Double Bottom: a post about a modern ecosystem, in which we pay data for everything, and also about fast Blockchain Protocols
An introduction that is only partially relevant.
In the middle of this year, one of my friends was supposed to introduce me to a very useful business partner. Before sending the letter, he wrote to me that, probably, that person would search for my name on the Internet, and that before that it would be nice to clean my Facebook Account.
I went to Facebook and looked through my profile - the usual posts of an ordinary person, nothing supernatural. When I asked what was wrong, my friend answered that when he opens my account, he sees a strange picture where I hug with a plush duck.
I uploaded this photo to Facebook five years ago, and safely forgot about the fact that it once happened. I opened my profile in Incognito Mode and saw the same duck. Why out of the thousands of photos that I uploaded to Facebook over the 7 years of my account, does Facebook show this to strangers? How long have people searching for me on the Internet found this page with a photo that is compromising me? And most importantly - how much other similar information I managed to leave on the Internet, which in the future could harm me?
In fact, in this particular story, to a large extent, the fault lies with me - I myself laid out this photo, and put it myself (or rather, did not change it) on it the right for the whole world to see it. But here lies another problem, which I began to think about that day. This is the problem that the services that collect our information use it in an opaque and incomprehensible way. Either Facebook globally, or I myself shortly after the publication of this photo, I changed the default settings to “only for friends” for all new photos, and as a result, this photo was shown to any person who searched me on the Internet for five years, like my last public photo. At the same time I could not know about it, because when I was looking for myself and opened the first link to Facebook, I saw a full profile, not a public one.
')
When this happened, the first thing I did was delete all my social media profiles. After that, I began to think about how much more I leave traces due to the fact that I do not understand how the services I use use the information they collect.
For example, I think many people know the AmIUnique service, which tells you whether you can be uniquely identified by information that can be gathered from request headers or using JavaScript. I checked all my browsers, and each browser on each of my machines is absolutely unique!
Let's think about it again. Each browser creates an imprint that allows me to uniquely identify between sites, for a long time, in or outside Incognito Mode. Well, of course no one collects such an imprint, right? I thought so, until I once installed the DuckDuckGo plugin, which shows how much analysts are hanging on each site.
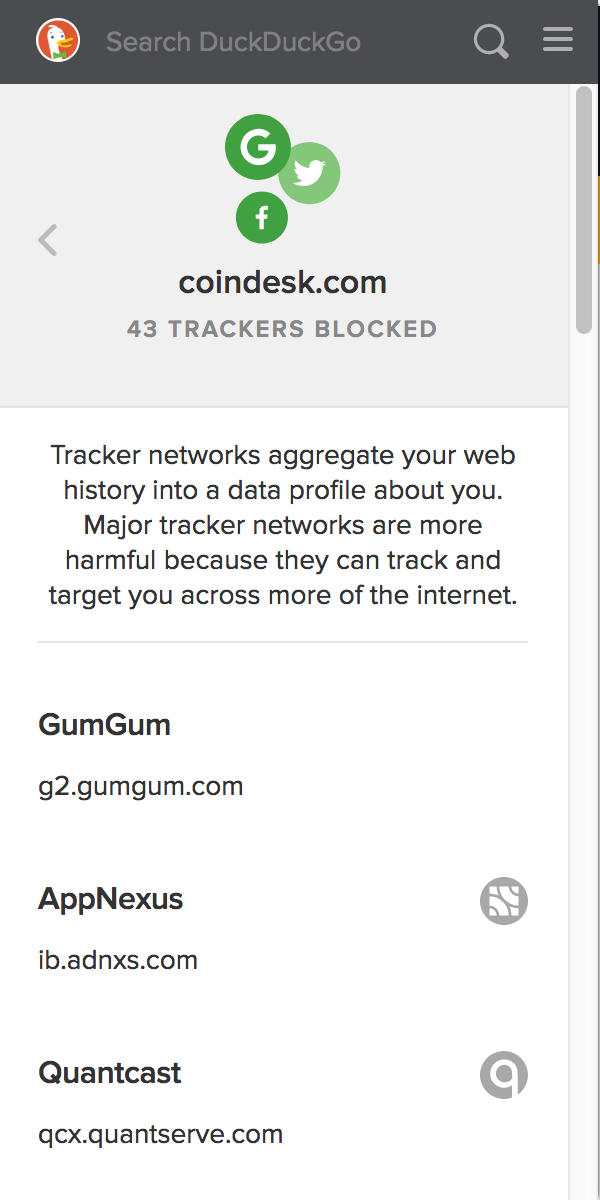 This is a nightmare! Every site I visit records this visit to a dozen different analytics. And of course in your logs. And some browsers also send each visited URL to their servers.
