Chain replication: building efficient KV storage (part 2/2)

We continue to consider examples of the use of chain replication. Basic definitions and architectures were given in the first part , I recommend to get acquainted with it before reading the second part.
In this article we will study the following systems:
- Hibari is a distributed, fault-tolerant repository written in erlang.
- HyperDex is a distributed key-value repository with support for fast search by secondary attributes and search by range.
- ChainReaction - Causal + consistency and geo-replication.
- Building a distributed system without using additional external monitoring / reconfiguration processes.
5. Hibari
Hibari is a distributed, fault-tolerant KV-repository written in erlang. Uses chain replication (basic approach), so achieves strict consistency. In tests, Hibari shows high performance - on two-unit servers, several thousand updates per second are achieved (requests for 1Kb)
5.1 Architecture
For posting data is used consistent hashing. The storage is based on physical and logical blocks. The physical block ( physical brick ) is a server with Linux, maybe an EC2 instance and in general a VM as a whole. Logical block ( logical brick ) is the storage instance with which the main processes of the cluster work and each block is a node of any one chain. In the example below, the cluster is configured with the placement of 2 logical blocks on each physical block and with a chain length of 2. Note that the nodes of the circuit are “smeared” across the physical blocks to increase reliability.
')
The master process (see definition in the first part) is called the Admin server .
Data is stored in “tables”, which simply serve as a division into neimspaces, each table is stored in at least one chain, and each chain stores data from only one table.
The Hibari client receives updates from the Admin server with a list of all the head and tail of all the chains (and all tables). Thus, clients know immediately which logical node to send a request to.
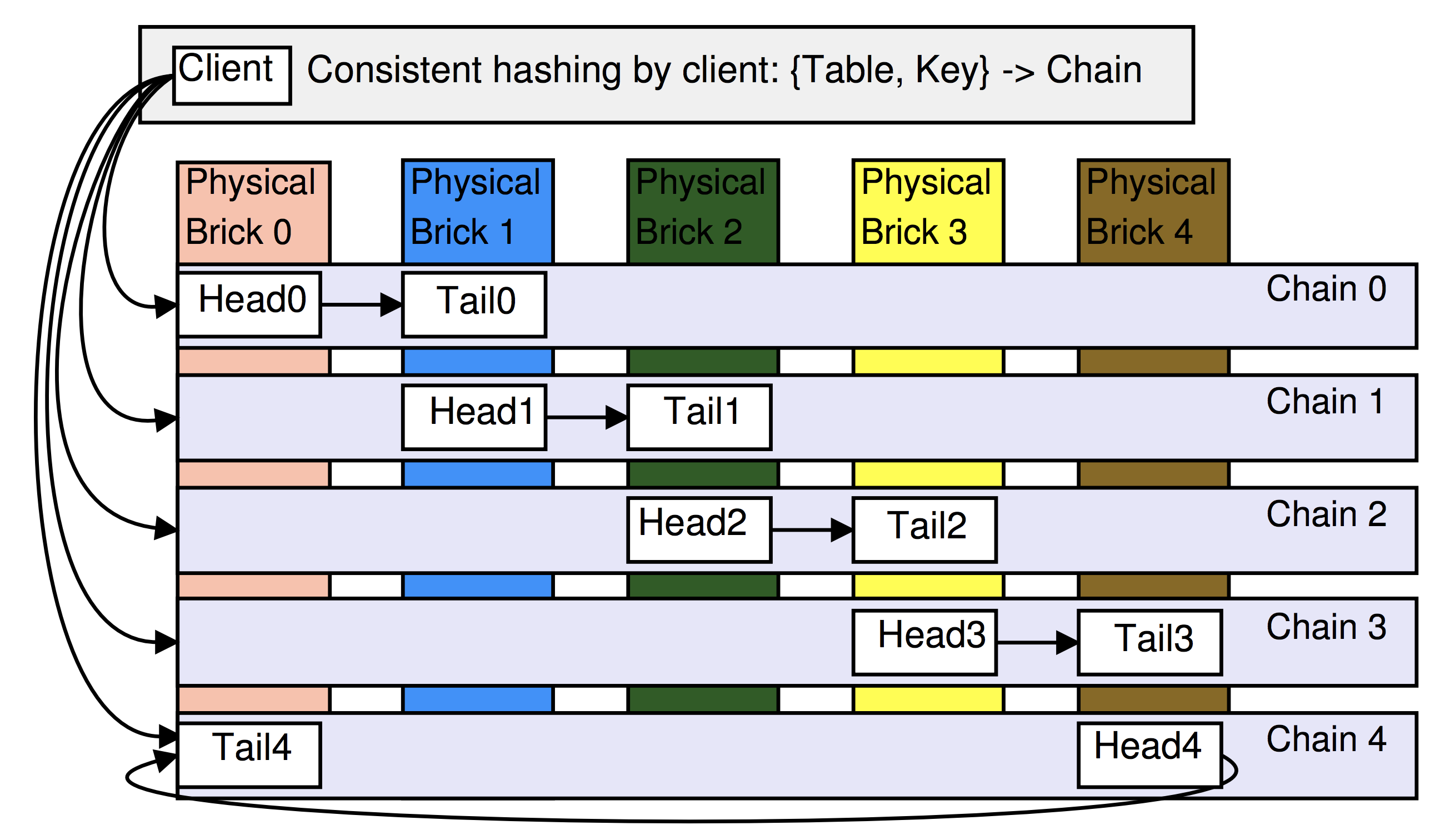
5.2 Hashing
Hibari uses a couple \ {T, K \} to determine the name of the chain that stores the key in the table : key displayed on the interval (using MD5), which is divided into sections for which any one circuit is responsible. Sections can be of different widths, depending on the "weight" of the chain, for example:

