Far Fields mic (Mic array) - the inconspicuous hero in the smart column
In this article I want to talk about my long-time passion - to study and work with far fields mic (mic array) - arrays of microphones.
The article will be interesting to the keen construction of their voice assistants, she will answer some questions for people who perceive engineering as an art, and also for those who want to try themselves in the role of Q ( This is from Bond ). My humble story, I hope, may help you to understand why a clever speaker-assistant, made strictly according to the tutorial, works well only if there is a complete absence of noise. And so bad where they are, for example in the kitchen.
Many years ago I became interested in programming, I started writing code simply because wise teachers only allowed me to play games written by myself. It was in the year 87 and it was the Yamaha MSX. On this topic at the same time was the first startup. Everything is strictly according to wisdom: “Choose a job you like, and you will not have to work a single day in your life” (Confucius).
And so years have passed, and I'm still writing code. Even a hobby with a code - well, except for roller skating, to warm up the brain and "I will not forget matane" is working with Far Fields mic (Mic array). In vain that the teachers spent time with me.
What it is and where it applies
In the voice assistant that listens to you, there is usually an array of microphones. We also find them in video conferencing systems. With collective communication, the lion's share of attention is paid to speech, we naturally, not constantly when we communicate, look at the speaker, and speaking exactly into a microphone or a headset, it is embarrassing and inconvenient.
Practically everyone, a cell phone manufacturer who respects a client, uses 2 or more microphones in his creations (yes, yes, behind these holes are microphones above, below, behind). For example, in the iPhone 3G / 3GS it was the only one, in the fourth generation of iPhones there were two, and in the fifth there were already three microphones. In general, this is also an array of microphones. And all this for better hearing of sound.
But back to our voice assistants.
How to increase the range of hearing?
"need big ears"
A simple idea: if in order to hear someone nearby, one microphone is enough, then in order to hear from afar, you need to use a more expensive microphone with a reflector, similar to the ears of chanterelles:

(Wikipedia)


 In fact, this is not part of the furry suite, but a serious device for hunters and scouts.
In fact, this is not part of the furry suite, but a serious device for hunters and scouts.

The same, only on resonator tubes

In the habitat.
(Taken from https://forum.guns.ru )
Diameter of a mirror is from 200 mm to 1,5m
(for more, see http://elektronicspy.narod.ru/next.html )
"Need more microphones"
Or maybe, if you put a lot of cheap microphones, then the quantity goes into quality and everything will work out? Zerg-rush microphones only.
Strange, but it works in real life. True with a lot of matane, but it works. And we will tell about it in the next section.
And how to learn to hear on without beautiful horns?

One of the problems of the horn systems is that it is well heard that is in focus. But if you need to hear something from another direction, then you need to make "feint ears" and physically retarget the system in another direction.
And about the signal-to-noise ratio of systems with microphone arrays is somehow better compared to a conventional microphone.
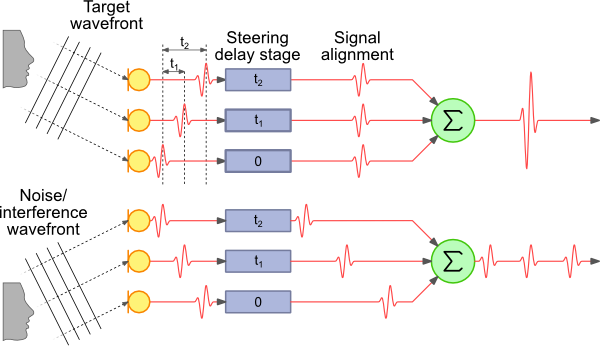
In arrays of microphones, as in their closest relatives - HEADLIGHTS (phased antenna arrays), nothing needs to be turned. Read more in the Beamforming section. Easy to see:

Unfocused microphone (left picture) records all sounds from all directions, and not just what you need.
Where does the long range come from? In the right picture, the microphone attentively listens to only one source. As if focusing, it receives a signal only from the chosen source, and not porridge from possible sources of noise, and simply amplify the clean signal (turn it up) without using complicated noise reduction techniques. Approximately like a shout, but on a matan-colored joint.
What is wrong with noise cancellation?
The use of complex noise cancellation of a lot of flaws means that a part of the signal will leave, along with a part of the signal the sound will change, and to the ear it looks like a characteristic coloring of the sound with a noise and as a result promiscuity. This promiscuity is visible to Russian-speaking people who want to hear from the interlocutor these sizzling ones. Well, and additionally - as a result of noise cancellation, the listener does not hear any identifying signals at all connecting him with the interlocutor (breathing, sniffling and other noises accompanying live speech). This creates some problems, because in colloquial speech this is all audible, and just helps to assess the state and attitude of the interlocutor to you. The absence of them (noise) while we hear the voice causes discomfort and reduces the level of perception, understanding and identification. Well, if you are listening to the voice assistant - noise reduction makes it difficult to recognize both the key phrase and the speech after. True, there is a life hack - the discriminator needs to be trained on a sample recorded with account of the distortions from the noise reduction used.
Those who are familiar with the words cocktail party problem can still go for a coffee or a cocktail, and conduct a field experiment, those who read the mood, continue on.

Briefly about matane, on which it works:
DOA Estimation (determining the direction to the sound source) and beam forming (beamforming)
DOA (determining the direction, and if possible, and localization to the source):
I will be brief, because the topic is very extensive, it is done with the help of white, gray or dark magic (depending on the preferred topic in the IDE) and matan. main A frequent way to play DOA is to analyze correlations and other differences between pairs of microphones (usually opposite in diameter).
Layfkhak: for research it is better to choose an array with a circular arrangement of microphones. Benefit - it is easy to collect statistics from pairs with different distances between microphones - maximum diameter, and to minimum between microphones - if you take pairs along the chords, and with different azimuths (directions) to the source.
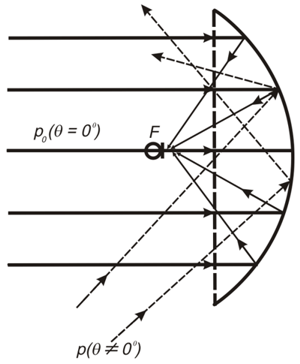
Beam Formation- The easiest and easiest to understand way is Delay & Sum (DAS and FDAS) —beam based on delay and summation.
For visuals:
(Taken from http://www.labbookpages.co.uk/audio/beamforming/delaySum.html )
Life hacking: Do not forget about the different wavelengths and for each frequency we calculate our phase difference tn
An approximate radiation pattern will look something like this.
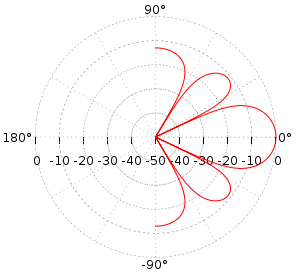
Those who have not forgotten how to smoke matan can take part in JIO-RLS (Joint Iterative Subspace Adaptive Reduced-rank least squares). Much like the taste of gradient descent, you know.

So we summarize: using conventional methods, it is difficult to achieve quality comparable to a matrix microphone. After applying the definition of direction to the source, and as a result of this, we hear only the source that is needed, we get rid of the noise and reverberation of the medium, even that which is poorly audible (Haas effect).
Voice Assistant - how it looks from the inside
So, what does the sound processing circuitry look like for the experienced voice assistant:

The signal from the microphone array goes to the device in which we form a beam to the sound source (beamforming), thereby removing the interference. Then we begin to recognize the sound of this beam, usually it is not enough for the qualitative recognition of the device’s resources, and most often the signal goes to the cloud for recognition (Microsoft, Google, Amazon).
Attentive reader will note: And in the picture with the description there is some kind of square Word not, and why did not immediately recognize it, as promised?
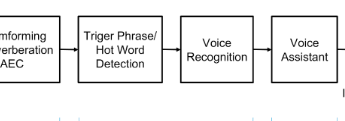
Why on the diagram this one is probably an extra square?
And because constantly broadcast the signal from all sources of noise to the Internet for listening Recognition of any resources is not enough. Therefore, we begin to recognize only when we realized that they really wanted this from us - and for this they said a special spell - ok Google, Siri or Alex, well, or they called Kortan. A classifier Music Word - most often neuronka and works directly on the device. In the construction of the classifier there are also many interesting things, but today is not about that.
And in fact, the scheme looks like this:
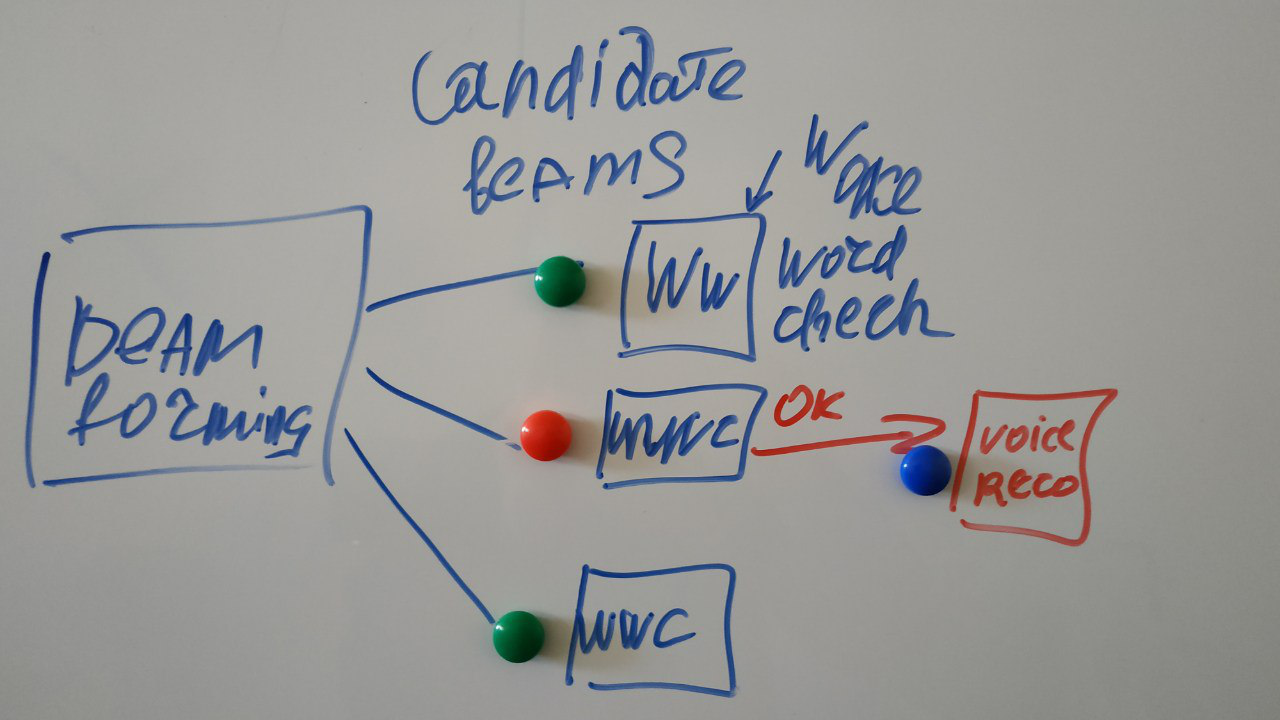
(my doodles)
Several rays can be formed at different signal sources, and we are looking for a special word in each of them. But we will process further the one who said the right word.
The next stage is recognition in the cloud, it has been repeatedly covered on the Internet, there are many tutorials on it.
How can you join this holiday Matana
The easiest way to buy a dev board. Overview of existing devbord: one of the most complete - by reference .
Most friendly for beginners:
https://www.seeedstudio.com/ReSpeaker-4-Mic-Array-for-Raspberry-Pi-p-2941.html
https://www.seeedstudio.com/ReSpeaker-Mic-Array-v2-0-p-3053.html
based on XMOS XVF-3000.
