Consistency and ACID guarantees in distributed storage systems
Distributed systems are used when there is a need for horizontal scaling to provide increased performance that a vertically scaled system cannot provide for adequate money.
As well as the transition from a single-threaded paradigm to a multi-threaded one, migration to a distributed system requires a kind of immersion and understanding of how it works inside, what you need to pay attention to.
One of the problems that confronts a person who wants to migrate a project to a distributed system or start a project on it is which product to choose.
')
We, as a company that has “eaten a dog” in the development of systems of this kind, help our clients to make such decisions in a balanced way with regard to distributed storage systems. We are also releasing a series of webinars for a wider audience, which are devoted to basic principles, spoken in simple language, and regardless of any specific product preferences, help to map the relevant characteristics in order to facilitate the selection.
This article is based on our materials on consistency and ACID guarantees in distributed systems.
“ Data consistency (sometimes data consistency , data consistency ) - data consistency with each other, data integrity, and also internal consistency.” ( Wikipedia )
Consistency implies that at any time applications can be sure that they are working with the correct, technically relevant version of the data, and can rely on it when making decisions.
In distributed systems, it becomes more difficult and more expensive to ensure consistency, because a whole series of new calls appear connected with network exchange between different nodes, the possibility of failure of individual nodes, and often the lack of a single memory that can be used for verification.
For example, if I have a system of 4 nodes: A, B, C, and D, which serves banking transactions, and nodes C and D are separated from A and B (say, due to network problems), it is possible that I’ve no longer I have access to part of the transaction. How should I act in this situation? Different systems take different approaches.

At the top level there are 2 key directions, which are expressed in the CAP-theorem.
“ The CAP theorem (also known as the Brewer theorem ) is a heuristic statement that in any implementation of distributed computing it is possible to provide no more than two of the three following properties:
( Wikipedia )
When the CAP theorem speaks of consistency, it implies a rather strict definition, including linearization of records and reads, and specifies consistency only when writing individual values. ( Martin Kleppman )
CAP-theorem says that if we want to be resistant to network problems, then we generally have to choose what to sacrifice: consistency or accessibility. There is also an extended version of this theorem - PACELC ( Wikipedia ), which additionally says that even in the absence of network problems, we must choose between response speed and consistency.
And although, at first glance, a native of the world of classic DBMS, it seems that the choice is obvious, and consistency is the most important thing that we have, it is not always the case that vividly illustrates the explosive growth of a number of NoSQL DBMS that made a different choice and despite this, have gained a huge user base. Apache Cassandra with its famous eventual consistency is a good example.
All because it is a choice , which implies that we are sacrificing something, and we are not always ready to sacrifice it.
Often the problem of consistency in distributed systems is solved simply by rejecting this consistency.
But it is necessary and important to understand when the rejection of this consistency is acceptable, and when it is a business-critical requirement.
For example, if I design a component that is responsible for storing user sessions, here, most likely, the consistency is not so important to me, and data loss is noncritical, if it occurs only in problematic cases - very rarely. The worst that will happen is that the user will need to re-login, and for many businesses this will have almost no effect on their financial performance.
If I do analytics on the data stream from the sensors, in many cases I’m not at all critical to lose part of the data and get reduced sampling over a short period of time, especially if “eventually” I’ll see the data.
But if I do the banking system, the consistency of cash transactions is critical for my business. If I accrued a penalty on the client's loan because I simply did not see the payment made on time, although it was in the system - this is very, very bad. How and if a client can withdraw all the money from my credit card several times, because I had network problems at the time of the transaction, and information about withdrawals did not reach part of my cluster.
If you are making an expensive purchase in an online store, you do not want your order to be forgotten, despite the success of the reported web page.
But if you opt for consistency, you sacrifice accessibility. And often this is expected, most likely, you have repeatedly come across it personally.
It is better if the basket of the online store says “try later, the distributed DBMS is not available” than if it reports success and forgets the order. It is better to get a denial of a transaction due to the inaccessibility of the bank’s services than a beat on success and then a trial with the bank due to the fact that it forgot that you made a loan payment.
Finally, if we look at the advanced, PACELC theorem, then we understand that even in the case of a regular system operation, choosing consistency, we can sacrifice low latency, obtaining a potentially lower level of maximum performance.