Thus, if some physical blocks are very powerful, then wider sections can be given to chains located on them (then more keys will fall on them).
6. HyperDex
The goal of this project was to build a distributed key-value store, which, unlike other popular solutions (BigTable, Cassandra, Dynamo), will support fast search by secondary attributes and will be able to quickly search by range. For example, in the previously reviewed systems, to search for all values in a certain range, one will have to go through all the servers, which is obviously unacceptable. HyperDex solves this problem using Hyperspace Hashing .
6.1 Architecture
The idea behind hyperspace hashing is to build -dimensional space where each attribute corresponds to one coordinate axis. For example, for objects (first-name, last-name, phone-number) the space might look like this:
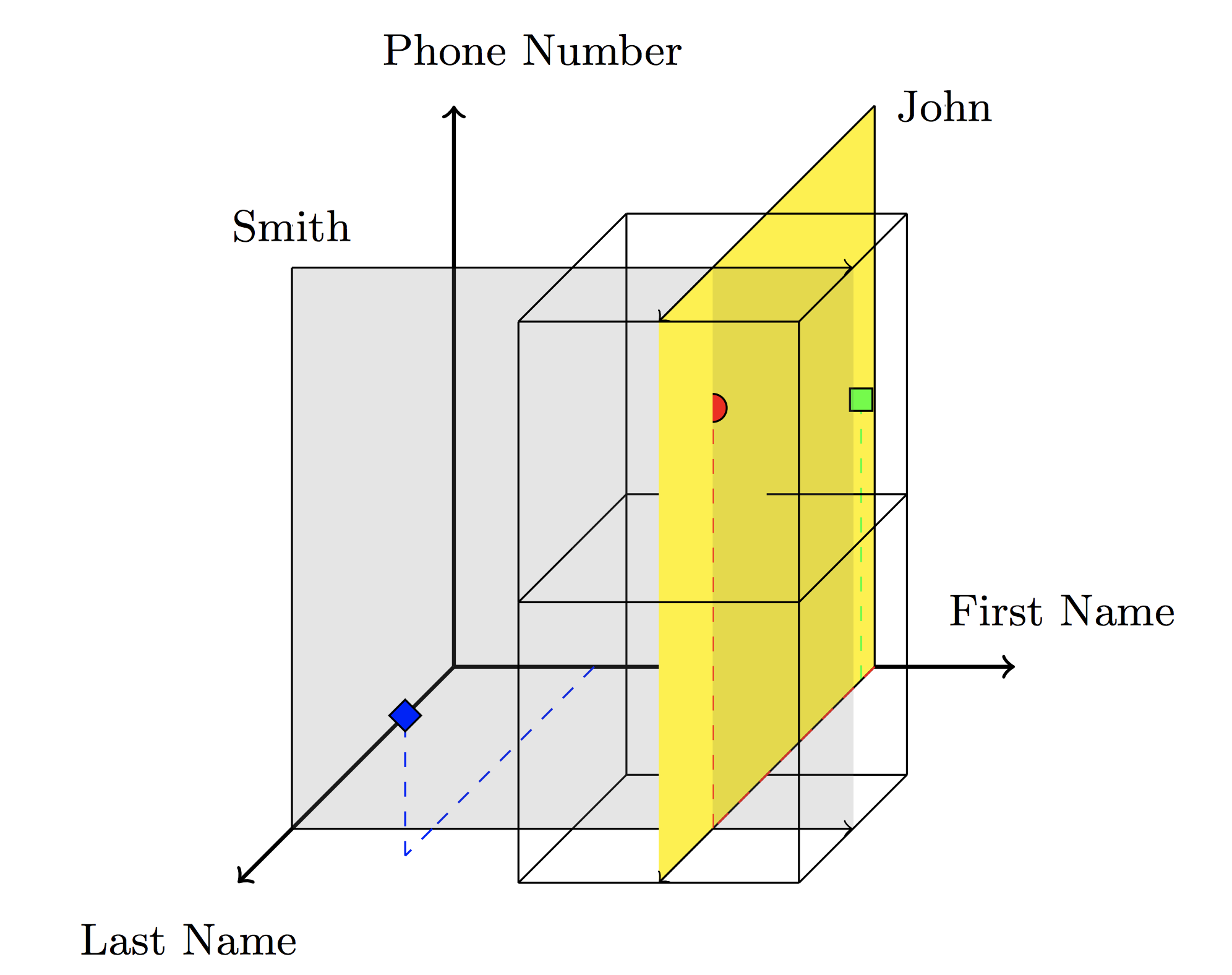
The gray hyperplane traverses all the keys, where is last-name = Smith, the yellow one goes through all the keys, where first-name = John. The intersection of these planes forms the answer to the search query phone numbers of people with the name John and the last name Smith. So the request for attribute returns -dimensional subspace.
The search space is split into -dimensional non-intersecting regions, and each region is assigned to a single server. The object with coordinates from the region is stored on the server of this region. Thus a hash is built between objects and servers.
A search query (by range) will determine the regions included in the resulting hyperplane and, thus, reduce the number of polled servers to a minimum.
In this approach, there is one problem - the number of required servers grows exponentially with the number of attributes, i.e. if attributes then need servers. To solve this problem, HyperDex uses a partition of the hyperspace into subspaces (with a smaller dimension) with, respectively, a subset of attributes:

