High Availability and Scalable Elasticsearch at Kubernetes

In the previous post, we scaled the MongoDB replica set and met StatefulSet. We will now orchestrate Elasticsearch high-availability cluster (with other master nodes, data nodes, and client nodes) and use ES-HQ and Kibana.
You will need:
- Basic idea of Elasticsearch, its node types and their roles.
- A working Kubernetes cluster with at least three nodes (at least four cores, 4 GB).
- Ability to work with Kibana.
Deployment architecture
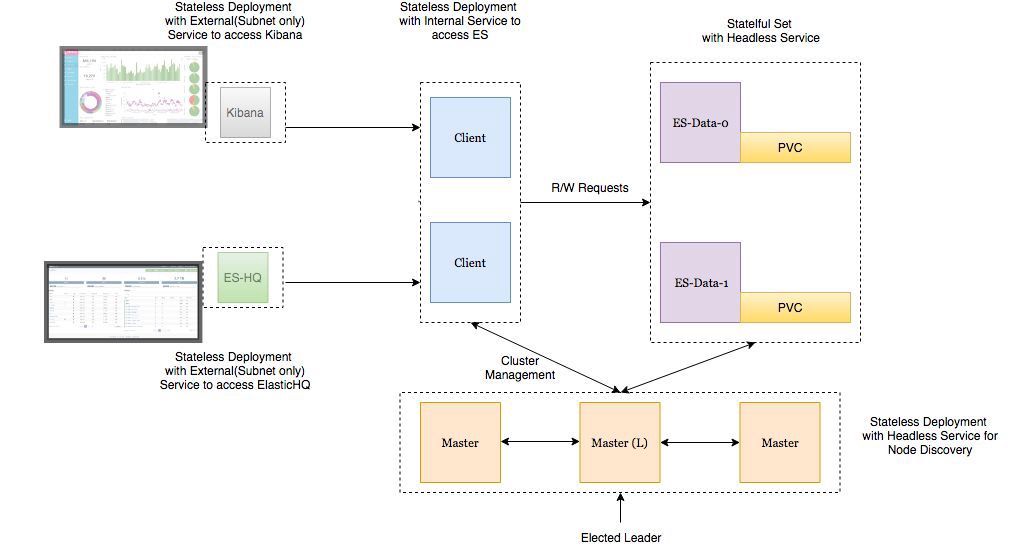
- Subs on the Elasticsearch data nodes are deployed as a StatefulSet with a headless service so that we have stable network identifiers .
- Elasticsearch masters are deployed as ReplicaSet with a headless service. This is for autodiscovery .
- Subs on the Elasticsearch client nodes are deployed as ReplicaSet with an internal service so that you can send read / write requests to the data nodes.
- Pods Kibana and ElasticHQ are deployed as ReplicaSet with services that are available outside the Kubernetes cluster , but are still inside the subnet (do not open outwards unnecessarily).
- HPA (Horizonal Pod Autoscaler) is deployed for client nodes and is responsible for horizontal autoscaling under high load.
"Do not forget to configure for the environment:- The variable ES_JAVA_OPTS .
- The variable CLUSTER_NAME .
- The variable NUMBER_OF_MASTERS for deployment of masters to avoid the split-brain situation. If we have 3 masters, we specify 2.
- The rules of anti-affinity for similar podov to guarantee high reliability if the working note falls off.
"
Let's deploy these services in a GKE cluster.
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-master namespace: elasticsearch labels: component: elasticsearch role: master spec: replicas: 3 template: metadata: labels: component: elasticsearch role: master spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: role operator: In values: - master topologyKey: kubernetes.io/hostname initContainers: - name: init-sysctl image: busybox:1.27.2 command: - sysctl - -w - vm.max_map_count=262144 securityContext: privileged: true containers: - name: es-master image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4 env: - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: NODE_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: CLUSTER_NAME value: my-es - name: NUMBER_OF_MASTERS value: "2" - name: NODE_MASTER value: "true" - name: NODE_INGEST value: "false" - name: NODE_DATA value: "false" - name: HTTP_ENABLE value: "false" - name: ES_JAVA_OPTS value: -Xms256m -Xmx256m - name: PROCESSORS valueFrom: resourceFieldRef: resource: limits.cpu resources: limits: cpu: 2 ports: - containerPort: 9300 name: transport volumeMounts: - name: storage mountPath: /data volumes: - emptyDir: medium: "" name: "storage" --- apiVersion: v1 kind: Service metadata: name: elasticsearch-discovery namespace: elasticsearch labels: component: elasticsearch role: master spec: selector: component: elasticsearch role: master ports: - name: transport port: 9300 protocol: TCP clusterIP: None view rawes-master.yml hosted with love by GitHub (Depla and headless service for master nodes)
root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-master 3 3 3 3 32s NAME DESIRED CURRENT READY AGE rs/es-master-594b58b86c 3 3 3 31s NAME READY STATUS RESTARTS AGE po/es-master-594b58b86c-9jkj2 1/1 Running 0 31s po/es-master-594b58b86c-bj7g7 1/1 Running 0 31s po/es-master-594b58b86c-lfpps 1/1 Running 0 31s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 31s It is interesting to study the logs of the hearths on the master nodes and see how the master is selected among them now and how it will be later when we add new data nodes and client nodes.
