Packages and package managers for k8s
We all use some kind of package managers, including cleaning lady Aunt Galya, who has an iPhone in her pocket right now. But there is no general agreement on the functions of the package managers, and the standard rpm and dpkg for the OS, and the build systems are called package managers. We propose to reflect on their functions - what it is and why they are needed in the modern world. And then we will dig in the direction of Kubernetes and carefully consider Helm from the point of view of these functions.
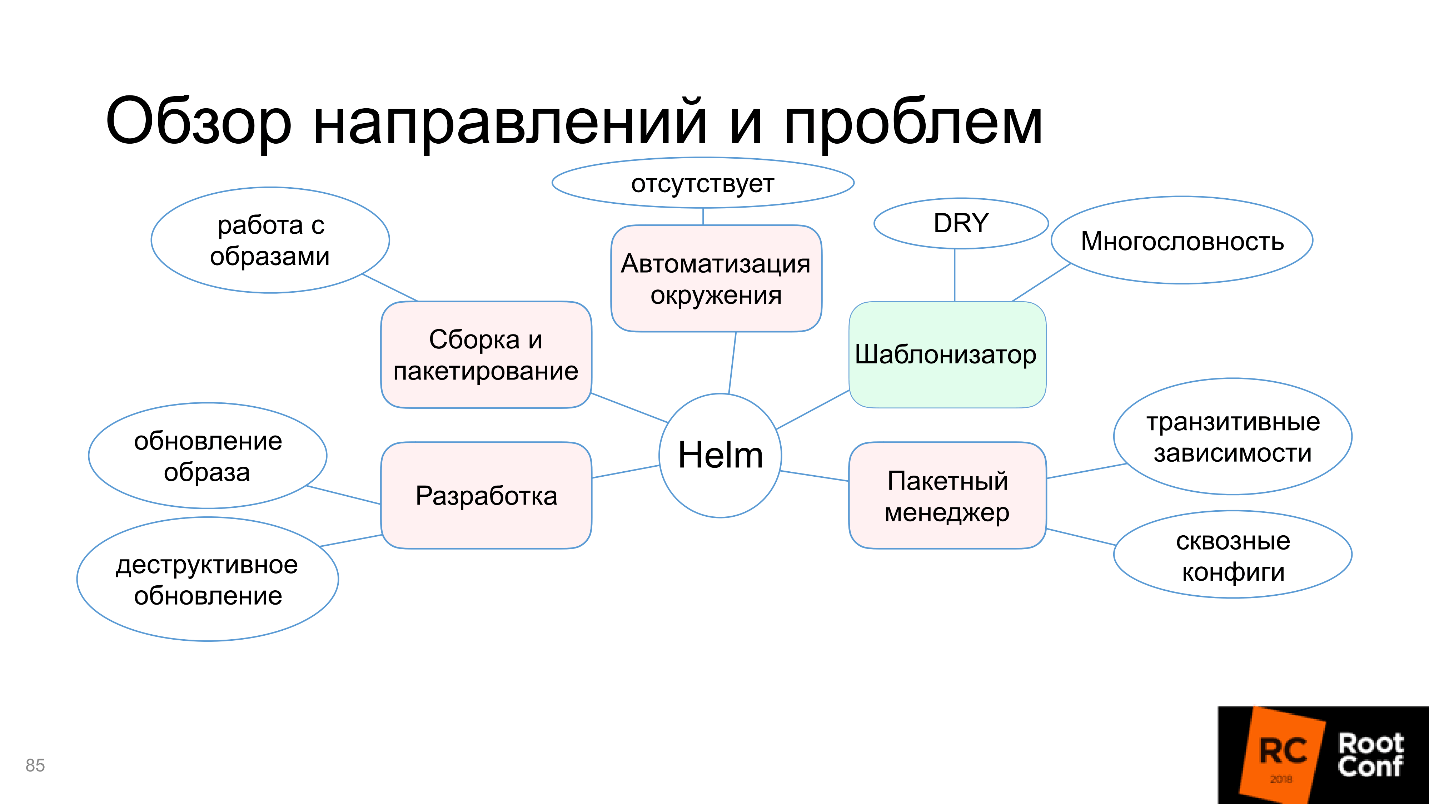
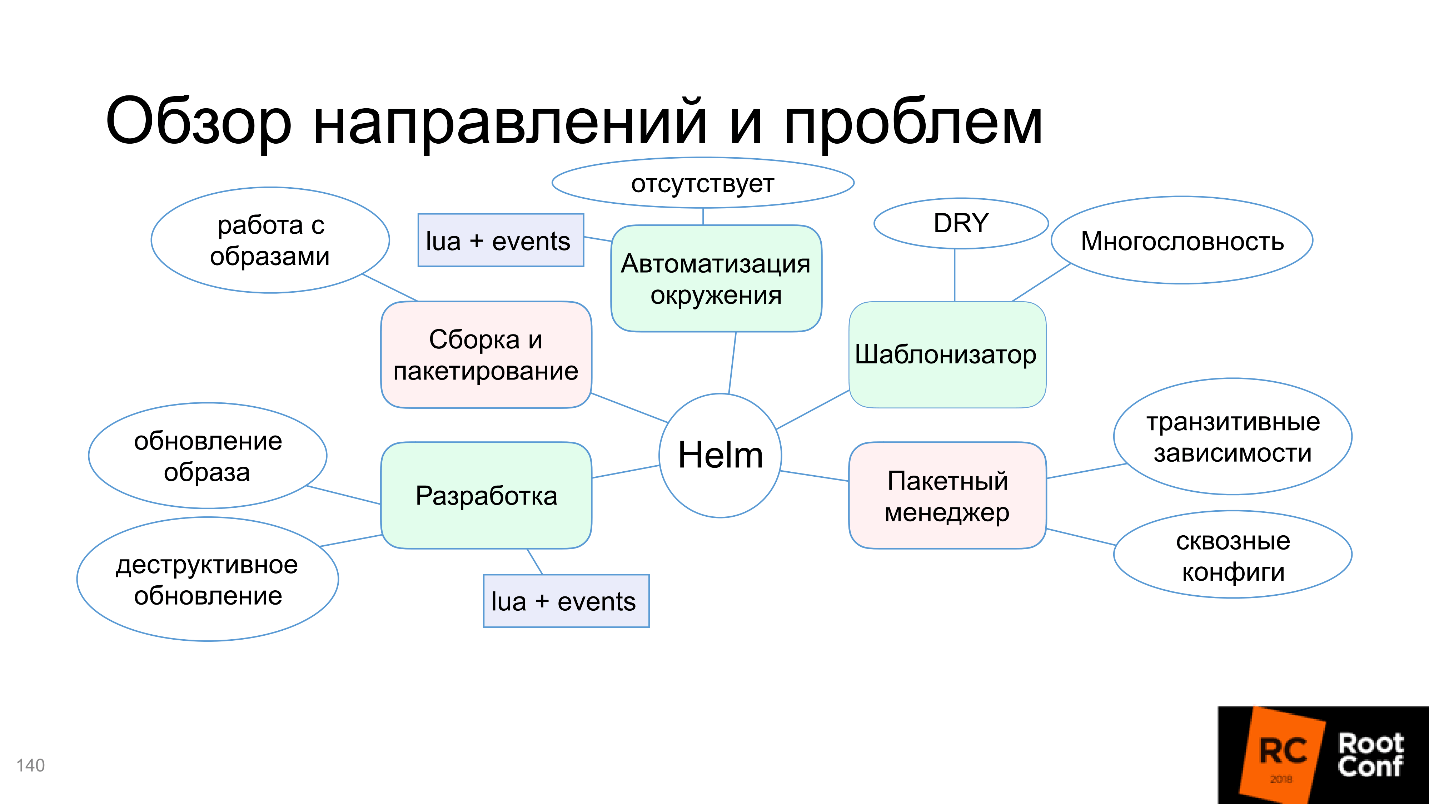
Let us see why in this diagram only the template function is highlighted in green, and what are the problems with assembly and packaging, automation of the environment and other things. But do not worry, the article will not end on the fact that everything is bad. The community could not come to terms with this and offers alternative tools and solutions - let's deal with them.
Ivan Glushkov ( gli ) helped us in this with his report on RIT ++, the video and text version of this detailed and detailed presentation below.
')
About the speaker: Ivan Glushkov has been developing software for 15 years. I managed to work in MZ, in Echo over the platform for comments, to participate in the development of compilers for the Elbrus processor in MCST. Now he is engaged in infrastructure projects in Postmates. Ivan is one of the leading DevZen podcasts, which also talk about our conferences: there is about RHS ++, and here about HighLoad ++.
Package managers
Although everyone uses any kind of package managers, there is no single agreement on what it is. There is a common understanding, and each has its own.
Let's remember what types of package managers first come to mind:
Their main function is to execute commands to install a package, update a package, delete a package, manage dependencies. In package managers inside programming languages, everything is a bit more complicated. For example, there are commands like “run package” or “create release” (build / run / release). It turns out that this is already an assembly system, although we also call it a package manager.

All this is only due to the fact that you can’t just take it and ... let the Haskell lovers forgive this comparison. You can run a binary file, but you cannot run a program in Haskell or in C, you must first prepare it in some way. And this preparation is quite complicated, and users want everything to be done automatically.
Development
The one who worked with the GNU libtool, which is made for a large project consisting of a large number of components, does not laugh at the circus. It is really very difficult, and some cases cannot be resolved in principle, but can only be circumvented.
Compared to him, modern package managers of languages like Rust are much more convenient - you press a button and everything works. Although in fact, under the hood solved a large number of problems. At the same time, all these new functions require something additional, in particular, a database. Although in the package manager itself it can be called whatever you like, I call it a database, since the data is stored there: about installed packages, about their versions, connected repositories, versions in these repositories. All this must be stored somewhere, so there is an internal database.
Development in this programming language, testing for this programming language, launches - everything is built in and located inside, the work becomes very convenient . Most modern languages have supported this approach. Even those that did not support, begin to support, because the community crushes and says that in the modern world without this is impossible.
But any decision always has not only pluses, but also minuses . Here, the downside is that wrappers, additional utilities, and the built-in “database” are needed.
Docker
No matter how, but in fact yes. I do not know a more correct utility in order to fully install the application along with all dependencies, and to make it work by pressing one button. What is this if not a package manager? This is a great batch manager!
Maxim Lapshin has already said that with Docker it has become much easier, and it is. Docker has a built-in build system, all these databases, bindings, utilities.
What is the price of all the benefits? Those who work with Docker think little about industrial applications. I have this experience, and the price is, in fact, very high:
For example, I had the task to translate one program to use Docker. The program has been developed by the team that has developed over the years. I come, we do everything that is written in the books: we write users stories, roles, see what and how they do, their standard routines.
I say:
- Docker can solve all your problems. See how it is done.
- Everything will be on the button - great! But we want to do SSH inside Kubernetes containers.
- Wait, no SSH anywhere.
- Yes, yes, all is well ... Can you use SSH?
