Event machine on guard of the life cycle
Disclaimer: This article describes an unobvious solution to an unobvious problem. Before rushingeggsput it into practice, I recommend reading the article to the end and think twice.

Hello! When working with code, we often have to deal with state . One of these cases is the life cycle of objects. Managing an object with several possible states can be a very nontrivial task. Add asynchronous execution to this and the task becomes more complicated. There is an effective and natural solution. In this article I will talk about the event machine and how to implement it in Go.
Why manage the condition?
For a start, we will define the concept itself. The simplest example of state is files and various connections. You can not just take and read the file. It must first be opened, and at the end desirable be sure to close. It turns out that the current action depends on the result of the previous action: the reading depends on the discovery. The saved result is the state.
The main problem with the state is complexity. Any state automatically complicates the code. You have to store the results of actions in memory and add various checks to the logic. That is why stateless architects are so attracted to programmers - no one wants troubles difficulties. If the results of your actions do not affect the execution logic, you do not need the state.
However, there is one property that makes one reckon with difficulties. The state requires you to follow a specific order of action. In general, such situations should be avoided, but this is not always possible. An example is the life cycle of program objects. Thanks to good state management, it is possible to obtain predictable behavior of objects with a complex life cycle.
Now let's figure out how to do it cool .
Automatic as a way to solve problems

When people talk about states, finite automata immediately come to mind. It is logical, because an automaton is the most natural way to control a state.
I will not delve into the theory of automata , information on the Internet is more than enough.
If you look for examples of finite automata for Go, you will definitely meet Rob Pike’s lexer (Rob Pike). A great example of an automaton in which the input alphabet is processed data. This means that the state transitions are caused by the text that the lexer processes. Elegant solution to a specific problem.
The main thing to understand is that an automaton is the solution of a strictly specific problem. Therefore, before considering it as a remedy for all problems, you must fully understand the task. Specifically, the entity you want to manage:
- states - life cycle;
- events - what exactly causes the transition to each state;
- work result - output;
- execution mode (synchronous / asynchronous);
- main usage scenarios.
Lexer is beautiful, but he changes his state only because of the data that he himself processes. And how to be in a situation when the user calls the transitions? This is where the event automat can help out.
Real example
To make it clearer, I will analyze an example from the phono library.
For full immersion in context, you can read the introductory article . This is not necessary for this topic, but will help to better understand what we manage.
And what is manageable?
At the heart of phono is the DSP pipeline. It consists of three stages of processing. Each stage can include from one to several components:
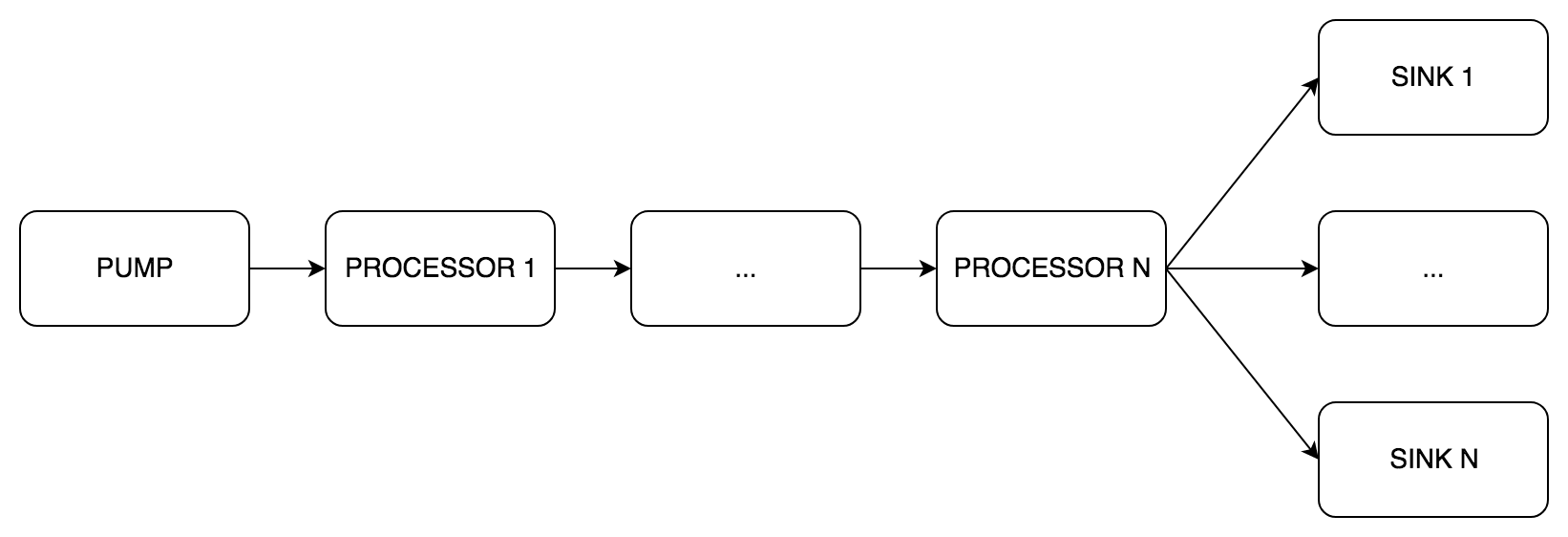
pipe.Pump(English pump) - a mandatory stage of obtaining sound, always only one component.pipe.Processor(English processor) - an optional stage of sound processing , from 0 to N components.pipe.Sink(English sink) - a mandatory stage of sound transmission , from 1 to N components.
