Retrospective of automation and changes in the development processes of Timeweb
On November 1, 2017, I became the head of the development team in the Timeweb software development department. And on November 12, 2018, the head of the department asked when the article would be ready for Habrahabr, because the marketing department asks, the volunteers are over, and the content plan requires something else)
Therefore, I want to give a retrospective of how the processes of development, testing and supply of our products have changed over the past year. About inherited processes and tools, docker, gitlab and how we are developing.
Hosts Timeweb exists since 2006. All this time, the company has invested a lot of effort to provide customers with a unique and convenient service that would distinguish it from competitors. Timeweb has its own mobile applications, a web-based email interface, virtual hosting control panels, VDS, an affiliate program, its own support tools and much more.
There are about 250 projects in our gitlab: these are client applications, internal tools, libraries, configuration storage. Dozens of them are actively developed and supported: they commit during the week, test, collect, release.
')
In addition to the large amount of inherited code, all this pulls the corresponding number of inherited processes and related tools. Like any legacy, they also need to be maintained, optimized, refactored, and sometimes replaced.
From all this abundance of projects are closest to the clients hosting the control panel. And it is in the “Control Panel” project that we often run in various infrastructure improvements and make a lot of effort to keep the connected infrastructure in shape. Spreading the experience and favorite practices in other products and their teams.
I will tell you about different changes in tools and processes over the past year.
On the first working day, I tried to raise the control panel locally. At that time, there were five web applications in one repository:
- PU shared hosting 3.0,
- PU VDS 2.0,
- PU webmasters,
- STAFF (supports tool),
- Guidelines (demo standardized front-line components).
Vagrant was used locally to run. In Vagrant, it was run ansible. To start and configure it took the help of colleagues and about a day clean time. I had to install a special version of the Virtual Box (there were problems on the current stable one), the work from the console inside the virtual machine was unnerving: trivial commands like npm / composer install slowed down noticeably.
The performance of the applications themselves in the virtual machine was far from possible, given the technology stack used and the power of the machine. Not to mention that a virtual machine is a virtual machine, and by definition it occupies a significant part of the resources of your PC.
The local development environment was rewritten to run in docker containers. Docker-based containerization is the most common solution for isolating the application environment at all stages of its life cycle. Therefore, there are no special alternatives.
Of the benefits:
- locally the application has become more responsive, containers require less than a VM,
- the launch of a new instance, as practice has shown, takes only a few minutes and requires only docker (-compose) not lower than certain versions. After cloning, just run:
Not without compromise:
- I had to write shell-binding for the docked commands (composer, npm, etc.). They, like docker-compose.yml, are not completely cross-platform, in comparison with Vagrant. For example, launching on a Mac requires additional efforts, and on Windows, it will probably be easier to run the linux distribution with docker in the virtual machine. But this is an acceptable compromise, because the team uses only debian-based distributions, this is a valid limit for commercial development,
- a container based on github.com/jwilder/nginx-proxy is launched locally to support virtual hosts. Not that a crutch, but additional software, which sometimes must be remembered, although it does not cause problems.
Yes, everyone in the team had to realize a little bit what a docker is. Although thanks to the above shell scripts and Makefile, developers perform 95% of their tasks without thinking about containers, but in guaranteed identical environments.
These strange phrases are the names of the machines with test panels of the control panels, new and old, respectively.
The ansible recipes were used exclusively inside Vagrant, so the main advantage was not achieved: the versions of the packages in the sale and on the stands differed from what the developers worked.
The inconsistency of the versions of the server software packages on the old stands with what the developers had led to problems. Synchronization was complicated by the fact that system administrators use a different configuration management system, and it is not possible to integrate it with the developers repository.
After containerization, it was not too difficult to expand the docker-compose configuration for use on test benches. A new machine was created to deploy the stands on DOCKER_HOST.
Developers are now confident in the relevance of local and test environments.
Configuring projects in TeamCity is a painstaking and ungrateful process. The CI configuration was stored separately from the code, in xml, to which normal versioning is not applicable, and an overview of the changes. We also experienced problems with the stability of the build process on TeamCity agents.
Since gitlab was already used as a repository repository, starting to use its CI was not only logical, but also easy and pleasant. Now the entire CI / CD configuration is right in the repository.
For the year, almost all the projects gathered by TeamCity successfully moved to gitlab-ci. We were able to quickly implement a variety of features for automating CI / CD processes.