In order to turn the perception of users in a new direction, it takes a lot of time, it needs educational work and a lot of effort.
Another factor in the price is that the Docker-registry is an external repository for images; it must somehow be installed and controlled. There are problems of their own, garbage collector, etc., and it can often fall if it is not followed, but this is all solved.
Kubernetes
Finally we reached Kubernetes. This is a cool OpenSource application management system that is actively supported by the community. Although she originally left the same company, now Kubernetes has a huge community, and it’s impossible to keep up with it, there are practically no alternatives.
Interestingly, all Kubernetes nodes work in Kubernetes itself through containers, and all external applications work through containers — everything works through containers ! This is a plus and a minus.
Kubernetes has a lot of useful functionality and properties: distribution, fault tolerance, the ability to work with different cloud services, focusing on microservice architecture. All this is interesting and cool, but how to install the application in Kubernetes?
How to install the application?
Behind this phrase is the abyss. You imagine - you have an application written in, say, Ruby, and you have to put the Docker image into the Docker registry. This means you must:
In fact, this is a big-big pain in one line.
Plus, you still need to describe the application manifests in terms of (resources) k8s. The easiest option:

On the slide, Gandhi rubs his hands - it looks like I found a package manager at Kubernetes. But kubectl is not a package manager. It simply says that I want to see the final state of the system. This is not a package installation, not a dependency operation, not an assembly — it's just “I want to see this final state.”
Helm
Finally we come to Helm. Helm is a multipurpose utility. Now we will consider what directions Helm is developing and working with it.
Template engine
First, Helm is a template engine. We discussed the need to prepare resources, and the problem is to write in Kubernetes terms (it is possible and not only in yaml). The most interesting thing is that these are static files for your specific application in this particular environment.
However, if you work with several environments and you have not only Production, but also Staging, Testing, Development and different environments for different teams, you need to have several such manifests. For example, because in one of them there are several servers, and you need to have a large number of replicas, and in the other - only one replica. There is no database accessing RDS, and you need to install PostgreSQL inside. And here we have an old version, and we need to rewrite everything a bit.
All this diversity leads to the fact that you have to take your manifesto for Kubernetes, copy it everywhere and correct it everywhere: change one number here, something else here. This becomes very uncomfortable.
The solution is simple - you must enter the templates . That is, you form the manifest, define variables in it, and then you define the variables defined from the outside as a file. The template creates the final manifest. It turns out the reuse of the same manifest for all environments, which is much more convenient.
For example, the manifest for Helm.

The simplest startup command for installing the chart is helm install ./wordpress (folder). To redefine some parameters, we say: "I want to redefine precisely these parameters and set such and such values."
Helm copes with this task, so we’ll mark it green in the diagram.
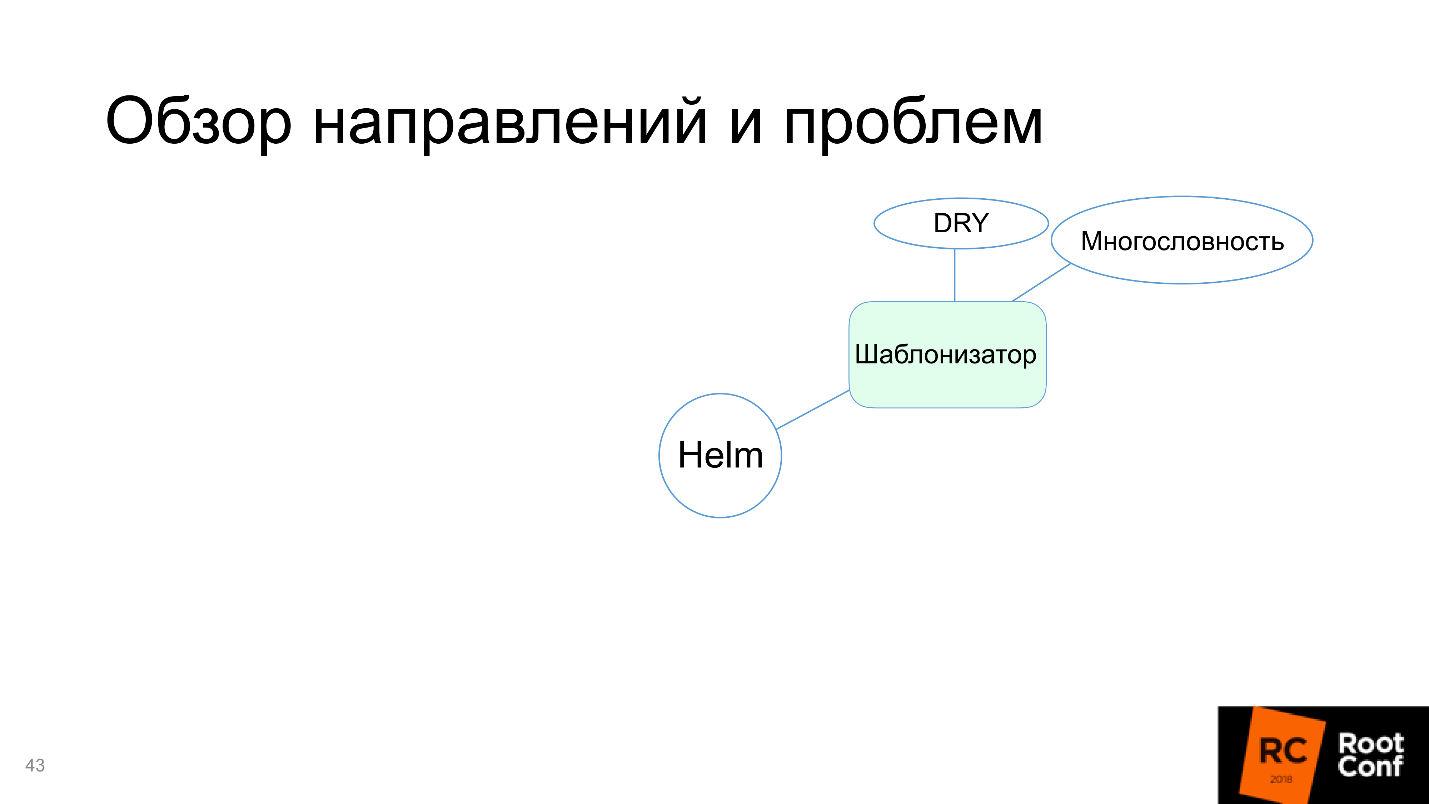
True cons appear:
Before plunging into the direction of Helm - the package manager, for which I am telling all this, let's see how Helm works with dependencies.
Work with dependencies
With dependencies Helm works hard. First, there is a requirements.yaml file that fits with what we depend on. While working with requirements, it makes requirements.lock - this is the current state (impression) of all dependencies. After that, he downloads them to a folder called / charts.
There are tools to control: who, how, where to connect - tags and conditions , with the help of which it is determined in which environment, depending on which external parameters to connect or not to connect any dependencies.
Let's say you have PostgreSQL for the Staging environment (or RDS for Production, or NoSQL for tests). By installing this package in Production, you do not install PostgreSQL, because it is not needed there - just with the help of tags and conditions.
What is interesting here?
After we have downloaded all the dependencies in / charts (these dependencies can be, for example, 100), Helm inside it takes and copies all the resources. After he has rendered the templates, he collects all the resources in one place and sorts them in some kind of his own order. You cannot influence this order. You have to decide for yourself what your package depends on, and if the package has transitive dependencies, you need to include them all in the description in the requirements.yaml. This must be borne in mind.
Batch manager
Helm installs applications and dependencies, and you can tell Helm install — and it will install the package. So this is a package manager.
At the same time, if you have an external repository in which you are uploading a package, you can not access it as a local folder, but simply say: “From this repository, take this package, install it with such and such parameters”.
There are open repositories with a large number of packages. For example, you can run: helm install -f prod / values.yaml stable / wordpress
From the repository of stable you take wordpress and install to yourself. You can do everything: search / upgrade / delete. It turns out, indeed, Helm - package manager.
But there are downsides: all transitive dependencies must be turned inward. This is a big problem when transitive dependencies are independent applications, and you want to work with them separately for testing and development.
Another disadvantage is end-to - end configuration . When you have a database and its name needs to be transferred to all packages, it is possible, but difficult to do.

Most often it does not happen that you have installed one small bag, and it works. The world is complex: the application depends on the application, which in turn also depends on the application - you need to tweak them somehow cleverly. Helm does not know how to support it, or supports it with big problems, and sometimes you have to dance a lot with a tambourine to make it work. This is bad, so the “package manager” on the scheme is highlighted in red.
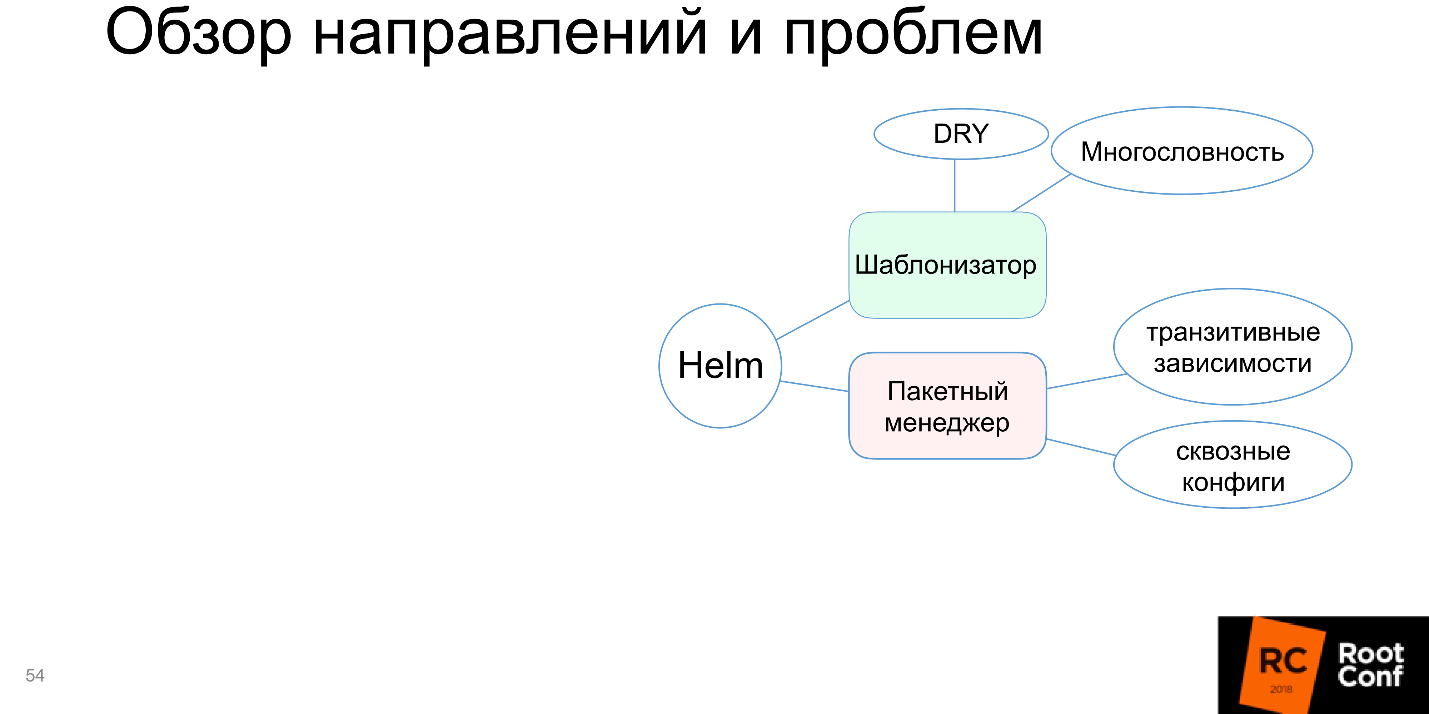
Assembly and packaging
"You can not just take and" run the application in Kubernetes. You need to build it, that is, make a Docker image, write it to the Docker registry, etc. Although all the definition of the package in Helm is. We define what a package is, what features and fields there should be, signatures and authentication (your company's security system will be very pleased). Therefore, on the one hand, the build and packaging seems to be supported, and on the other, the work with Docker images is not configured.