Actually we will manage the life cycle of the pipeline.
Life cycle
This is how the pipe.Pipe state diagram looks like.
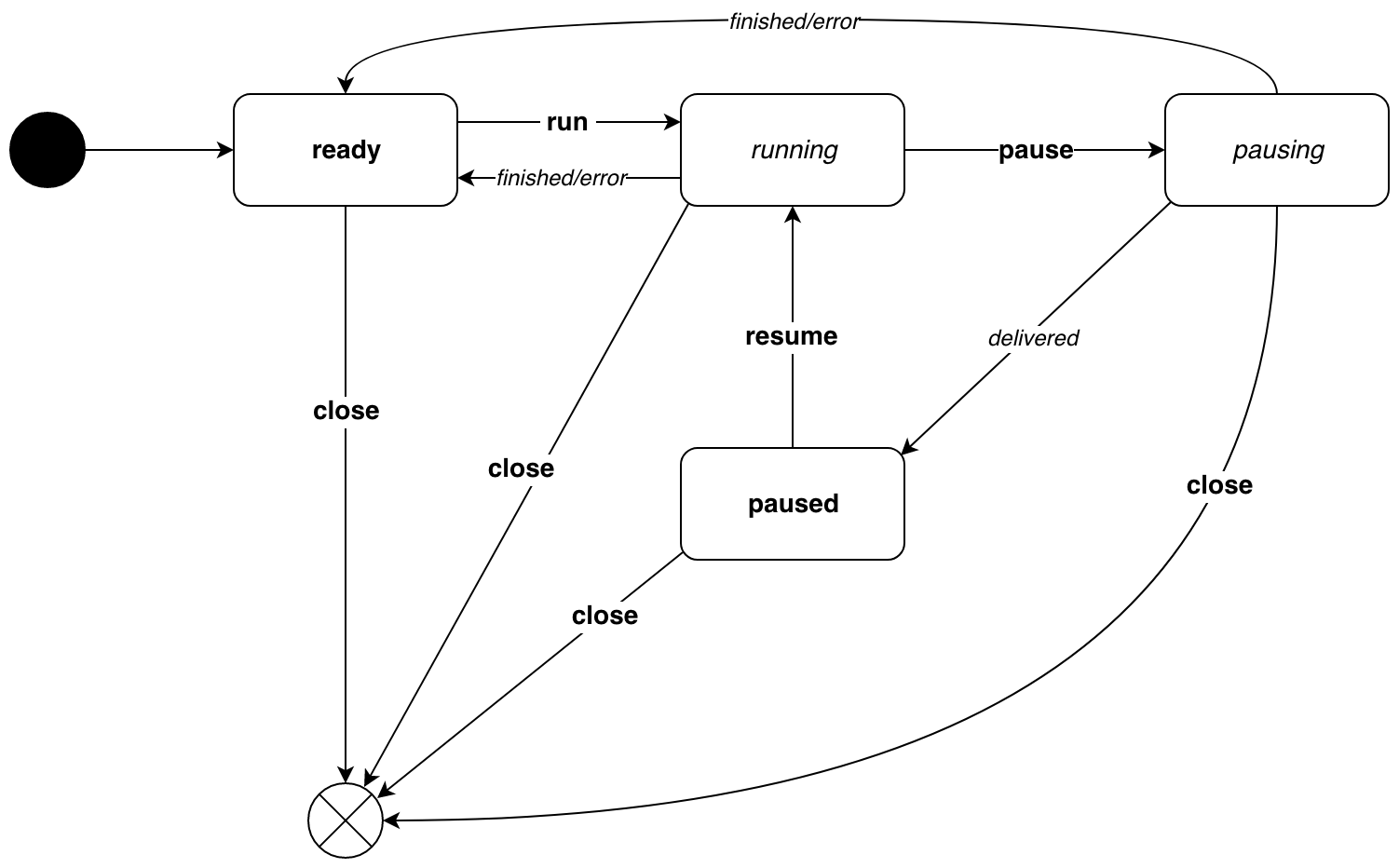
Transitions caused by the internal execution logic are in italics . In boldface - transitions caused by events. The diagram shows that the states are divided into 2 types:
- resting states -
readyandpaused, of which you can go only by event - active states -
runningandpausing, transitions on an event and because of the logic of execution
Before a detailed analysis of the code, a good example of using all states:
// PlayWav .wav portaudio -. func PlayWav(wavFile string) error { bufferSize := phono.BufferSize(512) // w, err := wav.NewPump(wavFile, bufferSize) // wav pump if err != nil { return err } pa := portaudio.NewSink( // portaudio sink bufferSize, w.WavSampleRate(), w.WavNumChannels(), ) p := pipe.New( // pipe.Pipe ready w.WavSampleRate(), pipe.WithPump(w), pipe.WithSinks(pa), ) p.Run() // running p.Run() errc := p.Pause() // pausing p.Pause() err = pipe.Wait(errc) // paused if err != nil { return err } errc = p.Resume() // running p.Resume() err = pipe.Wait(errc) // ready if err != nil { return err } return pipe.Wait(p.Close()) // } Now about everything in order.
