MySQL High Availability on GitHub
GitHub uses MySQL as the main data repository for everything that is not related to git , so the availability of MySQL is key to the normal operation of GitHub. The site itself, the GitHub API, the authentication system and many other features require access to databases. We use several MySQL clusters to handle various services and tasks. They are set up according to the classical scheme with one main node available for recording and its replicas. Replicas (the remaining nodes of the cluster) asynchronously reproduce the changes of the main node and provide read access.
The availability of the main nodes is critical. Without a master node, the cluster does not support writing, which means that the necessary changes cannot be saved. Committing transactions, registering problems, creating new users, repositories, reviews and much more will be simply impossible.
To maintain the record, you need the corresponding available node — the main node in the cluster. However, no less important is the ability to identify or detect such a node.
In the event of a failure of the current main node, it is important to ensure the prompt appearance of a new replacement server, as well as to be able to quickly notify all services about this change. Total downtime is the sum of the time it takes to detect a crash, fail over, and notify about a new main node.

This publication describes a solution for ensuring high availability of MySQL on GitHub and detection of the main service, which allows us to reliably perform operations across several data centers, maintain operability when certain such centers are unavailable, and guarantee minimum downtime in case of failure.
Goals for High Availability
The solution described in the article is a new, improved version of previous solutions for providing high availability (HA) implemented in GitHub. As we grow, we need to adapt the MySQL HA strategy to change. We aim to follow similar approaches for MySQL and other services on GitHub.
To find the right solution for high availability and service discovery, you must first answer a few specific questions. Here is their sample list:
- What is the maximum downtime for you uncritically?
- How reliable are crash detection tools? Are false positives (premature failover) critical for you?
- How reliable is the failover system? Where can fail occur?
- How efficiently does the solution work in multiple data center environments? How effective is the solution in low and high latency networks?
- Will the solution continue to operate in the event of a complete failure of the data processing center (DPC) or in network isolation conditions?
- What mechanism (if any) prevents or mitigates the effects of the emergence of two main servers in a cluster that independently write to each other?
- Is data loss critical for you? If so, to what extent?
In order to demonstrate, let's first consider the previous solution and discuss why we decided to refuse it.
Refusal to use VIP and DNS for detection
As part of the previous decision, we used:
- orchestrator for detecting and failing;
- VIP and DNS to locate the main node.
In this case, the clients detected the entry node by its name, for example, mysql-writer-1.github.net . By name, the virtual IP address (VIP) of the host has been determined.
