How does artificial intelligence help work with legal documents? Lecture of Egor Budnikov from ABBYY
Recently, a systems analyst at the technology department of ABBYY, Yegor Budnikov, spoke at Yandex at the Data & Science: Law and Records Management conference. He told how computer vision works, text processing takes place, what is important to pay attention to when extracting information from legal documents and much more.
- A company may have developed data analysis methodologies and electronic document flow, while documents created in Word can be sent from clients or from neighboring departments to the company, printed, scanned and brought to the flash drive.
What to do with the document flow, which is now, with “dirty” documents, with paper storage, to the extent that documents can be stored up to 70 years before they are scanned and must be recognized?
')

ABBYY develops artificial intelligence technologies for business. Artificial intelligence should be able to do roughly the same thing that a person does in everyday or professional activities, namely: read a picture of a real world from a picture or a stream of pictures. This can be not only computer vision, but also hearing or data recognition from sensors, for example from smoke or temperature sensors. Further data from these sensors enter the system and must be involved in the decision making. To successfully implement this function, the system must avoid stupid logical errors, as in the picture:

Texts are difficult to analyze: the diversity and development of the language make them beautiful and expressive, but this complicates the task of their automatic processing. Usually, the ambiguity of words is overcome by the fact that by context we can determine what a particular word means, but sometimes the context leaves room for interpretations. In the phrase “ These types of steel are in stock ” in the context it is impossible to understand with absolute accuracy: whether it is people who have lunch in the room, or whether they are some types of steel that are stored in the warehouse. In order to resolve this ambiguity, a broader context is needed.
 The lower part of the collage - a frame from the film "Operation" Y "and other adventures of Shurik.
The lower part of the collage - a frame from the film "Operation" Y "and other adventures of Shurik.
In the general case, artificial intelligence or a smart robot must be able to move in space and successfully interact with objects — for example, lift the box over and over again, which the instructor knocks out of his hands.
Finally, general intelligence and knowledge representation: knowledge differs from information, including the fact that its parts actively interact with each other, generating new knowledge. In order to effectively solve the problem of mixing cocktails, you can go a simple way: list the ingredients and specify the order in which to mix them. In this case, the system will not be able to answer arbitrary questions about the subject of its interest. For example, what happens if you replace tomato juice with pineapple. In order for the system to take a deeper hold of the material, databases, taxonomies (concept trees, logically connected with each other), the procedure of inference must be added. In this case, we can really say that the system understands what it does, and it will be able to answer an arbitrary question about the process.
The artificial intelligence that ABBYY develops processes documents, that is, turns paper, scanned and electronic media into structured information extracted from these documents. Let us dwell on two components, such as computer vision and word processing. Computer vision allows you to turn PDF, scanned images, images into editable text formats. Why is this task difficult? Firstly, documents can have an arbitrary structure.
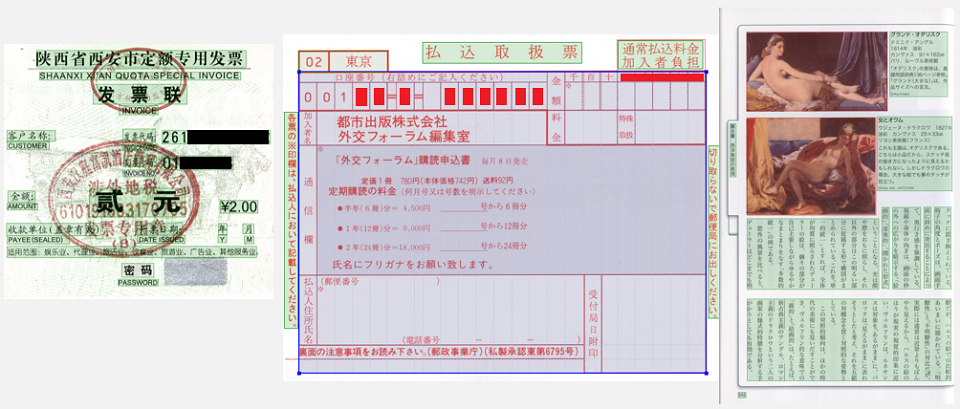
This means that you first need to solve the problem of structural analysis of documents: understand where the text blocks, pictures, tables, lists are located, and then determine how they interact with each other. Secondly, the documents may be in different languages. This means that it is necessary to support the detection of different types of writing and the ability to recognize words and symbols that may be very different from each other. Third, images come to us from the real world, which means that anything can happen to them. They can be distorted, photographed with the wrong perspective, they may be stains from coffee, stripes from the printer and then from the scanner. With all this you need to somehow cope in order to subsequently extract information.