All source code is available in the repository .
States and events
Let's start with the most important thing.
// state . type state interface { listen(*Pipe, target) (state, target) // transition(*Pipe, eventMessage) (state, error) // } // idleState . . type idleState interface { state } // activeState . // . type activeState interface { state sendMessage(*Pipe) state // } // . type ( idleReady struct{} activeRunning struct{} activePausing struct{} idlePaused struct{} ) // . var ( ready idleReady running activeRunning paused idlePaused pausing activePausing ) Thanks to the individual types, the transitions are also declared separately for each state. This avoids the huge sausages transition functions with nested switch . The states themselves do not contain any data or logic. For them, you can declare variables at the package level, so as not to do this every time. The state interface is needed for polymorphism. activeState idleState talk about activeState and idleState bit later.
The second most important part of our machine is events.
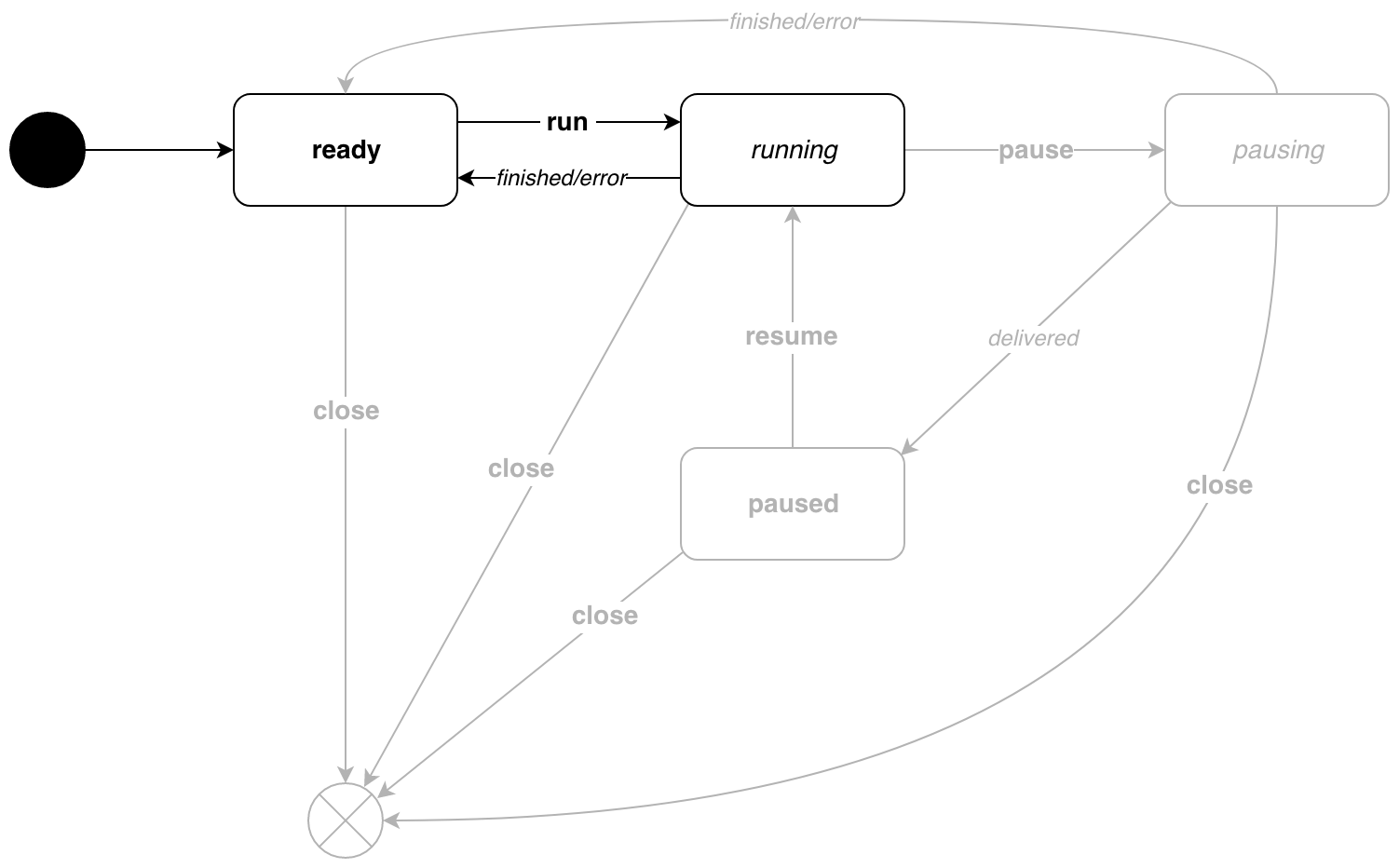
// event . type event int // . const ( run event = iota pause resume push measure cancel ) // target . type target struct { state idleState // errc chan error // , } // eventMessage , . type eventMessage struct { event // params params // components []string // id target // } To understand why the target type is needed, consider a simple example. We have created a new pipeline, it is ready . Now run it with the p.Run() function. The run event is sent to the machine, the pipeline goes into the running state. How to know when the pipeline is finished? This is where the target type will help us. It indicates the state of rest to wait after the event. In our example, after the end of the work, the conveyor will again return to the ready state. The same on the diagram:
Now more about the types of states. More precisely, about the idleState and activeState . Let's look at the listen(*Pipe, target) (state, target) functions for different types of stages:
// listen ready. func (s idleReady) listen(p *Pipe, t target) (state, target) { return p.idle(s, t) } // listen running. func (s activeRunning) listen(p *Pipe, t target) (state, target) { return p.active(s, t) } pipe.Pipe has different functions to wait for the transition! What is there?
