Load testing with locust. Part 2
For those who liked my previous article , I continue to share my impressions of the tool for load testing Locust.
I will try to visually show the benefits of writing a python load test code in which you can conveniently prepare any data for the test and process the results.
Sometimes in load testing it is not enough just to get an HTTP 200 OK from the server. It happens, you still have to check the contents of the response to make sure that under load the server provides the correct data or performs accurate calculations. Just for such cases, Locust added the ability to override the server response success parameters. Consider the following example:
')
It has only one request, which will create a load in the following scenario:
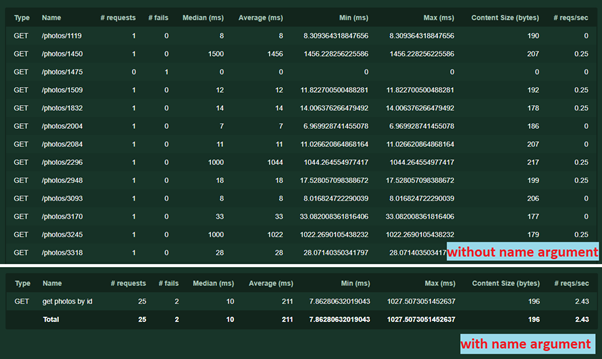
Using the same argument, you can perform another trick - sometimes it happens that one service with different parameters (for example, different contents of POST requests) performs different logic. So that the test results are not mixed up, you can write several separate tasks, specifying your own name argument for each.
Next we do the checks. I have two of them. First we check that the server returned the answer to us if response.status_code == 200 :
If yes, then check if the album id is a multiple of 10. If not multiple, then mark this answer as successful response.success ()
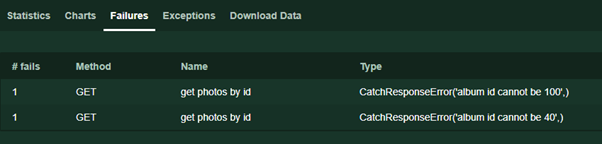
In other cases, we indicate why the response failed response.failure ('error text') . This text will be displayed on the Failures page during the test run.
Also attentive readers could notice the absence of exception handlers (Exceptions), characteristic of the code that works with network interfaces. Indeed, in the case of timeout, connection error and other unforeseen incidents, Locust itself will handle the errors and still return the answer, indicating, however, the status of the response code is 0.
If the code still generates an Exception, it will be written on the Exceptions tab at runtime so that we can process it. The most typical situation is that in json'e the answer did not return the value we were looking for, but we are already doing the following operations on it.
Before, close the topic - in the example I use the json server for clarity, as it is easier to handle the answers. But you can work with the same success with HTML, XML, FormData, file attachments, and other data used by HTTP-based protocols.
Almost every time the task is set to conduct load testing of a web application, it quickly becomes clear that it is impossible to provide adequate coverage with GET services alone - which simply return data.
A classic example: to test an online store, it is desirable that the user
From the example, we can assume that it’s impossible to call services in a random order, only sequentially. Moreover, the goods, baskets and forms of payment can have unique identifiers for each user.
Using the previous example, with minor modifications, you can easily implement testing of such a scenario. Adapt the example to our test server:
In this example, I added a new class FlowException . After each step, if it didn’t go as expected, I’ll throw this exception class in order to interrupt the script — if the post failed to create, then there’s nothing to comment, etc. If desired, the construction can be replaced with a normal return , but in this case, during execution and when analyzing the results, it will not be so clearly seen at which step the execution script falls on the Exceptions tab. For the same reason, I do not use the try ... except construction.
Now I can be reproached - in the case of the store, everything is really linear, but the example of posts and comments is too far-fetched - they read posts 10 times more often than they create. Reasonably, let's make the example more vital. And there are at least 2 approaches:
In the UserBehavior class , I created a created_posts list. Pay special attention - this is an object and it was not created in the class constructor __init __ (), therefore, unlike the client session, this list is common for all users. The first task creates a post and writes its id to the list. The second - 10 times more often, reads one, randomly selected post from the list. An additional condition of the second task is to check whether there are any posts created.
If we need each user to operate only with his own data, we can declare it in the constructor as follows:
For the sequential launch of tasks, the official documentation suggests that we also use the task annotation @seq_task (1), indicating the sequence number of the task in the argument
In this example, each user will first execute first_task , then second_task , then 10 times third_task .
