Apache NiFi: what it is and a brief overview of the features
Today, on thematic foreign sites about Big Data, one can find the mention of such a relatively new tool for the Hadoop ecosystem as Apache NiFi. This is a modern open source ETL tool. Distributed architecture for fast parallel loading and processing of data, a large number of plug-ins for sources and transformations, versioning of configurations is only part of its advantages. For all its power, NiFi remains fairly simple to use.
At Rostelecom, we are striving to develop work with Hadoop, so we have already tried and appreciated the advantages of Apache NiFi compared to other solutions. In this article I will tell you what attracted us to this tool and how we use it.
Not so long ago, we were faced with the choice of a solution for loading data from external sources into the Hadoop cluster. A long time to solve such problems, we used Apache Flume . To Flume as a whole, there were no complaints, except for a few moments that did not suit us.
')
The first thing that we, as administrators, did not like was that the writing of the Flume config to perform the next trivial download could not be trusted to a developer or analyst who was not immersed in the subtleties of this tool. Connecting each new source required mandatory intervention from the team of administrators.
The second point was fault tolerance and scaling. For heavy downloads, for example, via syslog, it was necessary to configure several Flume agents and set up a balancer in front of them. All this then needed to be somehow monitored and restored in the event of a failure.
Thirdly , Flume did not allow downloading data from various DBMSs and working with some other protocols out of the box. Of course, in the open spaces of the network, it was possible to find ways to make Flume work with Oracle or SFTP, but the support of such “bikes” is not at all pleasant. To download data from the same Oracle, we had to use one more tool - Apache Sqoop .
Frankly, I am a lazy man by nature, and I didn’t want to support the zoo of decisions at all. And I didn’t like that I had to do all this work myself.
There are, of course, quite powerful solutions on the market for ETL tools that can work with Hadoop. These include Informatica, IBM Datastage, SAS and Pentaho Data Integration. These are the ones that can most often be heard from colleagues and those that come to mind first. By the way, we use IBM DataStage for ETL on solutions of the Data Warehouse class. But historically, our team had no opportunity to use DataStage for downloads to Hadoop. Again, we did not need all the power of solutions of this level to perform fairly simple transformations and data downloads. What we needed was a solution with good development dynamics, able to work with a variety of protocols and possessing a convenient and understandable interface that not only the administrator can understand, but also the developer with the analyst, who are often for us customers of the data itself.
As you can see from the title, we solved the problems listed with Apache NiFi.
The name NiFi comes from "Niagara Files". The project was developed for eight years by the US National Security Agency, and in November 2014 its source code was opened and transferred to the Apache Software Foundation as part of the NSA Technology Transfer Program .
NiFi is an open source ETL / ELT tool that can work with many systems, and not just the Big Data class and the Data Warehouse. Here are some of them: HDFS, Hive, HBase, Solr, Cassandra, MongoDB, ElastcSearch, Kafka, RabbitMQ, Syslog, HTTPS, SFTP. You can view the full list in the official documentation .
Work with a specific DBMS is implemented by adding the appropriate JDBC driver. There is an API for writing your module as an additional receiver or data converter. Examples can be found here and here .
NiFi uses a web interface to create a dataflow. The analyst, who recently started working with Hadoop, the developer, and the bearded admin will cope with it. The latter two can interact not only with “rectangles and arrows”, but also with the REST API for collecting statistics, monitoring and managing DataFlow components.
NiFi control web interface
Below, I will show a few DataFlow examples for performing some common operations.