// idle . . func (p *Pipe) idle(s idleState, t target) (state, target) { if s == t.state || s == ready { t = t.dismiss() // , target } for { var newState state var err error select { case e := <-p.events: // newState, err = s.transition(p, e) // if err != nil { e.target.handle(err) } else if e.hasTarget() { t.dismiss() t = e.target } } if s != newState { return newState, t // , } } } // active . , // . func (p *Pipe) active(s activeState, t target) (state, target) { for { var newState state var err error select { case e := <-p.events: // newState, err = s.transition(p, e) // if err != nil { // ? e.target.handle(err) // , } else if e.hasTarget() { // , target t.dismiss() // t = e.target // } case <-p.provide: // newState = s.sendMessage(p) // case err, ok := <-p.errc: // if ok { // , interrupt(p.cancel) // t.handle(err) // } // , return ready, t // ready } if s != newState { return newState, t // , } } } Thus, we can listen to different channels in different states. For example, this allows you not to send messages during a pause - we just do not listen to the corresponding channel.
Designer and start machine
// New . // ready. func New(sampleRate phono.SampleRate, options ...Option) *Pipe { p := &Pipe{ UID: phono.NewUID(), sampleRate: sampleRate, log: log.GetLogger(), processors: make([]*processRunner, 0), sinks: make([]*sinkRunner, 0), metrics: make(map[string]measurable), params: make(map[string][]phono.ParamFunc), feedback: make(map[string][]phono.ParamFunc), events: make(chan eventMessage, 1), // cancel: make(chan struct{}), // provide: make(chan struct{}), consume: make(chan message), } for _, option := range options { // option(p)() } go p.loop() // return p } In addition to initialization and functional options , there is a start of a separate gorutina with a main cycle. Well, let's look at it:
// loop , nil . func (p *Pipe) loop() { var s state = ready // t := target{} for s != nil { s, t = s.listen(p, t) // p.log.Debug(fmt.Sprintf("%v is %T", p, s)) } t.dismiss() close(p.events) // } // listen ready. func (s idleReady) listen(p *Pipe, t target) (state, target) { return p.idle(s, t) } // transition . func (s idleReady) transition(p *Pipe, e eventMessage) (state, error) { switch e.event { case cancel: interrupt(p.cancel) return nil, nil case push: e.params.applyTo(p.ID()) p.params = p.params.merge(e.params) return s, nil case measure: for _, id := range e.components { e.params.applyTo(id) } return s, nil case run: if err := p.start(); err != nil { return s, err } return running, nil } return s, ErrInvalidState } The conveyor was created and stopped waiting for events.
It's time to work
Call p.Run() !