The clearest screenshots are pipelines:
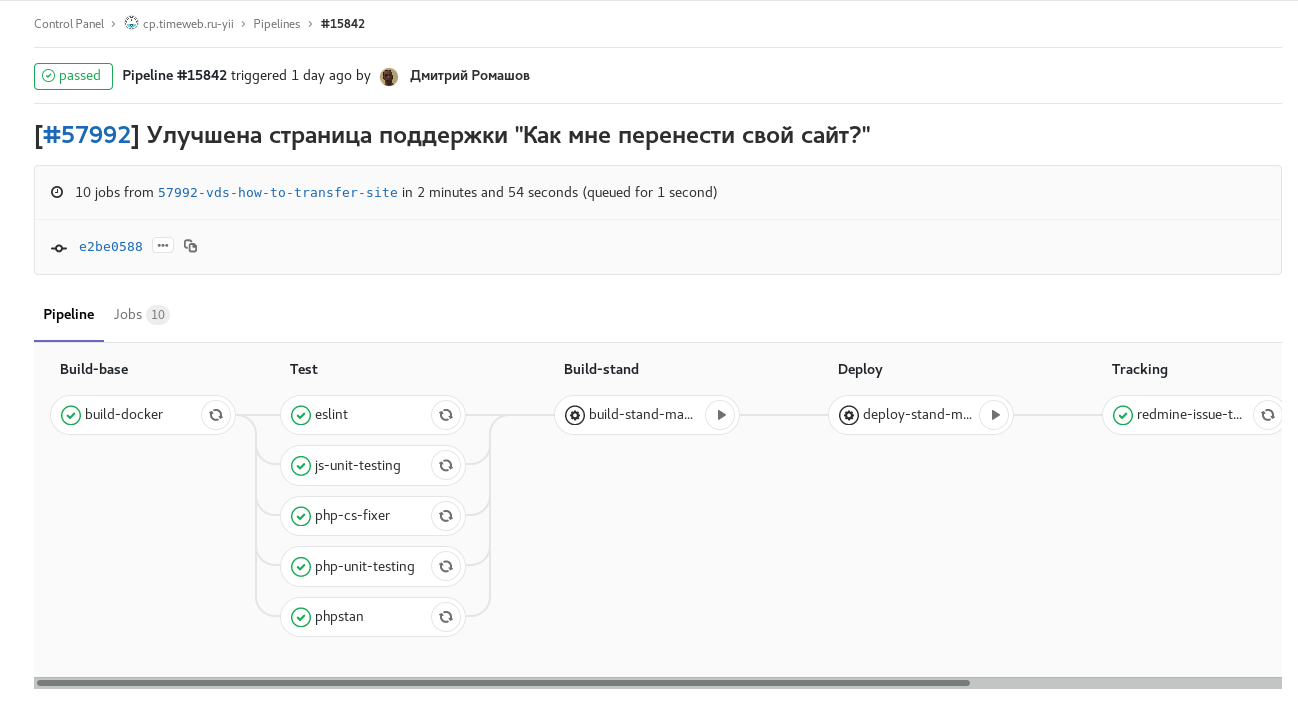
Ill. 1. feature-branch: includes all available automatic checks and tests. Upon completion, sends a comment referring to the pipeline to the redmine task. Manual tasks for the assembly and launch of the stand with this branch.