Frankly speaking, the presence of such an opportunity pleases, but, unlike the previous examples, it is not clear how to transfer the results of the first task to the second if necessary.
Also, for particularly complex scenarios, it is possible to create nested sets of tasks, in essence, creating several TaskSet classes and connecting with each other.
In the example above, with a probability of 1 to 6, the Todo script will be run, and it will be executed until, with a probability of 1 to 4, it returns to the UserBehavior script. The presence of the self.interrupt () call is very important here - without it, testing will loop on the subtask.
Thank you for reading. In the final article I will write about distributed testing and testing without UI, as well as the difficulties encountered in the testing process using Locust and how to get around them.
I will try to visually show the benefits of writing a python load test code in which you can conveniently prepare any data for the test and process the results.
Processing server responses
Sometimes in load testing it is not enough just to get an HTTP 200 OK from the server. It happens, you still have to check the contents of the response to make sure that under load the server provides the correct data or performs accurate calculations. Just for such cases, Locust added the ability to override the server response success parameters. Consider the following example:
')
from locust import HttpLocust, TaskSet, task import random as rnd class UserBehavior(TaskSet): @task(1) def check_albums(self): photo_id = rnd.randint(1, 5000) with self.client.get(f'/photos/{photo_id}', catch_response=True, name='/photos/[id]') as response: if response.status_code == 200: album_id = response.json().get('albumId') if album_id % 10 != 0: response.success() else: response.failure(f'album id cannot be {album_id}') else: response.failure(f'status code is {response.status_code}') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000 It has only one request, which will create a load in the following scenario:
From the server, we request photos with random id in the range from 1 to 5000 and check the album id in this object, assuming that it cannot be a multiple of 10Here you can immediately give a few explanations:
- the awesome with request () construction as response: you can successfully replace with response = request () and work quietly with the response object
- The URL is formed using the string format syntax added in python 3.6, if I'm not mistaken, f '/ photos / {photo_id}' . In previous versions, this design will not work!
- The new argument, which we have not used before, catch_response = True , indicates to Locust that we ourselves will determine the success of the server response. If you do not specify it, we will receive the response object in the same way and will be able to process its data, but not override the result. Below is a detailed example.
- Another argument name = '/ photos / [id]' . It is needed for grouping rekvestov in statistics. The name can be any text, it is not necessary to repeat the url. Without it, each request with a unique address or parameters will be recorded separately. Here's how it works:
Using the same argument, you can perform another trick - sometimes it happens that one service with different parameters (for example, different contents of POST requests) performs different logic. So that the test results are not mixed up, you can write several separate tasks, specifying your own name argument for each.
Next we do the checks. I have two of them. First we check that the server returned the answer to us if response.status_code == 200 :
If yes, then check if the album id is a multiple of 10. If not multiple, then mark this answer as successful response.success ()
In other cases, we indicate why the response failed response.failure ('error text') . This text will be displayed on the Failures page during the test run.
Also attentive readers could notice the absence of exception handlers (Exceptions), characteristic of the code that works with network interfaces. Indeed, in the case of timeout, connection error and other unforeseen incidents, Locust itself will handle the errors and still return the answer, indicating, however, the status of the response code is 0.
If the code still generates an Exception, it will be written on the Exceptions tab at runtime so that we can process it. The most typical situation is that in json'e the answer did not return the value we were looking for, but we are already doing the following operations on it.
Before, close the topic - in the example I use the json server for clarity, as it is easier to handle the answers. But you can work with the same success with HTML, XML, FormData, file attachments, and other data used by HTTP-based protocols.
Work with complex scenarios
Almost every time the task is set to conduct load testing of a web application, it quickly becomes clear that it is impossible to provide adequate coverage with GET services alone - which simply return data.
A classic example: to test an online store, it is desirable that the user
- Opened the main store
- I was looking for goods
- Opened the details of the goods
- Add item to cart
- Paid
From the example, we can assume that it’s impossible to call services in a random order, only sequentially. Moreover, the goods, baskets and forms of payment can have unique identifiers for each user.
Using the previous example, with minor modifications, you can easily implement testing of such a scenario. Adapt the example to our test server:
- User writes a new post
- The user writes a comment to the new post.