How does image recognition work with us? At the first stage, we receive and process images. The document is aligned, correcting distortions. Then the page structure is analyzed, at this stage the block types are found and determined. When the blocks are defined, the lines or columns are aligned, you can divide these lines into words and symbols — for example, by vertical and horizontal histograms of black distribution.
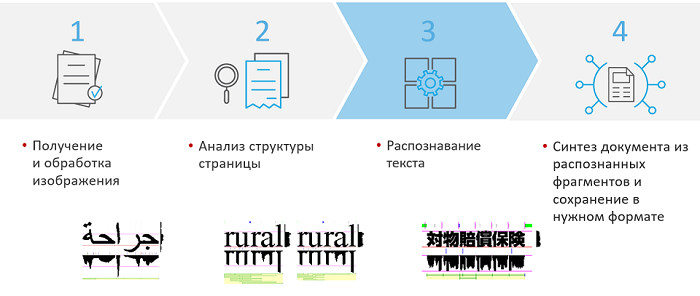
Thus, it is possible to determine where the boundaries of characters and words are, and then recognize what these characters and words are. Finally, the recognized blocks are synthesized into single text documents and exported.
This process can be viewed from the point of view of entities at different levels. First we have a document that is paginated. Then these pages need to be divided into blocks, blocks into lines, lines into words, words into characters, and then these characters need to be recognized. After that we collect the recognized characters into words, words into lines, lines into blocks, blocks into pages, pages into a document. In this case, on the return trip, the initial splitting may change. The simplest example is if the initially broken blocks belonged to the same numbered list, it means that they should eventually belong to the same block with the “structured list” type. In other words, neighboring stages can influence each other in order to improve the quality of recognition.
The document was recognized, then you need to extract information from it. Documents can be divided into more structured and less structured. Business cards, checks, invoices are more structured. The less structured are powers of attorney, statutes, articles in journals. If the document type is fixed, it is more or less structured and the documents inside this type do not differ much from each other in structure, you can apply methods that learn to directly extract the necessary attributes from a text document using text and graphic features. For example, using recurrent neural networks, you can extract items from invoices. Invoices are documents in which items of goods and a description of methods of payment for these goods are presented.

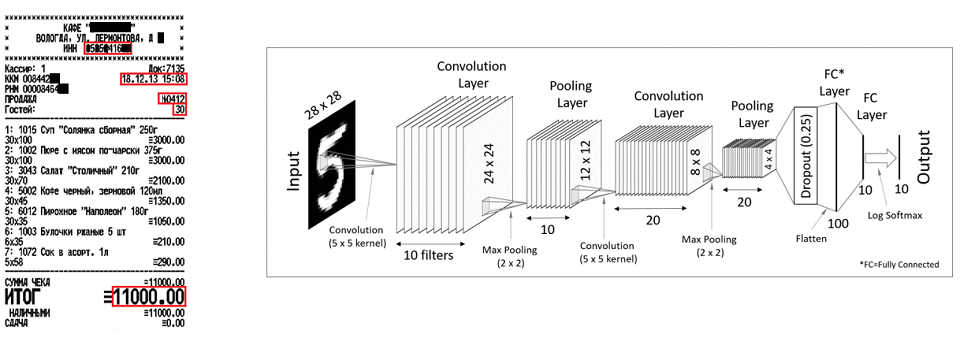
Another example is checks. With the help of convolutional neural networks, it is possible to extract single attributes, such as TIN, check number, date-time, final score. Frankly speaking, both those and other methods are used in checks and invoices, but for different purposes. Convolutional neural networks are good for single attributes that have a position, and recurrent networks for repeatable elements.
If the documents are less structured, the methods of natural language processing, natural language processing, or NLP come into play. Why is it difficult? I have already spoken about the ambiguity of words. The word address, for example, can mean the address of a company, or it can mean its obligations to solve some problems of the customer.

Also, texts are often omitted, but words are implied. In order to extract information, you need to recover these missing words. This effect in linguistics is called “ellipsis”.
