Backup for Linux, or how to create snapshot
Hello! I work at Veeam on the Veeam Agent for Linux project. With this product, you can back up a machine with Linux OS. “Agent” in the title means that the program allows you to back up physical machines. Virtuals are also backed up, but at the same time are located on the guest OS.
The inspiration for this article served as my report at the Linux Piter conference, which I decided to issue as an article for all interested artists.
In the article, I will cover the topic of creating snapshots, which allows you to make a backup, and tell you about the problems that we faced when creating our own mechanism for creating snapshots of block devices.
')
All interested in asking under the cat!

Historically, there are two approaches to creating backups: File backup and Volume backup. In the first case, we copy each file as a separate object; in the second, we copy the entire contents of the volume as an image.
Both methods have a lot of their pros and cons, but we will look at them through the prism of recovery after a failure:
Obviously, in the case of Volume backup, you can restore the system as quickly as possible, and this is an important feature of the system . Therefore, for ourselves, we note volume backup as a more preferred option.
How do we take and keep the entire volume entirely? Of course, by simple copying, we will not achieve anything good. During copying, some activity with data will occur on the volume; as a result, inconsistent data will appear in the backup. The file system structure will be broken, database files are damaged, as well as other files with which operations will be performed during copying.
To avoid all these problems, progressive humanity came up with the technology of snapshot - snapshot. In theory, everything is simple: create an immutable copy - snapshot - and back up the data from it. When the backup is finished, snapshot is destroyed. It sounds simple, but, as usual, there are nuances.
Because of them, many implementations of this technology were born. For example, device mapper- based solutions, such as LVM and Thin provisioning, provide full-fledged snapshots of volumes, but require special disk markup at the system installation stage, which means that they are generally not suitable.
BTRFS and ZFS make it possible to create snapshots of file system substructures, which is very cool, but at the moment their share on the servers is small, and we are trying to make a universal solution.
Suppose on our block device there is a banal EXT. In this case, we can use dm-snap (by the way, a dm-bow is being developed), but here’s a nuance. You need to have a free block device at the ready, so that there is where to drop snapshot data.
Drawing attention to alternative solutions for backup, we noticed that they, as a rule, use their kernel module to create snapshots of block devices. We decided to go this way by writing our own module. It was decided to distribute it under the GPL license, so that it is publicly available on github .
So, now we will consider the general principle of operation of the module and in more detail we will stop on key problems.
In fact, veeamsnap (as we called our kernel module) is a block device driver filter.

His job is to intercept requests to the block device driver.
Intercepting the write request, the module copies data from the original block device to the snapshot data area. Let's call this area snapstory.
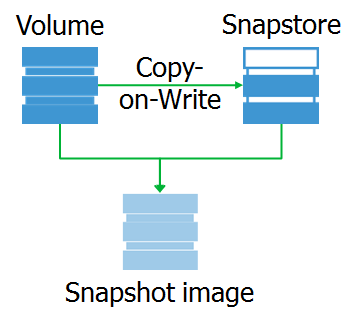
And what is the snapshot itself? This is a virtual block device, a copy of the original device at a specific point in time. When accessing data blocks on this device, they can be read either from snapstores or from the original device.
I want to note that snapshot is a block device that is completely identical to the original at the time of snapshot removal. Thanks to this, we can mount the file system on snapshot and perform the necessary preprocessing.
For example, we can get a map of busy blocks from the file system. The easiest way to do this is to use ioctl GETFSMAP .
The data on occupied blocks allows you to read only actual data from snapshots.
Also, you can exclude some files. Well, quite an optional action: index files that fall into the backup, for the possibility of a granular restaurant in the future.
Let's dwell a bit on the choice of the snapshot algorithm. The choice here is not particularly extensive: Copy-on-Write or Redirect-on-Write .
Redirect-on-Write, when intercepting a write request, will redirect it to snapstore, after which all requests to read this block will go there. Remarkable algorithm for storage systems based on B + trees, such as BTRFS, ZFS and Thin Provisioning. The technology is as old as the world, but it shows itself especially well in hypervisors, where you can create a new file and write new blocks there for the duration of the snapshot. Performance is excellent compared to CoW. But there is a fat minus - the structure of the original device changes, and when you remove the snapshot, you need to copy all the blocks from the snapstores to the original place.