This is the same as if, in order to make an upgrade install for some small library, you would be sent to a remote folder to run the compiler.
Therefore, we say that Helm does not know how to work with images.

Development
The next headache is development. In development, we want to quickly and conveniently change our code. The time has passed when you punched holes on punched cards, and the result was obtained after 5 days. Everyone is used to replacing one letter with another in the editor, pressing the compilation, and the already changed program works.
It also turns out that when changing the code, a lot of additional actions are needed: prepare a Docker file; Run Docker to create an image; somewhere to push it; deploy to the kubernetes cluster. And only then you will get what you want on Production, and will be able to check the operation of the code.
Another inconvenience is due to the destructive helm upgrade upgrade. You looked at how everything works, through kubectl exec looked inside the container, everything is fine. At this point, you are launching an update, a new image is being downloaded, new resources are being launched, and old ones are being deleted - everything must be started from the very beginning.
The biggest pain is the big images . Most companies do not work with small applications. Often this if not supermonolith, then at least a small monolithic. Over time, the growth of annual rings, increases the amount of code base, and gradually the application becomes quite large. I have come across more than once Docker images larger than 2 GB. Imagine now that you make a change of one byte in your program, press a button, and a two-gigabyte Docker image begins to assemble. Then you press the next button, and the transfer of 2 GB to the server begins.
Docker allows you to work with layers, i.e. checks if there is one layer or another and sends the missing one. But the world is such that more often it will be one big layer. While 2 GB will go to the server, while they and the Docker-registry come to Kubernetes, roll out all the boxes, until you finally start - you can safely drink tea.
Helm does not provide any help in working with large Docker images. I believe that this should not be, but the Helm developers know better than all users, and Steve Jobs smiles at this.

The development block also turned red.
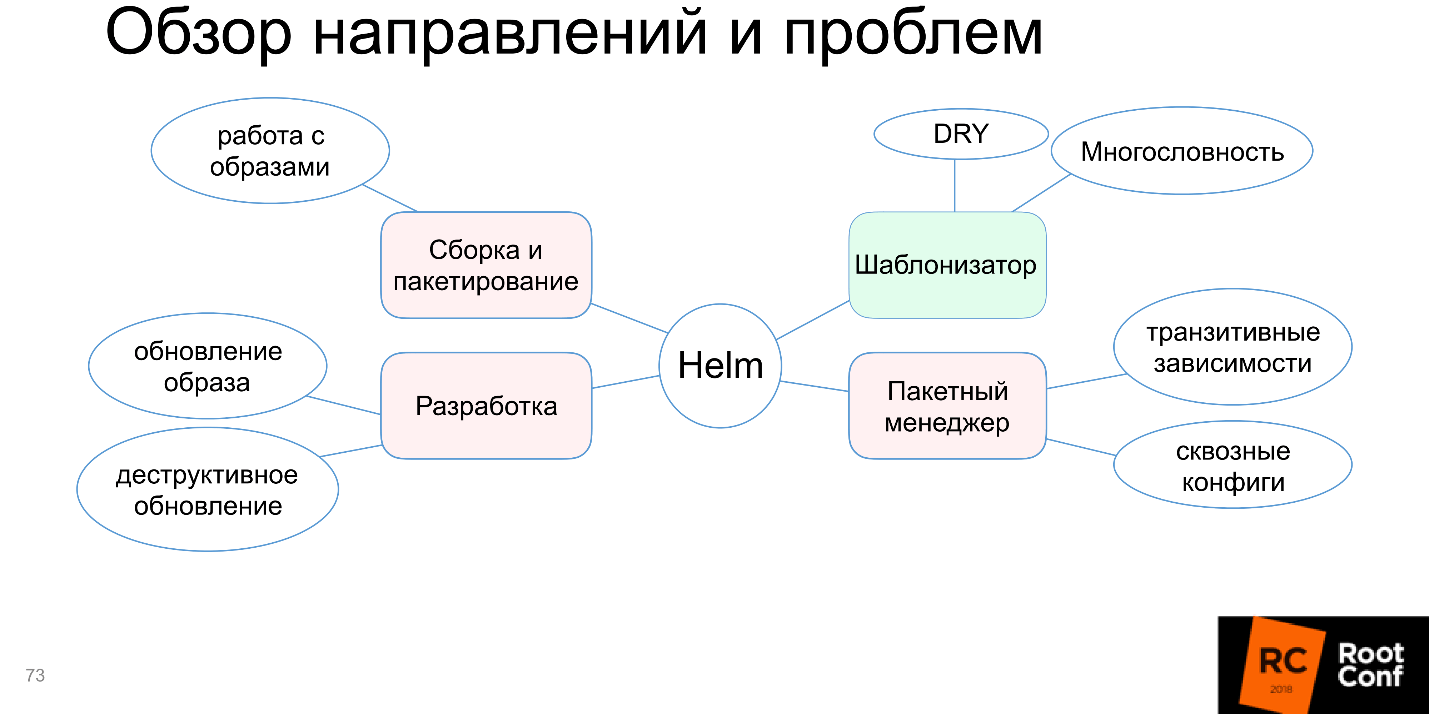
Environment Automation
The last area, environment automation, is an interesting area. Before the Docker world (and Kubernetes, as a related model), it was not possible to say: “I want to install my application on this server or on these servers, so that there are n replicas, 50 dependencies, and it all works automatically!” that was, but was not!
Kubernetes provides this and it is logical to use it somehow, for example, to say: “I’m deploying a new environment here and I want all the development teams that have prepared their applications to simply press a button, and all these applications are automatically installed on the new environment” . Theoretically, Helm should help with this, so that the configuration can be taken from an external data source - S3, GitHub - from anywhere.
It is desirable that in Helm there was a special button “Make me feel good at last!” - and it would immediately become good. Kubernetes allows you to do this.
This is especially convenient because Kubernetes can be run anywhere, and it works through the API. Running minikube locally, or in AWS, or in the Google Cloud Engine, you get Kubernetes right out of the box and work the same everywhere: press a button, and everything is all right at once.
It would seem, of course Helm allows you to do this. Because otherwise, what was the point of creating Helm?
But it turns out, no!
Automation environment absent.
Alternatives
When there is an application from Kubernetes that everyone uses (this is now in fact the solution number 1), but at the same time Helm has the problems discussed above, the community could not help but answer. It began to create alternative tools and solutions.
Template engines
It would seem that, as a template engine, Helm solved all the problems, but still the community creates alternatives. I recall the problems of the template engine: verbosity and code reuse.
A good representative here is Ksonnet. It uses a fundamentally different data model and concepts, and it does not work with Kubernetes resources, but with its own definitions:
prototype (params) -> component -> application -> environments.
There are parts (parts) that make up the prototype. The prototype is parameterized by external data, and a component appears. Several components make up an application that can be run. It runs in different environments. Some understandable links to Kubernetes resources are here, but there may not be a direct analogy.
The main purpose of the emergence of Ksonnet was, of course, the reuse of resources . They wanted to make it so that you, once having written the code, could later use it anywhere, which increases the speed of development. If you create a large external library, people can constantly place their resources there, and the whole community will be able to reuse them.
Theoretically it is convenient. I practically did not use it.
Package managers
The problem here, as we remember, is nested dependencies, end-to-end configs, transitive dependencies. Their Ksonnet does not solve. Ksonnet has a very similar model to Helm, which also defines the list of dependencies in the file, it is uploaded to a specific directory, etc. The difference is that you can make patches, that is, you prepare a folder in which you put patches for specific packages.

When you upload a folder, these patches overlap, and the result obtained by merging several patches can begin to be used. Plus there is a validation of configurations for dependencies. This may be convenient, but it is still very raw, there is almost no documentation, and the version has stopped at 0.1. I think it's too early to use it.
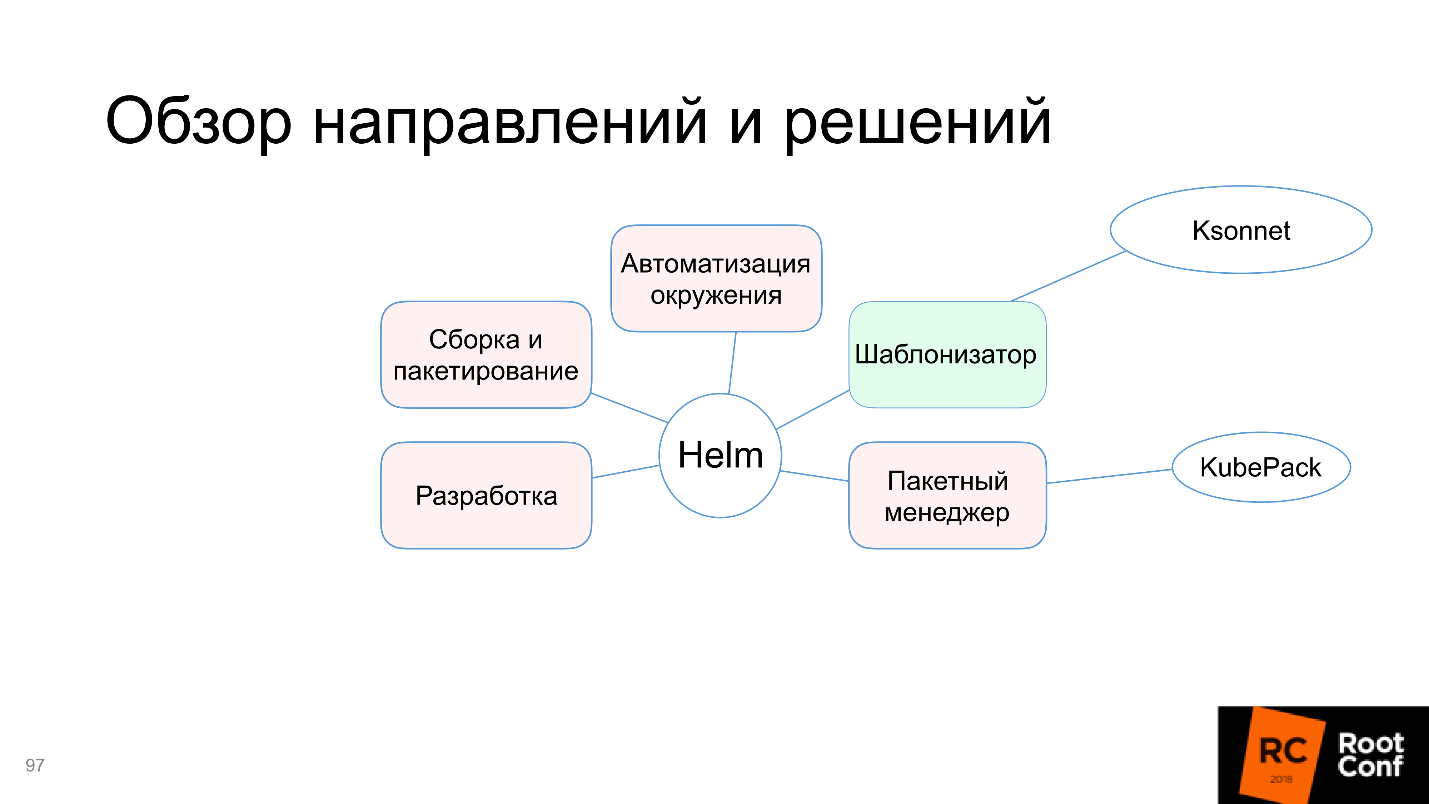
So, the package manager is KubePack , and I haven’t yet seen other alternatives.
