We begin to consider the option of rolling back and restoring the database from backup.
We check the backups of the database and find out that backups were not made using DBMS tools, the last backup was in 2014, i.e. There are no backups. Why not done - a separate question, it is the responsibility of the clinic to ensure the health and safety of the database.
There is a high probability that it will not be possible to restore the current database, we begin to consider other options for rollback.
Let's take a closer look at the situation with backups in the clinic.
Backup situation:
The database is on disk D, respectively, they made weekly full backups and daily incremental backups.
Those. in principle, we can roll back to the state before the problem occurs.
We are waiting for the update from the clinic to start rolling back the database from the backup.
At the same time, the clinic sent a request to an iron supplier (HP) marked “urgent”.
13:13 The IT service of the clinic begins setting up a new virtual machine, since Fix the damage in the file of the old virtual machine does not work.
19:09 A new virtual machine is available with SQL Server installed.
The next step is to restore the database from the disk backup. To begin with, we decide to roll back to the 22nd, if the problem is still present, then we roll back to the 21st, 20th, and so on, until we reach a working state.
It was the 28th in the courtyard, we are at a corporate party, and here we are informed that the clinic has problems with restoring the backup, because the backups are EMPTY!
Here is the news!
During the recovery of the backup of disk D from the 21st, it turns out that it is empty, like all the others. Directly backups Schrödinger obtained - they seem to be as it is, but at the same time, they are not. It is not completely clear how this happened at all, but, as far as we were able to understand, the problem is not enough space on the disk to store disk backups. They allocated 500 Gb backups for storage, but at the time of the incident the database already weighed 800 Gb, therefore, in principle, the backup could not be passed successfully. Those. backups were regularly done on a schedule, but due to lack of space, they ended up with an error and were therefore empty, and the IT-service of the clinic did not even bother to check that everything was fine with them. Do not do it this way.
13:11 Discussion of further action. Possible options:
On the new server, 1 Tb disk was allocated, which is obviously not enough if we try to backup and restore from it, because in the worst case, without compression, the backup will take up as much space as the original database, i.e. 800 Gb.
Please add space on the new server and proceed to copying the database files.
A database has been created on the new server and the database schema has been restored - this will allow at least to process new jobs. The clinic will at least be able to accept new patients using this system.
14:36 Therefore, we proceed to option number one, although we don’t expect much success.
Stop the SQL Server, start copying the data file (mdf) and log (ldf).
16:13 After one and a half, the log file was copied successfully (48 Gb), and 50 GB of data file were already copied (795 of 846 GB left). At this speed, it will take about 12 hours to complete the copy.
16:30 Old database server turned off while copying a file, which is quite expected.
17:09 Therefore, we move on to the next option — setting up replication; in this case, we can specify which data will be replicated, that is, we can first exclude obviously damaged tables and copy the intact data first, and then transfer the problem tables in parts. But this option, unfortunately, also does not work, since we cannot even create a publication with certain tables due to database damage.
Consider more options for transferring data.
20:01 In the end, we start simply to transfer data from the old to the new server in a regular manner by importing and exporting in order of priority.
21:35 First, the most critical data, then archived and less critical data (~ 300 GB). In the first wave of exports, less than 300 GB of data remained. Table Documents is also excluded (300GB). Run the copy process in the night.
15:00 We continue to transfer data. Jobs table is not available at all. The main part of the tables was copied by this time.
But without Jobs, it's all useless, because it is the main link between all the data and gives them meaning and value from a business point of view. Without it, we simply have a fragmented set of data that we can’t use.
Also at this point the restoration of the database schema is complete.
Consequences of the incident:
By this moment we have a huge loss of live data.
Those. Formally, we have some data in the database, but, in fact, there is no way to use them or link them together, so we can talk about complete data loss.
More than 750,000 patient admissions have been lost.
This is really sad!
We began to think what we can do in this situation. Began to sort through the system to find clues.
15:16 Analyzing all aspects of the system, we understand that we can try to extract the missing data from the ElasticSearch index. The fact of the matter is that due to the incorrect configuration of the ElasticSearch indexes, it stores not only the fields by which full-text search is performed, but everything, that is, in fact, there is a complete copy of the data and we can theoretically extract data from there about jobs and put them back into our database. It is hoped that the data will still be restored.
A bug that you can put a monument!

18:00 The utility for data extraction was quickly written and after a few hours we are convinced that the approach works and the data will be restored.
20:00 Started restoring works from ElasticSearch with the help of a written utility. The approach worked, data about the work can be restored. In parallel, we begin to extract the latest versions of the document for each work.
14:09 During the night, 188,811 works were restored.