root$ kubectl -n elasticsearch logs -f po/es-master-594b58b86c-9jkj2 | grep ClusterApplierService [2018-10-21T07:41:54,958][INFO ][oecsClusterApplierService] [es-master-594b58b86c-9jkj2] detected_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},{es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3]]) Here you can see that under es-master with the name es-master-594b58b86c-bj7g7 selected by the master, and the other two hearths are added to it and to each other.
The headless elasticsearch-discovery service is installed by default in the Docker image as an environment variable and is used for detection in the nodes. This setting can be replaced if desired.
Similarly, we deploy data nodes and client nodes . Configurations see below.
Deploy data node:
kind: Namespace metadata: name: elasticsearch --- apiVersion: storage.k8s.io/v1beta1 kind: StorageClass metadata: name: fast provisioner: kubernetes.io/gce-pd parameters: type: pd-ssd fsType: xfs allowVolumeExpansion: true --- apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: es-data namespace: elasticsearch labels: component: elasticsearch role: data spec: serviceName: elasticsearch-data replicas: 3 template: metadata: labels: component: elasticsearch role: data spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: role operator: In values: - data topologyKey: kubernetes.io/hostname initContainers: - name: init-sysctl image: busybox:1.27.2 command: - sysctl - -w - vm.max_map_count=262144 securityContext: privileged: true containers: - name: es-data image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4 env: - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: NODE_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: CLUSTER_NAME value: my-es - name: NODE_MASTER value: "false" - name: NODE_INGEST value: "false" - name: HTTP_ENABLE value: "false" - name: ES_JAVA_OPTS value: -Xms256m -Xmx256m - name: PROCESSORS valueFrom: resourceFieldRef: resource: limits.cpu resources: limits: cpu: 2 ports: - containerPort: 9300 name: transport volumeMounts: - name: storage mountPath: /data volumeClaimTemplates: - metadata: name: storage annotations: volume.beta.kubernetes.io/storage-class: "fast" spec: accessModes: [ "ReadWriteOnce" ] storageClassName: fast resources: requests: storage: 10Gi --- apiVersion: v1 kind: Service metadata: name: elasticsearch-data namespace: elasticsearch labels: component: elasticsearch role: data spec: ports: - port: 9300 name: transport clusterIP: None selector: component: elasticsearch role: data view rawes-data.yml hosted with love by GitHub (StatefulSet and headless data node service)
The headless service on the data nodes provides the nodes with stable network identifiers and helps to transfer data between the nodes.
It is important to format the permanent volume before tying it to the hearth. Just specify the volume type when creating the storage class. You can also set a parameter to allow automatic volume expansion . Read more here .
parameters: type: pd-ssd fsType: xfs allowVolumeExpansion: true ... Deploy client nodes:
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-client namespace: elasticsearch labels: component: elasticsearch role: client spec: replicas: 2 template: metadata: labels: component: elasticsearch role: client spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: role operator: In values: - client topologyKey: kubernetes.io/hostname initContainers: - name: init-sysctl image: busybox:1.27.2 command: - sysctl - -w - vm.max_map_count=262144 securityContext: privileged: true containers: - name: es-client image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4 env: - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: NODE_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: CLUSTER_NAME value: my-es - name: NODE_MASTER value: "false" - name: NODE_DATA value: "false" - name: HTTP_ENABLE value: "true" - name: ES_JAVA_OPTS value: -Xms256m -Xmx256m - name: NETWORK_HOST value: _site_,_lo_ - name: PROCESSORS valueFrom: resourceFieldRef: resource: limits.cpu resources: limits: cpu: 1 ports: - containerPort: 9200 name: http - containerPort: 9300 name: transport volumeMounts: - name: storage mountPath: /data volumes: - emptyDir: medium: "" name: storage --- apiVersion: v1 kind: Service metadata: name: elasticsearch namespace: elasticsearch annotations: cloud.google.com/load-balancer-type: Internal labels: component: elasticsearch role: client spec: selector: component: elasticsearch role: client ports: - name: http port: 9200 type: LoadBalancer view rawes-client.yml hosted with love by GitHub (Deploy and external service for client nodes)
The service deployed here allows access to the ES cluster outside the Kubernetes cluster, but it is still inside the subnet. The annotation cloud.google.com/load-balancer-type: Internal is responsible for this.