Development
Solutions are divided into several different categories:
1. Development over Helm
A good representative is Draft . Its goal is to be able to try the application before the code is committed, that is, to see the current status. Draft uses the Heroku-style programming method:
This can be done in any directory with code, everything seems to be quick, easy and good.
But in the future it is better to start working with Helm anyway, because Draft creates Helm-resources, and when your code reaches production-ready state, it’s not worth hoping that Draft will create Helm-resources well. You will still have to create them manually.
It turns out that Draft is needed to quickly start and try at the very beginning before you have written at least one Helm-resource. Draft - the first contender for this direction.
2. Development without Helm
Development without Helm Charts involves building the same Kubernetes manifestos that would otherwise be built through Helm Charts. I suggest three alternatives:
They are all very similar to Helm, the differences in small details. In particular, some solutions assume that you will use the command line interface, and Chart assumes that you will do git push and manage hooks.
In the end, you still run docker build, docker push and kubectl rollout. All the problems that we listed for Helm are not solved at all. It is just an alternative with the same drawbacks.
3. Development in the language of the application
The next alternative is the development in the language of the application. Here is a good example - Metaparticle . Let's say you write code in Python, and right inside Python you start to think what you want from the application.
If it is correct to describe a working application, what parts it consists of, how they interact, theoretically some kind of magic will help turn this knowledge from the point of view of the application into Kubernetes resources.
With the help of decorators we determine: where the repository is located, how to properly push it; what services are and how they interact with each other; there should be so many replicas on the cluster, etc.

I don’t know about you, but personally I don’t like it when instead of me some kind of magic decides that you need to make such a Kubernetes config from the Python definitions. And if I need another?
All this works up to a certain limit, while the application is fairly standard. After that, problems begin. Let's say I want the preinstall container run before the main container runs, which will perform some actions to configure the future container. This is all done in the framework of Kubernetes-configs, but I don’t know whether it is done in the framework of Metaparticle.
I cite commonplace simple examples, and there are many more of them, there are a lot of parameters in the specification of Kubernetes-configs. I am sure that they are not fully present in decorators like Metaparticle.
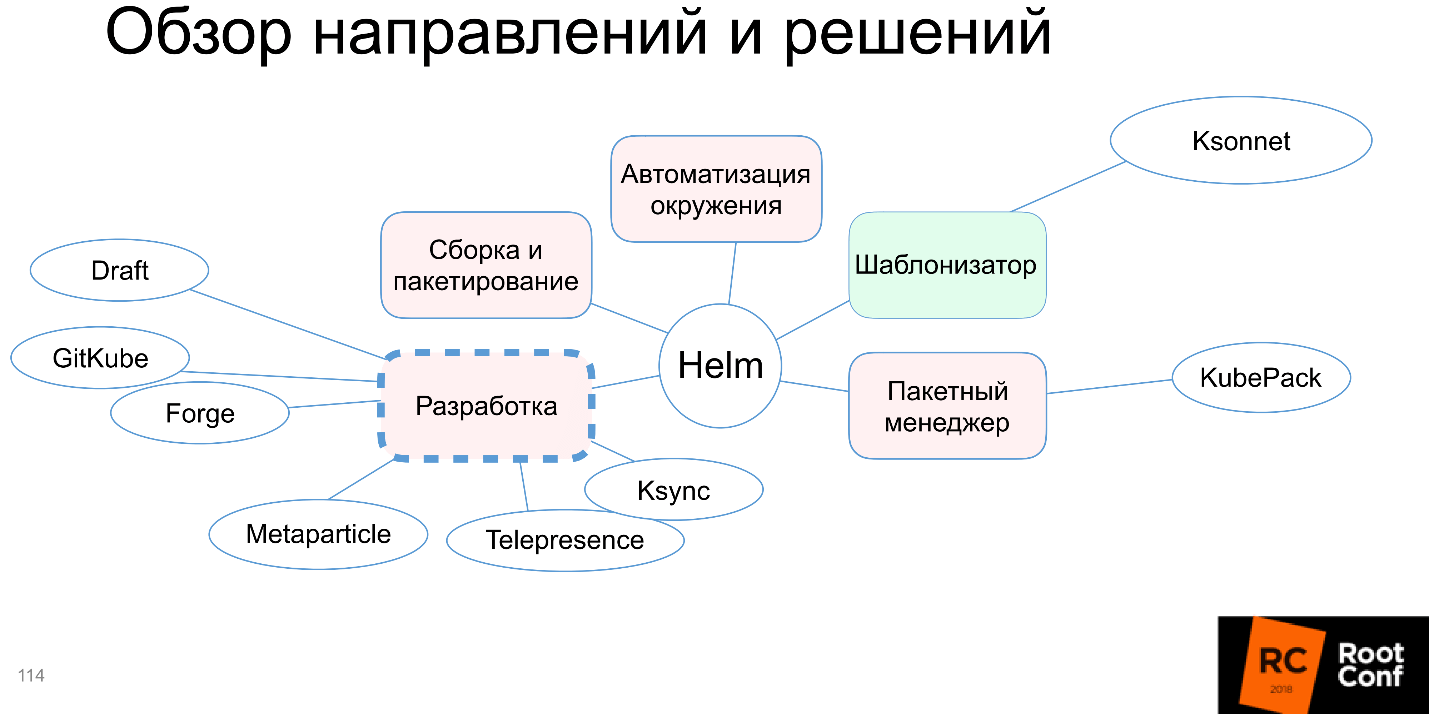
Metaparticle appears on the diagram, and we discussed three alternative approaches to Helm. However, there are additional, and they are very promising in my opinion.
Telepresence / Ksync is one of them. Suppose you have an application that has already been written, there are Helm-resources that are also written. You installed the application, it started somewhere in the cluster, and at this moment you want to try something, for example, change one line in your code. Of course, I’m not talking about Production clusters, although some of them even rule something on Production.
The Kubernetes problem is that you need to transfer these local edits via the Docker update, via the registry, to Kubernetes. But to bring to the cluster one modified line can be in other ways. You can synchronize the local and remote folder, which is located on the hearth.
Yes, of course, at the same time there should be a compiler in the image, everything necessary for Development should be there in place. But what a convenience: install the application, change a few lines, synchronization works automatically, the updated code becomes on the page, we start the compilation and tests - nothing breaks, nothing updates, no destructive updates, as in Helm, does not happen, we get the updated one that works attachment.
In my opinion, this is an excellent solution to the problem.
4. Development for Kubernetes without Kubernetes
I used to think that there was no point in working with Kubernetes without Kubernetes. I thought that it’s better to make the Helm-definitions once and use the appropriate tools so that in local development you can have the same configs for everything. But over time, I was faced with reality and saw applications for which it is extremely difficult to do. Now I have come to the conclusion that it is easier to write a Docker-compose file.
When you do a Docker-compose file, you run all the same images, and mount, just like in the previous case, the local folder on the folder in the Docker container, just not inside Kubernetes, but just in Docker-compose, which is running locally . Then just run the compiler, and everything works fine. The downside is that you need to have additional configs for Docker. The advantage is speed and simplicity.
In my example, I tried to run in minikube the same thing that I tried to do with Docker-compose, and the difference was huge. It worked badly, there were incomprehensible problems, and you raise Docker-compose in 10 lines and everything works. Since you are working with the same images, it guarantees repeatability.
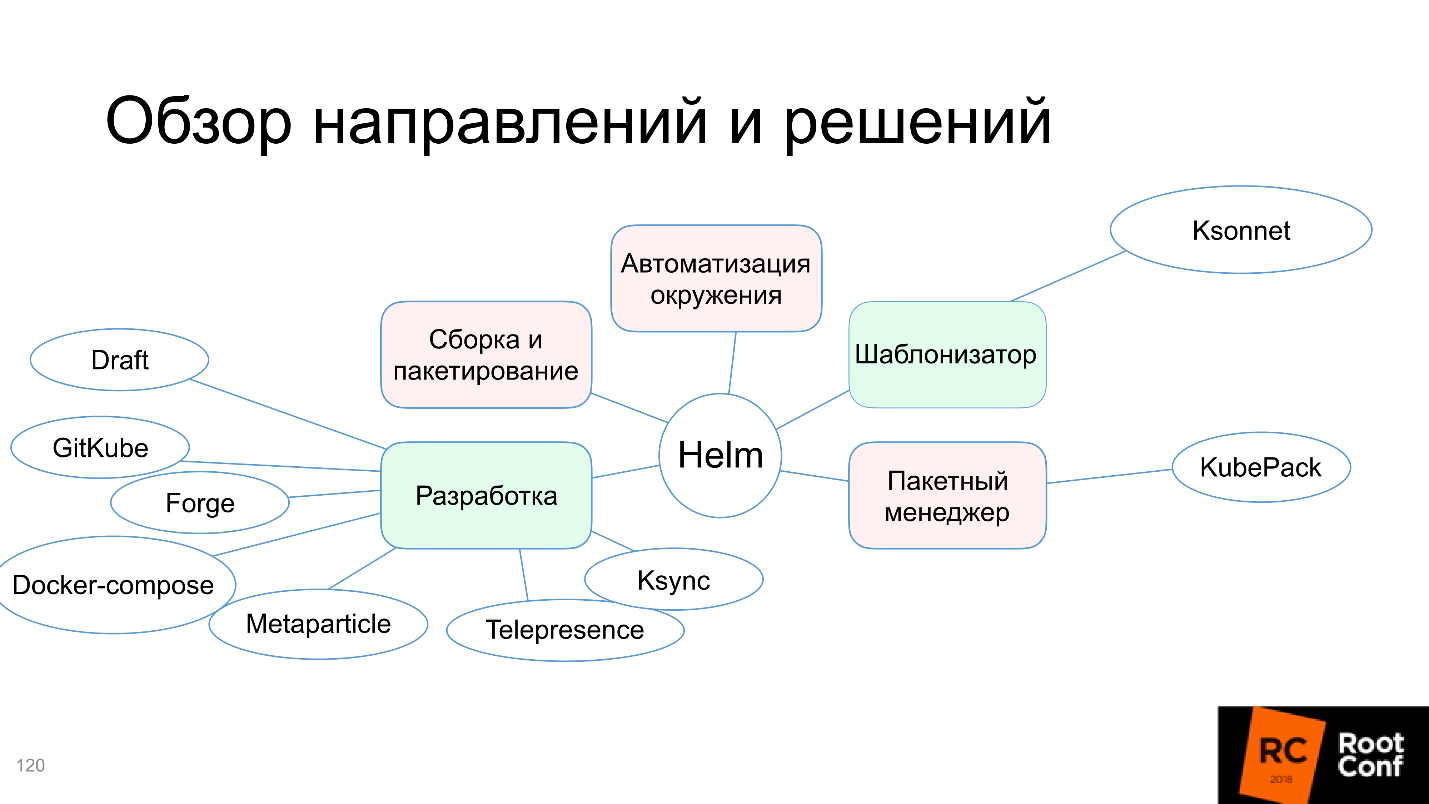
Docker-compose is added to our scheme, and as a whole, it turns out that the community summed up with all these solutions to solve the development problem.