When intercepting a request, Copy-on-Write copies the data to the snapshot, which should undergo a change, and then allows it to be overwritten in the original place. Used to create snapshots for LVM volumes and shadow copies of VSS. Obviously, it is more suitable for creating snapshots of block devices, since does not change the structure of the original device, and when you delete (or crash), snapshots can be simply discarded without risking the data. The disadvantage of this approach is a decrease in performance, since a pair of read / write operations is added to each write operation.
Since the preservation of data is our main priority, we chose CoW.
So far, everything looks simple, so let's take a look at real-life problems.
For him, and all thought.
For example, if at the moment of creating a snapshot (in the first approximation, we can assume that it is being created instantly), a file will be written to some file, then in the snapshot the file will be undefined, which means damaged and meaningless. The situation is similar with the database files and the file system itself.
But we live in the 21st century! There are journaling mechanisms that protect against such problems! The remark is true, however, there is an important “but”: this protection is not from failure, but from its consequences. When restoring to a consistent state in the log, the incomplete operations will be discarded, which means they will be lost. Therefore, it is important to shift the priority to protection against the cause, and not to treat the consequences.
The system can be warned that snapshot will be created now. To do this, the kernel has functions freeze_bdev and thaw_bdev . They pull freeze_fs and unfreeze_fs file system functions. When calling the first one, the system should reset the cache, suspend the creation of new requests to the block device and wait until all previously generated requests are completed. And when unfreeze_fs is called, the file system restores its normal operation.
It turns out that we can warn the file system. And what about the applications? Here, unfortunately, everything is bad. While in Windows there is a VSS mechanism that, with the help of Writers, provides interaction with other products, in Linux everyone goes his own way. At the moment, this has led to the situation that the task of the system administrator is to write (copy,steal , buy, etc) the pre-freeze and post-thaw scripts that will prepare their application for snapshots. For our part, in the next release we will introduce support for Oracle Application Processing, as the function most frequently requested by our customers. Then, perhaps, other applications will be supported, but in general the situation is rather sad.
This is the second problem arising in our path. At first glance, the problem is not obvious, but, having a little understood, we will see that this is still a thorn.
Of course, the simplest solution is to place the snapshot in RAM. For the developer, the option is just great! Everything is fast, it is very convenient to do debugging, but there is a cant: RAM is a valuable resource, and no one will give us a large snapshot.
OK, let's make snapstore a regular file. But another problem arises - it is impossible to backup the volume on which snapstora is located. The reason is simple: we intercept requests to write, which means we will intercept our own requests to write to snapstore. Horses ran in circles, scientifically deadlock. Following this, there is a strong desire to use a separate disk for this, but no one will add disks to the server for us. We must be able to work on what is.
To place a snapshot remotely - the idea is excellent, but realizable in very narrow circles of networks with high bandwidth and microscopic latency. Otherwise, while holding the snapshot, the machine will have a turn-based strategy.
So, you need to somehow sneakly place the snapshot on a local disk. But, as a rule, all space on local disks is already distributed between file systems, and at the same time we need to think hard about how to get around the deadlock problem.
The direction for thinking, in principle, is one thing: you need to somehow allocate space from the file system, but work directly with the block device. The solution to this problem was implemented in the user-space code, in the service.
There is a fallocate system call that allows you to create an empty file of the desired size. In this case, in fact, only metadata is created on the file system that describes the location of the file on the volume. And ioctl FIEMAP allows us to get a map of the location of the file blocks.
And voila: we create a file under snapstore using fallocate, FIEMAP gives us a block map of this file, which we can transfer to work in our veeamsnap module. Further, when accessing SnapStop, the module makes requests directly to the block device into known blocks, and no deadlocks.
But there is a nuance. The fallocate system call only supports XFS, EXT4 and BTRFS. For other file systems like EXT3, for allocating a file, you have to write it down completely. On the functional, this affects the increase in time for preparing snapstors, but it is not necessary to choose. Again, you need to be able to work on what is.
What if ioctl FIEMAP is also not supported? This is the reality of NTFS and FAT32, where there is not even support for the ancient FIBMAP. I had to implement a generic algorithm, whose work does not depend on the file system features. In a nutshell, an algorithm like this:
Yes, difficult, yes, slowly, but better than nothing. It is used in isolated cases for file systems without the support of FIEMAP and FIBMAP.
Rather, the place we allocated for snapstor is ending. The essence of the problem is that the new data has nowhere to discard, which means that the snapshot becomes unusable.
What to do?