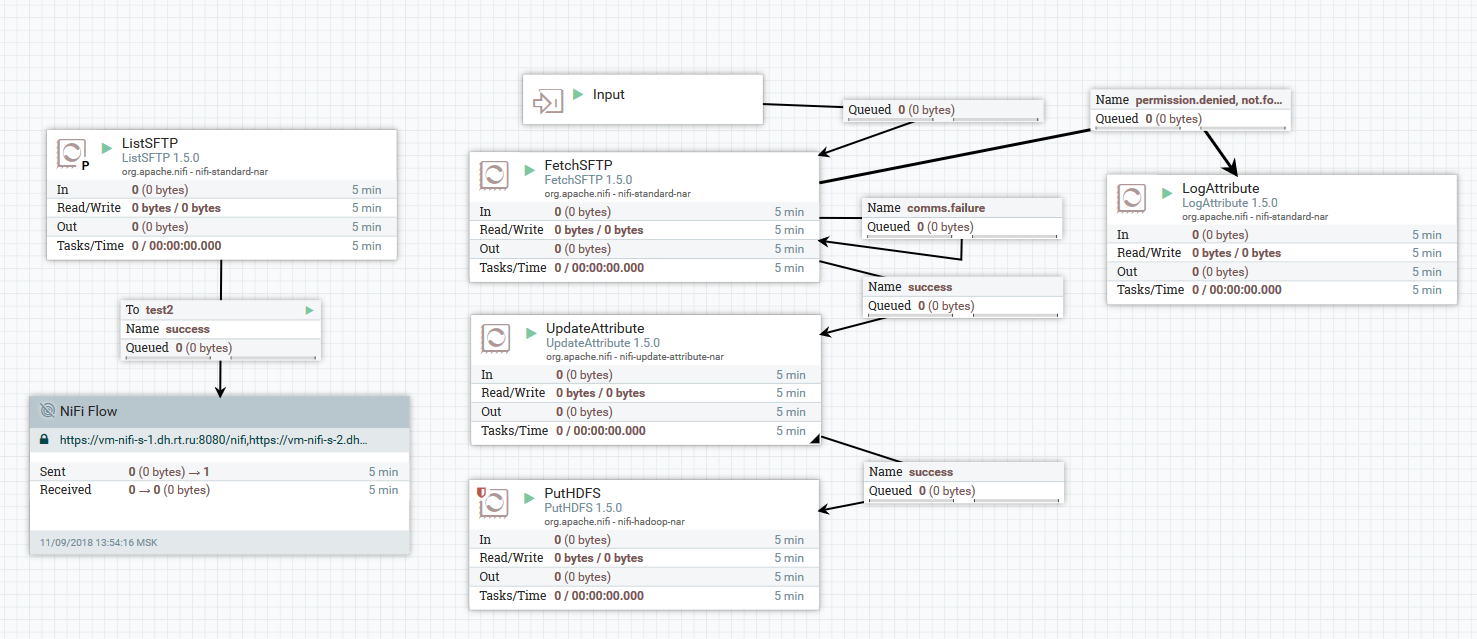
Example of uploading files from SFTP server to HDFS
In this example, the ListSFTP processor lists files on a remote server. The result of this listing is used for parallel downloading of files by all the nodes of the cluster by the FetchSFTP processor. After this, attributes are added to each file, obtained by parsing its name, which are then used by the PutHDFS processor when writing the file to the destination directory.
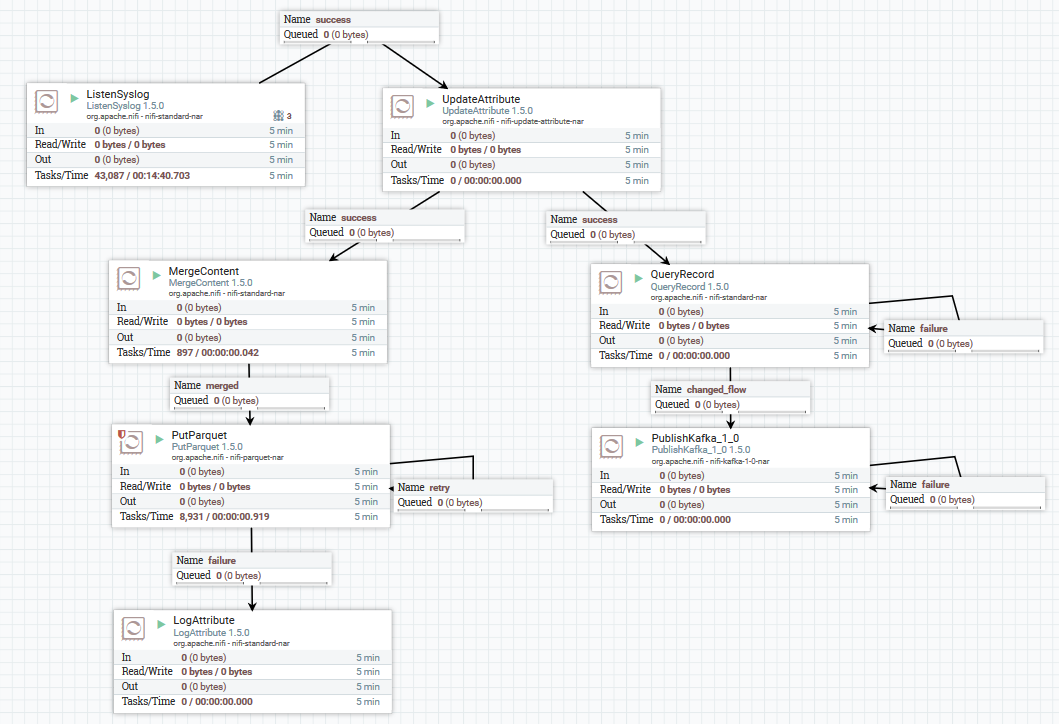
Example of loading data on syslog in Kafka and HDFS
Here, using the ListenSyslog processor, we get the input message flow. After that, each group of messages is added with attributes about the time of their arrival at NiFi and the name of the scheme in Avro Schema