Therefore, answering the question “why is it necessary?”: This is necessary if it is critical for your task to have relevant, complete data, and the alternative will bring you significant losses, greater than the temporary unavailability of the service for the period of the incident or its lower performance.
Accordingly, the first decision you need to make is where you are in the CAP theorem, you want consistency or availability in the event of an incident.
Next, you need to understand at what level you want to make changes. Perhaps you have enough ordinary atomic records affecting a single object, as MongoDB was able and able (it now extends this with additional support for full-fledged transactions). Let me remind you that the CAP-theorem says nothing about the consistency of write operations involving multiple objects: the system may well be CP (i.e., prefer accessibility consistency) and still provide only atomic single entries.
If this is not enough for you, we begin to approach the concept of full-fledged distributed ACID transactions.
I note that even when moving to a brave new world of distributed ACID transactions, we often have to sacrifice something. For example, a number of distributed storage systems have distributed transactions, but only within one partition. Or, for example, the system may not maintain the “I” part at the level you need, without having isolation, or with an insufficient number of isolation levels.
These restrictions were often made for some reason: either to simplify the implementation, or, for example, to improve performance, or for something else. They are sufficient for a large number of cases, so you should not consider them as cons in themselves.
You need to understand whether these restrictions are a problem for your particular scenario. If not, you have more choices, and you can give more weight, for example, to performance indicators or the ability of the system to provide disaster recovery, etc. Finally, we must not forget that for a number of systems these parameters can be adjusted to the extent that the system can be CP or AP depending on the configuration.
If our product tends to be CP, then usually it has either a quorum approach to data selection, or dedicated nodes that are the main owners of records, all data changes pass through them, and in case of network problems, if these master nodes cannot give answer, it is considered that data is basically impossible to obtain, or arbitration, when an external high-availability component (for example, a ZooKeeper cluster) can tell which of the cluster segments is the main one, contains the current version of the data and can efficiently service the request s.
Finally, if we are not only interested in CPs, but support for fully-fledged distributed ACID transactions, then a single source of truth is often or is used, for example, centralized disk storage, where our nodes are, in fact, only caches to it, which can be disabled in commit time, or multiphase commit protocol is applied.
The first single-disk approach also simplifies implementation, gives low latency on distributed transactions, but trades in return for very limited scalability on loads with large write volumes.
The second approach gives much more freedom in scaling, and, in turn, is divided into two-phase ( Wikipedia ) and three-phase ( Wikipedia ) commit protocols.
Consider the example of a two-phase commit, which uses, for example, Apache Ignite.
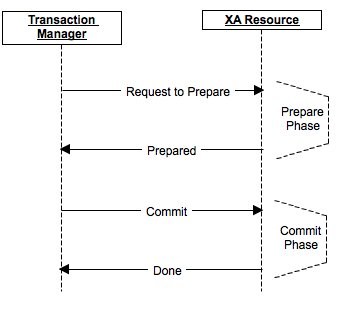

The commit procedure is divided into 2 phases: prepare and commit.
During the prepare phase, a message about preparing for a commit is sent, and each participant makes a lock if necessary, performs all operations up to the actual commit not inclusive, sends the prepare to its replicas, if this is assumed by the product. If at least one of the participants responded for some reason as a refusal or was unavailable, the data did not actually change, there was no commit. Participants roll back changes, remove locks and return to their original state.
The commit phase sends the actual commit commit to the cluster nodes. If for some reason some of the nodes were unavailable or answered with an error, then by that time the data is entered into their redo-log (since the prepare was completed successfully), and the commit can be completed in any case at least in the pending state.
Finally, if the coordinator fails, the commit will be canceled at the prepare stage, a new coordinator may be selected at the commit stage, and if all nodes have completed prepare, he can verify and ensure that the commit stage is performed.
Different products have their own features of implementation and optimization. For example, some products are able in some cases to reduce 2-phase commits to 1-phase, significantly gaining in performance.
The key conclusion: distributed data storage systems is a fairly developed market, and the products on it can provide high consistency of data.
At the same time, products of this category are located at different points of the consistency scale, from fully AP products without any transitivity, to CP products that additionally give full ACID transactions. Some products can be configured in one direction or the other.
When you choose what you need, you need to take into account the needs of your case and understand well what sacrifices and compromises you are willing to make, because nothing is free, and choosing one, you will most likely give up on something else.