Obviously, you need to increase the size of snapshots. How much? The easiest way to set the size of snapshots is to determine the percentage of free space on the volume (as was done for VSS). For a 20 TB volume, 10% will be 2TB - which is a lot for an unloaded server. For a 200 GB volume, 10% will be 20GB, which may be too small for a server that intensively updates its data. And there are still thin volumes ...
In general, only the system administrator of the server can estimate the optimal size of the required snapshots in advance, that is, you have to make the person think and give his expert opinion. This is not consistent with the principle of “It just work”.
To solve this problem, we developed a stretch snapshot algorithm. The idea is to break snaps into chunks. At the same time, new portions are created after the creation of snapshots as needed.

Again, a short algorithm:
It is important to note that the module should have time to create new snapshots as needed, otherwise - overflow, dump snapshot and no backup. Therefore, the operation of such an algorithm is possible only on file systems that support fallocate, where you can quickly create an empty file.
What to do in other cases? We try to guess the required size and create the entire snapstor entirely. But according to our statistics, the vast majority of Linux servers now use EXT4 and XFS. EXT3 is found on older machines. But in SLES / openSUSE you can stumble on BTRFS.
Incremental or differential backup (by the way, horseradish is sweeter or not, I suggest reading here ) - without it, no adult backup product can be imagined. And for this to work, you need CBT. If someone missed: CBT allows you to track changes and write to the backup only the data changed from the last backup.

Many people have their own experience in this area. For example, in VMware vSphere, this feature is available from version 4 in 2009. In Hyper-V, support was introduced with Windows Server 2016, and to support earlier releases, the VeeamFCT driver was developed as early as 2012. Therefore, for our module, we did not begin to originate and used already working algorithms.
A little about how it works.
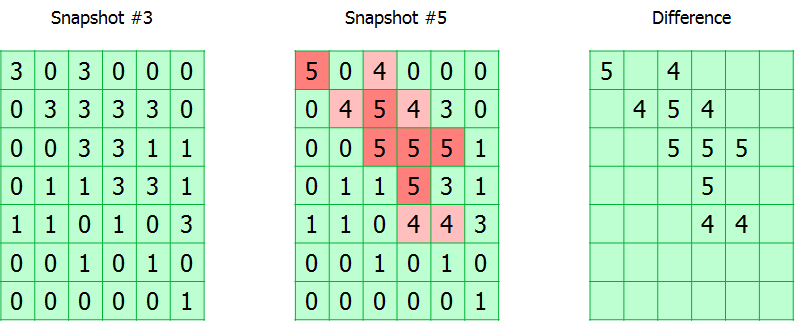
The entire monitored volume is divided into blocks. The module simply keeps track of all write requests, marking the changed blocks in the table. In fact, the CBT table is an array of bytes, where each byte corresponds to a block and contains the snapshot number in which it was modified.
During backup, the snapshot number is recorded in the backup metadata. Thus, knowing the current snapshot number and the one from which the previous successful backup was made, you can calculate the map of the location of the changed blocks.
There are two nuances.
As I said, one byte is allocated for the snapshot number in the CBT table, which means that the maximum length of the incremental chain cannot be greater than 255. When this threshold is reached, the table is reset and a full backup occurs. It may seem inconvenient, but in fact a chain of 255 increments is far from the best solution when creating a backup plan.
The second feature is the storage of CBT tables only in RAM. This means that when the target machine is rebooted or the module is unloaded, it will be reset, and again, you will need to create a full backup. This solution allows you to not solve the problem of starting the module at system startup. In addition, there is no need to save the CBT tables when the system is turned off.
Backup is always a good load on your equipment's IO. If it already has enough active tasks, then the backup process can turn your system into a sort of sloth .
Let's see why.
Imagine that the server just writes some linear data. The recording speed in this case is maximum, all delays are minimized, performance tends to the maximum. Now we will add the backup process here, which, with each write, must still have time to execute the Copy-on-Write algorithm, which is an additional read operation followed by a write. And do not forget that for backup, you must also read the data from the same volume. In short, your beautiful linear access turns into a merciless random access with all that it implies.
We obviously need to do something with this, and we have implemented a pipeline to process requests not one at a time, but in whole batches. It works like this.
