Neural Network Architecture
Neural Network Architectures Translation
Algorithms of deep neural networks today have gained great popularity, which is largely ensured by the well thought-out architecture. Let's look at the history of their development over the past few years. If you are interested in a deeper analysis, refer to this work .
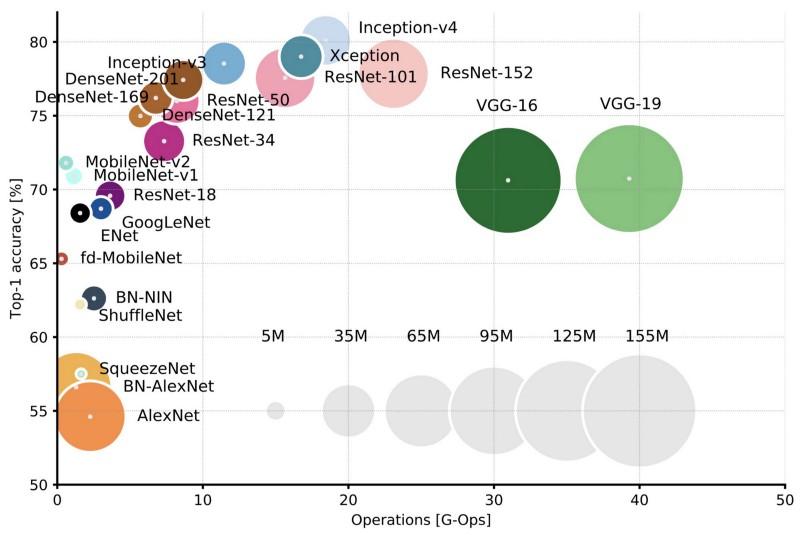
Comparison of popular architectures for Top-1 one-crop accuracy and the number of operations required for one straight pass. Read more here .
In 1994, one of the first convolutional neural networks was developed, which marked the beginning of deep learning. This pioneering work of Yan Lekun (Yann LeCun) after many successful iterations since 1988 has received the name LeNet5 !
')