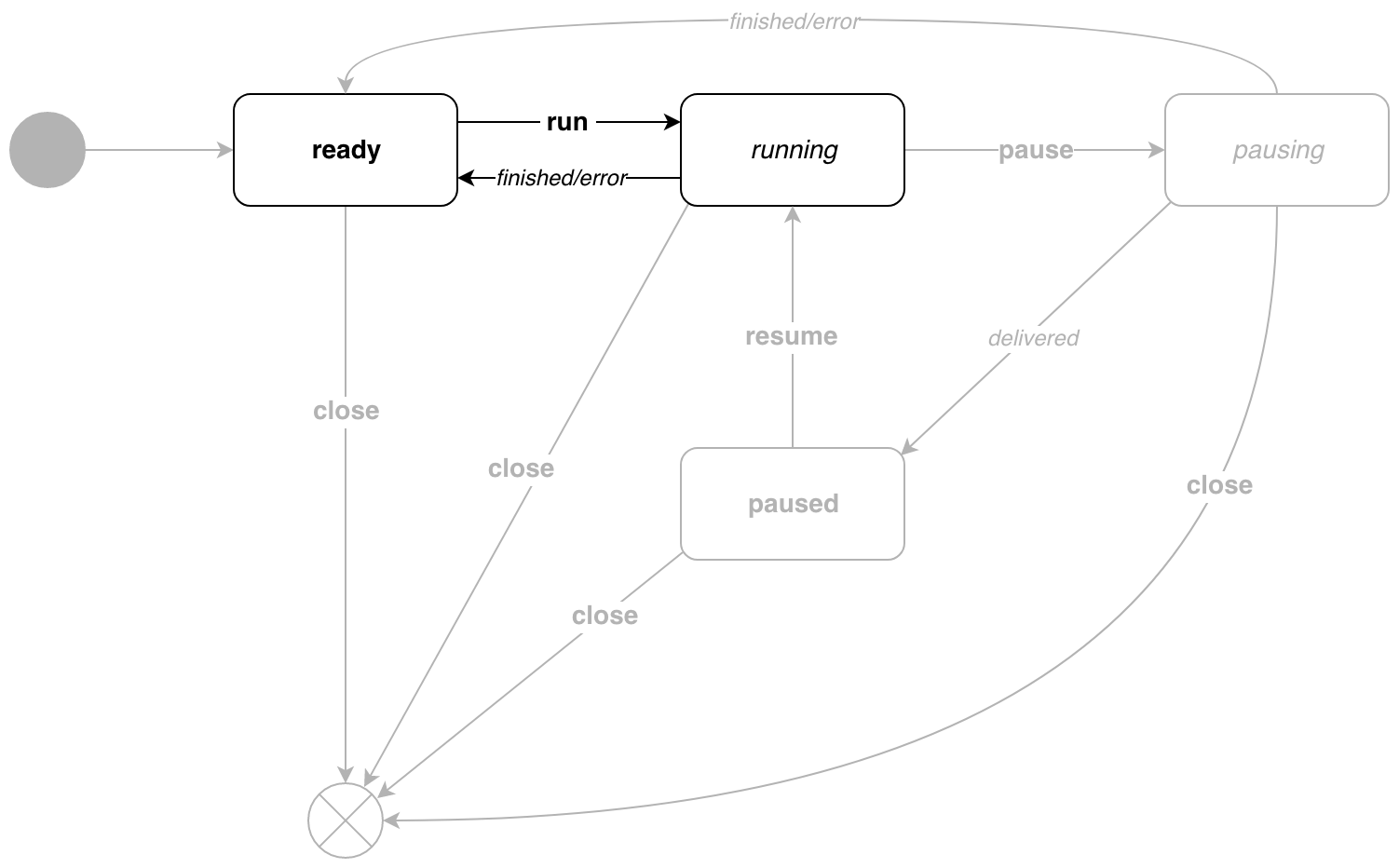
// Run run . // pipe.Close . func (p *Pipe) Run() chan error { runEvent := eventMessage{ event: run, target: target{ state: ready, // errc: make(chan error, 1), }, } p.events <- runEvent return runEvent.target.errc } // listen running. func (s activeRunning) listen(p *Pipe, t target) (state, target) { return p.active(s, t) } // transition . func (s activeRunning) transition(p *Pipe, e eventMessage) (state, error) { switch e.event { case cancel: interrupt(p.cancel) err := Wait(p.errc) return nil, err case measure: e.params.applyTo(p.ID()) p.feedback = p.feedback.merge(e.params) return s, nil case push: e.params.applyTo(p.ID()) p.params = p.params.merge(e.params) return s, nil case pause: return pausing, nil } return s, ErrInvalidState } // sendMessage . func (s activeRunning) sendMessage(p *Pipe) state { p.consume <- p.newMessage() return s } running generates messages and runs until the pipeline ends.
Pause
During the execution of the pipeline, we can pause it. In this state, the pipeline will not generate new messages. To do this, call the p.Pause() method.