Registry. Next, the first branch is sent to the input of the QueryRecord processor, which, based on the specified scheme, reads the data and parses it using SQL, and then sends it to Kafka. The second branch is sent to the “MergeContent” processor, which aggregates the data for 10 minutes, then gives it to the next processor for conversion to the Parquet format and writing to HDFS.
Here is an example of how you can still make DataFlow:
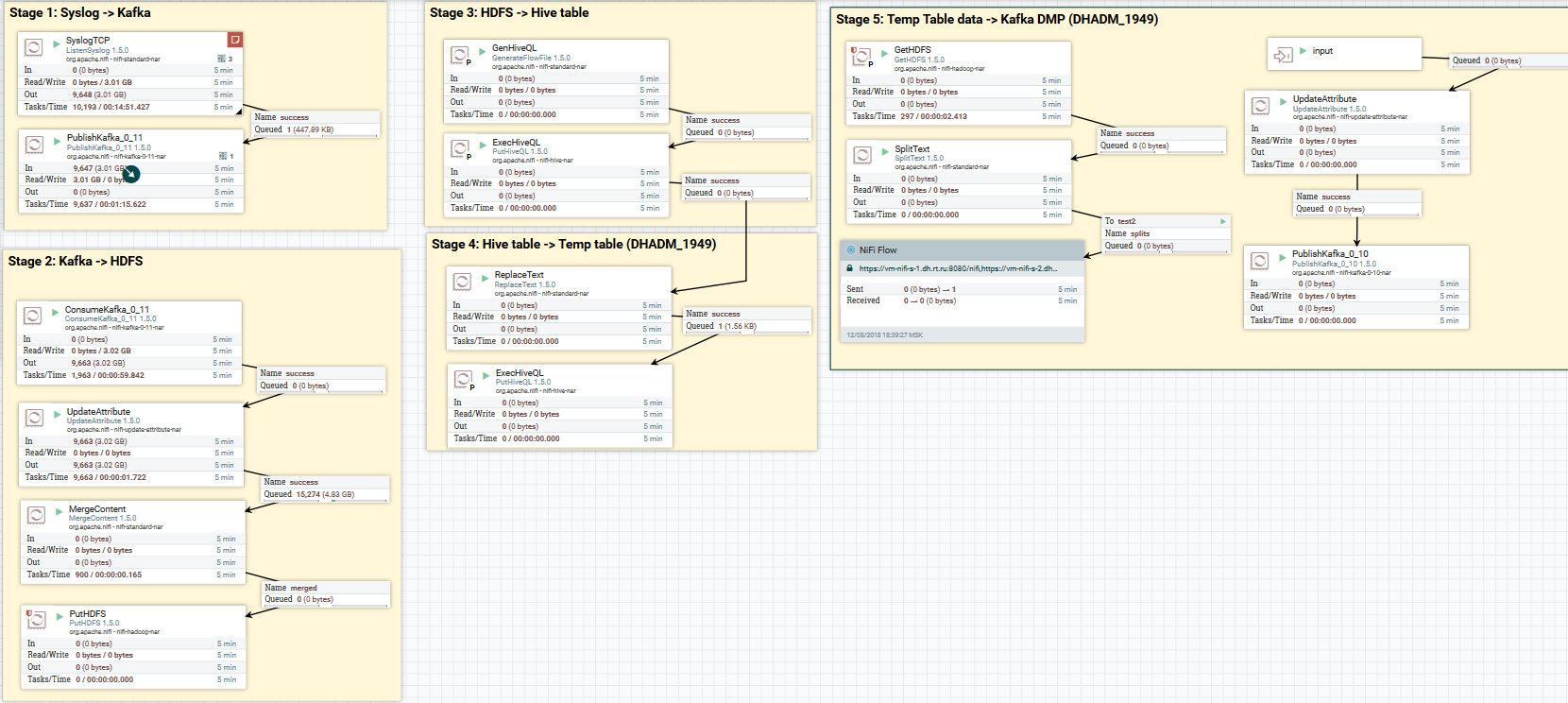
Downloading syslog data to Kafka and HDFS. Clearing data in Hive
Now about data conversion. NiFi allows you to parse data regularly, run SQL on it, filter and add fields, convert one data format to another. It also has its own expression language, rich in various operators and built-in