Assembly and packaging
Yes, assembly and packaging is a problem for Helm, but probably the developers of Helm were right after all. Each company has its own CI / CD system that collects artifacts, checks and tests. If it is already there - why close this problem in Helm, when everyone has his own? Perhaps one correct solution will fail, each will have modifications.
If you have a CI / CD, there is integration with an external repository, dockers are automatically collected for each commit, set tests are run, and you can press the button and close it all, you have solved the problem - it is not left.
CI / CD is really a solution to the build and packaging problem, and we paint it green.
Results

From 5 directions, Helm itself closes only the template engine. Immediately it becomes clear why it was created. The rest of the solutions the community has jointly added, the problems of development, assembly and packaging are completely solved by external solutions. This is not completely convenient, it is not always easy to do within the framework of the established traditions within the company, but it is possible, at least.
Future helm
I am afraid that none of us knows for sure what Helm should come to. As we have seen, the Helm developers sometimes know better than us what needs to be done. I think that most of the problems that we have considered will not be closed by the next releases of Helm.
Let's see what has been added to the current Road Map. There is such a Kuberneres Helm repository in the community , in which there are development plans and good documentation on what will happen in the next version of Helm V3 .
Tiller disclaimer, only cli
We have not yet discussed these details, so we will consider now. The Helm architecture consists of two parts:
Tiller handles requests that you send through the Command Line Interface. So you say: “I want to install this Chart” - and in fact Helm collects it, packs it, sends it to Tiller, and he already decides: “Oh, something has come to me! It seems that this is projected into the next Kubernetes resources ”- and it launches.
According to the Helm developers, one Tiller should work per cluster and manage the entire technology zoo that is in the cluster. But it turned out that in order to properly share access, it is more profitable for us to have not one but several Tillers - for each namespace its own. So that Tiller can create resources only in the namespace, in which it is running, and did not have the right to go to the neighboring ones. This makes it possible to divide the area of responsibility, the area of visibility for different teams.
The next version of V3 Tiller will not.
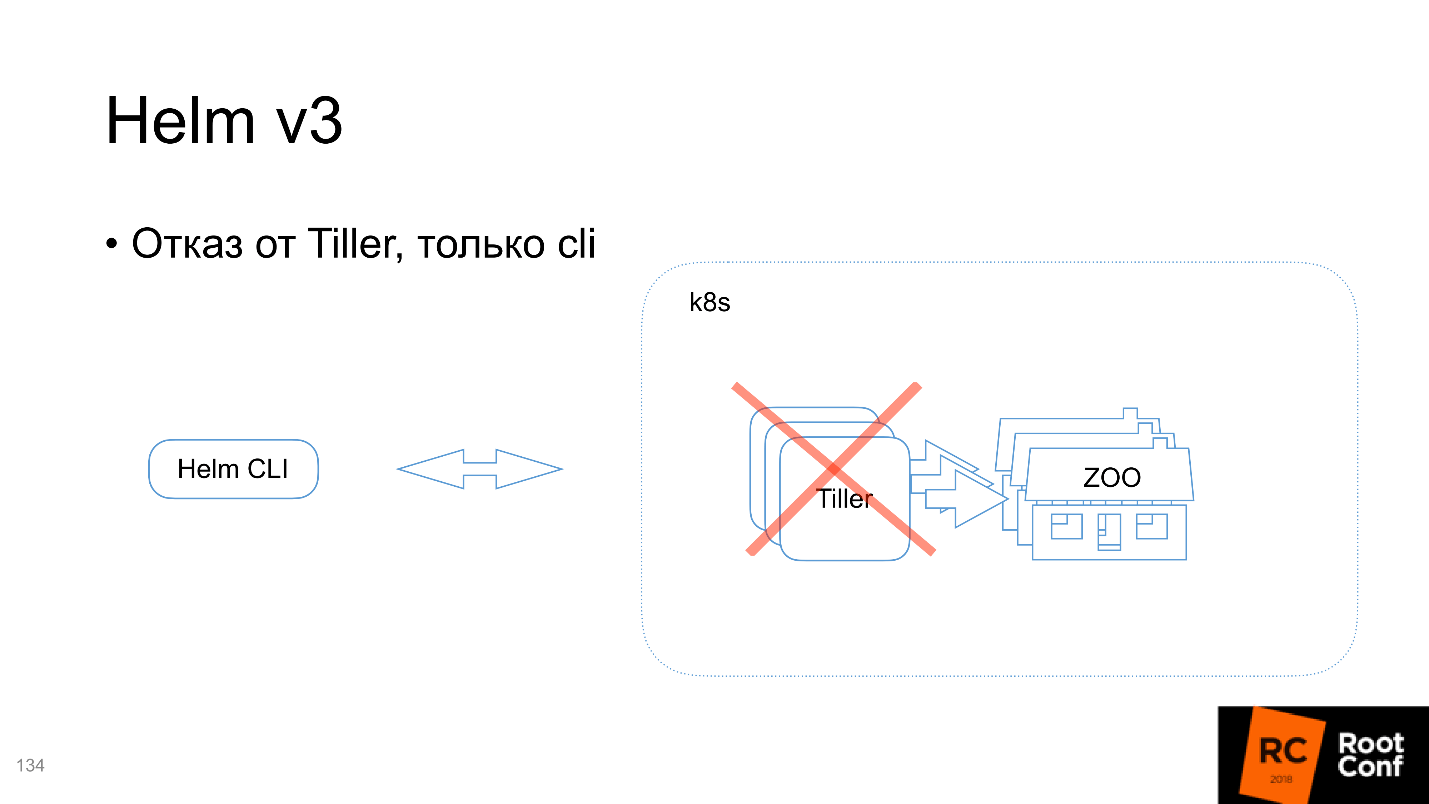
And why is he even needed? In essence, it contains information transmitted via the Command Line Interface, which it uses to launch resources in Kubernetes. It turns out that Kubernetes already contains exactly the same information that is contained in Tiller. But I can do the same with kubectl cli.
Instead of Tiller, an event system is introduced . On all new resources that you send to Kubernetes via the Command Line Interface there will be events: settings, changes, deletions, pre-and post-events. There are quite a few of these events.
Chart Lua Scripts
Some of them you cannot edit, some you can, and you can do this with the help of lua scripts . At the stage of creating a Chart, you add a collection of lua-scripts that you put into a special folder. They will fully track the handling of external events. It must be convenient. In fact, some of the problems we discussed earlier can be solved with this approach.
Lua and events can close development problems, because it will be possible to control what needs to be done when something happens, both on the server side and on the automation side of the environment too.
Unfortunately, there is still no implementation, one can only guess. But theoretically, the most important problem for me is to automate the environment, we can completely close it. You can write a new application in Kubernetes, send some configs to it, and using the mechanism that you program yourself, the application will install everything that you want. Let's see what happens.
Release object + release release secret
In order to fully track the release process, a Release-object will appear with information about which Release was written. It has not yet been announced that it will be a Release object, how it will be created, maybe it will be a CRD, or maybe not.
Binding to release namespace
This release object will be created in the namespace in which everything was running, and accordingly because of this, it is not necessary to bind Tiller to the namespace — the problem I mentioned a little earlier.
CRD: controller
Additionally, in the distant future, developers are thinking of creating a CRD controller for Helm for those cases that cannot be covered by the standard push model. But information about the implementation of this is not at all.
Collection of recipes
In total, I recommend using the system.

Of course, this is Helm . It is created by the community, all alternative solutions are created by independent teams, about which we are not sure how long they will exist. Unfortunately, the day after tomorrow they may abandon their projects, and you will remain at the bottom of the trough. And Helm is, after all, a part of Kubernetes. In addition, it will somehow develop and, perhaps, solve problems.
Of course, CI / CD , automatic assembly by commit. In our company, we have done integration with Slack., we have a bot that tells you when a new build went through in master, and that all the tests were successful. You say to him: “I want to install it in Staging” - and he installs, say: “I want to run a test there!” - and he launches. Pretty comfortable.
For development use Docker-compose or Telepresence.