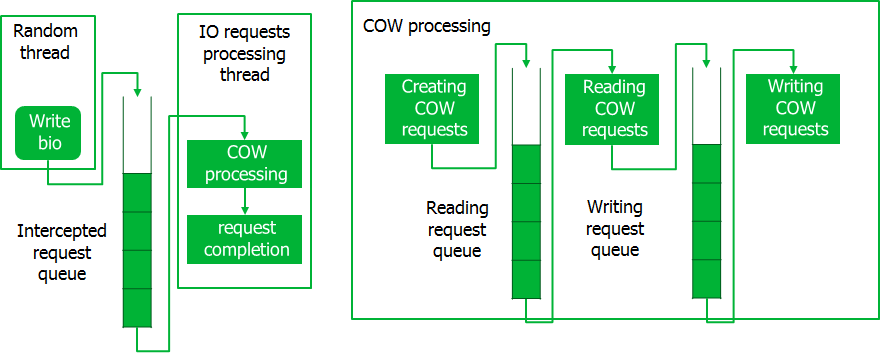
When intercepting requests, they are placed in a queue, from where their special flow takes them in portions. At this time, CoW requests are created, which are also processed in chunks. When processing CoW requests, all read operations for the entire batch are performed first, and then write operations are performed. Only after the processing of the entire portion of the CoW requests is completed, the intercepted requests are executed. Such a pipeline provides disk access in large portions of data, which minimizes temporary losses.
Already at the stage of debugging surfaced more nuance. During the backup, the system became non-responsive, i.e. system I / O requests started with long delays. On the other hand, requests to read data from snapshot were executed at a speed close to the maximum.
I had to strangle the backup process a bit by implementing the trotting mechanism. To do this, the process reading from the snapshot image is transferred to the waiting state if the queue of intercepted requests is not empty. Expectedly, the system came to life.
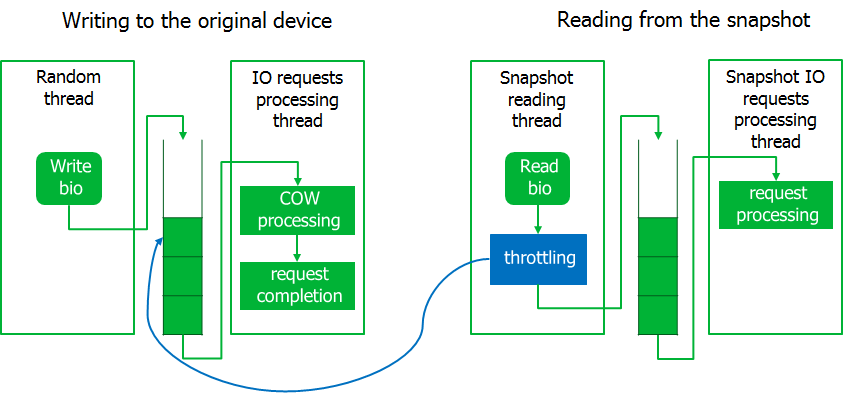
As a result, if the load on the I / O system increases dramatically, then the process of reading from snapshot will wait. Here we decided to be guided by the principle that we'd better complete the backup with an error than to disrupt the server.
I think we need to explain in some detail what it is.
Already at the testing stage, we began to deal with situations of complete system hanging with a diagnosis: seven troubles - one reset.
Began to understand. It turned out that such a situation can be observed if, for example, you create a snapshot of a block device on which the LVM volume is located, and the snapshot is placed on the same LVM volume. Let me remind you that LVM uses the device mapper kernel module.

In this situation, when intercepting a request for a record, the module, by copying the data to the snapshot, will send a request to write to the LVM volume. The device mapper will redirect this request to a block device. The request from the device mapper will be intercepted by the module again. But a new request cannot be processed until the previous one has been processed. As a result, request processing is blocked, you are welcomed by deadlock.
In order to prevent such a situation, the kernel module itself provides a timeout for the operation of copying data to the snapshot. This allows you to detect a deadlock and abort the backup. The logic here is the same: it is better not to make a backup than to hang the server.
This is already a problem thrown by users after the release of the first version.
It turned out that there are such services, which are the only ones that are constantly rewriting the same blocks. A vivid example is monitoring services that constantly generate system state data and overwrite it in a circle. For such tasks use specialized cyclic databases ( RRD ).
It turned out that when backing up such bases snapshot is guaranteed to overflow. A detailed study of the problem, we found a flaw in the implementation of the CoW algorithm. If the same block was overwritten, the data was copied to the snapshot each time. Result: data duplication in snapstore.