This is a nightmare! Every site I visit records this visit to a dozen different analytics. And of course in your logs. And some browsers also send each visited URL to their servers.Then I imagined what would happen if the logs from some site with controversial content, which I entered Incognito Mode with my unique fingerprint, leaked, and the same logs of any site where I identified myself. But in general, this article is not quite about that.
Muting the wall is not an option
This problem seems to have a solution. You can install the Tor Browser, use DuckDuckGo, and never identify yourself anywhere. I know a lot of people who do that. But only this is not convenient! And this is only a partial solution.
I do not want to not use Google Maps, because they are convenient. But they are spying on me. As recently as last week, they proudly sent me my Timeline, where they showed my every move over the past week. What is the bottom! Why can not I install the application in order to create routes without being spied on me? I did not even install it, I just bought a phone and told him my email, and suddenly all my movements merge with Google and are associated with my name.
As a result, I came to the conclusion for myself that I had already inherited so much about myself that now it is too late to change something, and that big companies put me in a situation in which I have to either pay with my data for services or live in an isolated world no amenities at all. I restored all my accounts (the fact that a “deleted” account can generally restore this separate bottom), and went to solve the problem on a large scale otherwise.
Blockchain to the rescue
I discussed the situation with a number of guys, and during the discussion I began to think that the idea behind Smart Contracts was very attractive for solving the bottom in which we, as a society, were lying, rejoice in the convenience of this bottom day we unconsciously merge megabytes of personal information to large companies without the slightest idea what this will ultimately turn out for us.
I was very attracted to the idea of the existence of services from which I can study the code on the Backend, and be sure that this is really the code that is executed when I send a request. And, if a protocol is developed specifically for this purpose, the development of scalable decentralized services on top of such a protocol should be fairly simple. Even simpler than developing centralized services without such a protocol, and certainly easier than trying to develop a similar decentralized service without a ready infrastructure.
Inspired by the idea, I went to the guys who were involved in Blockchain to start a revolution. From communication with them, I, unfortunately, quickly realized that today at the Blockchain nothing can be picked up at all, because it is terribly slow. It has been terribly slow since that day in 2014 when Ethereum was launched, and of course, since then, someone has already seriously taken up speeding it up, right? And maybe I just need to go and figure out who is writing a good, fast Blockchain Protocol, and start working with them. I spent a couple of months on a deep study of the situation and realized that everything was bad there too.
What day we will not talk
I will not talk about any ICOs at all. This is also the perfect bottom, and this also caused irreparable damage to the Blockchains reputation, but these ICOs have nothing to do with the technology itself, and are pure speculation.
About the bottom in the deblocking of protocols
The number of protocols that began to be developed from 2014, which were supposed to speed up or become faster than Ethereum, is amazing. In order to be in the subject, I probably had to read about a hundred articles. But three things were surprising: the first is the fact that in four years a huge amount of such protocols raised an incredible amount of money - 30-100 million dollars each. The second is that no protocol was ever launched (EOS is an exception from both these points - it raised a lot more than $ 100 million, and was launched, but it is a fully centralized protocol controlled by the 21st company, so it is not relevant in context of this article). And the third - that none of the proposed protocol, it would seem, does not solve the problem entirely.
Since 2011 I have been developing distributed databases. I have some good understanding of how distributed systems work, and how difficult and complex the task is to develop such a system. Developing a good scalable protocol is a huge amount of engineering work, and in fact, in many ways, just a clever use of some already known technologies.
But each protocol, which raises tens of millions of dollars, is fixated on one idea, and is actively promoting it everywhere, without at all touching other problems. DFinity each time talks about its Threshold Relays for a random number generation and that this is a panacea for everything. Algorand got hooked on the fact that it is impossible for the creators of the blocks to be known in advance, and speaks about it everywhere. Conflux suggested using DAG instead of Chain, and this should solve all the problems. The authors of each protocol spend an incredible amount of time on any presentation to advertise this one idea, and very little to tell about other aspects of their protocol. And these other aspects are always worked out so badly that it is impossible to believe that the authors do not understand this.
And this bottom goes deeper. I did not accidentally choose Algorand and Conflux as examples. The authors of both protocols are Turing Award Winners. This is the most prestigious award in the field of Computer Science. They are people on whom it is necessary to be equal. After all, it can not be that they tried to deceive people, and just use their name and position to raise 60 million dollars and deceive the whole planet?
But there is a suspicion that this is exactly what is happening. I was in Prague three weeks ago at DevCon4 and went to the Silvio Micali presentation from Algorand. For the context, the main idea of Algorand, which they are trying to sell with incredible force, is that the participant in the protocol who has to do some kind of action (propose a block, or take part in a consensus) is not known to anyone except himself until he will not do this action. The idea behind this sounds reasonable enough: if such a participant is known in advance, then he can be bribed, or he can be blocked by DDoS, thereby disrupting the protocol. Silvio is promoting this idea very actively. He argues that even if an adversary can bribe anyone instantly, their protocol will stand:
Go

There are two problems with what and how Silvio sells.