Evaluating products from this side, you should pay attention to:
As well as the transition from a single-threaded paradigm to a multi-threaded one, migration to a distributed system requires a kind of immersion and understanding of how it works inside, what you need to pay attention to.
One of the problems that confronts a person who wants to migrate a project to a distributed system or start a project on it is which product to choose.
')
We, as a company that has “eaten a dog” in the development of systems of this kind, help our clients to make such decisions in a balanced way with regard to distributed storage systems. We are also releasing a series of webinars for a wider audience, which are devoted to basic principles, spoken in simple language, and regardless of any specific product preferences, help to map the relevant characteristics in order to facilitate the selection.
This article is based on our materials on consistency and ACID guarantees in distributed systems.
What is it and why is it needed?
“ Data consistency (sometimes data consistency , data consistency ) - data consistency with each other, data integrity, and also internal consistency.” ( Wikipedia )
Consistency implies that at any time applications can be sure that they are working with the correct, technically relevant version of the data, and can rely on it when making decisions.
In distributed systems, it becomes more difficult and more expensive to ensure consistency, because a whole series of new calls appear connected with network exchange between different nodes, the possibility of failure of individual nodes, and often the lack of a single memory that can be used for verification.
For example, if I have a system of 4 nodes: A, B, C, and D, which serves banking transactions, and nodes C and D are separated from A and B (say, due to network problems), it is possible that I’ve no longer I have access to part of the transaction. How should I act in this situation? Different systems take different approaches.
At the top level there are 2 key directions, which are expressed in the CAP-theorem.
“ The CAP theorem (also known as the Brewer theorem ) is a heuristic statement that in any implementation of distributed computing it is possible to provide no more than two of the three following properties:
- data consistency (eng. consistency) - in all computing nodes at one time point the data do not contradict each other;
- availability (eng. availability) - any request to a distributed system ends with a correct response, but without guarantee that the answers of all nodes of the system match;
- Resistance to separation (English partition tolerance) - splitting a distributed system into several isolated sections does not lead to incorrect response from each of the sections. "
( Wikipedia )
When the CAP theorem speaks of consistency, it implies a rather strict definition, including linearization of records and reads, and specifies consistency only when writing individual values. ( Martin Kleppman )
CAP-theorem says that if we want to be resistant to network problems, then we generally have to choose what to sacrifice: consistency or accessibility. There is also an extended version of this theorem - PACELC ( Wikipedia ), which additionally says that even in the absence of network problems, we must choose between response speed and consistency.
And although, at first glance, a native of the world of classic DBMS, it seems that the choice is obvious, and consistency is the most important thing that we have, it is not always the case that vividly illustrates the explosive growth of a number of NoSQL DBMS that made a different choice and despite this, have gained a huge user base. Apache Cassandra with its famous eventual consistency is a good example.
All because it is a choice , which implies that we are sacrificing something, and we are not always ready to sacrifice it.
Often the problem of consistency in distributed systems is solved simply by rejecting this consistency.
But it is necessary and important to understand when the rejection of this consistency is acceptable, and when it is a business-critical requirement.
For example, if I design a component that is responsible for storing user sessions, here, most likely, the consistency is not so important to me, and data loss is noncritical, if it occurs only in problematic cases - very rarely. The worst that will happen is that the user will need to re-login, and for many businesses this will have almost no effect on their financial performance.
If I do analytics on the data stream from the sensors, in many cases I’m not at all critical to lose part of the data and get reduced sampling over a short period of time, especially if “eventually” I’ll see the data.
But if I do the banking system, the consistency of cash transactions is critical for my business. If I accrued a penalty on the client's loan because I simply did not see the payment made on time, although it was in the system - this is very, very bad. How and if a client can withdraw all the money from my credit card several times, because I had network problems at the time of the transaction, and information about withdrawals did not reach part of my cluster.
If you are making an expensive purchase in an online store, you do not want your order to be forgotten, despite the success of the reported web page.
But if you opt for consistency, you sacrifice accessibility. And often this is expected, most likely, you have repeatedly come across it personally.
It is better if the basket of the online store says “try later, the distributed DBMS is not available” than if it reports success and forgets the order. It is better to get a denial of a transaction due to the inaccessibility of the bank’s services than a beat on success and then a trial with the bank due to the fact that it forgot that you made a loan payment.
Finally, if we look at the advanced, PACELC theorem, then we understand that even in the case of a regular system operation, choosing consistency, we can sacrifice low latency, obtaining a potentially lower level of maximum performance.