Language is diverse, and there are usually countless ways to express the same thought. In order to automatically process texts, you need to somehow reduce this variation: use synonyms and similar constructions to replace one word or expression; word permutation or grammatical voice change. For example, “companies entered into an agreement” and “an agreement was concluded between companies” in order to say the same thing. In the case of synonyms, you can enter the so-called semantic space, a vector space in which words are represented as dots. Near points denote similar concepts, distant points denote more distant concepts. To reduce the variability of formulations, you can enter syntactic and semantic parse trees. In this case, a similar problem is also solved, and the algorithm for extracting information is capable of extracting information, even if it encounters constructions or words that have not previously been encountered in the training set.
How is the extraction of information? At the first stage the lexical analysis of the document is made. The text is divided into paragraphs, paragraphs into sentences, sentences into words. This may be non-trivial: those of you who are familiar with NLP may know that even such a seemingly simple task, like breaking up the text into sentences, can be difficult: dots do not always mean the end of a sentence. These may be unknown abbreviations, so in lexical analysis we try to sort through all possible options for splitting sentences into words and leave the most probable ones. As a rule, we encounter this problem in languages in which there are few or no gaps, such as Japanese or Chinese. Either have a rich word formation. This, for example, is a language like German: there are very long words in it, which consist of several words (such words are called composites). Also for all these words all possible interpretations are calculated. For example, if the text contains “g” with a dot, it can mean a lot: city, year, gram, lord, and even the fourth point (a, b, c, d).

Then segmentation is performed, that is, the search for sections of interest. It is produced for various reasons, for example, to speed up the processing of a document or to find information that interests us; to find some piece of the document, which refers to the responsibilities of the party. Either this is the acceleration of processing, for example, our document may consist of several tens or even hundreds of pages in especially neglected cases, and interesting information is contained only in a few pages. Segmentation allows you to find these interesting pieces and analyze only them. Then the semantic analysis of the document may or may not be done, it depends on the task, and at this stage the search for the best interpretations of the sentences, all the sentences of the document or only those that we found in the previous step is performed. Also generated semantic features for the classifier in the next step.
Finally, the stage of direct extraction of attributes. Here, machine-trained models are used or simple templates are written. One way or another, they rely on the signs generated by the previous stages. These are structural features, both lexical and semantic. Depending on the complexity of the task, we use many different methods: machine learning methods and methods for writing templates. At this stage, we are looking for the attributes we are interested in. These may be the names of the parties, obligations, date of signing, etc.
Finally, some attributes may require post-processing. Reduction to normal form or casting to the date template. Some attributes can be calculated in principle, they are not extracted from the contract, but calculated on the basis of those attributes that are extracted from the contract. For example, the duration of the contract on the basis of the beginning of the action and its termination.
Consider this in one of the scenarios, it is called “Opening an account by a legal entity”. What is the challenge? A legal entity comes to the bank, or, more precisely, its representative, and brings a hefty stack of documents. In a good case, he has already scanned these documents, but it is not clear with what quality. In order to optimize the process, reduce the number of errors in entering this information into the system, speed up the process and, consequently, speed up the decision making and increase customer loyalty, the following scheme was proposed:
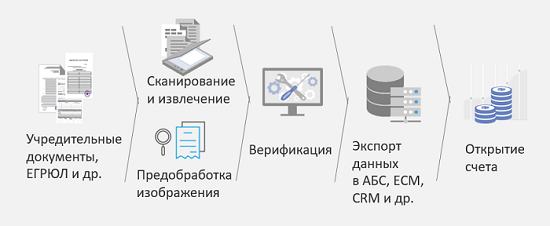
The constituent documents, which include a lot of different types, are scanned first, then they are recognized. After recognition, they are classified according to different types, and depending on the type, different algorithms can be used to recognize and extract information. Then this extracted information, if necessary, is sent to people for verification, and after that it is already possible to make a decision: open an account, or need some other additional documents. The main result of this decision is to cut the cost by half of data entry when opening an account. Results based on measurements of our client.
What attributes need to be extracted? A lot of things. Suppose we have a charter at the entrance. First we recognize it. As we remember, this can be quite problematic if it is a scan or a photo. Then we define the type of the document, and this is important, because the information we need may be contained in some specific chapter or sub-paragraph, and therefore the knowledge of when this chapter or sub-paragraph begins or ends helps the information extraction algorithm.