20:13 Seeing our success, the clinic decides to postpone the transfer of the server to the HP service in order to give us time to extract the maximum data from the old server.
With such news, we met the New Year))
11:23 Preparation for launching the system after the incident:
14:28 Then they began to copy a table of documents, which was skipped during the initial transfer due to its large size.
- The old DB server has shut down again. It is obvious that the Documents table is also damaged; it is with it that all information on patients is stored. Fortunately, it is not completely damaged, we can make requests to it, and when a request to us returns a damaged record, at this moment the server crashes and turns off. Part of the data in this case we can extract.
Accordingly, we signal the client, they raise the server, and in parallel we continue to prepare the new database for the launch of the system.
18:01 Restoring all integrity constraints after transferring the main part of the data.
22:02 Restoring constraints completed. We just carried the raw data to the maximum. The presence of integrity constraints would greatly complicate our task.
05:52 Old DB server turned off again while copying the document. He is promptly picked up so that we can continue to work.
09:00 Batch managed to recover about 200.000 documents (approximately 20%)
We started using different recovery methods: sorting by different columns to retrieve data from the end or beginning of the table, until we hit some damaged part of the table.
13:42 Started copying archival works in the table - it is, fortunately, not damaged.
17:08 Restored all archival work (491,380 pieces).
The system is ready to launch: users can create and process new jobs.
Unfortunately, due to partial damage to the table of documents, you can not just transfer all the data from it, as with other tables, because The table is partially damaged. Therefore, when you try to retrieve all the data, the request falls with an error when you try to read damaged pages. Therefore, we extract the data point-wise, using different sorts and sample size:
08:58 Continued the process of recovering documents. Documents were restored only for active, unfinished work. By this time 1000 works (active) without documents.
11:38 Moved all SQL Jobs
13:17 5 works without documents, 231 work is missing, but there is an audio file, you need to resynchronize.
Started manual restoration and verification of remaining work.
The system works, monitoring and correction of errors in online mode.
Reports are scheduled for migration to SSRS.
Transfer to the new server is impossible, because In the clinic, an older version of SQL Server was installed and the database could not be moved from the old server.
Options:
It was decided to wait for the update of SQL Server.
09:21 Background restoration of documents for completed works started - the process is long and will take several days.
13:28 Change the priority of the recovery of documents by department.
18:18 Clinic gave access to SMTP, mail setup
All medical institutions using the product can be divided into two large groups:
- Hosting in the data center of our client, who is fully responsible for the performance of the application, both for the software and for the hardware. For example, if disk space runs out, or there is not enough server performance on the CPU;
- Self-hosted: they place all the equipment directly at themselves and are responsible for its performance. Our client provides them with the application and its support.
This is how our team interacts with end servers hosted directly in our client’s cloud.
')
We have access to these servers to carry out all the planned work and maintenance that is required.
The second group is self-hosted clients - for them the client cloud acts as a gateway through which we connect to these servers. We have limited rights in this case, and often we cannot perform any operations due to security settings. We connect to the servers via RDP - Remote Desktop Protocol on Windows OS. Naturally, this all works through VPN.
Here we must bear in mind that each server represented in the diagram is in fact a bundle of an application server and a database server. On the database server, MS SQL Server DBMS and SSRS reporting service are installed respectively. Moreover, the MSSQL Server version is different in all clinics: 2008, 2012, 2014. In addition to the versions themselves, different Service Packs and patches are installed everywhere. In general, a complete zoo.
We have an IIS web server and ElasticSearch installed on the application server. ElasticSearch is a search engine, which also implements full-text search.
The main entity in terms of our product is “job” (job). Work is an abstract entity that binds together all the information related to a particular patient's reception. This information includes:
- data about the doctor;
- patient information;
- information about the visit;
- audio file (doctor's speech);
- documents (several versions);
- work processing history;
- information about the department, etc.
This diagram shows a simplified database schema, from which you can see the relationships between the main tables. This is only the base part, in fact in the database of more than 200 tables.
A little about the clinic where the incident happened:
- 1500-2000 works per day;
- 1000+ active users (doctors + secretaries);
- Self-hosted.
DB:
- Size: 800+ Gb (750K + works, 2M + documents);
- DBMS: MS SQL Server 2008 R2;
- Recovery Model: Simple.
Here I want to make a little explanation. There are 3 recovery models in SQL Server: simple, bulk-logged, and full. I will not speak about the third now, I will explain about the first and second. The main difference is that in the simple model, we do not keep a transaction history in the log — once the transaction has been committed, the record from the transaction log will be deleted. When using the full recovery mode, the entire history of data changes is stored in the transaction log. What does this give us? In case of some unforeseen situation, when we need to roll back the database from the backup, we can return not only to some specific backup, but we can return to any point in time, up to a certain transaction, i.e. In backups, not only is a certain state of the database at the time of backup, but also the whole is a history of data changes.