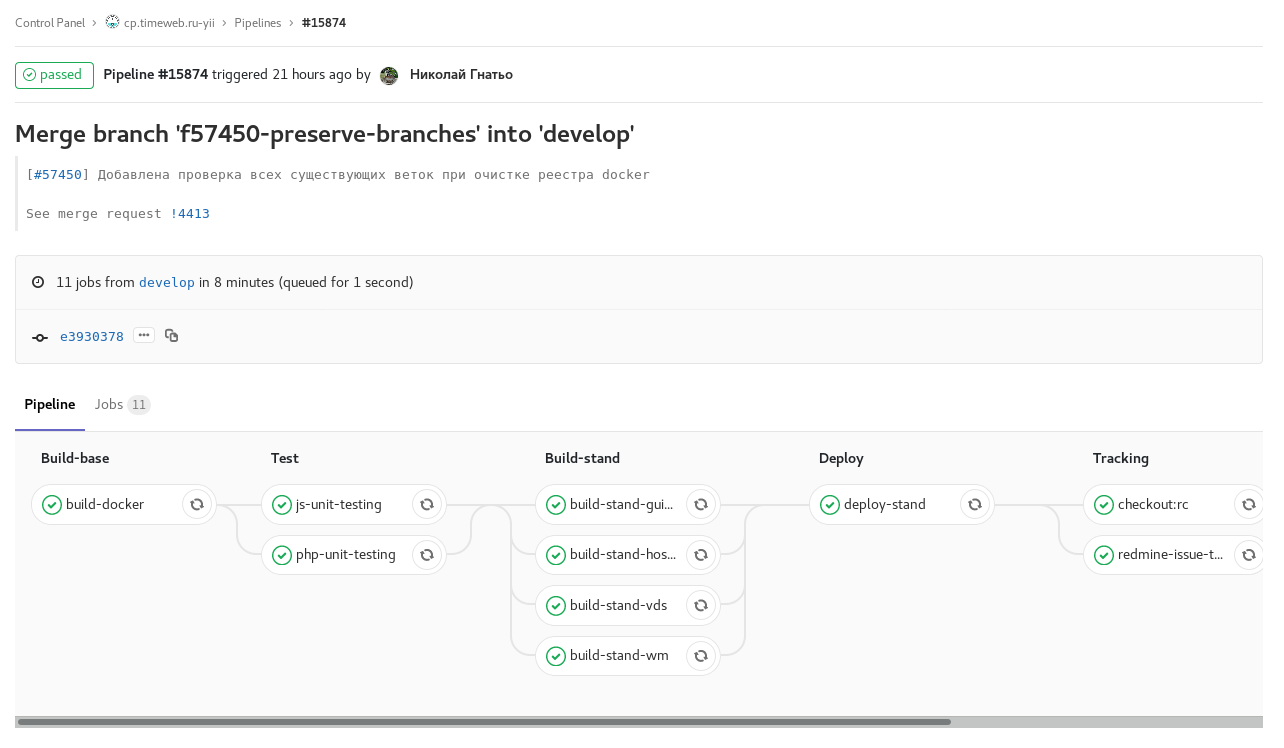
Ill. 2. develop a scheduled build with code freeze (checkout: rc): build develop on a schedule with code freeze. The assembly of the images for the stands of individual control panels takes place in parallel.
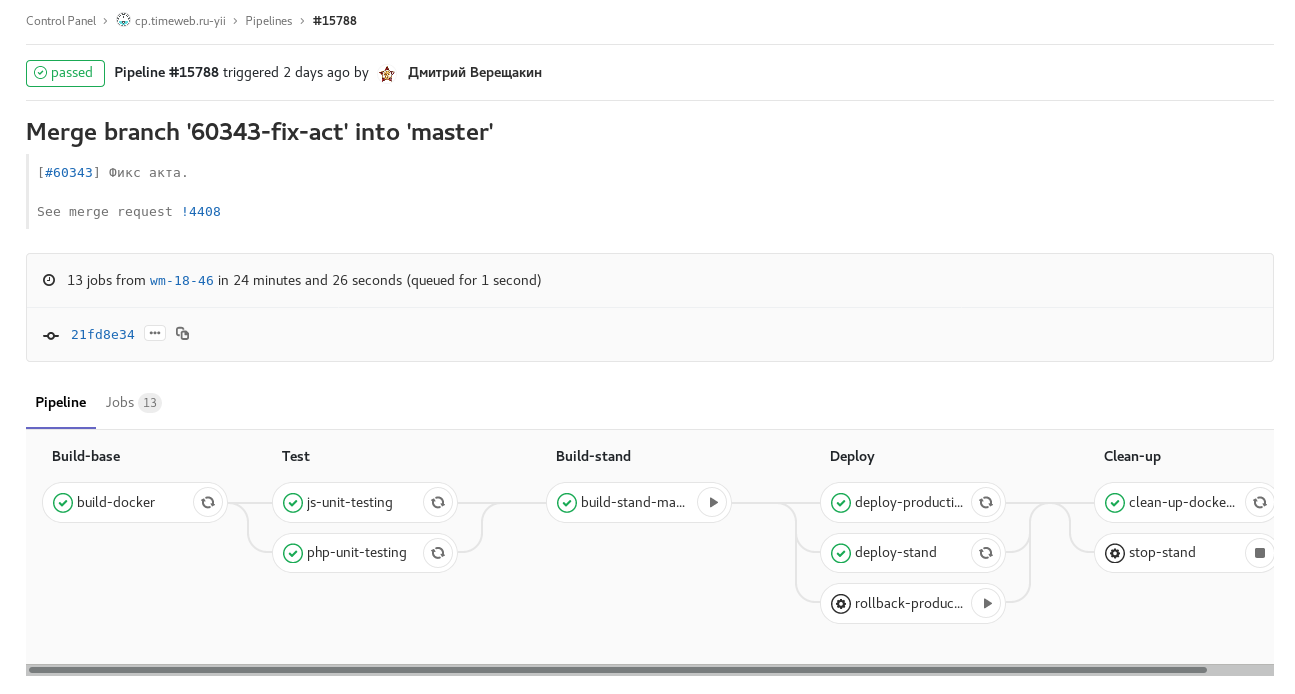
Ill. 3. tag pipeline: release of one of the control panels. Manual task for rollback release.