The machine then retrieves all the underlying entities it can reach:
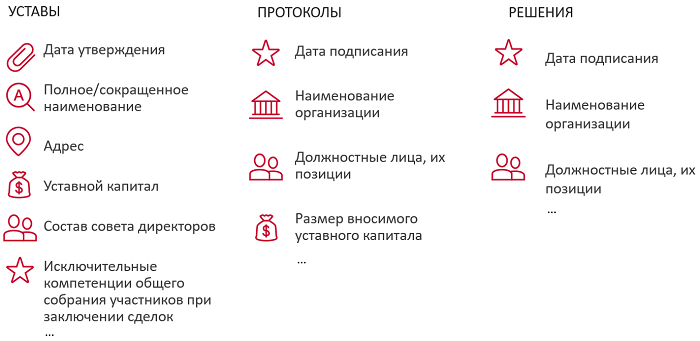
This is necessary so that in the next step of extracting attributes or defining roles, the algorithm can use not only the context, but also the features that were generated in the previous steps. For example, it can greatly simplify the task of determining who is the director of a legal entity, the information that this is a person. Accordingly, among the set of persons that are found in the document, we must classify them, the director is or not the director. When we have a limited number of objects, this greatly simplifies the task.
Over the past two years, we have faced several other clients' tasks and successfully solved them. For example, media monitoring for corporate risks.
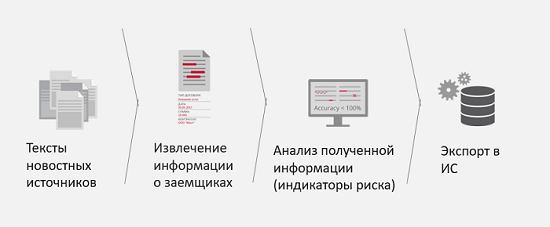
What is the business problem here? For example, you have a potential partner or customer who wants to take a loan from you. In order to speed up the processing of this client's data and reduce the risks of a bad partnership, or the future bankruptcy of this legal entity, it is proposed to monitor the media for the presence of references to this individual or legal entity there and for the presence of so-called risk indicators in the news. That is, if, for example, it constantly emerges in the news that a legal entity is involved in legal proceedings or a company is torn up by shareholders conflicts, it is better to find out about this early in order to pass this information to analysts or the analytical system and understand how bad or good it is for your business. . The result of this task is to obtain more complete and accurate information about the borrower, and also reduces the amount of time to receive this information.

Another application example in which it is necessary to reduce the amount of routine and the number of errors when entering information into the system is to extract data from contracts. It is proposed to recognize agreements, extract information from them and send it immediately to the system. After this, the personnel department gives you a tearful thanks and warm welcome at every meeting.

Not only the personnel department suffers from a large amount of routine work with incoming documentation, but also the accounting department, sales departments, and purchasing departments also suffer. Employees have to spend a lot of time entering information from invoices, incoming acts, and so on.

In fact, all these documents are structured, and therefore it is easy to recognize them and extract information from them. Data entry speed increases up to 5 times, and at the same time the number of errors decreases, because the human factor is excluded. Conditionally, if the employee returned after lunch, he may begin to enter data inattentively. Our own measurements and the industry, which in one way or another is engaged in manual entry of information into the system, says that if a person enters data from a document, and does so on a regular basis and in a stream, he rarely gets more than 95% quality, and more and more than 90%. Therefore, for a person you need to recount, recheck even more than the machine.
Moreover, if the machine gives some estimate of confidence that it has not extracted - for example, some document may be dirty - and the machine is not sure that it has extracted it, but it can signal the verifier that he is not very sure of this result. : "Please recheck." And the person rechecks the individual information so that it is of high quality. This is not such a routine operation: he checks only really important and difficult moments, his eyes are not blurred.
If information can be extracted from documents, this information can also be compared.
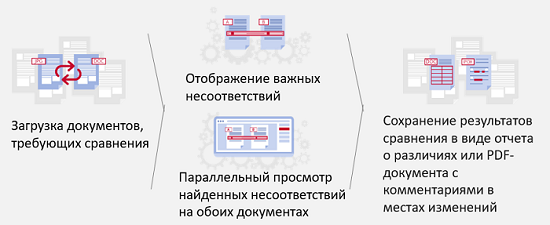
This is important in two cases. First, to compare different versions of the same document, for example, a contract that is consistent for a long time, it is constantly being edited on both sides. Secondly, this is a comparison of documents of different types, for example, if there is a contract that indicates that we should receive from our partner, on the other hand, there are different invoices and reports, estimates, etc. We need to relate them and understand that everything is in order, and if not in order, then somehow signal this to the responsible people.