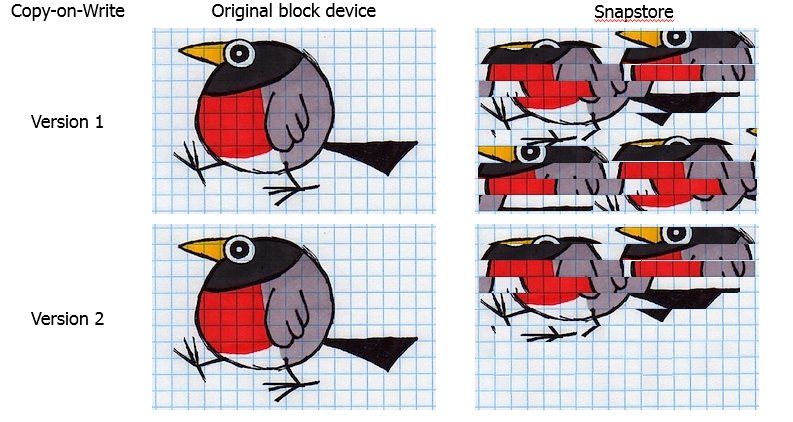
Naturally, we changed the algorithm. Now the volume is divided into blocks, and the data is copied to the snapshot blocks. If the block has already been copied once, then this process is not repeated.
Now, when snapstora is divided into blocks, the question arises: what size is it necessary to make blocks for splitting snapstores?
The problem is twofold. If a block is made large, it is easier for them to operate, but if at least one sector changes, they will have to send the entire block to the snapshot and, as a result, the chances of overflowing snapshots increase.

Obviously, the smaller the block size, the greater the percentage of useful data sent to snapshot, but how will this hit performance?
Truth was sought empirically and came to the result in 16KiB. Also note that Windows VSS also uses 16 KiB blocks.
That's all for now. I’ll leave many other equally interesting problems behind the board, such as dependence on kernel versions, choice of module distribution options, kABI compatibility, working in backporting conditions, etc. The article turned out to be voluminous, so I decided to dwell on the most interesting problems.
Now we are preparing for release version 3.0, the module code is on github , and anyone can use it under the GPL license.
The inspiration for this article served as my report at the Linux Piter conference, which I decided to issue as an article for all interested artists.
In the article, I will cover the topic of creating snapshots, which allows you to make a backup, and tell you about the problems that we faced when creating our own mechanism for creating snapshots of block devices.
')
All interested in asking under the cat!
A bit of theory at the beginning
Historically, there are two approaches to creating backups: File backup and Volume backup. In the first case, we copy each file as a separate object; in the second, we copy the entire contents of the volume as an image.
Both methods have a lot of their pros and cons, but we will look at them through the prism of recovery after a failure:
- In the case of File backup, in order to fully restore the server as a whole, we need to first install the OS, then the necessary services and only after that restore the files from the backup.
- In the case of Volume backup for full recovery, it is enough just to restore all the volumes of the machine without any extra effort from the person.
Obviously, in the case of Volume backup, you can restore the system as quickly as possible, and this is an important feature of the system . Therefore, for ourselves, we note volume backup as a more preferred option.
How do we take and keep the entire volume entirely? Of course, by simple copying, we will not achieve anything good. During copying, some activity with data will occur on the volume; as a result, inconsistent data will appear in the backup. The file system structure will be broken, database files are damaged, as well as other files with which operations will be performed during copying.
To avoid all these problems, progressive humanity came up with the technology of snapshot - snapshot. In theory, everything is simple: create an immutable copy - snapshot - and back up the data from it. When the backup is finished, snapshot is destroyed. It sounds simple, but, as usual, there are nuances.
Because of them, many implementations of this technology were born. For example, device mapper- based solutions, such as LVM and Thin provisioning, provide full-fledged snapshots of volumes, but require special disk markup at the system installation stage, which means that they are generally not suitable.
BTRFS and ZFS make it possible to create snapshots of file system substructures, which is very cool, but at the moment their share on the servers is small, and we are trying to make a universal solution.
Suppose on our block device there is a banal EXT. In this case, we can use dm-snap (by the way, a dm-bow is being developed), but here’s a nuance. You need to have a free block device at the ready, so that there is where to drop snapshot data.
Drawing attention to alternative solutions for backup, we noticed that they, as a rule, use their kernel module to create snapshots of block devices. We decided to go this way by writing our own module. It was decided to distribute it under the GPL license, so that it is publicly available on github .
How it works - in theory
Snapshot under the microscope
So, now we will consider the general principle of operation of the module and in more detail we will stop on key problems.