Thus, in the normal situation, the clients simply had to resolve the name and connect to the received IP address, where the main node was already waiting for them.
Consider the following replication topology, covering three different data centers:
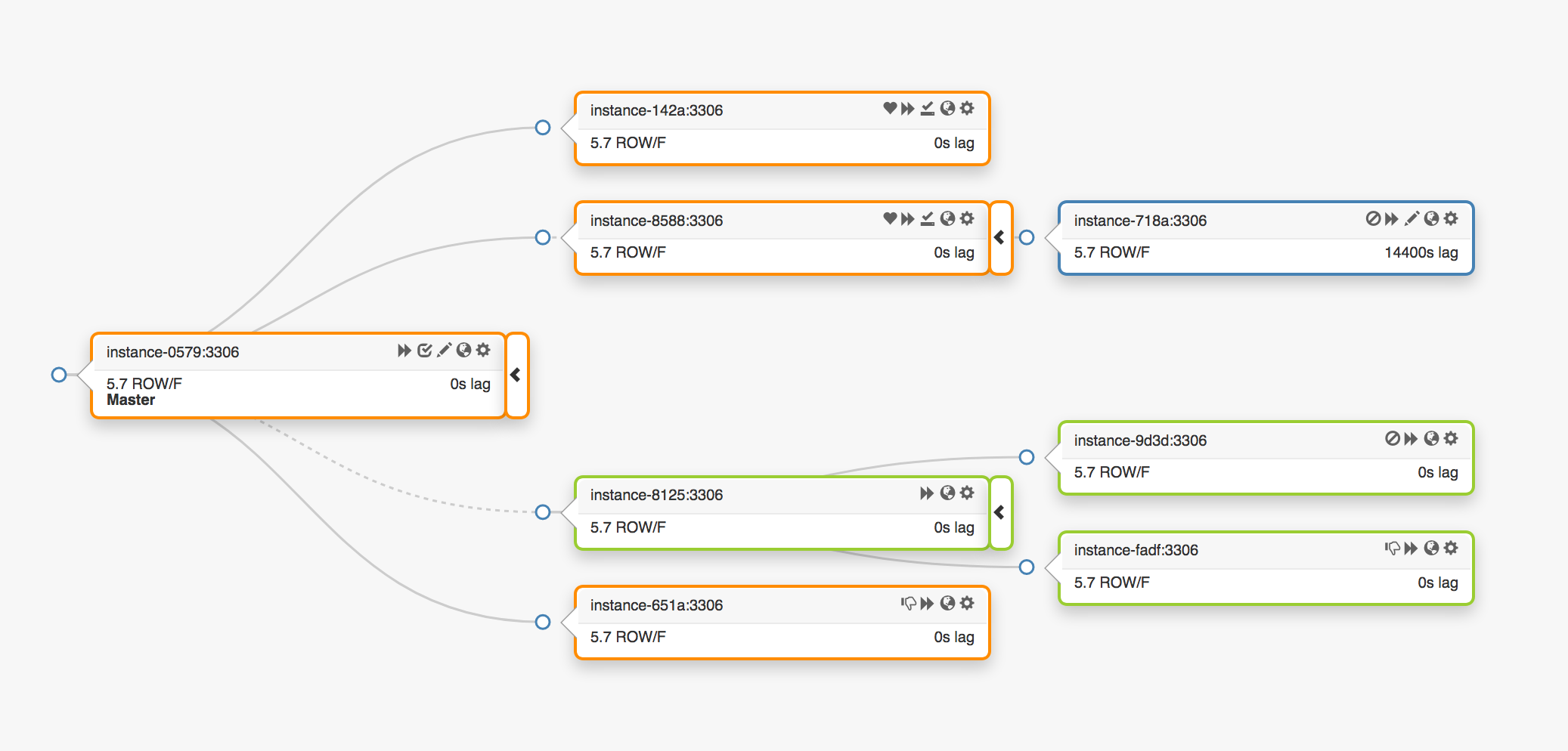
In the event of a failure of the main node, a new server should be assigned in its place (one of the replicas).
orchestrator detects a failure, selects a new master node, and then assigns the name / VIP. The clients do not really know the identity of the main node; they only know the name, which now must point to the new node. However, pay attention to that.
VIP-addresses are shared, the database servers request them and own them. To receive or release a VIP, the server must send an ARP request. The server owning the VIP must first release it before the new master has access to this address. This approach leads to some undesirable consequences:
- In normal mode, the failover system will first contact the failed main node and request it to release the VIP, and then contact the new main server with a request for assigning VIP. But what to do if the first head node is unavailable or refuses to request to release the VIP address? Given that the server is currently in a state of failure, it is unlikely that it will be able to respond to the request in a timely manner or respond to it altogether.
- As a result, a situation may arise when two hosts claim their rights to the same VIP. Different clients can connect to any of these servers, depending on the shortest network path.
- The correct operation in this situation depends on the interaction of two independent servers, and this configuration is unreliable.
- Even if the first master node responds to requests, we are wasting precious time: switching to a new master server does not occur while we are contacting the old one.
- At the same time, even in the case of VIP reassignment, there is no guarantee that the existing client connections on the old server will be broken. We again run the risk of being in a situation with two independent main nodes.
Somewhere in our environment, VIP addresses are related to physical location. They are assigned to a switch or router. Therefore, we can reassign the VIP address only to a server located in the same environment as the original head node. In particular, in some cases, we will not be able to assign a VIP server in another data center and will need to make changes to the DNS.
- It takes more time to propagate changes to the DNS. Clients store DNS names for a pre-configured period of time. Failure of multiple data centers involves longer downtime because it takes more time to provide all customers with information about the new main site.
These restrictions were enough to force us to start the search for a new solution, but it was necessary to take into account the following:
- The main nodes independently transmitted heartbeat packets through the
pt-heartbeatto measure the amount of lag and adjust the load . The service needed to be transferred to the newly designated head node. If possible, it should be disabled on the old server. - Similarly, the main nodes independently managed the work with Pseudo-GTID . It was necessary to start this process on the new main node and it is desirable to stop on the old one.