functions. With it, you can add variables and attributes to the data, compare and calculate values, use them later in the formation of various parameters, such as the path to write to HDFS or the SQL query to Hive. Read more here .
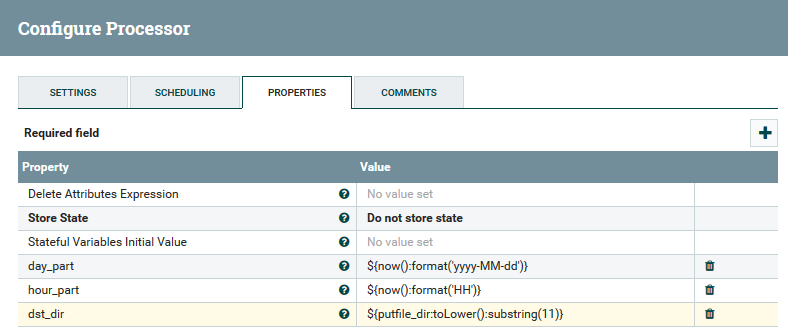
Example of using variables and functions in the UpdateAttribute processor
The user can track the full path of the data, watch for changes in their contents and attributes.
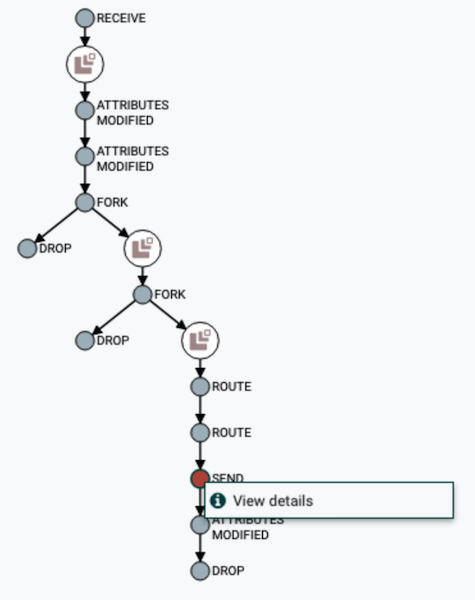
DataFlow chain visualization
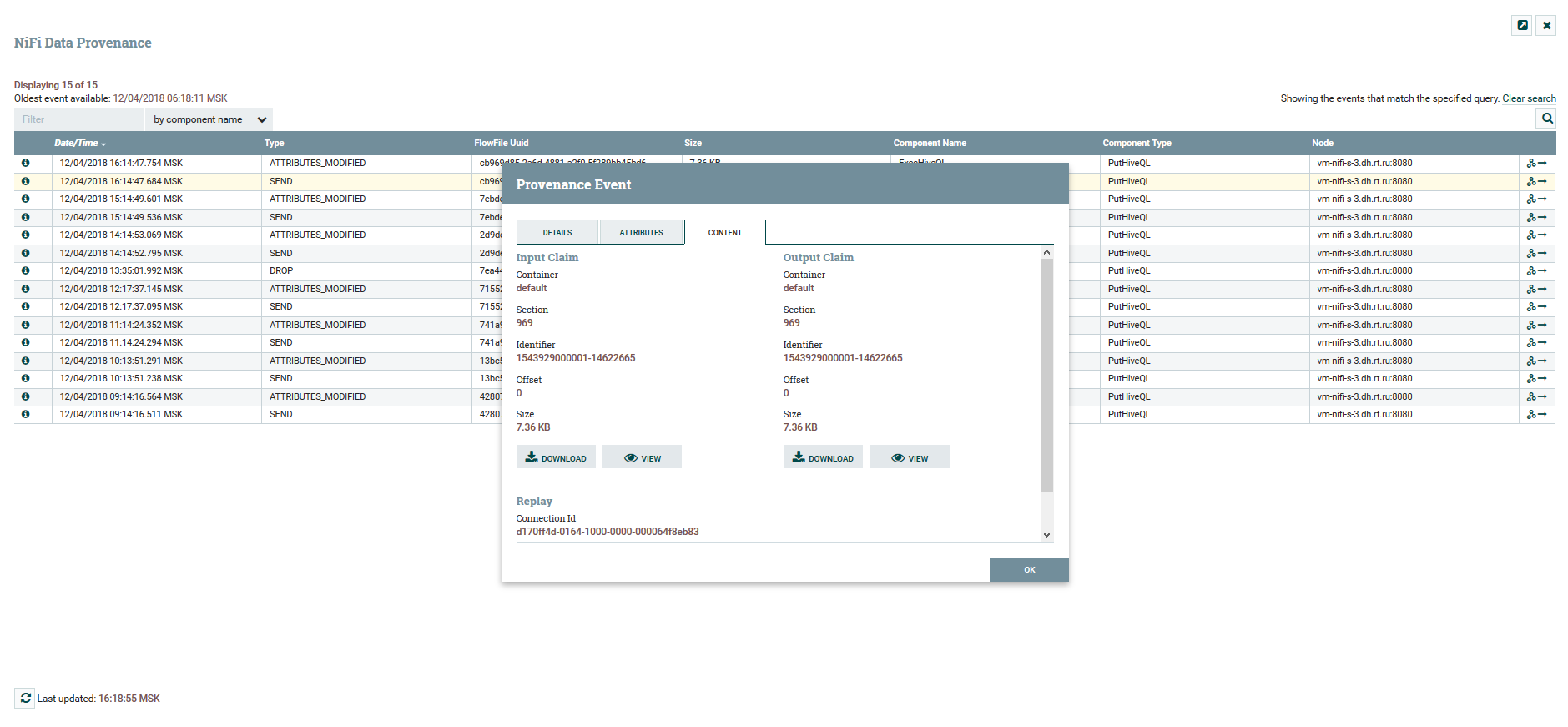
View content and data attributes
For versioning DataFlow there is a separate service NiFi Registry . By setting it up, you get the opportunity to manage change. You can launch local changes, roll back or download any previous version.

Version Control menu
In NiFi, you can control access to the web interface and the separation of user rights. The following authentication mechanisms are currently supported:
Simultaneous use of several mechanisms at once is not supported. For authorization of users in the system FileUserGroupProvider and LdapUserGroupProvider are used. Read more about it here .
As I said, NiFi can work in cluster mode. This provides fault tolerance and makes it possible to scale the load horizontally. There is no static fixed master node. Instead, Apache Zookeeper selects one node as the coordinator and one as the primary. The coordinator receives information from other nodes about their status and is responsible for connecting and disconnecting them from the cluster.