- User reads comment
from locust import HttpLocust, TaskSet, task class FlowException(Exception): pass class UserBehavior(TaskSet): @task(1) def check_flow(self): # step 1 new_post = {'userId': 1, 'title': 'my shiny new post', 'body': 'hello everybody'} post_response = self.client.post('/posts', json=new_post) if post_response.status_code != 201: raise FlowException('post not created') post_id = post_response.json().get('id') # step 2 new_comment = { "postId": post_id, "name": "my comment", "email": "test@user.habr", "body": "Author is cool. Some text. Hello world!" } comment_response = self.client.post('/comments', json=new_comment) if comment_response.status_code != 201: raise FlowException('comment not created') comment_id = comment_response.json().get('id') # step 3 self.client.get(f'/comments/{comment_id}', name='/comments/[id]') if comment_response.status_code != 200: raise FlowException('comment not read') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000 In this example, I added a new class FlowException . After each step, if it didn’t go as expected, I’ll throw this exception class in order to interrupt the script — if the post failed to create, then there’s nothing to comment, etc. If desired, the construction can be replaced with a normal return , but in this case, during execution and when analyzing the results, it will not be so clearly seen at which step the execution script falls on the Exceptions tab. For the same reason, I do not use the try ... except construction.
Making the load realistic
Now I can be reproached - in the case of the store, everything is really linear, but the example of posts and comments is too far-fetched - they read posts 10 times more often than they create. Reasonably, let's make the example more vital. And there are at least 2 approaches:
- You can “hardcore” the list of posts that users read, and simplify the test code, if there is such a possibility and the backend functionality does not depend on specific posts
- Save created posts and read them if it is not possible to preset a list of posts or the realistic load depends strongly on what posts are read (I removed the creation of comments from the example to make its code smaller and clearer)
from locust import HttpLocust, TaskSet, task import random as r class UserBehavior(TaskSet): created_posts = [] @task(1) def create_post(self): new_post = {'userId': 1, 'title': 'my shiny new post', 'body': 'hello everybody'} post_response = self.client.post('/posts', json=new_post) if post_response.status_code != 201: return post_id = post_response.json().get('id') self.created_posts.append(post_id) @task(10) def read_post(self): if len(self.created_posts) == 0: return post_id = r.choice(self.created_posts) self.client.get(f'/posts/{post_id}', name='read post') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000 In the UserBehavior class , I created a created_posts list. Pay special attention - this is an object and it was not created in the class constructor __init __ (), therefore, unlike the client session, this list is common for all users. The first task creates a post and writes its id to the list. The second - 10 times more often, reads one, randomly selected post from the list. An additional condition of the second task is to check whether there are any posts created.
If we need each user to operate only with his own data, we can declare it in the constructor as follows:
class UserBehavior(TaskSet): def __init__(self, parent): super(UserBehavior, self).__init__(parent) self.created_posts = list() Some more features
For the sequential launch of tasks, the official documentation suggests that we also use the task annotation @seq_task (1), indicating the sequence number of the task in the argument
class MyTaskSequence(TaskSequence): @seq_task(1) def first_task(self): pass @seq_task(2) def second_task(self): pass @seq_task(3) @task(10) def third_task(self): pass In this example, each user will first execute first_task , then second_task , then 10 times third_task .
Frankly speaking, the presence of such an opportunity pleases, but, unlike the previous examples, it is not clear how to transfer the results of the first task to the second if necessary.
Also, for particularly complex scenarios, it is possible to create nested sets of tasks, in essence, creating several TaskSet classes and connecting with each other.
from locust import HttpLocust, TaskSet, task class Todo(TaskSet): @task(3) def index(self): self.client.get("/todos") @task(1) def stop(self): self.interrupt() class UserBehavior(TaskSet): tasks = {Todo: 1} @task(3) def index(self): self.client.get("/") @task(2) def posts(self): self.client.get("/posts") class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000 In the example above, with a probability of 1 to 6, the Todo script will be run, and it will be executed until, with a probability of 1 to 4, it returns to the UserBehavior script. The presence of the self.interrupt () call is very important here - without it, testing will loop on the subtask.
Thank you for reading. In the final article I will write about distributed testing and testing without UI, as well as the difficulties encountered in the testing process using Locust and how to get around them.
Source: https://habr.com/ru/post/430810/
All Articles