- A new master node became available for writing. The old node (if possible) should have received the
read_onlylabel (read-only).
These additional steps increased total downtime and added their own points of failure and problems.
The solution worked, and GitHub successfully worked out MySQL failures in the background, but we wanted to improve our approach to HA as follows:
- ensure independence from specific data centers;
- guarantee performance in case of data center failures;
- abandon unreliable collaborative workflows;
- reduce total downtime;
- perform, as far as possible, lossless failures.
GitHub HA Solution: orchestrator, Consul, GLB
Our new strategy, along with the accompanying improvements, eliminates most of the problems mentioned above or mitigates their consequences. Our current HA system consists of the following elements:
- orchestrator for detecting and developing failures. We use an orchestrator / raft scheme with multiple data centers, as shown in the figure below;
- Hashicorp Consul for service discovery;
- GLB / HAProxy as a proxy layer between clients and recording nodes. The source code for the GLB Director tool is open;
anycasttechnology for network routing.
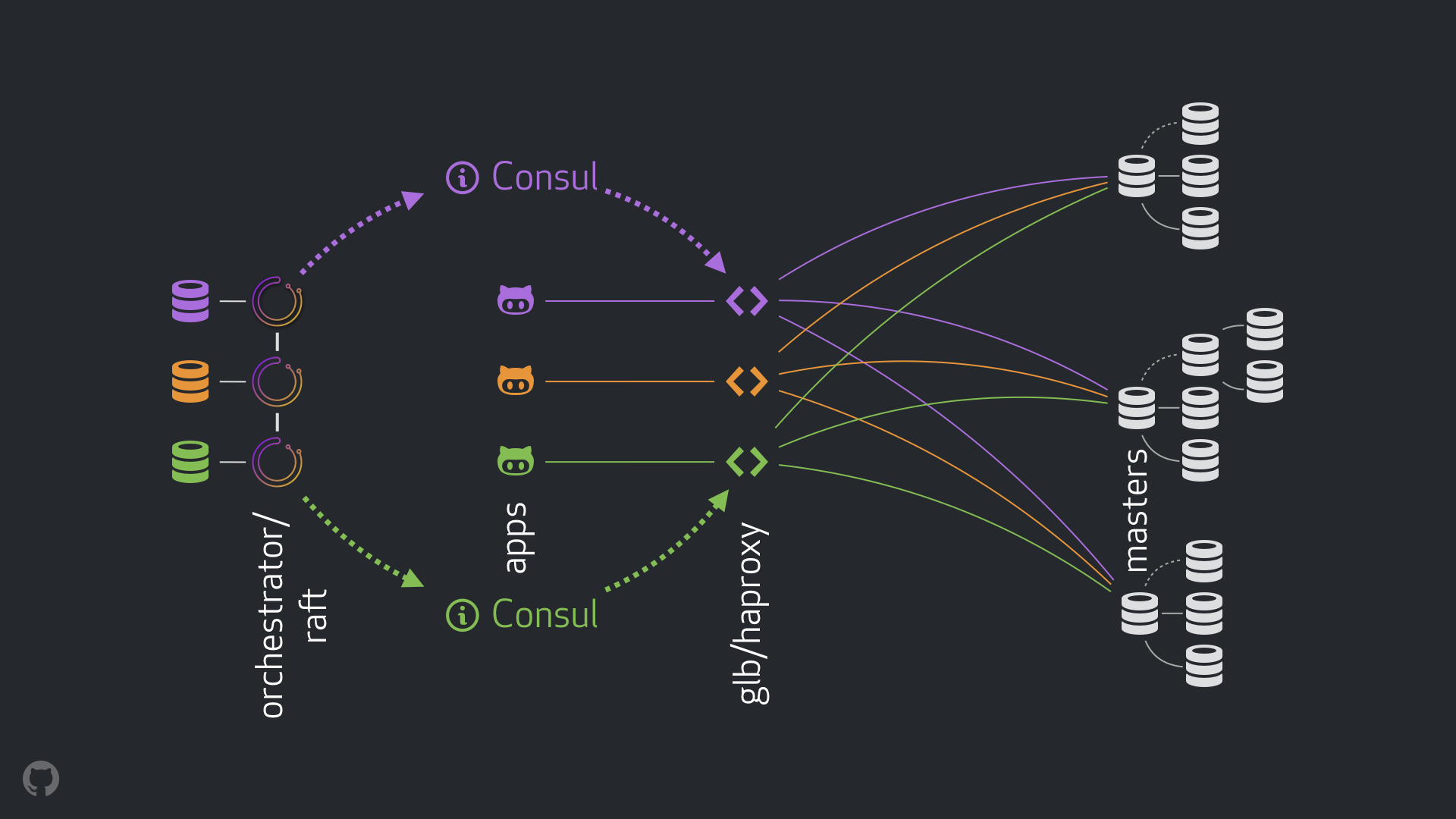
The new scheme allowed to completely abandon the changes in VIP and DNS. Now, with the introduction of new components, we can separate them and simplify the task. In addition, we were able to use reliable and stable solutions. A detailed analysis of the new solution is given below.