Primary-node is used to run isolated processors that should not run on all nodes at the same time.
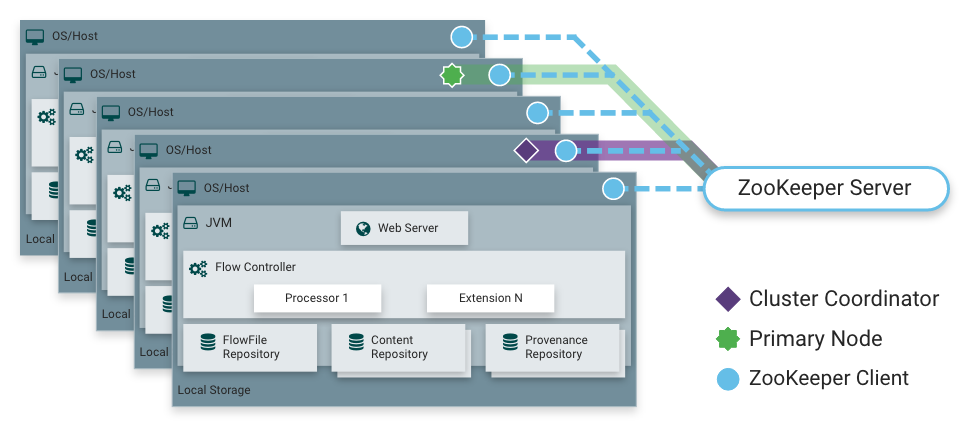
NiFi work in a cluster
Load distribution across cluster nodes using the example of PutHDFS processor

NiFi Instance Architecture
NiFi is based on the concept of “Flow Based Programming” ( FBP ). Here are the basic concepts and components that each user encounters:
FlowFile - an entity that represents an object with content from zero and more bytes and corresponding attributes. This can be either the data itself (for example, the Kafka message flow), or the result of the processor (PutSQL, for example), which does not contain the data as such, but only the attributes generated as a result of the query. Attributes are FlowFile metadata.
FlowFile Processor - this is the essence that performs the main work in NiFi. The processor, as a rule, has one or several functions for working with FlowFile: create, read / write and change content, read / write / change attributes, and route. For example, the processor "ListenSyslog" receives data on the syslog-protocol, creating FlowFile'y with the attributes syslog.version, syslog.hostname, syslog.sender and others at the output. The RouteOnAttribute processor reads the attributes of the input FlowFile and decides whether to redirect it to the appropriate connection with another processor depending on the attribute values.
Connection - connects and transfers FlowFile between different processors and some other NiFi entities. Connection puts FlowFile in the queue, and then passes it further along the chain. You can configure how FlowFiles are selected from the queue, their lifetime, the maximum number and maximum size of all objects in the queue.
Process Group - a set of processors, their connections and other elements of DataFlow. It is a mechanism for organizing multiple components into one logical structure. Allows you to simplify the understanding of DataFlow. Input / Output Ports are used to receive and send data from Process Groups. Read more about their use here .
The FlowFile Repository is where NiFi stores all the information it knows about every existing FlowFile in the system.
Content Repository - the repository in which the contents of all FlowFile are located, i.e. the data being transferred.
Provenance Repository - contains a story about each FlowFile. Each time a flow event occurs (create, modify, etc.), the corresponding information is entered into this repository.
Web Server - provides a web interface and REST API.
With the help of NiFi, Rostelecom was able to improve the delivery mechanism of data to Data Lake on Hadoop. In general, the whole process has become more convenient and reliable. Today I can say with confidence that NiFi is great for doing downloads in Hadoop. We have no problems with its operation.
By the way, NiFi is included in the Hortonworks Data Flow distribution and is actively developed by Hortonworks itself. And he also has an interesting Apache MiNiFi subproject, which allows you to collect data from various devices and integrate them into DataFlow inside NiFi.
Perhaps that's all. Thank you all for your attention. Write in the comments if you have questions. I will answer them with pleasure.
At Rostelecom, we are striving to develop work with Hadoop, so we have already tried and appreciated the advantages of Apache NiFi compared to other solutions. In this article I will tell you what attracted us to this tool and how we use it.