In addition, from gitlab-ci, there is a change of status and the assignment of a person responsible in redmine at the stages In Progress → Review → QA, notification in Slack about releases and updates of staging and rollbacks.
This is convenient, but we did not take into account one methodological point. Having implemented similar automation in one project, people quickly get used to it. And in the case of switching to another project where there is no such thing yet, or the process is different, you can forget to move and reassign the puzzle to redmine or leave a comment with a link to the Merge Request (which also gitlab-ci does), thus causing the reviewer to look for the desired MR yourself. At the same time, you simply don’t want to copy pieces of .gitlab-ci.yml and the accompanying shell code between projects, because you have to support copy-paste.
Conclusion: automation is good, but when it is the same at the level of all teams and projects, it is even better. I would be grateful to the respected public for ideas on how to organize a reuse of this configuration beautifully.
Gradually, our CI began to occupy indecently a lot of time. Testers suffered a lot from this: every fix in the master had to wait an hour for a release. It looked like this:

Ill. 4. pipeline 80lvl min duration.
It took a few days to dive into the analysis of slow places and search for ways to accelerate while maintaining functionality.
The most lengthy places in the process were installing npm-packages. Without any problems, they replaced it with yarn and saved up to 7 minutes in several places.
Abandoned automatic staging updates, preferred manual control of the state of this stand.
We also added several runners and divided into parallel tasks the assembly of application images and all the checks. After these optimizations, the pipeline of the main branch with the update of all the stands began to occupy in most cases 7-8 minutes.
For deployment in production and on the qa-booth, Capistrano was used (and continues to be used at the time of this writing). The main scenario for this tool: cloning the repository to the target server and performing all the tasks there.
Previously, the deployment was started by the hands of a QA-engineer who has the necessary ssh keys from Vagrant. Then, as Vagrant was abandoned, Capistrano moved to a separate container. Now the deployment is made from a container with Capistrano with gitlab-runners, marked with special tags and having the necessary keys, automatically when the necessary tags appear.
The problem here is that the whole build process:
a) significantly consumes combat server resources (especially node / gulp),
b) there is no possibility to keep up to date composer version, npm. node, etc.
It is more logical to build on a build server (in our case, this is gitlab-runner), and to put ready-made artifacts on the target server. This will save the combat server from the assembly utilities and alien responsibility.
Now we are considering deployer as a replacement for capistrano (since we don’t have rubies, and neither do we have a desire to work with its DSL) and plan to transfer the assembly to the gitlab side. In some non-critical projects, we have already managed to try it and are satisfied so far: it looks simpler, we have not encountered restrictions.
The development is carried out in weekly cycles. Over the course of five days, a new version is being developed: improvements and corrections are scheduled for release, scheduled for release next week. On Friday evening, code freeze automatically occurs. On Monday, testing of the new version begins, improvements are made, and by the mid-end of the working week, a release takes place.
Previously, we used branches with names like rc18-47, which means the release of the candidate of the 47th week of 2018. Code freeze consisted in checkout rc-branches from develop. But in October of this year they switched to tags. Tags have been set before, but after the fact, after the release and merger of rc with master. Now the appearance of the tag leads to automatic deployment, and freezing this merge develop into master.
So we got rid of unnecessary entities in git and variables in the process.
Now we are “pulling” projects that are lagging behind in the process to a similar workflow.
Automation of processes, their optimization, as well as development, is a permanent matter: while the product is actively developing and the team is working, there will be corresponding tasks. There are new ideas how to get rid of routine actions: features are implemented in gitlab-ci.