Normal flow
Normally, applications connect to write nodes via GLB / HAProxy.
Applications do not receive core server credentials. As before, they use only the name. For example, the master node for cluster1 would be mysql-writer-1.github.net . However, in our current configuration, this name resolves to the anycast IP address.
Thanks to anycast technology, the name is resolved to the same IP address anywhere, but traffic is sent differently, given the location of the client. In particular, several copies of GLB, our high-availability load balancer, are deployed in each of our data centers. Traffic to mysql-writer-1.github.net always directed to the GLB cluster of the local data center. Due to this, all clients are served by local proxies.
We run GLB on top of HAProxy . Our HAProxy server provides write pools : one for each MySQL cluster. Moreover, each pool has only one server (the main cluster node). All GLB / HAProxy instances in all data centers have the same pools, and they all point to the same servers in these pools. Thus, if an application wants to write data to the database on mysql-writer-1.github.net , then it does not matter to which GLB server it is connected. In any case, it will be redirected to the actual cluster1 .
For applications, detection ends in GLB, and there is no need for re-detection. It is GLB that redirects traffic to the right place.
Where does GLB get information about which servers to include in the list? How do we make changes to GLB?
Detection via Consul
Consul is widely known as a service discovery solution; in addition, it also takes over the DNS functions. However, in our case, we use it as a highly accessible storage of key values (KV).
In the KV repository in Consul, we record the identity of the main nodes of the cluster. For each cluster there is a set of KV records pointing to the data of the corresponding main node: its fqdn , port, ipv4 and ipv6 addresses.
Each GLB / HAProxy node runs a consul-template , a service that tracks changes in Consul data (in our case, changes in the data of the main nodes). The consul-template creates a configuration file and can reload HAProxy when changing settings.
Due to this, the information about changing the identity of the main node in Consul is available to each GLB / HAProxy instance. Based on this information, instance configuration is performed, new master nodes are listed as the only entity in the cluster server pool. After this, the instances are rebooted for the changes to take effect.
We deployed Consul instances at each data center, and each instance provides high availability. However, these instances are independent of each other. They do not replicate or exchange any data.
Where does Consul get information about changes and how does it spread between data centers?
orchestrator / raft
We use the orchestrator/raft scheme: orchestrator nodes interact with each other through consensus raft . We have one or two orchestrator nodes in each data center.
orchestrator is responsible for detecting failures, working out MySQL failures, and transmitting changed data on the main node to Consul. Failover is managed by one orchestrator/raft master node, but the changes , the news that the cluster now has a new master node, are propagated to all orchestrator nodes using the raft mechanism.
When the orchestrator nodes receive news of changes in the main node data, each of them communicates with its local Consul instance and initiates a KV record. A data center with multiple orchestrator instances will receive several (identical) entries in Consul.
A generalized view of the entire stream.
If the main node fails:
orchestratornodes detect failures;- The
orchestrator/rafthost initiates a restore. A new master node is assigned; - the
orchestrator/raftschema transmits data on changes in the host to all nodes in theraftcluster; - each
orchestrator/raftinstance receives a node change notification and writes the identification data of the new main node to the local KV storage in Consul; - The
consul-templateservice is launched on each GLB / HAProxy instance, which tracks changes to the KV repository in Consul, reconfigures and reloads HAProxy; - client traffic is redirected to the new master node.