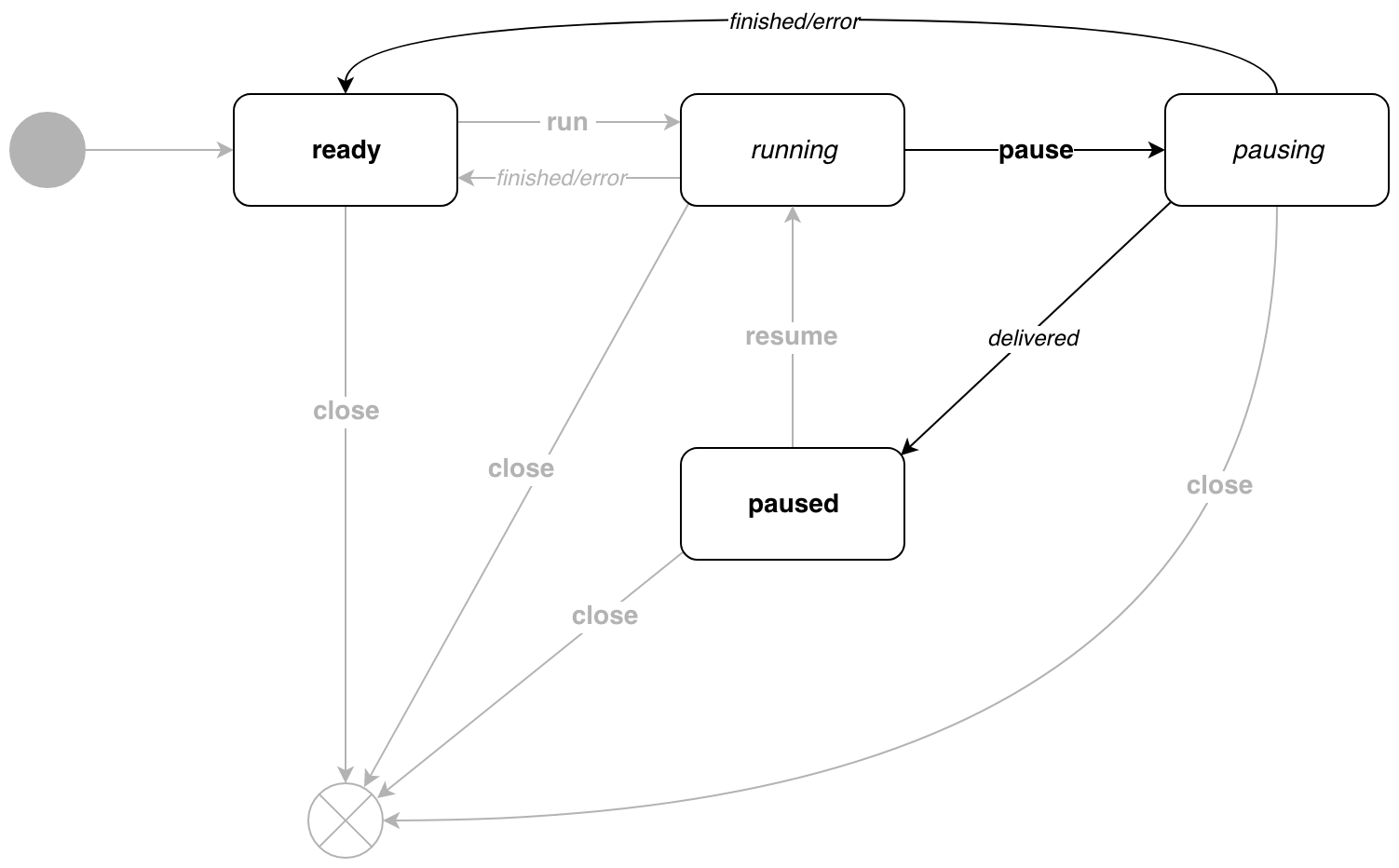
// Pause pause . // pipe.Close . func (p *Pipe) Pause() chan error { pauseEvent := eventMessage{ event: pause, target: target{ state: paused, // errc: make(chan error, 1), }, } p.events <- pauseEvent return pauseEvent.target.errc } // listen pausing. func (s activePausing) listen(p *Pipe, t target) (state, target) { return p.active(s, t) } // transition . func (s activePausing) transition(p *Pipe, e eventMessage) (state, error) { switch e.event { case cancel: interrupt(p.cancel) err := Wait(p.errc) return nil, err case measure: e.params.applyTo(p.ID()) p.feedback = p.feedback.merge(e.params) return s, nil case push: e.params.applyTo(p.ID()) p.params = p.params.merge(e.params) return s, nil } return s, ErrInvalidState } // sendMessage . -, // . // , . , // , , : // 1. // 2. func (s activePausing) sendMessage(p *Pipe) state { m := p.newMessage() if len(m.feedback) == 0 { m.feedback = make(map[string][]phono.ParamFunc) } var wg sync.WaitGroup // wg.Add(len(p.sinks)) // Sink for _, sink := range p.sinks { param := phono.ReceivedBy(&wg, sink.ID()) // - m.feedback = m.feedback.add(param) } p.consume <- m // wg.Wait() // , return paused } As soon as all recipients receive a message, the pipeline will transition to the paused state. If the message is the last, then the transition to the ready state.