Made as I like it - an open interface FPGA controls the microphones of the matrix, communicating with it via SDA.
My feats of crossing the Android Things and Mic Array:
Of course, there are quite a few examples for this board (Voice), but it’s just convenient for me to use it under Things.
Arguments for Things:
You can build a flexible and powerful tool:
- convenient that you can use the screen as a separate device
- can be used as a headless device, i.e. make a transfer over the network (create api for transfer to another device)
- convenient debugging
- many libraries, including for transmission over the network;
- tools for analysis - a lot.
- and if it seemed a little, it is possible to connect the Sishny libraries
For example, I use:
- sound file analysis
- HRTF,
- Training \ building classifiers.
And then if you have to port / rewrite the code to some embed, then how easy it is to do it with Java code.
Unfortunately, the example from the authors of the board for Things was a bit inoperative, so I made my demo project (of course, I can).
In short, what is there - all the black magic on quick interrogation of microphones, FFT do in C ++, and visualization, analysis, network interaction - in Java.
Future development plans
The source of the plans and at the same time inspiration: ODAS .
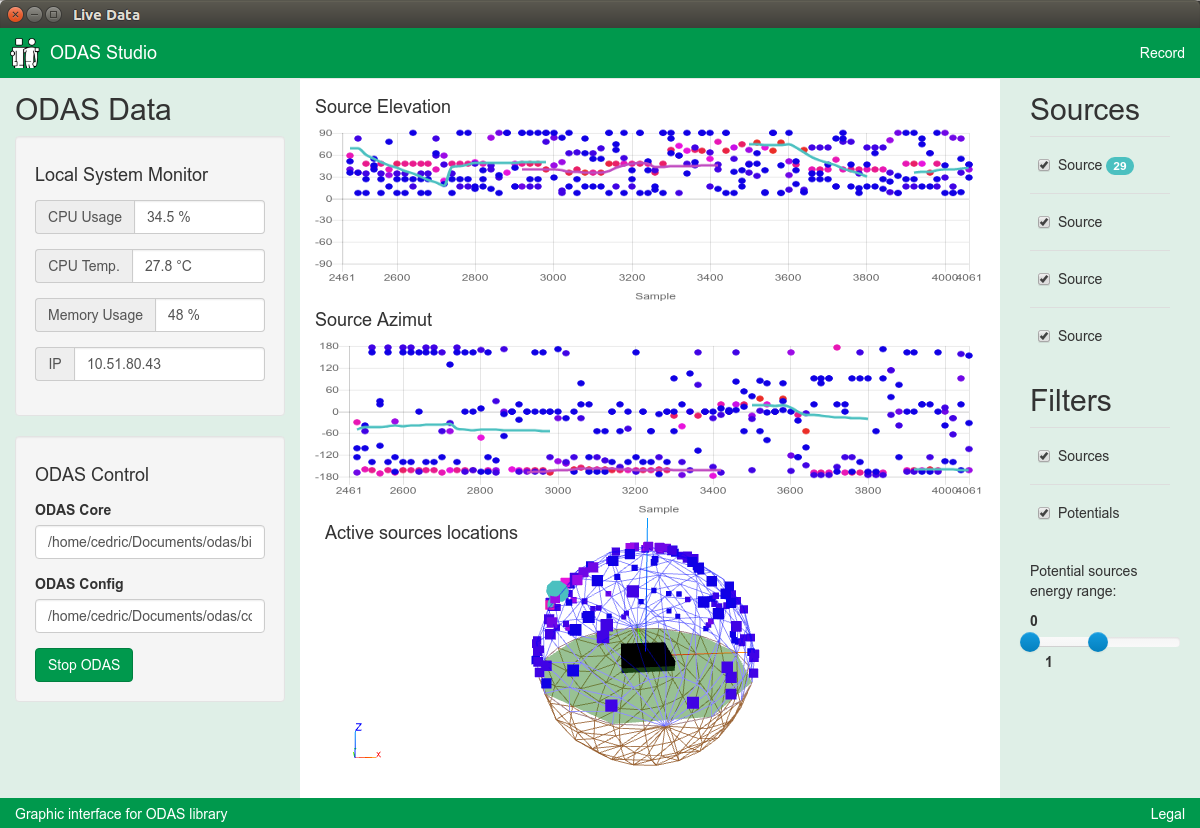
I just want to do the same, only on Things and without glitches.
- Because ODAS is a little awkward to use.
- I need a normal tool for work
- Because I can and I like this topic.
- Used hardware and software meet the complexity of the problem.
My plans are based on this (my) repository .
And remind
"If you have something to supplement or criticize, feel free to write about it in the comments, because one head is worse than two, two are worse than three, and n-1 is worse than n" nikitasius
')
Source: https://habr.com/ru/post/431144/
All Articles