Yandex opens the Cloud. New Platform Architecture

Today, Yandex.Oblako became available to everyone. Now, any user can go to Cloud and deploy the resources he needs, by gaining access to Yandex technologies. For example, to machine translation and speech recognition and synthesis.
Today I want to introduce you to Yandex. Cloud and tell you how it works inside. Under the cut you will learn a little about the history, team and architecture of our platform.
')
A bit of history
Despite the fact that the Yandex cloud platform was first publicly shown not so long ago, the project has been developing within the company for a long time and has survived several phases, and many of the technologies that formed its basis have passed the test of time in the internal infrastructure of Yandex. Development began last year, and the first external users began testing the platform in April 2018. It was a closed mode in which about 100 companies participated - web services of various sizes, SaaS developers and corporations. In September, we opened a public site, but it was possible to get to the Cloud itself only through a waiting list, and now, in December, access has become open to everyone.
At the very beginning, when a product development plan was being developed, several strategic decisions needed to be made about what characteristics the cloud should have and what technologies it should be based on: what open-ended decisions would be appropriate to use, what can be taken from the internal stack of Yandex technologies, and what will have to be developed specifically for the public platform. One of the most important issues was related to OpenStack.
By this time, a cluster of several thousand hosts on OpenStack has been successfully operating in Yandex for several years. One possible solution would be to use this technology to create the Cloud, especially since it would significantly accelerate the platform’s entry into the market. However, after many discussions and heated debates, it was decided in favor of its own design. Pros and cons argued, but the following arguments were decisive.
First of all, OpenStack is a solution for private single-tenant clouds. It has not historically been designed to build scalable multi-tenant platforms. The second point: this technology is poorly compatible with hyperconvergent architecture (when all the hardware resources form one large pool, and a virtual infrastructure is built on the basis of it). And thirdly, we have experienced all the difficulties with the support and modification of OpenStack, revealed during the operation of the cluster, and did not want to risk the customer experience of our future users. Of course, there were no unequivocal answers to the questions raised by us, but it was required to make an informed decision. The choice was made, and the platform went its own way.
Here it is worth noting the associated architectural approaches, which were also laid at the very beginning. Using a single pool of unified hardware resources is one of the principal decisions. This approach allows you to easily scale the platform and painlessly increase the number of available resources. In addition, we have determined that the platform will be built on the principle of self-hosting. That is, all cloud services, including service ones, should “live” over a single hyperconvergent infrastructure. This means that there are no dedicated management servers in Yandex. Oblak. All platform services are deployed on the same virtual machines as external users.
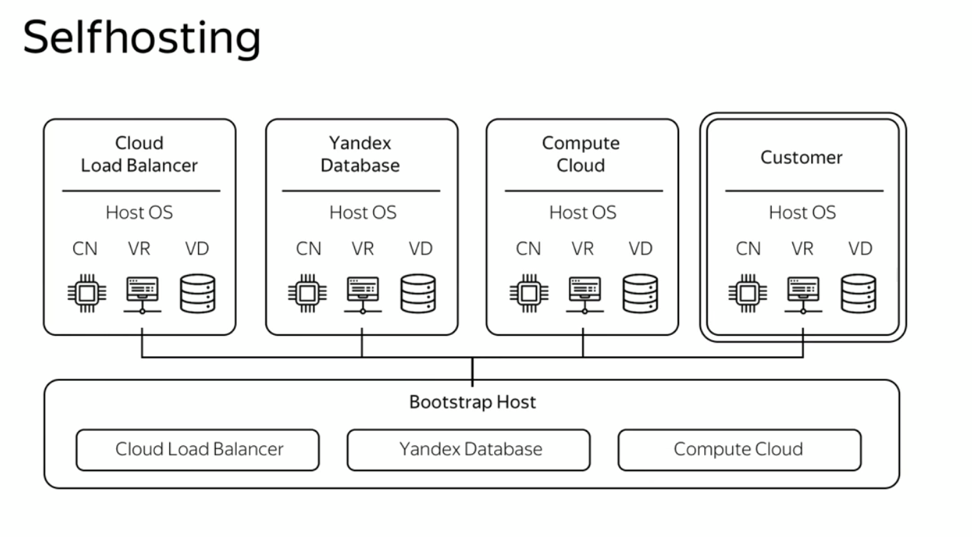
Self-hosting allows you to manage your cloud structure very flexibly and automatically connect additional infrastructure — from a single server to a data center with thousands of machines — at minimal cost. In addition, we work in the same conditions as our users, which means we can experience all client experience.
And the third principle underlying the platform: the presence of a single repository of metadata and system information for all services. For this, internal development is used - Yandex Database (YDB, not to be confused with ClickHouse), which allows you to place data very reliably, efficiently and elastic. Thus, the metadata repository has become the basic internal service for all other services of Yandex. Oblak.
You probably noticed that the basic principles of the organization of the platform are closely related to each other and in many respects define the architecture and many subsequent technological solutions. This is what gave us the opportunity to create a scalable platform that will allow us to plan the development of all existing and future Cloud services in the long term.
Architecture
In general, the architecture looks like this:

The basis of the cloud is the already mentioned shared storage metadata (storage layer). YDB using a special replication mechanism covers all the hardware storage available to the Cloud. A similar mechanism applies to network block storage (NBS). Together with YDB, they form a common data storage system, which is used by all other services in the Cloud.
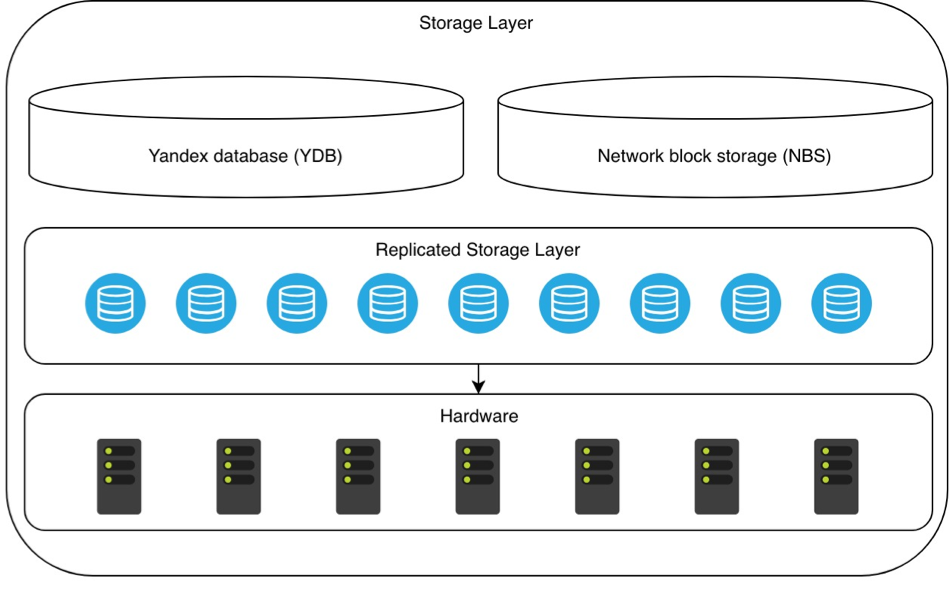
Above the repository is built Yandex Compute Cloud service . It provides the ability to manage virtual machines that are used by both external users and internal components of the platform. The hypervisor is KVM , and the emulator is QEMU . As a result, VirtIO drivers were chosen for device virtualization. An important part of the bundle of virtual machines and hardware infrastructure is the Scheduler. It is he who determines on which physical server the next virtual machine will be deployed.

Together, these components are the IaaS-part of the platform, which also includes the Yandex Virtual Private Cloud service . At the core of the network service is the open source project OpenContrail .
Another important component of this level is the snapshot mechanism. It allows you to take pictures and images of disks.

A level above - platform services, most of which are available to all users of Yandex. Cloud. These are services for managing databases in the Cloud, clusters of which are deployed in virtual machines (ClickHouse, Managed Databases for MongoDB and PostgreSQL); S3 compatible object storage ; as well as translation services and speech synthesis and recognition .
There are two more important services that cover all layers of the cloud. These are Billing and Identity and Access Management (IAM). The first is responsible for all transactions with billing and payment of consumed resources. The second implements control of access to resources based on roles (role based access control): each user can be assigned certain roles that describe the allowed operations. For example, the editor role allows you to create, delete, and edit resources, but does not allow you to control access to them.
This is a fairly general description of the device Yandex. Oblaka, but it allows you to understand how the different parts of a large platform interact with each other. If you want to understand the structure of the platform in more detail, I advise you to look at the conference recording about: cloud . Special attention at this event was paid to networks and Yandex Database.
Team
Finally - a couple of words about the team. Over the past year, it has increased significantly and continues to grow . Now it consists of more than 150 people, not counting the large number of groups that are not directly part of Yandex. Cloud, but which developments are also used in the platform. A significant part of the experts - of course, the developers. They are divided into units that are engaged in one direction or another: virtual machines, cloud databases, billing, networks, etc. There is a separate group specializing in cloud security issues and everything that is stored in it. And, of course, support, ready to quickly answer questions raised by users.
I have it all. In the near future we will publish several articles on the details of working with different services of our platform. In the meantime, you can get acquainted with Yandex. Cloud. Each new user will receive 4000 rubles to get acquainted with the platform. This amount is quite enough to place a medium-sized web project in the Cloud based on the standard LAMP bundle with the object storage of files per 1 terabyte; or in order to translate an array of data in excess of 9 million characters by connecting the machine translation to your mobile application or website.
Source: https://habr.com/ru/post/432042/
All Articles