I think it’s not worth explaining that the simple mode is used only in development, on test servers and its use in production is unacceptable. Not at all.
But the clinic, apparently, had its own thoughts on this subject;)
Start
A few days later, the New Year, everyone is preparing for the holiday, buying presents, decorating Christmas trees, holding corporate parties and are waiting for a long weekend.
December 22 (Friday) 1 day
14:31 The client said that he had not received another daily report. The report arrives at the mail twice a day on a schedule; it is needed to control the sending of data to an external integration system, which is not too critical.
There could be several reasons:
- Problems with SMTP, letters simply were not delivered (changed the password, for example, and did not tell anyone);
- Problems on the server side of the report;
- Something is wrong with the database.
16:03 The clinic sometimes changes the password to SMTP, without warning anyone about it, so after finishing the current tasks, we calmly check the report manually by launching through the web interface — we get an error that indicates problems in the database.
An example of an error that we received when running the report.
SQL Server detected a logical consistency-based I/O error: incorrect checksum (expected: 0x9876641f; actual: 0xa3255fbf). It occurred during a read of page (1:876) in database ID 7 at offset 0x000000006d8000 in file 'D:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\ServerLive.mdf'. This indicates that there are damaged pages in the database. We had a slight feeling of anxiety.
20:53 In order to assess the extent of damage, we launch the database check using the special command DBCC CHECKDB . Depending on the size of the damage, the verification team can take quite a long time, so we launch the command in the night. Here we are lucky that this happened on Friday afternoon, that is, we had at least the whole weekend to solve this problem.
At that moment the situation was as follows:
December 23 (Saturday) 2nd day
10:02 In the morning, we find out that checking the database using CHECKDB has stopped - this was due to the lack of free disk space, since the tempdb temporary database is actively used in the verification process, and at some point the free disk space just ran out.
Therefore, instead of checking the entire database, we decide to immediately launch a public check. To do this, use the DBCC CHECKTABLE command .
10:46 We decide to start with the JobHistory table, which is probably damaged, because it was used to generate the report. This table, as can be understood from the title, keeps the history of all works, i.e., transitions of work between stages.
Run DBCC CHECKTABLE ('dbo.JobHistory') .
Checking this table reveals damaged tables in the database, which in principle was expected.
12:00 At the moment, if the database used the full recovery model, we could restore the damaged pages from the backup, and that would be the end of it, but our database was in simple mode. Therefore, the only option for repairing damage is to launch the same command with the special parameter REPAIR_ALLOW_DATA_LOSS . In this case, data loss is possible.
We start. The check again fails - we get an error that the recovery of this table is impossible until the linked tables are restored. The history table refers to the work table (Jobs) by the foreign key, therefore, we conclude that there is also damage in the main work table (Jobs).
13:30 The next step is to check the Jobs table, while hoping that the damage is in the index, not in the data. In this case, it will be enough for us to simply rebuild the index for data recovery.
17:33 After a while, we discover that our server is unavailable via RDP. It was probably turned off, the check was not completed, the work was suspended. We inform the clinic that the server is unavailable, please raise it.
Light anxiety takes very specific forms.
December 24 (Sunday) 3rd day
14:31 Closer to the dinner server is raised, re-start checking the Jobs table.
DBCC CHECKTABLE ('dbo.Jobs')
16:05 Verification is not complete, the server is unavailable. Again.
After some time, the server is again unavailable, before we could complete the check of the table. At this moment, the IT clinic service performs a series of server checks. We are waiting for the completion of work.
Due to holidays, communication between us and the client was slow - we were waiting for answers to questions for several hours.
December 25 (Monday - Christmas) 4th day
16:00 The next day, the server was raised, the client has Christmas, and we again start checking the table, but this time we exclude the indexes from the check, and leave only the data check. And after a while the server is again unavailable.
What is going on?
At this moment, thoughts begin to creep in that this is not just a coincidence, and there is a suspicion that it could be damage at the level of iron (a hard disk fell down). We assume that there are bad sectors on the disk and when the check tries to read data from these sectors, the system crashes. We inform on the assumption to the client.
The client runs a disk check on the host machine.
17:19 IT clinic service reported that the virtual machine file is damaged - this is bad! (
We still can not work, and wait for the signal when they fix the problem and we can continue our work.