In fact, veeamsnap (as we called our kernel module) is a block device driver filter.
His job is to intercept requests to the block device driver.
Intercepting the write request, the module copies data from the original block device to the snapshot data area. Let's call this area snapstory.
And what is the snapshot itself? This is a virtual block device, a copy of the original device at a specific point in time. When accessing data blocks on this device, they can be read either from snapstores or from the original device.
I want to note that snapshot is a block device that is completely identical to the original at the time of snapshot removal. Thanks to this, we can mount the file system on snapshot and perform the necessary preprocessing.
For example, we can get a map of busy blocks from the file system. The easiest way to do this is to use ioctl GETFSMAP .
The data on occupied blocks allows you to read only actual data from snapshots.
Also, you can exclude some files. Well, quite an optional action: index files that fall into the backup, for the possibility of a granular restaurant in the future.
CoW vs RoW
Let's dwell a bit on the choice of the snapshot algorithm. The choice here is not particularly extensive: Copy-on-Write or Redirect-on-Write .
Redirect-on-Write, when intercepting a write request, will redirect it to snapstore, after which all requests to read this block will go there. Remarkable algorithm for storage systems based on B + trees, such as BTRFS, ZFS and Thin Provisioning. The technology is as old as the world, but it shows itself especially well in hypervisors, where you can create a new file and write new blocks there for the duration of the snapshot. Performance is excellent compared to CoW. But there is a fat minus - the structure of the original device changes, and when you remove the snapshot, you need to copy all the blocks from the snapstores to the original place.
When intercepting a request, Copy-on-Write copies the data to the snapshot, which should undergo a change, and then allows it to be overwritten in the original place. Used to create snapshots for LVM volumes and shadow copies of VSS. Obviously, it is more suitable for creating snapshots of block devices, since does not change the structure of the original device, and when you delete (or crash), snapshots can be simply discarded without risking the data. The disadvantage of this approach is a decrease in performance, since a pair of read / write operations is added to each write operation.
Since the preservation of data is our main priority, we chose CoW.
So far, everything looks simple, so let's take a look at real-life problems.
How it works - in practice
Agreed condition
For him, and all thought.
For example, if at the moment of creating a snapshot (in the first approximation, we can assume that it is being created instantly), a file will be written to some file, then in the snapshot the file will be undefined, which means damaged and meaningless. The situation is similar with the database files and the file system itself.
But we live in the 21st century! There are journaling mechanisms that protect against such problems! The remark is true, however, there is an important “but”: this protection is not from failure, but from its consequences. When restoring to a consistent state in the log, the incomplete operations will be discarded, which means they will be lost. Therefore, it is important to shift the priority to protection against the cause, and not to treat the consequences.
The system can be warned that snapshot will be created now. To do this, the kernel has functions freeze_bdev and thaw_bdev . They pull freeze_fs and unfreeze_fs file system functions. When calling the first one, the system should reset the cache, suspend the creation of new requests to the block device and wait until all previously generated requests are completed. And when unfreeze_fs is called, the file system restores its normal operation.
It turns out that we can warn the file system. And what about the applications? Here, unfortunately, everything is bad. While in Windows there is a VSS mechanism that, with the help of Writers, provides interaction with other products, in Linux everyone goes his own way. At the moment, this has led to the situation that the task of the system administrator is to write (copy,
Where to place snapstoru?
This is the second problem arising in our path. At first glance, the problem is not obvious, but, having a little understood, we will see that this is still a thorn.
Of course, the simplest solution is to place the snapshot in RAM. For the developer, the option is just great! Everything is fast, it is very convenient to do debugging, but there is a cant: RAM is a valuable resource, and no one will give us a large snapshot.
OK, let's make snapstore a regular file. But another problem arises - it is impossible to backup the volume on which snapstora is located. The reason is simple: we intercept requests to write, which means we will intercept our own requests to write to snapstore. Horses ran in circles, scientifically deadlock. Following this, there is a strong desire to use a separate disk for this, but no one will add disks to the server for us. We must be able to work on what is.
To place a snapshot remotely - the idea is excellent, but realizable in very narrow circles of networks with high bandwidth and microscopic latency. Otherwise, while holding the snapshot, the machine will have a turn-based strategy.
So, you need to somehow sneakly place the snapshot on a local disk. But, as a rule, all space on local disks is already distributed between file systems, and at the same time we need to think hard about how to get around the deadlock problem.