Multiple versions of the same service
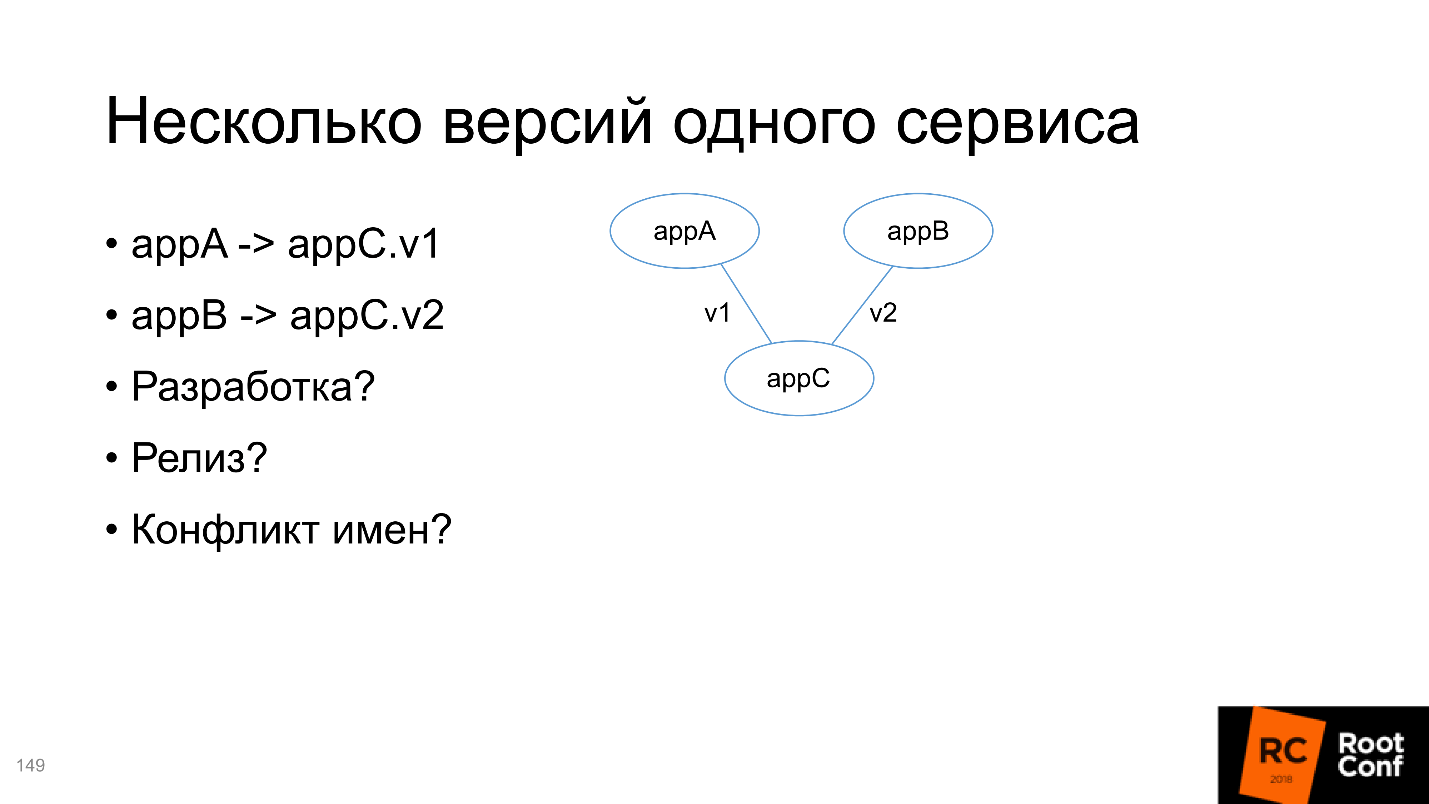
In the end we will analyze the situation when there are two applications A and B, which depend on C, but C different versions. Need to solve this problem:
In fact, Kubernetes decides everything for us - you just need to use it correctly.

I would advise you to create 4 Chart in terms of Helm, 3 repositories (for the C repository this will be just two different branches). What is most interesting, all installations for v1 and for v2 should contain information about the version or for which service it was created. One of the solutions on the slide, Appendix C; the release name indicates that this is version v1 for service A; The service name also contains a version. This is the simplest example you can do in a completely different way. But most importantly, the names were unique.
The second is transitive dependencies, and more complicated here.
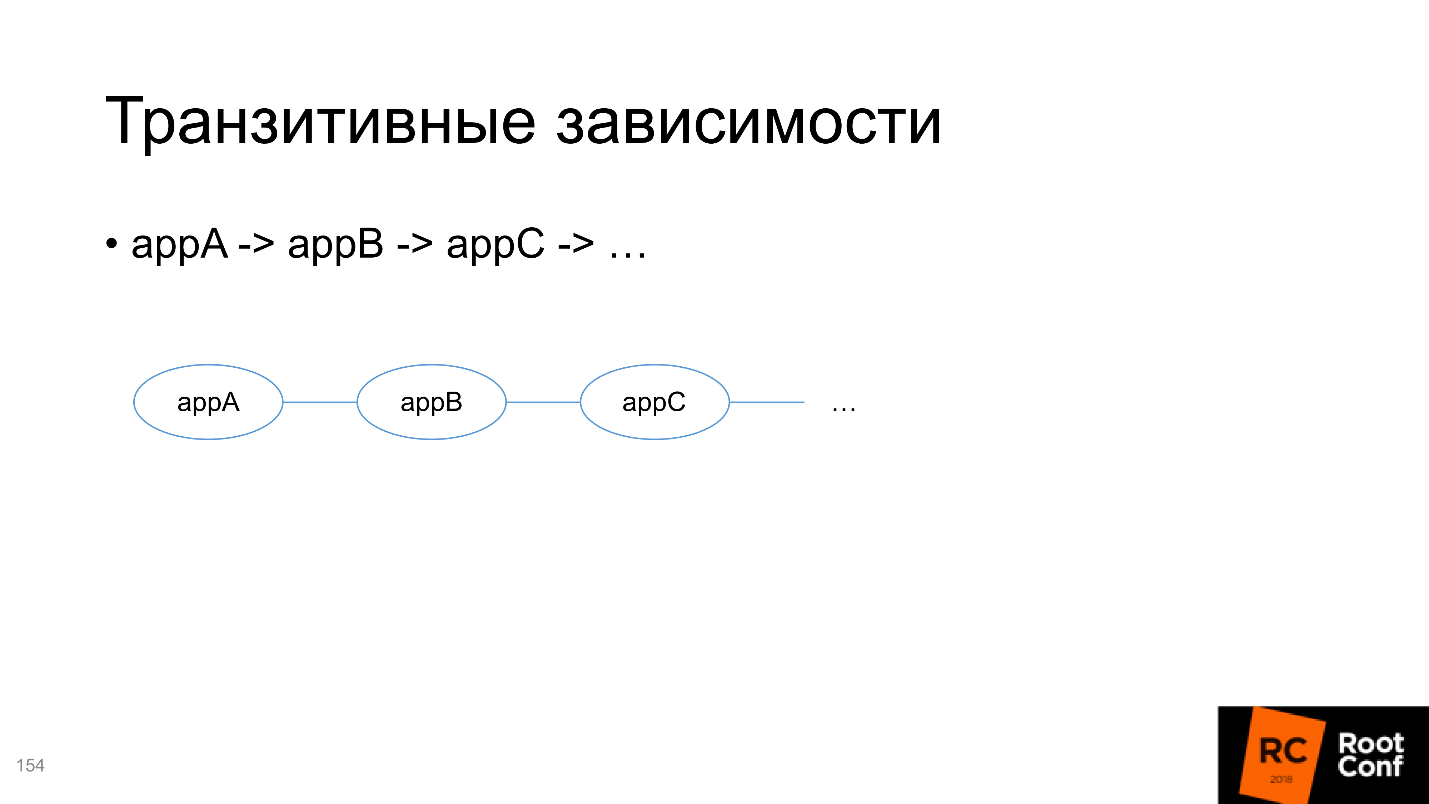
For example, you are developing a chain of services and want to test A. For this, you must pass all the dependencies on which A depends, including transitive, to the Helm-definition of your package. But at the same time, you want to develop B and test it too - how to do it is incomprehensible, because you need to put all transitive dependencies in it as well.
Therefore, I advise you not to add all dependencies inside each package, but to make them independent and from the outside manage what is running. This is inconvenient, but it is the lesser of two evils.
useful links
• Draft
• GitKube
• Helm
• Ksonnet
• Telegram stickers: one , two
• Sig-Apps
• KubePack
• Metaparticle
• Skaffold
• Helm v3
• Docker-compose
• Ksync
• Telepresence
• Drone
• Forge
Speaker Ivan Glushkov's profile on GitHub , in twitter , on Habré .
Let us see why in this diagram only the template function is highlighted in green, and what are the problems with assembly and packaging, automation of the environment and other things. But do not worry, the article will not end on the fact that everything is bad. The community could not come to terms with this and offers alternative tools and solutions - let's deal with them.
Ivan Glushkov ( gli ) helped us in this with his report on RIT ++, the video and text version of this detailed and detailed presentation below.
')
Videos of this and other talks on DevOps on RHS ++ are published and open for free viewing on our youtube channel - go in search of answers to your working questions.
About the speaker: Ivan Glushkov has been developing software for 15 years. I managed to work in MZ, in Echo over the platform for comments, to participate in the development of compilers for the Elbrus processor in MCST. Now he is engaged in infrastructure projects in Postmates. Ivan is one of the leading DevZen podcasts, which also talk about our conferences: there is about RHS ++, and here about HighLoad ++.
Package managers
Although everyone uses any kind of package managers, there is no single agreement on what it is. There is a common understanding, and each has its own.
Let's remember what types of package managers first come to mind:
- Standard package managers of all operating systems: rpm, dpkg, portage , ...
- Package managers for different programming languages: cargo, cabal, rebar3, mix , ...
Their main function is to execute commands to install a package, update a package, delete a package, manage dependencies. In package managers inside programming languages, everything is a bit more complicated. For example, there are commands like “run package” or “create release” (build / run / release). It turns out that this is already an assembly system, although we also call it a package manager.
All this is only due to the fact that you can’t just take it and ... let the Haskell lovers forgive this comparison. You can run a binary file, but you cannot run a program in Haskell or in C, you must first prepare it in some way. And this preparation is quite complicated, and users want everything to be done automatically.
Development
The one who worked with the GNU libtool, which is made for a large project consisting of a large number of components, does not laugh at the circus. It is really very difficult, and some cases cannot be resolved in principle, but can only be circumvented.
Compared to him, modern package managers of languages like Rust are much more convenient - you press a button and everything works. Although in fact, under the hood solved a large number of problems. At the same time, all these new functions require something additional, in particular, a database. Although in the package manager itself it can be called whatever you like, I call it a database, since the data is stored there: about installed packages, about their versions, connected repositories, versions in these repositories. All this must be stored somewhere, so there is an internal database.
Development in this programming language, testing for this programming language, launches - everything is built in and located inside, the work becomes very convenient . Most modern languages have supported this approach. Even those that did not support, begin to support, because the community crushes and says that in the modern world without this is impossible.
But any decision always has not only pluses, but also minuses . Here, the downside is that wrappers, additional utilities, and the built-in “database” are needed.
Docker
Do you think Docker is a package manager or not?
No matter how, but in fact yes. I do not know a more correct utility in order to fully install the application along with all dependencies, and to make it work by pressing one button. What is this if not a package manager? This is a great batch manager!
Maxim Lapshin has already said that with Docker it has become much easier, and it is. Docker has a built-in build system, all these databases, bindings, utilities.
What is the price of all the benefits? Those who work with Docker think little about industrial applications. I have this experience, and the price is, in fact, very high:
- The amount of information (image size) that should be stored in the Docker image. It is necessary to pack all dependencies, parts of utilities, libraries inside, the image is large and you need to know how to work with it.
- Much more difficult is the paradigm shift .
For example, I had the task to translate one program to use Docker. The program has been developed by the team that has developed over the years. I come, we do everything that is written in the books: we write users stories, roles, see what and how they do, their standard routines.