6.2 Replication
To ensure strict consistency, the authors developed a special approach based on chain replication - value dependent chaining , where each next node is determined by hashing the corresponding attribute. For example, the key first will be hashed into the key space (we will get the head of the chain, also called point leader ), then the hash from $ inline $ "John" $ inline $ to the coordinate on the corresponding axis and so on. (See the picture below for the update example. ).
All updates go through the point leader, which orders the queries (linearizability).

If an update leads to a change in the region, then first the new version is recorded immediately after the old one (see update ), and after receiving the ACK from tail, the link to the old version from the previous server will be changed. To simultaneous requests (for example, and ) did not violate the consistency. point leader adds versioning and other meta-information to the server, in case of earlier could determine that the order is broken and you need to wait .
7. ChainReaction
The causal + convergence model is used, which adds the condition of conflict-free convergence to causal (causal) convergence. To accomplish causal convergence, metadata is added to each query, which lists the versions of all cause-dependent keys. ChainReaction allows geo-replication in several data centers and is a further development of the CRAQ idea.
7.1 Architecture
The architecture from FAWN is used with small changes - each DC consists of data servers - backends (data storage, replication, form a DHT ring) and client proxies - frontends (send a request to a specific node). Each key replicates to R consecutive nodes, forming a chain. Requests for reading are processed tail, write - head.