The direction for thinking, in principle, is one thing: you need to somehow allocate space from the file system, but work directly with the block device. The solution to this problem was implemented in the user-space code, in the service.
There is a fallocate system call that allows you to create an empty file of the desired size. In this case, in fact, only metadata is created on the file system that describes the location of the file on the volume. And ioctl FIEMAP allows us to get a map of the location of the file blocks.
And voila: we create a file under snapstore using fallocate, FIEMAP gives us a block map of this file, which we can transfer to work in our veeamsnap module. Further, when accessing SnapStop, the module makes requests directly to the block device into known blocks, and no deadlocks.
But there is a nuance. The fallocate system call only supports XFS, EXT4 and BTRFS. For other file systems like EXT3, for allocating a file, you have to write it down completely. On the functional, this affects the increase in time for preparing snapstors, but it is not necessary to choose. Again, you need to be able to work on what is.
What if ioctl FIEMAP is also not supported? This is the reality of NTFS and FAT32, where there is not even support for the ancient FIBMAP. I had to implement a generic algorithm, whose work does not depend on the file system features. In a nutshell, an algorithm like this:
- The service creates a file and starts writing a specific pattern to it.
- The module intercepts the write requests, checks the recorded data.
- If the block data matches the specified pattern, then the block is marked as snapstore related.
Yes, difficult, yes, slowly, but better than nothing. It is used in isolated cases for file systems without the support of FIEMAP and FIBMAP.
Snapshot overflow
Rather, the place we allocated for snapstor is ending. The essence of the problem is that the new data has nowhere to discard, which means that the snapshot becomes unusable.
What to do?
Obviously, you need to increase the size of snapshots. How much? The easiest way to set the size of snapshots is to determine the percentage of free space on the volume (as was done for VSS). For a 20 TB volume, 10% will be 2TB - which is a lot for an unloaded server. For a 200 GB volume, 10% will be 20GB, which may be too small for a server that intensively updates its data. And there are still thin volumes ...
In general, only the system administrator of the server can estimate the optimal size of the required snapshots in advance, that is, you have to make the person think and give his expert opinion. This is not consistent with the principle of “It just work”.
To solve this problem, we developed a stretch snapshot algorithm. The idea is to break snaps into chunks. At the same time, new portions are created after the creation of snapshots as needed.
Again, a short algorithm:
- Before creating the snapshot, the first portion of snapshots is created and given to the module.
- When snapshot is created, the portion will begin to fill.
- As soon as half of the portion is filled, a request is sent to the service to create a new one.
- Service creates it, gives the data to the module.
- The module begins to fill the next batch.
- The algorithm is repeated until either the backup is completed, or until we rest on the free disk space usage limit.
It is important to note that the module should have time to create new snapshots as needed, otherwise - overflow, dump snapshot and no backup. Therefore, the operation of such an algorithm is possible only on file systems that support fallocate, where you can quickly create an empty file.
What to do in other cases? We try to guess the required size and create the entire snapstor entirely. But according to our statistics, the vast majority of Linux servers now use EXT4 and XFS. EXT3 is found on older machines. But in SLES / openSUSE you can stumble on BTRFS.
Change Block Tracking (CBT)
Incremental or differential backup (by the way, horseradish is sweeter or not, I suggest reading here ) - without it, no adult backup product can be imagined. And for this to work, you need CBT. If someone missed: CBT allows you to track changes and write to the backup only the data changed from the last backup.
Many people have their own experience in this area. For example, in VMware vSphere, this feature is available from version 4 in 2009. In Hyper-V, support was introduced with Windows Server 2016, and to support earlier releases, the VeeamFCT driver was developed as early as 2012. Therefore, for our module, we did not begin to originate and used already working algorithms.
A little about how it works.
The entire monitored volume is divided into blocks. The module simply keeps track of all write requests, marking the changed blocks in the table. In fact, the CBT table is an array of bytes, where each byte corresponds to a block and contains the snapshot number in which it was modified.
During backup, the snapshot number is recorded in the backup metadata. Thus, knowing the current snapshot number and the one from which the previous successful backup was made, you can calculate the map of the location of the changed blocks.
There are two nuances.
As I said, one byte is allocated for the snapshot number in the CBT table, which means that the maximum length of the incremental chain cannot be greater than 255. When this threshold is reached, the table is reset and a full backup occurs. It may seem inconvenient, but in fact a chain of 255 increments is far from the best solution when creating a backup plan.