With the growth of applications, CI processes start to take a prohibitively long time - it's time to work on their performance. As approaches and tools become obsolete, it is necessary to devote time to refactoring, revising them, and updating them.

Therefore, I want to give a retrospective of how the processes of development, testing and supply of our products have changed over the past year. About inherited processes and tools, docker, gitlab and how we are developing.
Hosts Timeweb exists since 2006. All this time, the company has invested a lot of effort to provide customers with a unique and convenient service that would distinguish it from competitors. Timeweb has its own mobile applications, a web-based email interface, virtual hosting control panels, VDS, an affiliate program, its own support tools and much more.
There are about 250 projects in our gitlab: these are client applications, internal tools, libraries, configuration storage. Dozens of them are actively developed and supported: they commit during the week, test, collect, release.
')
In addition to the large amount of inherited code, all this pulls the corresponding number of inherited processes and related tools. Like any legacy, they also need to be maintained, optimized, refactored, and sometimes replaced.
From all this abundance of projects are closest to the clients hosting the control panel. And it is in the “Control Panel” project that we often run in various infrastructure improvements and make a lot of effort to keep the connected infrastructure in shape. Spreading the experience and favorite practices in other products and their teams.
I will tell you about different changes in tools and processes over the past year.
Vagrant → docker-compose
Problem
On the first working day, I tried to raise the control panel locally. At that time, there were five web applications in one repository:
- PU shared hosting 3.0,
- PU VDS 2.0,
- PU webmasters,
- STAFF (supports tool),
- Guidelines (demo standardized front-line components).
Vagrant was used locally to run. In Vagrant, it was run ansible. To start and configure it took the help of colleagues and about a day clean time. I had to install a special version of the Virtual Box (there were problems on the current stable one), the work from the console inside the virtual machine was unnerving: trivial commands like npm / composer install slowed down noticeably.
The performance of the applications themselves in the virtual machine was far from possible, given the technology stack used and the power of the machine. Not to mention that a virtual machine is a virtual machine, and by definition it occupies a significant part of the resources of your PC.
Decision
The local development environment was rewritten to run in docker containers. Docker-based containerization is the most common solution for isolating the application environment at all stages of its life cycle. Therefore, there are no special alternatives.
findings
Of the benefits:
- locally the application has become more responsive, containers require less than a VM,
- the launch of a new instance, as practice has shown, takes only a few minutes and requires only docker (-compose) not lower than certain versions. After cloning, just run:
make install-dev make run-dev Not without compromise:
- I had to write shell-binding for the docked commands (composer, npm, etc.). They, like docker-compose.yml, are not completely cross-platform, in comparison with Vagrant. For example, launching on a Mac requires additional efforts, and on Windows, it will probably be easier to run the linux distribution with docker in the virtual machine. But this is an acceptable compromise, because the team uses only debian-based distributions, this is a valid limit for commercial development,
- a container based on github.com/jwilder/nginx-proxy is launched locally to support virtual hosts. Not that a crutch, but additional software, which sometimes must be remembered, although it does not cause problems.
Yes, everyone in the team had to realize a little bit what a docker is. Although thanks to the above shell scripts and Makefile, developers perform 95% of their tasks without thinking about containers, but in guaranteed identical environments.
newcp-dev → cp-stands
These strange phrases are the names of the machines with test panels of the control panels, new and old, respectively.
Problem
The ansible recipes were used exclusively inside Vagrant, so the main advantage was not achieved: the versions of the packages in the sale and on the stands differed from what the developers worked.
The inconsistency of the versions of the server software packages on the old stands with what the developers had led to problems. Synchronization was complicated by the fact that system administrators use a different configuration management system, and it is not possible to integrate it with the developers repository.
Decision
After containerization, it was not too difficult to expand the docker-compose configuration for use on test benches. A new machine was created to deploy the stands on DOCKER_HOST.
findings
Developers are now confident in the relevance of local and test environments.
TeamCity → gitlab-ci
Problems
Configuring projects in TeamCity is a painstaking and ungrateful process. The CI configuration was stored separately from the code, in xml, to which normal versioning is not applicable, and an overview of the changes. We also experienced problems with the stability of the build process on TeamCity agents.
Decision
Since gitlab was already used as a repository repository, starting to use its CI was not only logical, but also easy and pleasant. Now the entire CI / CD configuration is right in the repository.
Result
For the year, almost all the projects gathered by TeamCity successfully moved to gitlab-ci. We were able to quickly implement a variety of features for automating CI / CD processes.