December 26 (Tuesday) 5th day
14:05 IT clinic service starts another disk recovery process. We were told that we can run CHECKTABLE in parallel to check the table. We start the scan again - the virtual is crashing again, we inform the client that the virtual machine file is still damaged.
These days all communications with the customer are very slow with a huge time lag due to holidays.
December 27 (Wednesday) 6th day
14:00 Run the disk check using Windows tools - checkdisk inside the virtual machine - no problems identified.
The database is in the Simple mode, so the chances of correcting the current database by means of the DBMS tend to zero, since we are unable to repair individual damaged pages.
We begin to consider the option of rolling back and restoring the database from backup.
We check the backups of the database and find out that backups were not made using DBMS tools, the last backup was in 2014, i.e. There are no backups. Why not done - a separate question, it is the responsibility of the clinic to ensure the health and safety of the database.
There is a high probability that it will not be possible to restore the current database, we begin to consider other options for rollback.
Let's take a closer look at the situation with backups in the clinic.
Backup situation:
- There is no backup database (!!!)
- There is no snapshot of a virtual machine either (!?)
- But there are disk backups (full + inc)
The database is on disk D, respectively, they made weekly full backups and daily incremental backups.
- every Friday at 20:00 full backup
- every day incremental backup
- there is a full backup from the 15th and 22nd
- there are daily backups up to the 21st
Those. in principle, we can roll back to the state before the problem occurs.
We are waiting for the update from the clinic to start rolling back the database from the backup.
At the same time, the clinic sent a request to an iron supplier (HP) marked “urgent”.
December 28 (Thursday) 7th day
13:13 The IT service of the clinic begins setting up a new virtual machine, since Fix the damage in the file of the old virtual machine does not work.
19:09 A new virtual machine is available with SQL Server installed.
The next step is to restore the database from the disk backup. To begin with, we decide to roll back to the 22nd, if the problem is still present, then we roll back to the 21st, 20th, and so on, until we reach a working state.
It was the 28th in the courtyard, we are at a corporate party, and here we are informed that the clinic has problems with restoring the backup, because the backups are EMPTY!
Here is the news!
During the recovery of the backup of disk D from the 21st, it turns out that it is empty, like all the others. Directly backups Schrödinger obtained - they seem to be as it is, but at the same time, they are not. It is not completely clear how this happened at all, but, as far as we were able to understand, the problem is not enough space on the disk to store disk backups. They allocated 500 Gb backups for storage, but at the time of the incident the database already weighed 800 Gb, therefore, in principle, the backup could not be passed successfully. Those. backups were regularly done on a schedule, but due to lack of space, they ended up with an error and were therefore empty, and the IT-service of the clinic did not even bother to check that everything was fine with them. Do not do it this way.
December 29 (Friday) 8th day
13:11 Discussion of further action. Possible options:
- Trying to copy the database files (.ldf + .two files) - the chances of success are very low;
- Trying to make a backup database - again, the chances are very small;
- Set up replication - may work.
On the new server, 1 Tb disk was allocated, which is obviously not enough if we try to backup and restore from it, because in the worst case, without compression, the backup will take up as much space as the original database, i.e. 800 Gb.
Please add space on the new server and proceed to copying the database files.
A database has been created on the new server and the database schema has been restored - this will allow at least to process new jobs. The clinic will at least be able to accept new patients using this system.
14:36 Therefore, we proceed to option number one, although we don’t expect much success.
Stop the SQL Server, start copying the data file (mdf) and log (ldf).
16:13 After one and a half, the log file was copied successfully (48 Gb), and 50 GB of data file were already copied (795 of 846 GB left). At this speed, it will take about 12 hours to complete the copy.
16:30 Old database server turned off while copying a file, which is quite expected.
17:09 Therefore, we move on to the next option — setting up replication; in this case, we can specify which data will be replicated, that is, we can first exclude obviously damaged tables and copy the intact data first, and then transfer the problem tables in parts. But this option, unfortunately, also does not work, since we cannot even create a publication with certain tables due to database damage.
Consider more options for transferring data.
20:01 In the end, we start simply to transfer data from the old to the new server in a regular manner by importing and exporting in order of priority.
21:35 First, the most critical data, then archived and less critical data (~ 300 GB). In the first wave of exports, less than 300 GB of data remained. Table Documents is also excluded (300GB). Run the copy process in the night.
December 30 (Saturday) 9th day
15:00 We continue to transfer data. Jobs table is not available at all. The main part of the tables was copied by this time.
But without Jobs, it's all useless, because it is the main link between all the data and gives them meaning and value from a business point of view. Without it, we simply have a fragmented set of data that we can’t use.