Prehistory
Not so long ago, we were faced with the choice of a solution for loading data from external sources into the Hadoop cluster. A long time to solve such problems, we used Apache Flume . To Flume as a whole, there were no complaints, except for a few moments that did not suit us.
')
The first thing that we, as administrators, did not like was that the writing of the Flume config to perform the next trivial download could not be trusted to a developer or analyst who was not immersed in the subtleties of this tool. Connecting each new source required mandatory intervention from the team of administrators.
The second point was fault tolerance and scaling. For heavy downloads, for example, via syslog, it was necessary to configure several Flume agents and set up a balancer in front of them. All this then needed to be somehow monitored and restored in the event of a failure.
Thirdly , Flume did not allow downloading data from various DBMSs and working with some other protocols out of the box. Of course, in the open spaces of the network, it was possible to find ways to make Flume work with Oracle or SFTP, but the support of such “bikes” is not at all pleasant. To download data from the same Oracle, we had to use one more tool - Apache Sqoop .
Frankly, I am a lazy man by nature, and I didn’t want to support the zoo of decisions at all. And I didn’t like that I had to do all this work myself.
There are, of course, quite powerful solutions on the market for ETL tools that can work with Hadoop. These include Informatica, IBM Datastage, SAS and Pentaho Data Integration. These are the ones that can most often be heard from colleagues and those that come to mind first. By the way, we use IBM DataStage for ETL on solutions of the Data Warehouse class. But historically, our team had no opportunity to use DataStage for downloads to Hadoop. Again, we did not need all the power of solutions of this level to perform fairly simple transformations and data downloads. What we needed was a solution with good development dynamics, able to work with a variety of protocols and possessing a convenient and understandable interface that not only the administrator can understand, but also the developer with the analyst, who are often for us customers of the data itself.
As you can see from the title, we solved the problems listed with Apache NiFi.
What is Apache NiFi?
The name NiFi comes from "Niagara Files". The project was developed for eight years by the US National Security Agency, and in November 2014 its source code was opened and transferred to the Apache Software Foundation as part of the NSA Technology Transfer Program .
NiFi is an open source ETL / ELT tool that can work with many systems, and not just the Big Data class and the Data Warehouse. Here are some of them: HDFS, Hive, HBase, Solr, Cassandra, MongoDB, ElastcSearch, Kafka, RabbitMQ, Syslog, HTTPS, SFTP. You can view the full list in the official documentation .
Work with a specific DBMS is implemented by adding the appropriate JDBC driver. There is an API for writing your module as an additional receiver or data converter. Examples can be found here and here .
Main features
NiFi uses a web interface to create a dataflow. The analyst, who recently started working with Hadoop, the developer, and the bearded admin will cope with it. The latter two can interact not only with “rectangles and arrows”, but also with the REST API for collecting statistics, monitoring and managing DataFlow components.
NiFi control web interface
Below, I will show a few DataFlow examples for performing some common operations.
Example of uploading files from SFTP server to HDFS
In this example, the ListSFTP processor lists files on a remote server. The result of this listing is used for parallel downloading of files by all the nodes of the cluster by the FetchSFTP processor. After this, attributes are added to each file, obtained by parsing its name, which are then used by the PutHDFS processor when writing the file to the destination directory.
Example of loading data on syslog in Kafka and HDFS
Here, using the ListenSyslog processor, we get the input message flow. After that, each group of messages is added with attributes about the time of their arrival at NiFi and the name of the scheme in Avro Schema Registry. Next, the first branch is sent to the input of the QueryRecord processor, which, based on the specified scheme, reads the data and parses it using SQL, and then sends it to Kafka. The second branch is sent to the “MergeContent” processor, which aggregates the data for 10 minutes, then gives it to the next processor for conversion to the Parquet format and writing to HDFS.