The second feature is the storage of CBT tables only in RAM. This means that when the target machine is rebooted or the module is unloaded, it will be reset, and again, you will need to create a full backup. This solution allows you to not solve the problem of starting the module at system startup. In addition, there is no need to save the CBT tables when the system is turned off.
Performance issue
Backup is always a good load on your equipment's IO. If it already has enough active tasks, then the backup process can turn your system into a sort of sloth .
Let's see why.
Imagine that the server just writes some linear data. The recording speed in this case is maximum, all delays are minimized, performance tends to the maximum. Now we will add the backup process here, which, with each write, must still have time to execute the Copy-on-Write algorithm, which is an additional read operation followed by a write. And do not forget that for backup, you must also read the data from the same volume. In short, your beautiful linear access turns into a merciless random access with all that it implies.
We obviously need to do something with this, and we have implemented a pipeline to process requests not one at a time, but in whole batches. It works like this.
When intercepting requests, they are placed in a queue, from where their special flow takes them in portions. At this time, CoW requests are created, which are also processed in chunks. When processing CoW requests, all read operations for the entire batch are performed first, and then write operations are performed. Only after the processing of the entire portion of the CoW requests is completed, the intercepted requests are executed. Such a pipeline provides disk access in large portions of data, which minimizes temporary losses.
Throttling
Already at the stage of debugging surfaced more nuance. During the backup, the system became non-responsive, i.e. system I / O requests started with long delays. On the other hand, requests to read data from snapshot were executed at a speed close to the maximum.
I had to strangle the backup process a bit by implementing the trotting mechanism. To do this, the process reading from the snapshot image is transferred to the waiting state if the queue of intercepted requests is not empty. Expectedly, the system came to life.
As a result, if the load on the I / O system increases dramatically, then the process of reading from snapshot will wait. Here we decided to be guided by the principle that we'd better complete the backup with an error than to disrupt the server.
Deadlock
I think we need to explain in some detail what it is.
Already at the testing stage, we began to deal with situations of complete system hanging with a diagnosis: seven troubles - one reset.
Began to understand. It turned out that such a situation can be observed if, for example, you create a snapshot of a block device on which the LVM volume is located, and the snapshot is placed on the same LVM volume. Let me remind you that LVM uses the device mapper kernel module.
In this situation, when intercepting a request for a record, the module, by copying the data to the snapshot, will send a request to write to the LVM volume. The device mapper will redirect this request to a block device. The request from the device mapper will be intercepted by the module again. But a new request cannot be processed until the previous one has been processed. As a result, request processing is blocked, you are welcomed by deadlock.
In order to prevent such a situation, the kernel module itself provides a timeout for the operation of copying data to the snapshot. This allows you to detect a deadlock and abort the backup. The logic here is the same: it is better not to make a backup than to hang the server.
Round Robin Database
This is already a problem thrown by users after the release of the first version.
It turned out that there are such services, which are the only ones that are constantly rewriting the same blocks. A vivid example is monitoring services that constantly generate system state data and overwrite it in a circle. For such tasks use specialized cyclic databases ( RRD ).
It turned out that when backing up such bases snapshot is guaranteed to overflow. A detailed study of the problem, we found a flaw in the implementation of the CoW algorithm. If the same block was overwritten, the data was copied to the snapshot each time. Result: data duplication in snapstore.
Naturally, we changed the algorithm. Now the volume is divided into blocks, and the data is copied to the snapshot blocks. If the block has already been copied once, then this process is not repeated.
Select block size
Now, when snapstora is divided into blocks, the question arises: what size is it necessary to make blocks for splitting snapstores?
The problem is twofold. If a block is made large, it is easier for them to operate, but if at least one sector changes, they will have to send the entire block to the snapshot and, as a result, the chances of overflowing snapshots increase.
Obviously, the smaller the block size, the greater the percentage of useful data sent to snapshot, but how will this hit performance?
Truth was sought empirically and came to the result in 16KiB. Also note that Windows VSS also uses 16 KiB blocks.
Instead of conclusion
That's all for now. I’ll leave many other equally interesting problems behind the board, such as dependence on kernel versions, choice of module distribution options, kABI compatibility, working in backporting conditions, etc. The article turned out to be voluminous, so I decided to dwell on the most interesting problems.
Now we are preparing for release version 3.0, the module code is on github , and anyone can use it under the GPL license.
Source: https://habr.com/ru/post/430770/
All Articles