Also at this point the restoration of the database schema is complete.
Consequences of the incident:
By this moment we have a huge loss of live data.
Those. Formally, we have some data in the database, but, in fact, there is no way to use them or link them together, so we can talk about complete data loss.
More than 750,000 patient admissions have been lost.
This is really sad!
- This is a huge blow to the reputation of our client, which can turn into big business problems for them when entering into new contracts and finding new customers.
- The loss of such amount of data for the clinic can face serious problems and fines, because this is confidential data containing medical confidentiality and, in a direct sense, people's lives depend on it.
We began to think what we can do in this situation. Began to sort through the system to find clues.
15:16 Analyzing all aspects of the system, we understand that we can try to extract the missing data from the ElasticSearch index. The fact of the matter is that due to the incorrect configuration of the ElasticSearch indexes, it stores not only the fields by which full-text search is performed, but everything, that is, in fact, there is a complete copy of the data and we can theoretically extract data from there about jobs and put them back into our database. It is hoped that the data will still be restored.
A bug that you can put a monument!
18:00 The utility for data extraction was quickly written and after a few hours we are convinced that the approach works and the data will be restored.
20:00 Started restoring works from ElasticSearch with the help of a written utility. The approach worked, data about the work can be restored. In parallel, we begin to extract the latest versions of the document for each work.
December 31 (Sunday - New Year) 10th day
14:09 During the night, 188,811 works were restored.
20:13 Seeing our success, the clinic decides to postpone the transfer of the server to the HP service in order to give us time to extract the maximum data from the old server.
With such news, we met the New Year))
January 01 (Monday) 11th day
11:23 Preparation for launching the system after the incident:
- reconfigured IIS on the App server;
- migrated all the necessary services to work with the new database server;
- restored triggers, stored procedures, functions.
14:28 Then they began to copy a table of documents, which was skipped during the initial transfer due to its large size.
- The old DB server has shut down again. It is obvious that the Documents table is also damaged; it is with it that all information on patients is stored. Fortunately, it is not completely damaged, we can make requests to it, and when a request to us returns a damaged record, at this moment the server crashes and turns off. Part of the data in this case we can extract.
Accordingly, we signal the client, they raise the server, and in parallel we continue to prepare the new database for the launch of the system.
18:01 Restoring all integrity constraints after transferring the main part of the data.
22:02 Restoring constraints completed. We just carried the raw data to the maximum. The presence of integrity constraints would greatly complicate our task.
January 02 (Tuesday) 12th day
05:52 Old DB server turned off again while copying the document. He is promptly picked up so that we can continue to work.
09:00 Batch managed to recover about 200.000 documents (approximately 20%)
We started using different recovery methods: sorting by different columns to retrieve data from the end or beginning of the table, until we hit some damaged part of the table.
13:42 Started copying archival works in the table - it is, fortunately, not damaged.
17:08 Restored all archival work (491,380 pieces).
The system is ready to launch: users can create and process new jobs.
Unfortunately, due to partial damage to the table of documents, you can not just transfer all the data from it, as with other tables, because The table is partially damaged. Therefore, when you try to retrieve all the data, the request falls with an error when you try to read damaged pages. Therefore, we extract the data point-wise, using different sorts and sample size:
- Sort by different fields (ID, DateTime);
- Sort ascending, descending;
- Work with small groups of lines (1000, 100);
- Retrieving jobs by id.
January 03 (Wednesday) 13th day
08:58 Continued the process of recovering documents. Documents were restored only for active, unfinished work. By this time 1000 works (active) without documents.
11:38 Moved all SQL Jobs
13:17 5 works without documents, 231 work is missing, but there is an audio file, you need to resynchronize.
January 4 (Thursday) 14th day
Started manual restoration and verification of remaining work.
The system works, monitoring and correction of errors in online mode.
January 05 (Friday) 15th day
Reports are scheduled for migration to SSRS.
Transfer to the new server is impossible, because In the clinic, an older version of SQL Server was installed and the database could not be moved from the old server.
Options:
- Upgrade SQL Server from 2008 to 2008 R2;
- Customize everything from scratch.
It was decided to wait for the update of SQL Server.
09:21 Background restoration of documents for completed works started - the process is long and will take several days.
13:28 Change the priority of the recovery of documents by department.
18:18 Clinic gave access to SMTP, mail setup
Result:
- Almost all data was recovered (only 5 works were lost);
- Recommendations on database maintenance were issued to prevent such situations;
- Configured database backups using SQL Server;
- Additional monitoring for back-ups from our side, alerts in case of file.
Source: https://habr.com/ru/post/432998/
All Articles