But if the application that accesses the ES cluster for reading and writing is deployed inside the cluster, then access to the ElasticSearch service can be obtained at http: //elasticsearch.elasticsearch: 9200 .
When you deploy data nodes and client nodes, they will be added to the cluster automatically. (Look for the master in the logs)
root$ kubectl -n elasticsearch get pods -l role=data NAME READY STATUS RESTARTS AGE es-data-0 1/1 Running 0 48s es-data-1 1/1 Running 0 28s -------------------------------------------------------------------- root$ kubectl apply -f es-client.yml root$ kubectl -n elasticsearch get pods -l role=client NAME READY STATUS RESTARTS AGE es-client-69b84b46d8-kr7j4 1/1 Running 0 47s es-client-69b84b46d8-v5pj2 1/1 Running 0 47s -------------------------------------------------------------------- root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-client 2 2 2 2 1m deploy/es-master 3 3 3 3 9m NAME DESIRED CURRENT READY AGE rs/es-client-69b84b46d8 2 2 2 1m rs/es-master-594b58b86c 3 3 3 9m NAME DESIRED CURRENT AGE statefulsets/es-data 2 2 3m NAME READY STATUS RESTARTS AGE po/es-client-69b84b46d8-kr7j4 1/1 Running 0 1m po/es-client-69b84b46d8-v5pj2 1/1 Running 0 1m po/es-data-0 1/1 Running 0 3m po/es-data-1 1/1 Running 0 3m po/es-master-594b58b86c-9jkj2 1/1 Running 0 9m po/es-master-594b58b86c-bj7g7 1/1 Running 0 9m po/es-master-594b58b86c-lfpps 1/1 Running 0 9m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch LoadBalancer 10.9.121.160 10.9.120.8 9200:32310/TCP 1m svc/elasticsearch-data ClusterIP None <none> 9300/TCP 3m svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 9m -------------------------------------------------------------------- #Check logs of es-master leader pod root$ kubectl -n elasticsearch logs po/es-master-594b58b86c-bj7g7 | grep ClusterApplierService [2018-10-21T07:41:53,731][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] new_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300}]]]) [2018-10-21T07:41:55,162][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3] source [zen-disco-node-join[{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300}]]]) [2018-10-21T07:48:02,485][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [4] source [zen-disco-node-join[{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300}]]]) [2018-10-21T07:48:21,984][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [5] source [zen-disco-node-join[{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300}]]]) [2018-10-21T07:50:51,245][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [6] source [zen-disco-node-join[{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300}]]]) [2018-10-21T07:50:58,964][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [7] source [zen-disco-node-join[{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300}]]])] [es-master-594b58b86c-bj7g7] added {{es-data-root$ kubectl -n elasticsearch get pods -l role=data NAME READY STATUS RESTARTS AGE es-data-0 1/1 Running 0 48s es-data-1 1/1 Running 0 28s -------------------------------------------------------------------- root$ kubectl apply -f es-client.yml root$ kubectl -n elasticsearch get pods -l role=client NAME READY STATUS RESTARTS AGE es-client-69b84b46d8-kr7j4 1/1 Running 0 47s es-client-69b84b46d8-v5pj2 1/1 Running 0 47s -------------------------------------------------------------------- root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-client 2 2 2 2 1m deploy/es-master 3 3 3 3 9m NAME DESIRED CURRENT READY AGE rs/es-client-69b84b46d8 2 2 2 1m rs/es-master-594b58b86c 3 3 3 9m NAME DESIRED CURRENT AGE statefulsets/es-data 2 2 3m NAME READY STATUS RESTARTS AGE po/es-client-69b84b46d8-kr7j4 1/1 Running 0 1m po/es-client-69b84b46d8-v5pj2 1/1 Running 0 1m po/es-data-0 1/1 Running 0 3m po/es-data-1 1/1 Running 0 3m po/es-master-594b58b86c-9jkj2 1/1 Running 0 9m po/es-master-594b58b86c-bj7g7 1/1 Running 0 9m po/es-master-594b58b86c-lfpps 1/1 Running 0 9m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch LoadBalancer 10.9.121.160 10.9.120.8 9200:32310/TCP 1m svc/elasticsearch-data ClusterIP None <none> 9300/TCP 3m svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 9m -------------------------------------------------------------------- #Check logs of es-master leader pod root$ kubectl -n elasticsearch logs po/es-master-594b58b86c-bj7g7 | grep ClusterApplierService [2018-10-21T07:41:53,731][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] new_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300}]]]) [2018-10-21T07:41:55,162][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3] source [zen-disco-node-join[{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300}]]]) [2018-10-21T07:48:02,485][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [4] source [zen-disco-node-join[{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300}]]]) [2018-10-21T07:48:21,984][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [5] source [zen-disco-node-join[{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300}]]]) [2018-10-21T07:50:51,245][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [6] source [zen-disco-node-join[{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300}]]]) [2018-10-21T07:50:58,964][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [7] source [zen-disco-node-join[{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300}]]])10.9.125.82} {10.9.125.82root$ kubectl -n elasticsearch get pods -l role=data NAME READY STATUS RESTARTS AGE es-data-0 1/1 Running 0 48s es-data-1 1/1 Running 0 28s -------------------------------------------------------------------- root$ kubectl apply -f es-client.yml root$ kubectl -n elasticsearch get pods -l role=client NAME READY STATUS RESTARTS AGE es-client-69b84b46d8-kr7j4 1/1 Running 0 47s es-client-69b84b46d8-v5pj2 1/1 Running 0 47s -------------------------------------------------------------------- root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-client 2 2 2 2 1m deploy/es-master 3 3 3 3 9m NAME DESIRED CURRENT READY AGE rs/es-client-69b84b46d8 2 2 2 1m rs/es-master-594b58b86c 3 3 3 9m NAME DESIRED CURRENT AGE statefulsets/es-data 2 2 3m NAME READY STATUS RESTARTS AGE po/es-client-69b84b46d8-kr7j4 1/1 Running 0 1m po/es-client-69b84b46d8-v5pj2 1/1 Running 0 1m po/es-data-0 1/1 Running 0 3m po/es-data-1 1/1 Running 0 3m po/es-master-594b58b86c-9jkj2 1/1 Running 0 9m po/es-master-594b58b86c-bj7g7 1/1 Running 0 9m po/es-master-594b58b86c-lfpps 1/1 Running 0 9m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch LoadBalancer 10.9.121.160 10.9.120.8 9200:32310/TCP 1m svc/elasticsearch-data ClusterIP None <none> 9300/TCP 3m svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 9m -------------------------------------------------------------------- #Check logs of es-master leader pod root$ kubectl -n elasticsearch logs po/es-master-594b58b86c-bj7g7 | grep ClusterApplierService [2018-10-21T07:41:53,731][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] new_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300}]]]) [2018-10-21T07:41:55,162][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3] source [zen-disco-node-join[{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300}]]]) [2018-10-21T07:48:02,485][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [4] source [zen-disco-node-join[{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300}]]]) [2018-10-21T07:48:21,984][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [5] source [zen-disco-node-join[{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300}]]]) [2018-10-21T07:50:51,245][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [6] source [zen-disco-node-join[{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300}]]]) [2018-10-21T07:50:58,964][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [7] source [zen-disco-node-join[{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300}]]])
In the logs of the main master pod, you can clearly see when each node is added to the cluster. This is useful to know when debugging.
We have deployed all the components, and now we need to check:
1) Depla Elasticsearch from the Kubernetes cluster using the Ubuntu container.
root$ kubectl run my-shell --rm -i --tty --image ubuntu -- bash root@my-shell-68974bb7f7-pj9x6:/# curl http://elasticsearch.elasticsearch:9200/_cluster/health?pretty { "cluster_name" : "my-es", "status" : "green", "timed_out" : false, "number_of_nodes" : 7, "number_of_data_nodes" : 2, "active_primary_shards" : 0, "active_shards" : 0, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 } 2) Deploy Elasticsearch outside the cluster over the IP of the internal balancer GCP (in our case - 10.9.120.8 ).