The current development of technology in computer vision, processing of structured and unstructured documents is so high that even now and in the coming years, digital transformation of routine processes in companies will be felt, because it is cheaper, faster and often better.
At the same time, all these methods are by no means intended to replace people. Rather, I like the example of comparison with the Excel tool, in which you can do a lot and this tool is not intended to replace neither analysts, nor managers, nor anyone else. It is intended to expand human capabilities and simplify the solution of problems for him.

Thus, solutions related to artificial intelligence are also designed to reduce the number of repetitive routine operations in which a person often makes more mistakes than a machine to unload company resources and direct them to solving more creative and intellectual tasks. And it seems that we are moving there at full speed. Thank.
- A company may have developed data analysis methodologies and electronic document flow, while documents created in Word can be sent from clients or from neighboring departments to the company, printed, scanned and brought to the flash drive.
What to do with the document flow, which is now, with “dirty” documents, with paper storage, to the extent that documents can be stored up to 70 years before they are scanned and must be recognized?
')
ABBYY develops artificial intelligence technologies for business. Artificial intelligence should be able to do roughly the same thing that a person does in everyday or professional activities, namely: read a picture of a real world from a picture or a stream of pictures. This can be not only computer vision, but also hearing or data recognition from sensors, for example from smoke or temperature sensors. Further data from these sensors enter the system and must be involved in the decision making. To successfully implement this function, the system must avoid stupid logical errors, as in the picture:
Texts are difficult to analyze: the diversity and development of the language make them beautiful and expressive, but this complicates the task of their automatic processing. Usually, the ambiguity of words is overcome by the fact that by context we can determine what a particular word means, but sometimes the context leaves room for interpretations. In the phrase “ These types of steel are in stock ” in the context it is impossible to understand with absolute accuracy: whether it is people who have lunch in the room, or whether they are some types of steel that are stored in the warehouse. In order to resolve this ambiguity, a broader context is needed.
In the general case, artificial intelligence or a smart robot must be able to move in space and successfully interact with objects — for example, lift the box over and over again, which the instructor knocks out of his hands.
Finally, general intelligence and knowledge representation: knowledge differs from information, including the fact that its parts actively interact with each other, generating new knowledge. In order to effectively solve the problem of mixing cocktails, you can go a simple way: list the ingredients and specify the order in which to mix them. In this case, the system will not be able to answer arbitrary questions about the subject of its interest. For example, what happens if you replace tomato juice with pineapple. In order for the system to take a deeper hold of the material, databases, taxonomies (concept trees, logically connected with each other), the procedure of inference must be added. In this case, we can really say that the system understands what it does, and it will be able to answer an arbitrary question about the process.
The artificial intelligence that ABBYY develops processes documents, that is, turns paper, scanned and electronic media into structured information extracted from these documents. Let us dwell on two components, such as computer vision and word processing. Computer vision allows you to turn PDF, scanned images, images into editable text formats. Why is this task difficult? Firstly, documents can have an arbitrary structure.
This means that you first need to solve the problem of structural analysis of documents: understand where the text blocks, pictures, tables, lists are located, and then determine how they interact with each other. Secondly, the documents may be in different languages. This means that it is necessary to support the detection of different types of writing and the ability to recognize words and symbols that may be very different from each other. Third, images come to us from the real world, which means that anything can happen to them. They can be distorted, photographed with the wrong perspective, they may be stains from coffee, stripes from the printer and then from the scanner. With all this you need to somehow cope in order to subsequently extract information.
How does image recognition work with us? At the first stage, we receive and process images. The document is aligned, correcting distortions. Then the page structure is analyzed, at this stage the block types are found and determined. When the blocks are defined, the lines or columns are aligned, you can divide these lines into words and symbols — for example, by vertical and horizontal histograms of black distribution.
Thus, it is possible to determine where the boundaries of characters and words are, and then recognize what these characters and words are. Finally, the recognized blocks are synthesized into single text documents and exported.
This process can be viewed from the point of view of entities at different levels. First we have a document that is paginated. Then these pages need to be divided into blocks, blocks into lines, lines into words, words into characters, and then these characters need to be recognized. After that we collect the recognized characters into words, words into lines, lines into blocks, blocks into pages, pages into a document. In this case, on the return trip, the initial splitting may change. The simplest example is if the initially broken blocks belonged to the same numbered list, it means that they should eventually belong to the same block with the “structured list” type. In other words, neighboring stages can influence each other in order to improve the quality of recognition.