For each component, responsibilities are clearly distributed, and the whole structure is diversified and simplified. orchestrator does not interact with load balancers. Consul does not require information about the origin of information. Proxy servers only work with Consul. Clients work only with proxy servers.
Moreover:
- No need to make changes to the DNS and distribute information about them;
- TTL is not used;
- The thread does not wait for responses from the master in an error state. In general, it is ignored.
Additional Information
To stabilize the flow, we also use the following methods:
- The HAProxy
hard-stop-afterparameter is set to a very small value. When HAProxy reboots with a new server in the write pool, the server automatically terminates all existing connections to the old master node.- Setting the
hard-stop-afterparameter allows you not to wait for any actions from clients; in addition, the negative consequences of the possible occurrence of two main nodes in a cluster are minimized. It is important to understand that there is no magic here, and in any case some time passes before the old connections are broken. But there is a moment in time after which we can stop waiting for unpleasant surprises.
- Setting the
- We do not require the continued availability of the Consul service. In fact, we need it to be available only during failover. If the Consul service does not respond, then GLB continues to work with the latest known values and does not take drastic measures.
- GLB is configured to verify the identity of the newly assigned head node. As with our context-sensitive MySQL pools , a check is performed to confirm that the server is truly writable. If we accidentally delete the host identity in Consul, there will be no problem, the blank entry will be ignored. If we mistakenly write the name of another server (not the main one) to Consul, then in this case it's okay: GLB will not update it and will continue to work with the last valid state.
In the following sections, we look at the problems and analyze the goals of high availability.
Crash detection with orchestrator / raft
orchestrator uses an integrated approach to fault detection, which ensures high reliability of the tool. We do not face false positive results, premature failover is not performed, which means that optional downtime is excluded.
The orchestrator/raft scheme also copes with situations of complete network isolation of the data center ("data center fencing"). Network data center isolation can be confusing: the servers inside the data center can communicate with each other. How to understand who is really isolated - the servers inside the data center or all the other data centers?
In the orchestrator/raft schema, the orchestrator/raft master node performs failover. The host becomes the host, which receives majority support in the group (quorum). We deployed the orchestrator node in such a way that no single data center can provide the majority, while any n-1 data center provides it.
In the case of a complete network isolation of the data center, orchestrator nodes in this center are disconnected from similar nodes in other data centers. As a result, orchestrator nodes in an isolated data center cannot become leading in a raft cluster. If such a node was leading, then it loses this status. A new master will be assigned one of the nodes in the other data centers. This presenter will have the support of all other data centers that can communicate with each other.
Thus, the orchestrator host will always be located outside the data center isolated from the network. If the main node was in an isolated data center, the orchestrator initiates failover to replace it with one of the available data centers. We mitigate the effects of data center isolation by delegating decisions to the quorum of available data centers.
Accelerated Alert
The total idle time can be further reduced if you speed up the notification of a change in the main node. How to achieve this?
When the orchestrator starts failover, it considers a group of servers, one of which can be designated as the main server. Given the replication rules, recommendations, and limitations, he is able to make an informed decision about the best course of action.
By the following features, he can also understand that an accessible server is an ideal candidate for being the main candidate :
- nothing prevents the server from raising its status (and, perhaps, the user recommends this server);
- It is expected that the server will be able to use all other servers as replicas.
In this case, the orchestrator first configures the server as writable and immediately announces an increase in its status (in our case it makes an entry in the KV repository in the Consul). orchestrator , .
, , GLB , , . : !
, . , , . , , , .
: 500 . . ( ), .
( ) . , .
, / pt-heartbeat / , . , pt-heartbeat , read_only , .
pt-heartbeat , . . . , pt-heartbeat .
orchestrator
orchestrator :
- Pseudo-GTID;
- , ;
- (
read_only), .
, . , , , . orchestrator .
- , , . , -, .
, .
, , , - . . STONITH . , , , «» - . , , .
: Consul , . . , , , , .
results
orchestrator/GLB/Consul :
- ;
- ;
- ;
- ;
- , ( );
- ;
10-13.20, —25.
Conclusion
«// » , , . . , .
')
Source: https://habr.com/ru/post/432088/
All Articles