root$ curl http://10.9.120.8:9200/_cluster/health?pretty { "cluster_name" : "my-es", "status" : "green", "timed_out" : false, "number_of_nodes" : 7, "number_of_data_nodes" : 2, "active_primary_shards" : 0, "active_shards" : 0, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 } 3) Anti-affinity rules for ES pods.
root$ kubectl -n elasticsearch get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE es-client-69b84b46d8-kr7j4 1/1 Running 0 10m 10.8.14.52 gke-cluster1-pool1-d2ef2b34-t6h9 es-client-69b84b46d8-v5pj2 1/1 Running 0 10m 10.8.15.53 gke-cluster1-pool1-42b4fbc4-cncn es-data-0 1/1 Running 0 12m 10.8.16.58 gke-cluster1-pool1-4cfd808c-kpx1 es-data-1 1/1 Running 0 12m 10.8.15.52 gke-cluster1-pool1-42b4fbc4-cncn es-master-594b58b86c-9jkj2 1/1 Running 0 18m 10.8.15.51 gke-cluster1-pool1-42b4fbc4-cncn es-master-594b58b86c-bj7g7 1/1 Running 0 18m 10.8.16.57 gke-cluster1-pool1-4cfd808c-kpx1 es-master-594b58b86c-lfpps 1/1 Running 0 18m 10.8.14.51 gke-cluster1-pool1-d2ef2b34-t6h9 Notice - we do not have two similar pods on one node, so we ensured high reliability in case of node failure.
Scaling
We can deploy autoscaling services for client nodes depending on the CPU limit. HPA example for client node:
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: es-client namespace: elasticsearch spec: maxReplicas: 5 minReplicas: 2 scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: es-client targetCPUUtilizationPercentage: 80 Autoscaling adds pods on the client node to the cluster, and this can be seen in the logs of any pod on the master node.
As for podov on data nodes , you just need to increase the number of replicas on the Kubernetes control panel or in the GKE console. The created data node itself will be added to the cluster and will begin to replicate data from other nodes.
I will not need autoscaling on master nodes - they only store data on the cluster status. But if you are going to add data nodes, make sure that the number of master nodes in the cluster is odd , and do not forget to change the environment variable NUMBER_OF_MASTERS .
Deploy Kibana and ES-HQ
Kibana is a simple tool for visualizing ES data, and ES-HQ helps you administer and monitor the Elasticsearch cluster. With Kibana and ES-HQ Deploy, remember that:
- We pass the ES cluster name to the Docker image as an environment variable.
- The service for accessing the Kibana / ES-HQ deployment remains within the company, that is, a public IP is not created. We use the internal GCP load balancer.
Deploy Kibana
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-kibana namespace: elasticsearch labels: component: elasticsearch role: kibana spec: replicas: 1 template: metadata: labels: component: elasticsearch role: kibana spec: containers: - name: es-kibana image: docker.elastic.co/kibana/kibana-oss:6.2.2 env: - name: CLUSTER_NAME value: my-es - name: ELASTICSEARCH_URL value: http://elasticsearch:9200 resources: limits: cpu: 0.5 ports: - containerPort: 5601 name: http --- apiVersion: v1 kind: Service metadata: name: kibana annotations: cloud.google.com/load-balancer-type: "Internal" namespace: elasticsearch labels: component: elasticsearch role: kibana spec: selector: component: elasticsearch role: kibana ports: - name: http port: 80 targetPort: 5601 protocol: TCP type: LoadBalancer view rawes-kibana.yml hosted with love by GitHub (Deploy and Kibana service)
Deploy ES-HQ
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-hq namespace: elasticsearch labels: component: elasticsearch role: hq spec: replicas: 1 template: metadata: labels: component: elasticsearch role: hq spec: containers: - name: es-hq image: elastichq/elasticsearch-hq:release-v3.4.0 env: - name: HQ_DEFAULT_URL value: http://elasticsearch:9200 resources: limits: cpu: 0.5 ports: - containerPort: 5000 name: http --- apiVersion: v1 kind: Service metadata: name: hq annotations: cloud.google.com/load-balancer-type: "Internal" namespace: elasticsearch labels: component: elasticsearch role: hq spec: selector: component: elasticsearch role: hq ports: - name: http port: 80 targetPort: 5000 protocol: TCP type: LoadBalancer view rawes-hq.yml hosted with love by GitHub (Deploy and ES-HQ service)
We access both services through the newly created internal balancer.