The document was recognized, then you need to extract information from it. Documents can be divided into more structured and less structured. Business cards, checks, invoices are more structured. The less structured are powers of attorney, statutes, articles in journals. If the document type is fixed, it is more or less structured and the documents inside this type do not differ much from each other in structure, you can apply methods that learn to directly extract the necessary attributes from a text document using text and graphic features. For example, using recurrent neural networks, you can extract items from invoices. Invoices are documents in which items of goods and a description of methods of payment for these goods are presented.
Another example is checks. With the help of convolutional neural networks, it is possible to extract single attributes, such as TIN, check number, date-time, final score. Frankly speaking, both those and other methods are used in checks and invoices, but for different purposes. Convolutional neural networks are good for single attributes that have a position, and recurrent networks for repeatable elements.
If the documents are less structured, the methods of natural language processing, natural language processing, or NLP come into play. Why is it difficult? I have already spoken about the ambiguity of words. The word address, for example, can mean the address of a company, or it can mean its obligations to solve some problems of the customer.
Also, texts are often omitted, but words are implied. In order to extract information, you need to recover these missing words. This effect in linguistics is called “ellipsis”.
Language is diverse, and there are usually countless ways to express the same thought. In order to automatically process texts, you need to somehow reduce this variation: use synonyms and similar constructions to replace one word or expression; word permutation or grammatical voice change. For example, “companies entered into an agreement” and “an agreement was concluded between companies” in order to say the same thing. In the case of synonyms, you can enter the so-called semantic space, a vector space in which words are represented as dots. Near points denote similar concepts, distant points denote more distant concepts. To reduce the variability of formulations, you can enter syntactic and semantic parse trees. In this case, a similar problem is also solved, and the algorithm for extracting information is capable of extracting information, even if it encounters constructions or words that have not previously been encountered in the training set.
How is the extraction of information? At the first stage the lexical analysis of the document is made. The text is divided into paragraphs, paragraphs into sentences, sentences into words. This may be non-trivial: those of you who are familiar with NLP may know that even such a seemingly simple task, like breaking up the text into sentences, can be difficult: dots do not always mean the end of a sentence. These may be unknown abbreviations, so in lexical analysis we try to sort through all possible options for splitting sentences into words and leave the most probable ones. As a rule, we encounter this problem in languages in which there are few or no gaps, such as Japanese or Chinese. Either have a rich word formation. This, for example, is a language like German: there are very long words in it, which consist of several words (such words are called composites). Also for all these words all possible interpretations are calculated. For example, if the text contains “g” with a dot, it can mean a lot: city, year, gram, lord, and even the fourth point (a, b, c, d).
Then segmentation is performed, that is, the search for sections of interest. It is produced for various reasons, for example, to speed up the processing of a document or to find information that interests us; to find some piece of the document, which refers to the responsibilities of the party. Either this is the acceleration of processing, for example, our document may consist of several tens or even hundreds of pages in especially neglected cases, and interesting information is contained only in a few pages. Segmentation allows you to find these interesting pieces and analyze only them. Then the semantic analysis of the document may or may not be done, it depends on the task, and at this stage the search for the best interpretations of the sentences, all the sentences of the document or only those that we found in the previous step is performed. Also generated semantic features for the classifier in the next step.
Finally, the stage of direct extraction of attributes. Here, machine-trained models are used or simple templates are written. One way or another, they rely on the signs generated by the previous stages. These are structural features, both lexical and semantic. Depending on the complexity of the task, we use many different methods: machine learning methods and methods for writing templates. At this stage, we are looking for the attributes we are interested in. These may be the names of the parties, obligations, date of signing, etc.
Finally, some attributes may require post-processing. Reduction to normal form or casting to the date template. Some attributes can be calculated in principle, they are not extracted from the contract, but calculated on the basis of those attributes that are extracted from the contract. For example, the duration of the contract on the basis of the beginning of the action and its termination.
Consider this in one of the scenarios, it is called “Opening an account by a legal entity”. What is the challenge? A legal entity comes to the bank, or, more precisely, its representative, and brings a hefty stack of documents. In a good case, he has already scanned these documents, but it is not clear with what quality. In order to optimize the process, reduce the number of errors in entering this information into the system, speed up the process and, consequently, speed up the decision making and increase customer loyalty, the following scheme was proposed:
The constituent documents, which include a lot of different types, are scanned first, then they are recognized. After recognition, they are classified according to different types, and depending on the type, different algorithms can be used to recognize and extract information. Then this extracted information, if necessary, is sent to people for verification, and after that it is already possible to make a decision: open an account, or need some other additional documents. The main result of this decision is to cut the cost by half of data entry when opening an account. Results based on measurements of our client.