Back to work!
To exit the paused state, call p.Resume() .
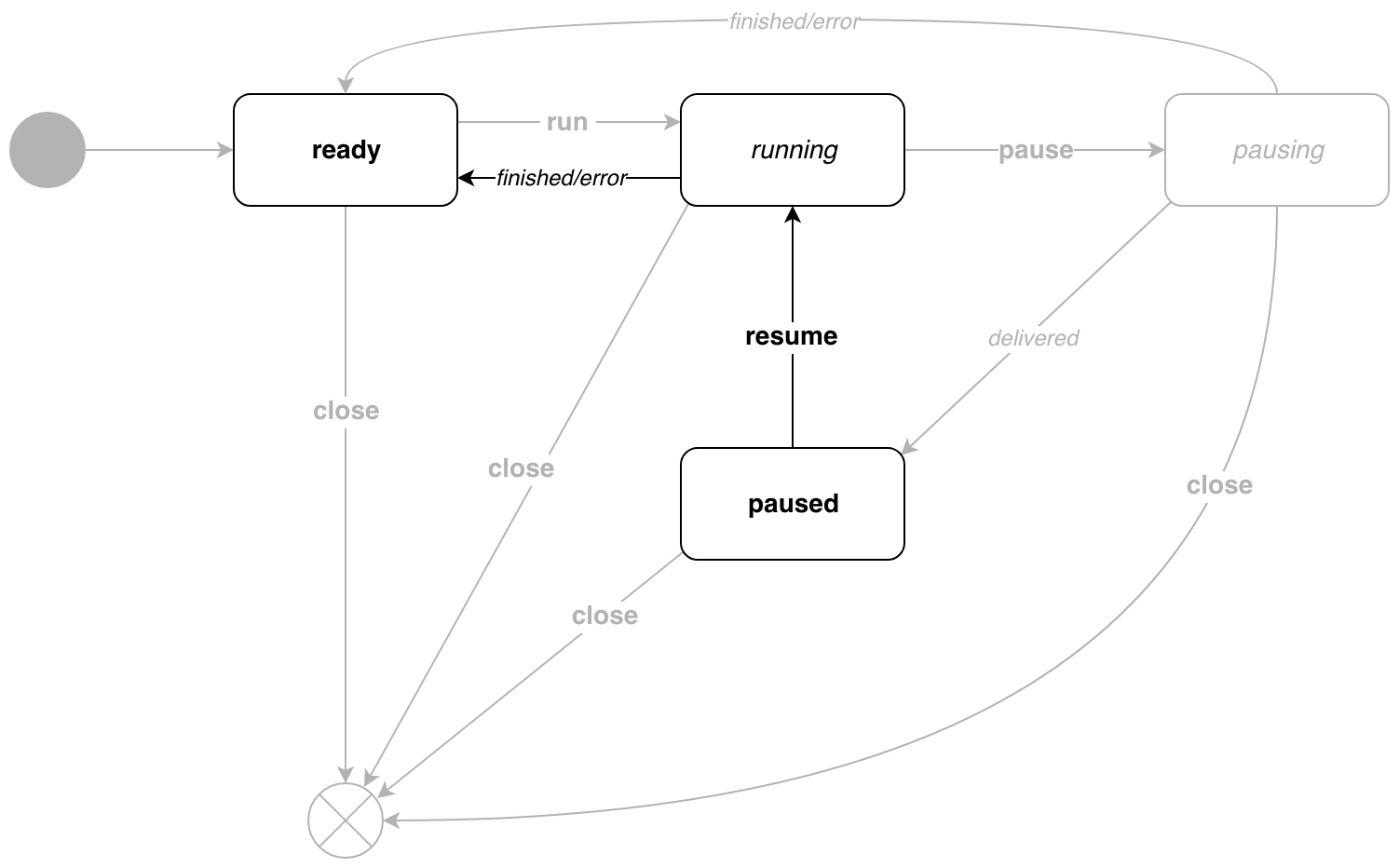
// Resume resume . // pipe.Close . func (p *Pipe) Resume() chan error { resumeEvent := eventMessage{ event: resume, target: target{ state: ready, errc: make(chan error, 1), }, } p.events <- resumeEvent return resumeEvent.target.errc } // listen paused. func (s idlePaused) listen(p *Pipe, t target) (state, target) { return p.idle(s, t) } // transition . func (s idlePaused) transition(p *Pipe, e eventMessage) (state, error) { switch e.event { case cancel: interrupt(p.cancel) err := Wait(p.errc) return nil, err case push: e.params.applyTo(p.ID()) p.params = p.params.merge(e.params) return s, nil case measure: for _, id := range e.components { e.params.applyTo(id) } return s, nil case resume: return running, nil } return s, ErrInvalidState } Everything is trivial, the pipeline is again in a running state.