root$ kubectl -n elasticsearch get svc -l role=kibana NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kibana LoadBalancer 10.9.121.246 10.9.120.10 80:31400/TCP 1m root$ kubectl -n elasticsearch get svc -l role=hq NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE hq LoadBalancer 10.9.121.150 10.9.120.9 80:31499/TCP 1m http: // <External-Ip-Kibana-Service> / app / kibana # / home? _g = ()
(Kibana control panel)
http: // <External-Ip-ES-Hq-Service> / #! / clusters / my-es
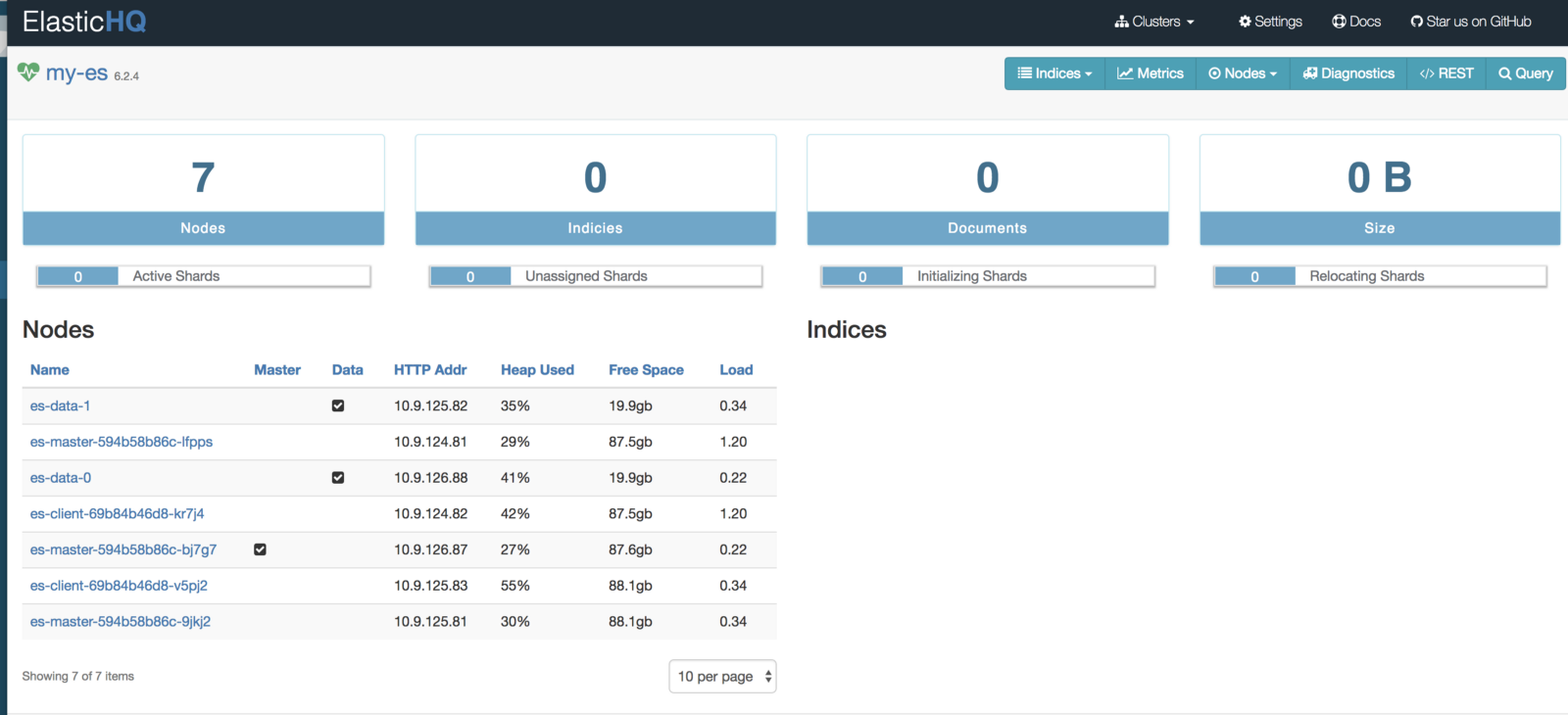
(ElasticHQ control panel for monitoring and managing the cluster)
ES is one of the most popular distributed search and analysis systems, and in Kubernetes it solves the key problems of mashshtabirovaniya and high availability. In addition, new ES clusters in Kubernetes are deployed instantly.
')
Source: https://habr.com/ru/post/432374/
All Articles