Therefore, answering the question “why is it necessary?”: This is necessary if it is critical for your task to have relevant, complete data, and the alternative will bring you significant losses, greater than the temporary unavailability of the service for the period of the incident or its lower performance.
How to provide it?
Accordingly, the first decision you need to make is where you are in the CAP theorem, you want consistency or availability in the event of an incident.
Next, you need to understand at what level you want to make changes. Perhaps you have enough ordinary atomic records affecting a single object, as MongoDB was able and able (it now extends this with additional support for full-fledged transactions). Let me remind you that the CAP-theorem says nothing about the consistency of write operations involving multiple objects: the system may well be CP (i.e., prefer accessibility consistency) and still provide only atomic single entries.
If this is not enough for you, we begin to approach the concept of full-fledged distributed ACID transactions.
I note that even when moving to a brave new world of distributed ACID transactions, we often have to sacrifice something. For example, a number of distributed storage systems have distributed transactions, but only within one partition. Or, for example, the system may not maintain the “I” part at the level you need, without having isolation, or with an insufficient number of isolation levels.
These restrictions were often made for some reason: either to simplify the implementation, or, for example, to improve performance, or for something else. They are sufficient for a large number of cases, so you should not consider them as cons in themselves.
You need to understand whether these restrictions are a problem for your particular scenario. If not, you have more choices, and you can give more weight, for example, to performance indicators or the ability of the system to provide disaster recovery, etc. Finally, we must not forget that for a number of systems these parameters can be adjusted to the extent that the system can be CP or AP depending on the configuration.
If our product tends to be CP, then usually it has either a quorum approach to data selection, or dedicated nodes that are the main owners of records, all data changes pass through them, and in case of network problems, if these master nodes cannot give answer, it is considered that data is basically impossible to obtain, or arbitration, when an external high-availability component (for example, a ZooKeeper cluster) can tell which of the cluster segments is the main one, contains the current version of the data and can efficiently service the request s.
Finally, if we are not only interested in CPs, but support for fully-fledged distributed ACID transactions, then a single source of truth is often or is used, for example, centralized disk storage, where our nodes are, in fact, only caches to it, which can be disabled in commit time, or multiphase commit protocol is applied.
The first single-disk approach also simplifies implementation, gives low latency on distributed transactions, but trades in return for very limited scalability on loads with large write volumes.
The second approach gives much more freedom in scaling, and, in turn, is divided into two-phase ( Wikipedia ) and three-phase ( Wikipedia ) commit protocols.
Consider the example of a two-phase commit, which uses, for example, Apache Ignite.

The commit procedure is divided into 2 phases: prepare and commit.
During the prepare phase, a message about preparing for a commit is sent, and each participant makes a lock if necessary, performs all operations up to the actual commit not inclusive, sends the prepare to its replicas, if this is assumed by the product. If at least one of the participants responded for some reason as a refusal or was unavailable, the data did not actually change, there was no commit. Participants roll back changes, remove locks and return to their original state.
The commit phase sends the actual commit commit to the cluster nodes. If for some reason some of the nodes were unavailable or answered with an error, then by that time the data is entered into their redo-log (since the prepare was completed successfully), and the commit can be completed in any case at least in the pending state.
Finally, if the coordinator fails, the commit will be canceled at the prepare stage, a new coordinator may be selected at the commit stage, and if all nodes have completed prepare, he can verify and ensure that the commit stage is performed.
Different products have their own features of implementation and optimization. For example, some products are able in some cases to reduce 2-phase commits to 1-phase, significantly gaining in performance.
findings
The key conclusion: distributed data storage systems is a fairly developed market, and the products on it can provide high consistency of data.
At the same time, products of this category are located at different points of the consistency scale, from fully AP products without any transitivity, to CP products that additionally give full ACID transactions. Some products can be configured in one direction or the other.
When you choose what you need, you need to take into account the needs of your case and understand well what sacrifices and compromises you are willing to make, because nothing is free, and choosing one, you will most likely give up on something else.
Evaluating products from this side, you should pay attention to:
- where they are in the CAP theorem;
- Do they support distributed ACID transactions?
- what restrictions do they impose on distributed transactions (for example, only within one partition, etc.);
- convenience and efficiency of using distributed transactions, their integration into other components of the product.
Source: https://habr.com/ru/post/430852/
All Articles