I say:
- Docker can solve all your problems. See how it is done.
- Everything will be on the button - great! But we want to do SSH inside Kubernetes containers.
- Wait, no SSH anywhere.
- Yes, yes, all is well ... Can you use SSH?
In order to turn the perception of users in a new direction, it takes a lot of time, it needs educational work and a lot of effort.
Another factor in the price is that the Docker-registry is an external repository for images; it must somehow be installed and controlled. There are problems of their own, garbage collector, etc., and it can often fall if it is not followed, but this is all solved.
Kubernetes
Finally we reached Kubernetes. This is a cool OpenSource application management system that is actively supported by the community. Although she originally left the same company, now Kubernetes has a huge community, and it’s impossible to keep up with it, there are practically no alternatives.
Interestingly, all Kubernetes nodes work in Kubernetes itself through containers, and all external applications work through containers — everything works through containers ! This is a plus and a minus.
Kubernetes has a lot of useful functionality and properties: distribution, fault tolerance, the ability to work with different cloud services, focusing on microservice architecture. All this is interesting and cool, but how to install the application in Kubernetes?
How to install the application?
Install the Docker image in the Docker registry.
Behind this phrase is the abyss. You imagine - you have an application written in, say, Ruby, and you have to put the Docker image into the Docker registry. This means you must:
- prepare a Docker image;
- understand how it is going, on which versions it is based;
- be able to test it;
- collect, fill in the Docker-registry, which you, by the way, have installed before.
In fact, this is a big-big pain in one line.
Plus, you still need to describe the application manifests in terms of (resources) k8s. The easiest option:
- describe deployment + pod, service + ingress (possible);
- Run the kubectl apply -f resources.yaml command, and transfer all resources to this command.
On the slide, Gandhi rubs his hands - it looks like I found a package manager at Kubernetes. But kubectl is not a package manager. It simply says that I want to see the final state of the system. This is not a package installation, not a dependency operation, not an assembly — it's just “I want to see this final state.”
Helm
Finally we come to Helm. Helm is a multipurpose utility. Now we will consider what directions Helm is developing and working with it.
Template engine
First, Helm is a template engine. We discussed the need to prepare resources, and the problem is to write in Kubernetes terms (it is possible and not only in yaml). The most interesting thing is that these are static files for your specific application in this particular environment.
However, if you work with several environments and you have not only Production, but also Staging, Testing, Development and different environments for different teams, you need to have several such manifests. For example, because in one of them there are several servers, and you need to have a large number of replicas, and in the other - only one replica. There is no database accessing RDS, and you need to install PostgreSQL inside. And here we have an old version, and we need to rewrite everything a bit.
All this diversity leads to the fact that you have to take your manifesto for Kubernetes, copy it everywhere and correct it everywhere: change one number here, something else here. This becomes very uncomfortable.
The solution is simple - you must enter the templates . That is, you form the manifest, define variables in it, and then you define the variables defined from the outside as a file. The template creates the final manifest. It turns out the reuse of the same manifest for all environments, which is much more convenient.
For example, the manifest for Helm.
- The most important part in Helm is Chart.yaml , which describes what the manifest is, what versions, how it works.
- templates are just Kubernetes resource templates that contain variables inside themselves. These variables must be defined in an external file or on the command line, but always outside.
- values.yaml is the standard name for the file with variables for these templates.
The simplest startup command for installing the chart is helm install ./wordpress (folder). To redefine some parameters, we say: "I want to redefine precisely these parameters and set such and such values."
Helm copes with this task, so we’ll mark it green in the diagram.
True cons appear:
- Verbosity . Resources are defined completely in terms of Kubernetes, no concepts of additional levels of abstraction are introduced: we simply write everything that we would like to write for Kubernetes, and substitute variables there.
- Don't repeat yourself - does not apply. You have to repeat the same thing often. If you have two similar services with different names, you need to completely copy the entire folder (most often do so) and change the necessary files.
Before plunging into the direction of Helm - the package manager, for which I am telling all this, let's see how Helm works with dependencies.
Work with dependencies
With dependencies Helm works hard. First, there is a requirements.yaml file that fits with what we depend on. While working with requirements, it makes requirements.lock - this is the current state (impression) of all dependencies. After that, he downloads them to a folder called / charts.
There are tools to control: who, how, where to connect - tags and conditions , with the help of which it is determined in which environment, depending on which external parameters to connect or not to connect any dependencies.
Let's say you have PostgreSQL for the Staging environment (or RDS for Production, or NoSQL for tests). By installing this package in Production, you do not install PostgreSQL, because it is not needed there - just with the help of tags and conditions.
What is interesting here?
- Helm mixes all the resources of all dependencies and applications;
- sort -> install / update
After we have downloaded all the dependencies in / charts (these dependencies can be, for example, 100), Helm inside it takes and copies all the resources. After he has rendered the templates, he collects all the resources in one place and sorts them in some kind of his own order. You cannot influence this order. You have to decide for yourself what your package depends on, and if the package has transitive dependencies, you need to include them all in the description in the requirements.yaml. This must be borne in mind.
Batch manager
Helm installs applications and dependencies, and you can tell Helm install — and it will install the package. So this is a package manager.
At the same time, if you have an external repository in which you are uploading a package, you can not access it as a local folder, but simply say: “From this repository, take this package, install it with such and such parameters”.
There are open repositories with a large number of packages. For example, you can run: helm install -f prod / values.yaml stable / wordpress
From the repository of stable you take wordpress and install to yourself. You can do everything: search / upgrade / delete. It turns out, indeed, Helm - package manager.
But there are downsides: all transitive dependencies must be turned inward. This is a big problem when transitive dependencies are independent applications, and you want to work with them separately for testing and development.
Another disadvantage is end-to - end configuration . When you have a database and its name needs to be transferred to all packages, it is possible, but difficult to do.
Most often it does not happen that you have installed one small bag, and it works. The world is complex: the application depends on the application, which in turn also depends on the application - you need to tweak them somehow cleverly. Helm does not know how to support it, or supports it with big problems, and sometimes you have to dance a lot with a tambourine to make it work. This is bad, so the “package manager” on the scheme is highlighted in red.
Assembly and packaging
"You can not just take and" run the application in Kubernetes. You need to build it, that is, make a Docker image, write it to the Docker registry, etc. Although all the definition of the package in Helm is. We define what a package is, what features and fields there should be, signatures and authentication (your company's security system will be very pleased). Therefore, on the one hand, the build and packaging seems to be supported, and on the other, the work with Docker images is not configured.
Helm does not allow you to start the application without a Docker image. At the same time, Helm is not configured to build and package, that is, in fact, it does not know how to work with Docker-images.
This is the same as if, in order to make an upgrade install for some small library, you would be sent to a remote folder to run the compiler.
Therefore, we say that Helm does not know how to work with images.
Development
The next headache is development. In development, we want to quickly and conveniently change our code. The time has passed when you punched holes on punched cards, and the result was obtained after 5 days. Everyone is used to replacing one letter with another in the editor, pressing the compilation, and the already changed program works.
It also turns out that when changing the code, a lot of additional actions are needed: prepare a Docker file; Run Docker to create an image; somewhere to push it; deploy to the kubernetes cluster. And only then you will get what you want on Production, and will be able to check the operation of the code.
Another inconvenience is due to the destructive helm upgrade upgrade. You looked at how everything works, through kubectl exec looked inside the container, everything is fine. At this point, you are launching an update, a new image is being downloaded, new resources are being launched, and old ones are being deleted - everything must be started from the very beginning.
The biggest pain is the big images . Most companies do not work with small applications. Often this if not supermonolith, then at least a small monolithic. Over time, the growth of annual rings, increases the amount of code base, and gradually the application becomes quite large. I have come across more than once Docker images larger than 2 GB. Imagine now that you make a change of one byte in your program, press a button, and a two-gigabyte Docker image begins to assemble. Then you press the next button, and the transfer of 2 GB to the server begins.
Docker allows you to work with layers, i.e. checks if there is one layer or another and sends the missing one. But the world is such that more often it will be one big layer. While 2 GB will go to the server, while they and the Docker-registry come to Kubernetes, roll out all the boxes, until you finally start - you can safely drink tea.
Helm does not provide any help in working with large Docker images. I believe that this should not be, but the Helm developers know better than all users, and Steve Jobs smiles at this.
The development block also turned red.
Environment Automation
The last area, environment automation, is an interesting area. Before the Docker world (and Kubernetes, as a related model), it was not possible to say: “I want to install my application on this server or on these servers, so that there are n replicas, 50 dependencies, and it all works automatically!” that was, but was not!
Kubernetes provides this and it is logical to use it somehow, for example, to say: “I’m deploying a new environment here and I want all the development teams that have prepared their applications to simply press a button, and all these applications are automatically installed on the new environment” . Theoretically, Helm should help with this, so that the configuration can be taken from an external data source - S3, GitHub - from anywhere.
It is desirable that in Helm there was a special button “Make me feel good at last!” - and it would immediately become good. Kubernetes allows you to do this.
This is especially convenient because Kubernetes can be run anywhere, and it works through the API. Running minikube locally, or in AWS, or in the Google Cloud Engine, you get Kubernetes right out of the box and work the same everywhere: press a button, and everything is all right at once.
It would seem, of course Helm allows you to do this. Because otherwise, what was the point of creating Helm?
But it turns out, no!
Automation environment absent.
Alternatives
When there is an application from Kubernetes that everyone uses (this is now in fact the solution number 1), but at the same time Helm has the problems discussed above, the community could not help but answer. It began to create alternative tools and solutions.
Template engines
It would seem that, as a template engine, Helm solved all the problems, but still the community creates alternatives. I recall the problems of the template engine: verbosity and code reuse.
A good representative here is Ksonnet. It uses a fundamentally different data model and concepts, and it does not work with Kubernetes resources, but with its own definitions:
prototype (params) -> component -> application -> environments.
There are parts (parts) that make up the prototype. The prototype is parameterized by external data, and a component appears. Several components make up an application that can be run. It runs in different environments. Some understandable links to Kubernetes resources are here, but there may not be a direct analogy.
The main purpose of the emergence of Ksonnet was, of course, the reuse of resources . They wanted to make it so that you, once having written the code, could later use it anywhere, which increases the speed of development. If you create a large external library, people can constantly place their resources there, and the whole community will be able to reuse them.
Theoretically it is convenient. I practically did not use it.
Package managers
The problem here, as we remember, is nested dependencies, end-to-end configs, transitive dependencies. Their Ksonnet does not solve. Ksonnet has a very similar model to Helm, which also defines the list of dependencies in the file, it is uploaded to a specific directory, etc. The difference is that you can make patches, that is, you prepare a folder in which you put patches for specific packages.
When you upload a folder, these patches overlap, and the result obtained by merging several patches can begin to be used. Plus there is a validation of configurations for dependencies. This may be convenient, but it is still very raw, there is almost no documentation, and the version has stopped at 0.1. I think it's too early to use it.