Here is an example of how you can still make DataFlow:
Downloading syslog data to Kafka and HDFS. Clearing data in Hive
Now about data conversion. NiFi allows you to parse data regularly, run SQL on it, filter and add fields, convert one data format to another. It also has its own expression language, rich in various operators and built-in functions. With it, you can add variables and attributes to the data, compare and calculate values, use them later in the formation of various parameters, such as the path to write to HDFS or the SQL query to Hive. Read more here .
Example of using variables and functions in the UpdateAttribute processor
The user can track the full path of the data, watch for changes in their contents and attributes.
DataFlow chain visualization
View content and data attributes
For versioning DataFlow there is a separate service NiFi Registry . By setting it up, you get the opportunity to manage change. You can launch local changes, roll back or download any previous version.
Version Control menu
In NiFi, you can control access to the web interface and the separation of user rights. The following authentication mechanisms are currently supported:
- Based on certificates
- Based on username and password through LDAP and Kerberos
- Via Apache Knox
- Via OpenID Connect
Simultaneous use of several mechanisms at once is not supported. For authorization of users in the system FileUserGroupProvider and LdapUserGroupProvider are used. Read more about it here .
As I said, NiFi can work in cluster mode. This provides fault tolerance and makes it possible to scale the load horizontally. There is no static fixed master node. Instead, Apache Zookeeper selects one node as the coordinator and one as the primary. The coordinator receives information from other nodes about their status and is responsible for connecting and disconnecting them from the cluster.
Primary-node is used to run isolated processors that should not run on all nodes at the same time.
NiFi work in a cluster
Load distribution across cluster nodes using the example of PutHDFS processor
A brief description of the architecture and components of NiFi
NiFi Instance Architecture
NiFi is based on the concept of “Flow Based Programming” ( FBP ). Here are the basic concepts and components that each user encounters:
FlowFile - an entity that represents an object with content from zero and more bytes and corresponding attributes. This can be either the data itself (for example, the Kafka message flow), or the result of the processor (PutSQL, for example), which does not contain the data as such, but only the attributes generated as a result of the query. Attributes are FlowFile metadata.
FlowFile Processor - this is the essence that performs the main work in NiFi. The processor, as a rule, has one or several functions for working with FlowFile: create, read / write and change content, read / write / change attributes, and route. For example, the processor "ListenSyslog" receives data on the syslog-protocol, creating FlowFile'y with the attributes syslog.version, syslog.hostname, syslog.sender and others at the output. The RouteOnAttribute processor reads the attributes of the input FlowFile and decides whether to redirect it to the appropriate connection with another processor depending on the attribute values.
Connection - connects and transfers FlowFile between different processors and some other NiFi entities. Connection puts FlowFile in the queue, and then passes it further along the chain. You can configure how FlowFiles are selected from the queue, their lifetime, the maximum number and maximum size of all objects in the queue.
Process Group - a set of processors, their connections and other elements of DataFlow. It is a mechanism for organizing multiple components into one logical structure. Allows you to simplify the understanding of DataFlow. Input / Output Ports are used to receive and send data from Process Groups. Read more about their use here .
The FlowFile Repository is where NiFi stores all the information it knows about every existing FlowFile in the system.
Content Repository - the repository in which the contents of all FlowFile are located, i.e. the data being transferred.
Provenance Repository - contains a story about each FlowFile. Each time a flow event occurs (create, modify, etc.), the corresponding information is entered into this repository.
Web Server - provides a web interface and REST API.
Conclusion
With the help of NiFi, Rostelecom was able to improve the delivery mechanism of data to Data Lake on Hadoop. In general, the whole process has become more convenient and reliable. Today I can say with confidence that NiFi is great for doing downloads in Hadoop. We have no problems with its operation.
By the way, NiFi is included in the Hortonworks Data Flow distribution and is actively developed by Hortonworks itself. And he also has an interesting Apache MiNiFi subproject, which allows you to collect data from various devices and integrate them into DataFlow inside NiFi.
Additional Info About NiFi
- Official project documentation page
- Collection of interesting articles about NiFi from one of the project participants
- NiFi developer blog
- Articles on the portal Hortonworks
Perhaps that's all. Thank you all for your attention. Write in the comments if you have questions. I will answer them with pleasure.
Source: https://habr.com/ru/post/432166/
All Articles