Roll up
The conveyor can be stopped from any state. For this there is p.Close() .
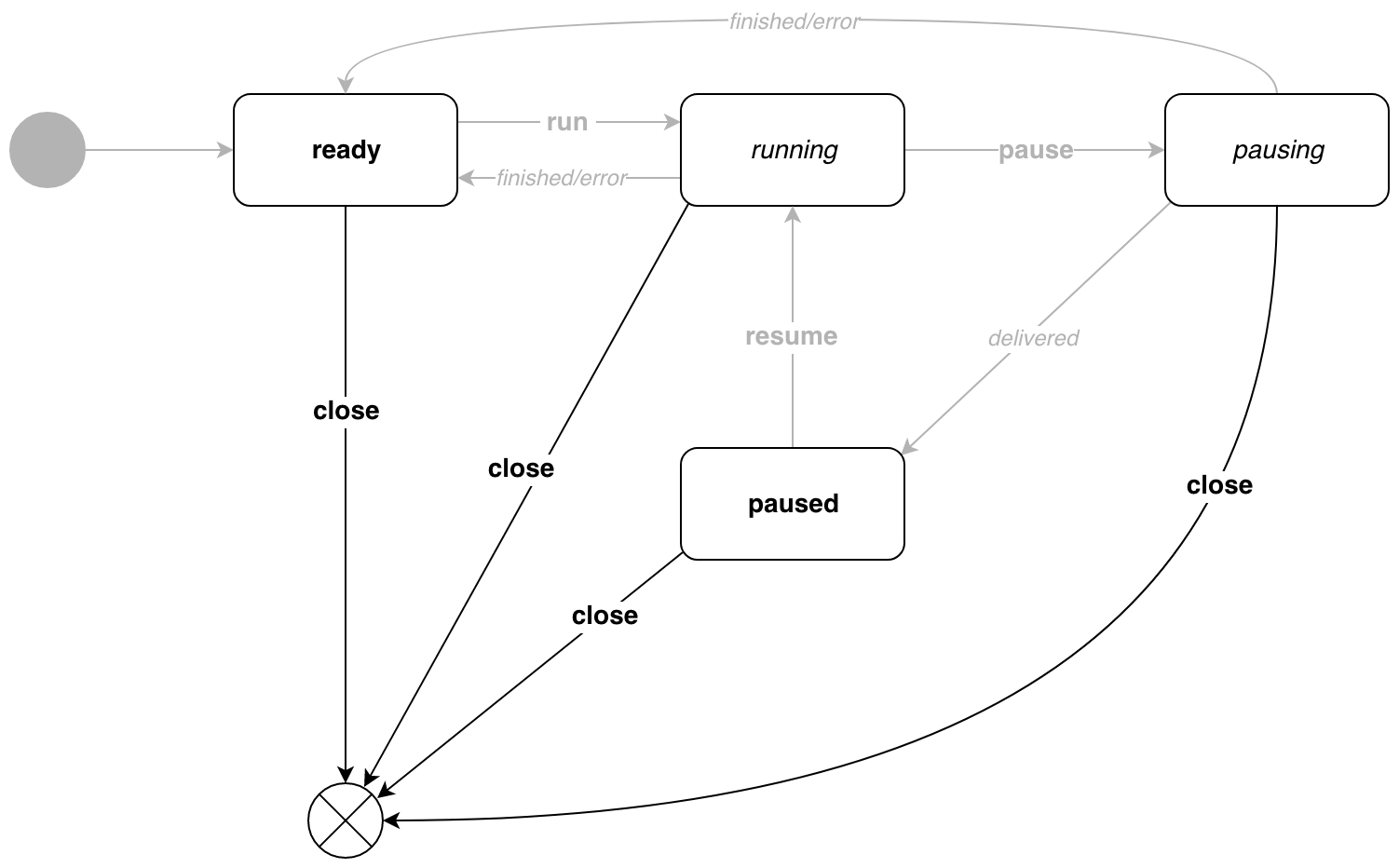
// Close cancel . // . // , . func (p *Pipe) Close() chan error { resumeEvent := eventMessage{ event: cancel, target: target{ state: nil, // errc: make(chan error, 1), }, } p.events <- resumeEvent return resumeEvent.target.errc } Who needs it?
Not everyone. To understand how to manage the state, you need to understand your task. There are exactly two circumstances in which an event-based asynchronous automaton can be used:
- Difficult life cycle - there are three or more states with nonlinear transitions.
- Asynchronous execution is used.
Even though the event automaton solves the problem, it is a rather complex pattern. Therefore, it should be used with great care and only after a full understanding of all the pros and cons.
Links
')
Source: https://habr.com/ru/post/431048/
All Articles