So, the package manager is KubePack , and I haven’t yet seen other alternatives.
Development
Solutions are divided into several different categories:
- try to work on top of Helm;
- instead of helm;
- they use a fundamentally different approach, in which they try to work directly in a programming language;
- and other variations about which later.
1. Development over Helm
A good representative is Draft . Its goal is to be able to try the application before the code is committed, that is, to see the current status. Draft uses the Heroku-style programming method:
- there are packages for your languages (pack);
- write, say, in Python "Hello, world!";
- press the button, a Docker file is automatically created (you do not write it);
- resources are automatically created, it all starts, it is sent to the docker-registry that you had to configure;
- The application starts automatically.
This can be done in any directory with code, everything seems to be quick, easy and good.
But in the future it is better to start working with Helm anyway, because Draft creates Helm-resources, and when your code reaches production-ready state, it’s not worth hoping that Draft will create Helm-resources well. You will still have to create them manually.
It turns out that Draft is needed to quickly start and try at the very beginning before you have written at least one Helm-resource. Draft - the first contender for this direction.
2. Development without Helm
Development without Helm Charts involves building the same Kubernetes manifestos that would otherwise be built through Helm Charts. I suggest three alternatives:
- GitKube;
- Skaffold;
- Forge.
They are all very similar to Helm, the differences in small details. In particular, some solutions assume that you will use the command line interface, and Chart assumes that you will do git push and manage hooks.
In the end, you still run docker build, docker push and kubectl rollout. All the problems that we listed for Helm are not solved at all. It is just an alternative with the same drawbacks.
3. Development in the language of the application
The next alternative is the development in the language of the application. Here is a good example - Metaparticle . Let's say you write code in Python, and right inside Python you start to think what you want from the application.
I see this as a very interesting concept, because most often the developer does not want to think about how the application should work on the servers, what is the correct way to set the config in sysconfig, etc. It is important working application.
If it is correct to describe a working application, what parts it consists of, how they interact, theoretically some kind of magic will help turn this knowledge from the point of view of the application into Kubernetes resources.
With the help of decorators we determine: where the repository is located, how to properly push it; what services are and how they interact with each other; there should be so many replicas on the cluster, etc.
I don’t know about you, but personally I don’t like it when instead of me some kind of magic decides that you need to make such a Kubernetes config from the Python definitions. And if I need another?
All this works up to a certain limit, while the application is fairly standard. After that, problems begin. Let's say I want the preinstall container run before the main container runs, which will perform some actions to configure the future container. This is all done in the framework of Kubernetes-configs, but I don’t know whether it is done in the framework of Metaparticle.
I cite commonplace simple examples, and there are many more of them, there are a lot of parameters in the specification of Kubernetes-configs. I am sure that they are not fully present in decorators like Metaparticle.
Metaparticle appears on the diagram, and we discussed three alternative approaches to Helm. However, there are additional, and they are very promising in my opinion.
Telepresence / Ksync is one of them. Suppose you have an application that has already been written, there are Helm-resources that are also written. You installed the application, it started somewhere in the cluster, and at this moment you want to try something, for example, change one line in your code. Of course, I’m not talking about Production clusters, although some of them even rule something on Production.
The Kubernetes problem is that you need to transfer these local edits via the Docker update, via the registry, to Kubernetes. But to bring to the cluster one modified line can be in other ways. You can synchronize the local and remote folder, which is located on the hearth.
Yes, of course, at the same time there should be a compiler in the image, everything necessary for Development should be there in place. But what a convenience: install the application, change a few lines, synchronization works automatically, the updated code becomes on the page, we start the compilation and tests - nothing breaks, nothing updates, no destructive updates, as in Helm, does not happen, we get the updated one that works attachment.
In my opinion, this is an excellent solution to the problem.
4. Development for Kubernetes without Kubernetes
I used to think that there was no point in working with Kubernetes without Kubernetes. I thought that it’s better to make the Helm-definitions once and use the appropriate tools so that in local development you can have the same configs for everything. But over time, I was faced with reality and saw applications for which it is extremely difficult to do. Now I have come to the conclusion that it is easier to write a Docker-compose file.
When you do a Docker-compose file, you run all the same images, and mount, just like in the previous case, the local folder on the folder in the Docker container, just not inside Kubernetes, but just in Docker-compose, which is running locally . Then just run the compiler, and everything works fine. The downside is that you need to have additional configs for Docker. The advantage is speed and simplicity.
In my example, I tried to run in minikube the same thing that I tried to do with Docker-compose, and the difference was huge. It worked badly, there were incomprehensible problems, and you raise Docker-compose in 10 lines and everything works. Since you are working with the same images, it guarantees repeatability.
Docker-compose is added to our scheme, and as a whole, it turns out that the community summed up with all these solutions to solve the development problem.
Assembly and packaging
Yes, assembly and packaging is a problem for Helm, but probably the developers of Helm were right after all. Each company has its own CI / CD system that collects artifacts, checks and tests. If it is already there - why close this problem in Helm, when everyone has his own? Perhaps one correct solution will fail, each will have modifications.
If you have a CI / CD, there is integration with an external repository, dockers are automatically collected for each commit, set tests are run, and you can press the button and close it all, you have solved the problem - it is not left.
CI / CD is really a solution to the build and packaging problem, and we paint it green.
Results
From 5 directions, Helm itself closes only the template engine. Immediately it becomes clear why it was created. The rest of the solutions the community has jointly added, the problems of development, assembly and packaging are completely solved by external solutions. This is not completely convenient, it is not always easy to do within the framework of the established traditions within the company, but it is possible, at least.
Future helm
I am afraid that none of us knows for sure what Helm should come to. As we have seen, the Helm developers sometimes know better than us what needs to be done. I think that most of the problems that we have considered will not be closed by the next releases of Helm.
Let's see what has been added to the current Road Map. There is such a Kuberneres Helm repository in the community , in which there are development plans and good documentation on what will happen in the next version of Helm V3 .
Tiller disclaimer, only cli
We have not yet discussed these details, so we will consider now. The Helm architecture consists of two parts:
- , (cmd ..).
- Tiller — , Kubernetes.
Tiller handles requests that you send through the Command Line Interface. So you say: “I want to install this Chart” - and in fact Helm collects it, packs it, sends it to Tiller, and he already decides: “Oh, something has come to me! It seems that this is projected into the next Kubernetes resources ”- and it launches.
According to the Helm developers, one Tiller should work per cluster and manage the entire technology zoo that is in the cluster. But it turned out that in order to properly share access, it is more profitable for us to have not one but several Tillers - for each namespace its own. So that Tiller can create resources only in the namespace, in which it is running, and did not have the right to go to the neighboring ones. This makes it possible to divide the area of responsibility, the area of visibility for different teams.
The next version of V3 Tiller will not.
And why is he even needed? In essence, it contains information transmitted via the Command Line Interface, which it uses to launch resources in Kubernetes. It turns out that Kubernetes already contains exactly the same information that is contained in Tiller. But I can do the same with kubectl cli.
Instead of Tiller, an event system is introduced . On all new resources that you send to Kubernetes via the Command Line Interface there will be events: settings, changes, deletions, pre-and post-events. There are quite a few of these events.
Chart Lua Scripts
Some of them you cannot edit, some you can, and you can do this with the help of lua scripts . At the stage of creating a Chart, you add a collection of lua-scripts that you put into a special folder. They will fully track the handling of external events. It must be convenient. In fact, some of the problems we discussed earlier can be solved with this approach.
Lua and events can close development problems, because it will be possible to control what needs to be done when something happens, both on the server side and on the automation side of the environment too.
Unfortunately, there is still no implementation, one can only guess. But theoretically, the most important problem for me is to automate the environment, we can completely close it. You can write a new application in Kubernetes, send some configs to it, and using the mechanism that you program yourself, the application will install everything that you want. Let's see what happens.
Release object + release release secret
In order to fully track the release process, a Release-object will appear with information about which Release was written. It has not yet been announced that it will be a Release object, how it will be created, maybe it will be a CRD, or maybe not.
Binding to release namespace
This release object will be created in the namespace in which everything was running, and accordingly because of this, it is not necessary to bind Tiller to the namespace — the problem I mentioned a little earlier.
CRD: controller
Additionally, in the distant future, developers are thinking of creating a CRD controller for Helm for those cases that cannot be covered by the standard push model. But information about the implementation of this is not at all.
Collection of recipes
In total, I recommend using the system.
Of course, this is Helm . It is created by the community, all alternative solutions are created by independent teams, about which we are not sure how long they will exist. Unfortunately, the day after tomorrow they may abandon their projects, and you will remain at the bottom of the trough. And Helm is, after all, a part of Kubernetes. In addition, it will somehow develop and, perhaps, solve problems.
Of course, CI / CD , automatic assembly by commit. In our company, we have done integration with Slack., we have a bot that tells you when a new build went through in master, and that all the tests were successful. You say to him: “I want to install it in Staging” - and he installs, say: “I want to run a test there!” - and he launches. Pretty comfortable.
For development use Docker-compose or Telepresence.
Multiple versions of the same service
In the end we will analyze the situation when there are two applications A and B, which depend on C, but C different versions. Need to solve this problem:
- for development, because in fact we must develop the same, but two different versions;
- for release;
- for name conflicts, because in all standard package managers, installing two packages of different versions can cause problems.
In fact, Kubernetes decides everything for us - you just need to use it correctly.
I would advise you to create 4 Chart in terms of Helm, 3 repositories (for the C repository this will be just two different branches). What is most interesting, all installations for v1 and for v2 should contain information about the version or for which service it was created. One of the solutions on the slide, Appendix C; the release name indicates that this is version v1 for service A; The service name also contains a version. This is the simplest example you can do in a completely different way. But most importantly, the names were unique.
The second is transitive dependencies, and more complicated here.
For example, you are developing a chain of services and want to test A. For this, you must pass all the dependencies on which A depends, including transitive, to the Helm-definition of your package. But at the same time, you want to develop B and test it too - how to do it is incomprehensible, because you need to put all transitive dependencies in it as well.
Therefore, I advise you not to add all dependencies inside each package, but to make them independent and from the outside manage what is running. This is inconvenient, but it is the lesser of two evils.
useful links
• Draft
• GitKube
• Helm
• Ksonnet
• Telegram stickers: one , two
• Sig-Apps
• KubePack
• Metaparticle
• Skaffold
• Helm v3
• Docker-compose
• Ksync
• Telepresence
• Drone
• Forge
Speaker Ivan Glushkov's profile on GitHub , in twitter , on Habré .
Great news
On our youtube channel, we opened a video of all the reports on DevOps from the RIT ++ festival . This is a separate playlist , but in the full list of videos there is a lot of useful information from other conferences.
It is even better to subscribe to the channel and newsletter , because in the upcoming year there will be a lot of devos waiting for us : in May, within the framework of RIT ++; in the spring, summer and autumn as a HighLoad ++ section, and a separate autumn DevOpsConf Russia .
Source: https://habr.com/ru/post/431540/
All Articles