7.2 One data center
Note one important property resulting from chain replication - if the node causal-consistent with some client operations, then all previous nodes - too. So, if the operation was seen by us last time on site then all are causal-dependent (from ) read operations can only be performed on nodes from head to . Once will be executed on the tail - there will be no restrictions on reading. Denote the write operations that were performed tail in DC as DC-Write-Stable (d) .
Each client stores a list (metadata) of all keys requested by the client in the format (key, version, chainIndex), where chainIndex is the position of the node in the chain that responded to the last request about the key key. The metadata is stored only for keys that the client does not know whether it is DC-Write-Stable (d) or not .
7.2.1 Performing a write operation
Note that once the operation has become DC-Write-Stable (d), then no read request can read previous versions.
For each write request, a list is added of all the keys to which read operations were performed before the last write operation. As soon as the client proxy receives the request, it performs blocking read operations on the tails of all keys from the metadata (we are waiting for confirmation of the presence of the same or a newer version, in other words, we fulfill the causal consistency condition). Once confirmations are received, the write request is sent to the head of the corresponding circuit.

As soon as the new value is stored on chain nodes, the notification is sent to the client (with the index of the last node). The client updates chainIndex and removes the metadata of the sent keys, since it became known about them that they are DC-Write-Stable (d). Parallel to this, the recording continues further - lazy propagation . Thus, priority is given to write operations at first. knots. As soon as tail saves the new version of the key, the notification is sent to the client and transmitted to all nodes in the chain so that they mark the key as stable.
7.2.2 Performing a read operation
The client proxy sends a read request to node in the chain, while distributing the load. In response, the node sends the value and version of this value. The response is sent to the client, with:
- If the version is stable, then the new chainIndex is equal to the size of the chain.
- If the version is newer, then the new chainIndex = index.
- Otherwise chainIndex does not change.
7.2.3 Processing node failures
Almost completely identical to the basic approach, with some differences in that in some cases the chainIndex on the client becomes invalid - this is easily determined when executing queries (there is no key with this version) and the request is redirected to the head of the chain to find the node with the desired version.
7.3 Several ( a) data centers (geo-replication)
Let's take as a basis the algorithms from the single-server architecture and adapt them to a minimum. To begin with, in the metadata, instead of just the version and chainIndex values, we will need versioned vectors of dimensions N.
Define Global-Write-Stable in a similar way with DC-Write-Stable (d) - the write operation is considered Global-Write-Stable if it was performed on the tails in all DCs.
Each DC has a new component - remote_proxy , its task is to receive / send updates from other DCs.
7.3.1 Performing a write operation (on the server )
The beginning is similar to the single-server architecture - we perform blocking reads, write to the first chain nodes. At this point, the client proxy sends the client a new vector chainIndex, where zeros are everywhere, except for the position - there is meaning . Further - as usual. Additional operation at the very end - the update is sent to remote_proxy, which accumulates several requests and then sends everything.
There are two problems here:
- How to ensure dependencies between different updates coming from different DCs?
Each remote_proxy stores a local version vector. dimensions which stores the number of sent and received updates, and sends it in each update. Thus, when receiving an update from another DC, remote_proxy checks the counters, and if the local counter is smaller, the operation is blocked until the corresponding update is received. - How to provide dependencies for this operation in other DC?
This is achieved using a bloom filter. When performing write / read operations from the client proxy, in addition to the metadata, a bloom filter is also sent to each key (called response filters). These filters are stored in the AccessedObjects list, and, when requesting write / read operations, the OR is also sent to the metadata using the filters sent by the keys (called a dependency filter). Similarly, after the write operation is completed, the corresponding filters are deleted. When sending a write operation to another DC, a dependency filter and response filter of this request are also sent.
Further, the remote DC, having received all this information, checks - if the set bits of the response filter coincide with the set bits of several query filters - then such operations are potentially casual-dependent. Potentially - because the bloom filter.
7.3.2 Performing a read operation
Similarly, a single-server architecture, adjusted for using the vector chainIndex instead of a scalar and the possibility of missing a key in a DC (because updates are asynchronous), then either wait or redirect the request to another DC.
7.3.3 Conflict Resolution
Thanks to the metadata, causal-dependent operations are always performed in the correct order (sometimes you have to block the process for this). But competitive changes in different DC can lead to conflicts. To resolve such situations, Last Write Wins is used, for which a pair is present in each update operation. where - clock on proxy, and - id DC.
7.3.4 Handling node failures
Similar to single-server architecture.
8. Leveraging Sharding in the Design of Scalable Replication Protocols
The aim of the study is to build a distributed system with shards and with replication without using an external master process to reconfigure / monitor the cluster.
In the main current approaches, the authors see the following disadvantages:
Replication:
- Primary / Backup - causes a state to diverge if the Primary was mistakenly identified as failed.
- Quorum Intersection - may cause a state to diverge during cluster reconfiguration.
Strict consistency:
- Protocols rely on majority-choice voting (for example, Paxos), where required knots for keeping fall knots.
Detection of node failures:
- P / B and CR implies the presence of perfect detection of failed nodes with the fail-stop model, which in practice is unattainable and one has to choose a satisfying scan interval.
- ZooKeeper is subject to the same problems - with a large number of clients, a significant amount of time (> 1 second) is required for them to update the configuration.
The approach proposed by the authors, called Elastic replication , is devoid of these shortcomings, and has the following characteristics:
- Strict consistency.
- To withstand the fall nodes must have knot.
- Reconfiguration without losing consistency.
- There is no need for consensus protocols based on majority voting.
Summary plate:

8.1 Organization of replicas
On each shard the sequence of configurations is determined. for example, the new configuration does not contain any fallen cue
Each element of the configuration sequence consists of:
- replicas - a set of replicas.
- orderer - replica id with a special role (see below).
Each shard is represented by a set of replicas (by construction - ), so we do not divide into roles “shard” and “cue”.
Each replica stores the following data:
- conf is the id of the configuration to which this replica belongs.
- orderer - which replica is the orderer of this configuration.
- mode - replica mode, one of the three: (all replicas from non- ), (all replicas from ), .
- history - the sequence of operations on the actual replica data (or just state).
- stable - the maximum length of the history prefix that is fixed by this replica. It's obvious that .
The main task of the replica orderer is to send requests to the rest of the replicas and support the largest history prefix:

8.2 Organization of shards
Shards are combined into rings called elastic bands . Each shard belongs to only one ring. Predecessor of every shard performs a special role - it is a sequencer for it. The task of the sequencer is to issue its successor a new configuration in case of replica failures.

Two conditions are required:
- Each elastic band has at least one shard and one working replica.
- In each elastic band there is at least one shard, which has all the replicas - workers.
The second condition seems too strict, but it is equivalent to the “traditional” condition that the master process never falls.
8.3 Using Chain replication
As you might have guessed, the replicas are organized as a chain (basic approach) - the orderer will be the head, with some differences:
- In case of failure in the CR node is thrown out of the chain (and replaced with a new one), in the ER a new chain is created.
- Read requests in CR are processed by tail, in ER - they go through the whole chain in the same way as write requests.
8.5 Reconfiguration in case of failure
- Replicas are monitored as replicas of their shard, and replicas of sequencer shard.
- As soon as a failure is detected, a command is sent by the remarks about it.
- Sequencer sends new configuration (without failed replica).
- A new replica is created, which synchronizes its state with the elastic band.
- After that, sequencer sends a new configuration with the added replica.
Links
Source: https://habr.com/ru/post/432020/
All Articles