The clearest screenshots are pipelines:
Ill. 1. feature-branch: includes all available automatic checks and tests. Upon completion, sends a comment referring to the pipeline to the redmine task. Manual tasks for the assembly and launch of the stand with this branch.
Ill. 2. develop a scheduled build with code freeze (checkout: rc): build develop on a schedule with code freeze. The assembly of the images for the stands of individual control panels takes place in parallel.
Ill. 3. tag pipeline: release of one of the control panels. Manual task for rollback release.
In addition, from gitlab-ci, there is a change of status and the assignment of a person responsible in redmine at the stages In Progress → Review → QA, notification in Slack about releases and updates of staging and rollbacks.
This is convenient, but we did not take into account one methodological point. Having implemented similar automation in one project, people quickly get used to it. And in the case of switching to another project where there is no such thing yet, or the process is different, you can forget to move and reassign the puzzle to redmine or leave a comment with a link to the Merge Request (which also gitlab-ci does), thus causing the reviewer to look for the desired MR yourself. At the same time, you simply don’t want to copy pieces of .gitlab-ci.yml and the accompanying shell code between projects, because you have to support copy-paste.
Conclusion: automation is good, but when it is the same at the level of all teams and projects, it is even better. I would be grateful to the respected public for ideas on how to organize a reuse of this configuration beautifully.
Pipeline duration: 80 min → 8 min
Gradually, our CI began to occupy indecently a lot of time. Testers suffered a lot from this: every fix in the master had to wait an hour for a release. It looked like this:
Ill. 4. pipeline 80
It took a few days to dive into the analysis of slow places and search for ways to accelerate while maintaining functionality.
The most lengthy places in the process were installing npm-packages. Without any problems, they replaced it with yarn and saved up to 7 minutes in several places.
Abandoned automatic staging updates, preferred manual control of the state of this stand.
We also added several runners and divided into parallel tasks the assembly of application images and all the checks. After these optimizations, the pipeline of the main branch with the update of all the stands began to occupy in most cases 7-8 minutes.
Capistrano → deployer
For deployment in production and on the qa-booth, Capistrano was used (and continues to be used at the time of this writing). The main scenario for this tool: cloning the repository to the target server and performing all the tasks there.
Previously, the deployment was started by the hands of a QA-engineer who has the necessary ssh keys from Vagrant. Then, as Vagrant was abandoned, Capistrano moved to a separate container. Now the deployment is made from a container with Capistrano with gitlab-runners, marked with special tags and having the necessary keys, automatically when the necessary tags appear.
The problem here is that the whole build process:
a) significantly consumes combat server resources (especially node / gulp),
b) there is no possibility to keep up to date composer version, npm. node, etc.
It is more logical to build on a build server (in our case, this is gitlab-runner), and to put ready-made artifacts on the target server. This will save the combat server from the assembly utilities and alien responsibility.
Now we are considering deployer as a replacement for capistrano (since we don’t have rubies, and neither do we have a desire to work with its DSL) and plan to transfer the assembly to the gitlab side. In some non-critical projects, we have already managed to try it and are satisfied so far: it looks simpler, we have not encountered restrictions.
Gitflow: rc-branches → tags
The development is carried out in weekly cycles. Over the course of five days, a new version is being developed: improvements and corrections are scheduled for release, scheduled for release next week. On Friday evening, code freeze automatically occurs. On Monday, testing of the new version begins, improvements are made, and by the mid-end of the working week, a release takes place.
Previously, we used branches with names like rc18-47, which means the release of the candidate of the 47th week of 2018. Code freeze consisted in checkout rc-branches from develop. But in October of this year they switched to tags. Tags have been set before, but after the fact, after the release and merger of rc with master. Now the appearance of the tag leads to automatic deployment, and freezing this merge develop into master.
So we got rid of unnecessary entities in git and variables in the process.
Now we are “pulling” projects that are lagging behind in the process to a similar workflow.
Conclusion
Automation of processes, their optimization, as well as development, is a permanent matter: while the product is actively developing and the team is working, there will be corresponding tasks. There are new ideas how to get rid of routine actions: features are implemented in gitlab-ci.
With the growth of applications, CI processes start to take a prohibitively long time - it's time to work on their performance. As approaches and tools become obsolete, it is necessary to devote time to refactoring, revising them, and updating them.
Source: https://habr.com/ru/post/432150/
All Articles