The first is far from the biggest problem facing the development of the protocol. It is very strange to focus so much attention on her.
The second is, in principle, does not solve the problem of bribery! When I was at Silvio's presentation, I asked him a question that in principle nothing prevents to raise a smart contract to Ethereum, in which any participant can send proof that he will be the next block producer or consensus participant in Algorand, along with a private key, and get a reward for it, thereby completely leveling all the advantages of the fact that he is not known to anyone except himself in advance. The fact that he is known to himself is sufficient to be bought off. Yes, the attacker cannot find it himself, but the participant can still find the attacker.
To which Silvio responded that any Blockchain operates under the assumption that 50% of the participants (in this case weighted by tokens) are honest, and that a participant who in principle can be bribed is by definition not honest.
Whether this assumption is reasonable or not is a separate topic (spoiler: it is unreasonable). What is important is that if we accept the assumption that 50% of the participants in principle cannot be bribed, then half of the Algorand idea becomes completely useless, because there is nothing terrible when participants who do some actions are known in advance because they cannot be bribed .
It is hard to believe that Turing Award Winner and his team do not understand that the idea of hiding participants does not solve the problem of bribery. And that the assumption of 50% non-purchaseable participants is unwise. And that a complex scalable protocol is much more than some small idea about hiding participants for the time being.
It is much easier to believe that Silvio uses its name to raise $ 60 million for an unfinished idea from people who don’t miss an opportunity to invest in Turing Award Winner. This, of course, is my value judgment.
I myself was not able to attend the presentation of Andrew Yao from Conflux, the second of the two Turing Award Winners I mentioned, but he spoke at Stanford the other day, and from communicating with those who went, it seems that so far the protocol has not been worked out either. Their article also addresses only one of many problems in order to write a scalable protocol, and there is unofficial information that Conflux also just tried to raise $ 60 million. It is not known whether they were able to raise all 60.
And these are two of the most outstanding examples, because in them a huge amount of money for not developed technology was raised by the best of the best - the people who received the most prestigious Computer Science award, which should serve as an example to follow.
I can easily name almost a dozen protocols that have raised up to 30-50 million each, with very well-known PhDs using their name to raise awareness of the project. In each example, at the time of raising money, these protocols had only an article that solves (or, as is the case with Algorand, does not solve) any one of dozens of problems, and the name of this well-known PhD. And everything, 30 million in a pocket.
What's this all about
I strongly believe in the following theses:
- The scalable usable Blockchain Protocol can greatly assist in developing an ecosystem of services that are as convenient as existing services from large corporations, but do not use user data as payment. As I wrote above, the Blockchain is needed, because:
- It allows you to audit the code that is executed on the backend;
- It makes it possible to easily develop such services using the distributed infrastructure of the network itself;
- It provides an opportunity to create reasonable ways for developers to monetize their applications.
- To develop such a protocol does not need 60 million dollars. At least not right away. Eminent people, who raised tens of millions of dollars on empty promises, greatly shaken people's faith that someone could develop such a protocol and not have the goal of simply raising a lot of money and never run anything.
I really want this protocol to start, and to develop on it analogues of existing services today without collecting personal data and with transparent policies. So that we as a society can audit the code of such services and promote them to the masses, and not choose between selling our personal data for convenience and not using anything that people have developed over the past decade.
But as a person who wants to do all this, I have to get out twice from a very deep bottom. People are so used to paying for all their personal data that they no longer see this as a problem. We are slowly, like a frog in boiling water, hit this bottom, and convincing people of the need for decentralized services will be a far from trivial task. It makes no difference to people that large companies know about their every movement, and charge personal data for the opportunity to post photos with cats or call a taxi more conveniently than by voting on the road.
But before we even begin to convince people of this, if I think that to create such services you need a fast and scalable Blockchain protocol and want to write such a protocol, then I need to first convince people that we are not just another team that wants to quickly cut tens of millions and not to write anything, and that in order to write a truly working scalable protocol, people with experience in the development of distributed systems are needed, not PhDs, who have never run anything in production.
Let's see how it goes
I did not manage to buy a paid account from TM, so I don’t publish any links.
All the code we write is open on GitHub.
We also publish a lot of good content about Blockchain Sharding in English.
Everything is easy to find. DuckDuckGo to the rescue!
All the code we write is open on GitHub.
We also publish a lot of good content about Blockchain Sharding in English.
Everything is easy to find. DuckDuckGo to the rescue!
Source: https://habr.com/ru/post/431464/
All Articles