What attributes need to be extracted? A lot of things. Suppose we have a charter at the entrance. First we recognize it. As we remember, this can be quite problematic if it is a scan or a photo. Then we define the type of the document, and this is important, because the information we need may be contained in some specific chapter or sub-paragraph, and therefore the knowledge of when this chapter or sub-paragraph begins or ends helps the information extraction algorithm.
The machine then retrieves all the underlying entities it can reach:
This is necessary so that in the next step of extracting attributes or defining roles, the algorithm can use not only the context, but also the features that were generated in the previous steps. For example, it can greatly simplify the task of determining who is the director of a legal entity, the information that this is a person. Accordingly, among the set of persons that are found in the document, we must classify them, the director is or not the director. When we have a limited number of objects, this greatly simplifies the task.
Over the past two years, we have faced several other clients' tasks and successfully solved them. For example, media monitoring for corporate risks.
What is the business problem here? For example, you have a potential partner or customer who wants to take a loan from you. In order to speed up the processing of this client's data and reduce the risks of a bad partnership, or the future bankruptcy of this legal entity, it is proposed to monitor the media for the presence of references to this individual or legal entity there and for the presence of so-called risk indicators in the news. That is, if, for example, it constantly emerges in the news that a legal entity is involved in legal proceedings or a company is torn up by shareholders conflicts, it is better to find out about this early in order to pass this information to analysts or the analytical system and understand how bad or good it is for your business. . The result of this task is to obtain more complete and accurate information about the borrower, and also reduces the amount of time to receive this information.
Another application example in which it is necessary to reduce the amount of routine and the number of errors when entering information into the system is to extract data from contracts. It is proposed to recognize agreements, extract information from them and send it immediately to the system. After this, the personnel department gives you a tearful thanks and warm welcome at every meeting.
Not only the personnel department suffers from a large amount of routine work with incoming documentation, but also the accounting department, sales departments, and purchasing departments also suffer. Employees have to spend a lot of time entering information from invoices, incoming acts, and so on.
In fact, all these documents are structured, and therefore it is easy to recognize them and extract information from them. Data entry speed increases up to 5 times, and at the same time the number of errors decreases, because the human factor is excluded. Conditionally, if the employee returned after lunch, he may begin to enter data inattentively. Our own measurements and the industry, which in one way or another is engaged in manual entry of information into the system, says that if a person enters data from a document, and does so on a regular basis and in a stream, he rarely gets more than 95% quality, and more and more than 90%. Therefore, for a person you need to recount, recheck even more than the machine.
Moreover, if the machine gives some estimate of confidence that it has not extracted - for example, some document may be dirty - and the machine is not sure that it has extracted it, but it can signal the verifier that he is not very sure of this result. : "Please recheck." And the person rechecks the individual information so that it is of high quality. This is not such a routine operation: he checks only really important and difficult moments, his eyes are not blurred.
If information can be extracted from documents, this information can also be compared.
This is important in two cases. First, to compare different versions of the same document, for example, a contract that is consistent for a long time, it is constantly being edited on both sides. Secondly, this is a comparison of documents of different types, for example, if there is a contract that indicates that we should receive from our partner, on the other hand, there are different invoices and reports, estimates, etc. We need to relate them and understand that everything is in order, and if not in order, then somehow signal this to the responsible people.
The current development of technology in computer vision, processing of structured and unstructured documents is so high that even now and in the coming years, digital transformation of routine processes in companies will be felt, because it is cheaper, faster and often better.
At the same time, all these methods are by no means intended to replace people. Rather, I like the example of comparison with the Excel tool, in which you can do a lot and this tool is not intended to replace neither analysts, nor managers, nor anyone else. It is intended to expand human capabilities and simplify the solution of problems for him.
Thus, solutions related to artificial intelligence are also designed to reduce the number of repetitive routine operations in which a person often makes more mistakes than a machine to unload company resources and direct them to solving more creative and intellectual tasks. And it seems that we are moving there at full speed. Thank.
Source: https://habr.com/ru/post/431934/
All Articles