The architecture of LeNet5 has become fundamental for deep learning, especially in terms of the distribution of image properties throughout the entire picture. Convolutions with trained parameters made it possible with the help of several parameters to efficiently extract the same properties from different places. In those years there were still no video cards capable of speeding up the learning process, and even the central processors were slow. Therefore, the key advantage of the architecture was the ability to save the parameters and results of calculations, in contrast to the use of each pixel as separate input data for a large multilayered neural network. In LeNet5, in the first layer, pixels are not used, because the images are highly correlated spatially, so using separate pixels as input properties will not allow you to take advantage of these correlations.
LeNet5 features:
This neural network formed the basis of many subsequent architectures and inspired many researchers.
From 1998 to 2010, the neural networks were in a state of incubation. Most people did not notice their growing capabilities, although many developers gradually honed the algorithms. Due to the flourishing of mobile phone cameras and the cheapening of digital cameras, more and more training data became available to us. At the same time, computing capabilities grew, processors became more powerful, and video cards became the main computing tool. All these processes allowed the development of neural networks, albeit rather slowly. Interest in the tasks that could be solved using neural networks increased, and finally the situation became obvious ...
In 2010, Dan Kireshan (Dan Claudiu Ciresan) and Jörgen Schmidhuber published one of the first descriptions of the implementation of GPU-neural networks . Their work contained a direct and reverse implementation of a 9-layer neural network on the NVIDIA GTX 280 .
In 2012, Alexey Krizhevsky published AlexNet , an in-depth and extended version of LeNet, which won by a large margin in the difficult competition ImageNet.
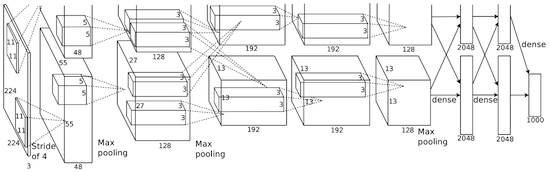
In AlexNet, the results of LeNet calculations are scaled to a much larger neural network, which is able to study much more complex objects and their hierarchies. Features of this solution:
By that time, the number of cores in the video cards had greatly increased, which made it possible to reduce the training time by about 10 times, and as a result, it became possible to use much larger datasets and pictures.
The success of AlexNet launched a small revolution, convolutional neural networks turned into a workhorse of deep learning - this term henceforth meant "large neural networks capable of solving useful tasks."
In December 2013, NYU Laboratory Yana Lekuna published a description of Overfeat , a variety of AlexNet. The article also described the bounding boxes, and subsequently many other works on this subject were published. We believe that it is better to learn how to segment objects, and not to use artificial bounding boxes.
In Oxford-developed VGG networks, for each convolutional layer, 3x3 filters were first used, and they also combined these layers in a sequence of convolutions.
This is contrary to the principles in LeNet, according to which large bundles were used to extract the same image properties. Instead of the 9x9 and 11x11 filters used in AlexNet, much smaller filters began to be used, dangerously close to the 1x1 convolutions, which LeNet authors tried to avoid, at least in the first layers of the network. But the great advantage of VGG was the discovery that several 3x3 bundles combined into a sequence could emulate larger receptive fields, for example, 5x5 or 7x7. These ideas will later be used in the Inception and ResNet architectures.
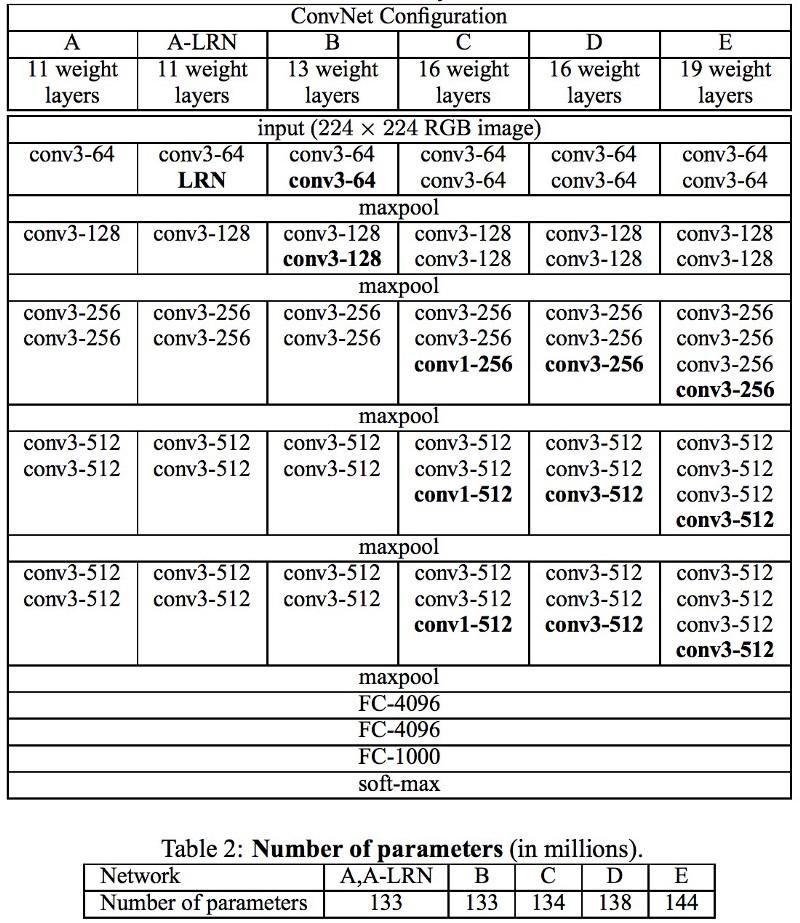
VGG networks use multiple 3x3 convolutional layers to represent complex properties. Note blocks 3, 4, and 5 in VGG-E: 256 × 256 and 512 × 512 3 × 3 filter sequences are used to extract more complex properties and combine them. This is tantamount to large convolutional classifiers 512x512 with three layers! This gives us a huge amount of parameters and excellent learning abilities. But it was difficult to learn such networks, it was necessary to break them up into smaller ones, adding layers one by one. The reason was the lack of effective ways to regularize models or some methods of restricting a large search space, which is supported by many parameters.
VGG in many layers use a large number of properties, so the training required a large computational cost . You can reduce the load by reducing the number of properties, as is done in the bottleneck layers of the Inception architecture.
The network-in-network (NiN) architecture is based on a simple idea: using 1x1 bundles to increase the combinatorial properties of the convolutional layers.
In NiN, spatial MLP layers are applied after each convolution in order to better combine the properties before feeding to the next layer. It may seem that the use of 1x1 bundles is contrary to the original LeNet principles, but in fact it allows you to combine properties better than just stuffing more convolutional layers. This approach differs from using bare pixels as input to the next layer. In this case, 1x1 convolutions are used for spatial combination of properties after convolution within property maps, so much fewer parameters can be used that are common to all pixels of these properties!
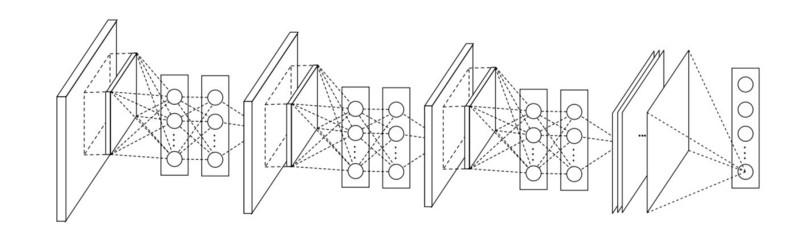
MLPs can greatly enhance the efficiency of individual convolutional layers by combining them into more complex groups. This idea was later used in other architectures, such as ResNet, Inception, and their variants.
Google's Christian Szegedy has bothered to reduce the amount of computation in deep neural networks, and as a result, he created GoogLeNet, the first Inception architecture .
By the fall of 2014, deep learning models have become very useful in categorizing the contents of images and frames from video. Many skeptics have recognized the benefits of deep learning and neural networks, and Internet giants, including Google, have been greatly interested in deploying efficient and large networks on their server capacities.
Christian was looking for ways to reduce the computational load in neural networks, achieving the highest performance (for example, in ImageNet). Or keeping the amount of calculations, but still at the same time improving performance.
As a result, the team created the Inception module:

At first glance, this is a parallel combination of convolutional filters 1x1, 3x3 and 5x5. But the highlight was the use of 1x1 convolutional blocks (NiN) to reduce the number of properties before serving in the "expensive" parallel blocks. Usually this part is called a bottleneck, it is described in more detail in the next chapter.
In GoogLeNet, a stem without Inception modules is used as the initial layer, and also uses an average pooling and softmax classifier similar to NiN. This classifier performs very few operations compared to AlexNet and VGG. It also helped create a very efficient neural network architecture .
This layer reduces the number of properties (and hence the operations) in each layer, so that the speed of obtaining the result can be kept at a high level. Before transferring data to “expensive” convolutional modules, the number of properties decreases, say, 4 times. This greatly reduces the amount of computation, which made the architecture popular.
Let's figure it out. Suppose we have 256 properties at the input and 256 at the output, and let the Inception-layer only perform 3x3 convolutions. We get 256x256x3x3 convolutions (589 000 multiply operations with accumulation, that is, MAC operations). This may go beyond our computational rate requirements, say that a layer was processed in 0.5 milliseconds on Google Server. Then reduce the number of properties for coagulation to 64 (256/4). In this case, we first execute the convolution 1x1 256 -> 64, then another 64 convolutions in all Inception branches, and then again apply the convolution 1x1 of 64 -> 256 properties. Number of operations:
A total of about 70,000, reduced the number of operations almost 10 times! But at the same time, we did not lose generalization in this layer. Bottleneck layers showed superior performance on dataset ImageNet, and were used in later architectures such as ResNet. The reason for their success is that the input properties are correlated, which means you can get rid of redundancy by correctly combining the properties with 1x1 convolutions. And after coagulation with a smaller number of properties, it is possible on the next layer to expand them again into a meaningful combination.
Christian and his team have been very effective researchers. In February 2015, the architecture of Batch-normalized Inception was introduced as the second version of Inception . Batch normalization (batch-normalization) calculates the mean and standard deviation of all property distribution maps in the output layer, and normalizes their responses with these values. This corresponds to the "bleaching" of the data, that is, the responses of all neural maps lie in the same range and with zero mean. This approach facilitates learning, because the subsequent layer does not have to remember the offsets of the input data and can only search for the best combinations of properties.
In December 2015, a new version of Inception modules and the corresponding architecture was released . The author’s article explains the original GoogLeNet architecture better, there is much more detail about the decisions made. Key ideas:
As the final classifier, Inception uses a softmax pooling layer.
In December 2015, at about the same time as the architecture of Inception v3 was presented, a revolution occurred - published ResNet . It contains simple ideas: we submit the output of two successful convolutional layers And bypass the input data for the next layer!

Such ideas have already been proposed, for example, here . But in this case, the authors bypass the TWO layers and apply the approach on a large scale. Bypassing one layer does not give much benefit, and bypassing two is a key finding. This can be considered as a small classifier, as a network-in-a-network!
It was also the first ever example of learning a network of several hundred, even thousands of layers.
In multi-layer ResNet, a bottleneck layer was used, similar to that used in Inception:

This layer reduces the number of properties in each layer, first using a 1x1 convolution with a lower output (usually a quarter of the input), then a 3x3 layer comes, and then again a 1x1 convolution into more properties. As in the case of Inception-modules, it saves computational resources, while maintaining a wealth of combinations of properties. Compare with more complex and less obvious stem in Inception V3 and V4.
ResNet uses a softmax for the final classifier in ResNet.
Every day there is more information about the ResNet architecture:
Once again, Christian and his team distinguished themselves by releasing a new version of Inception .
The inception module following the stem is the same as in Inception V3:

In this case, the Inception module is combined with the ResNet module:

This architecture turned out, for my taste, more complicated, less elegant, and also filled with imperfect heuristic solutions. It is difficult to understand why the authors made these or other decisions, and it is just as difficult to give them some kind of assessment.
Therefore, the prize for a clean and simple neural network, easy to understand and modify, goes to ResNet.
SqueezeNet published recently. This is a remake of a new way of many concepts from ResNet and Inception. The authors have demonstrated that improving the architecture can reduce the size of networks and the number of parameters without complex compression algorithms.
All the features of recent architectures are combined into a very efficient and compact network that uses very few parameters and computing power, but gives excellent results. The architecture was called ENet , it was developed by Adam Paszke. For example, we used it for very accurate marking of objects on the screen and parsing scenes. A few examples of how Enet works . These videos are not related to the training dataset .
Here you can find the technical details of ENet. This is a network based on the encoder and decoder. The encoder is built on the usual CNN scheme for categorization, and the decoder is an upsampling netowrk network designed for segmentation by distributing categories back to the original size image. For segmentation of images only neural networks were used, no other algorithms.
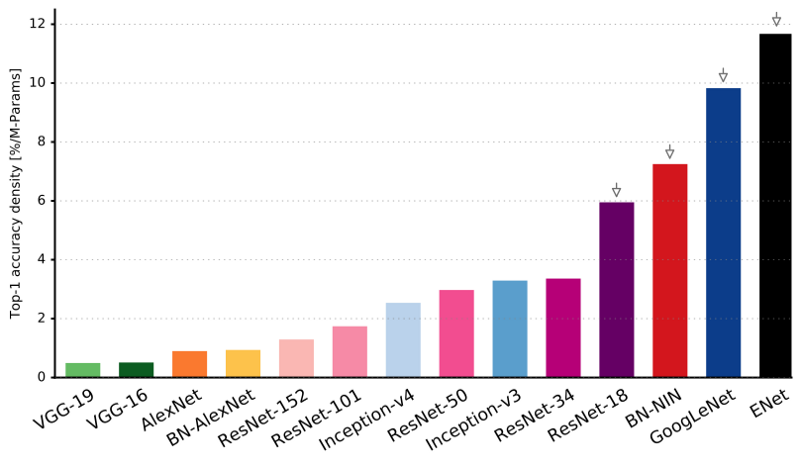
As you can see, ENet has the highest specific accuracy compared to all other neural networks.
ENet was designed to use as few resources as possible from the very beginning. As a result, the encoder and decoder together occupy only 0.7 MB with an accuracy of fp16. And with this tiny size, ENet is not inferior or superior to other purely neural network solutions in terms of segmentation accuracy.
Published a systematic assessment of CNN-modules. It turned out that it is profitable:
Xception introduced to the Inception module a simpler and more elegant architecture that is no less efficient than ResNet and Inception V4.
This is what the Xception module looks like:
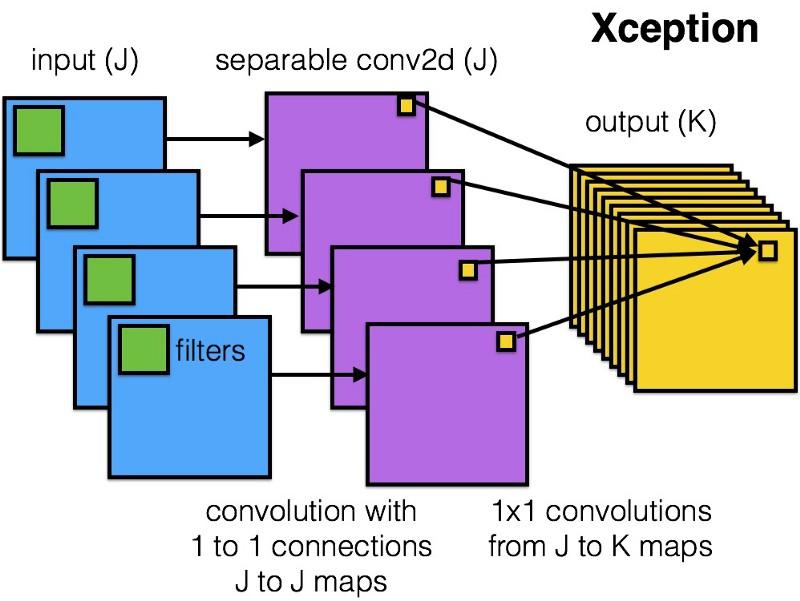
This network will appeal to anyone thanks to the simplicity and elegance of its architecture:

It contains 36 convolutions, and this is similar to ResNet-34. At the same time, the model and code are simple, as in ResNet, and much nicer than in Inception V4.
The Torch7 implementation of this network is available here , and the implementation on Keras / TF is here.
Curiously, the authors of the recent Xception architecture were also inspired by our work on separable convolution filters .
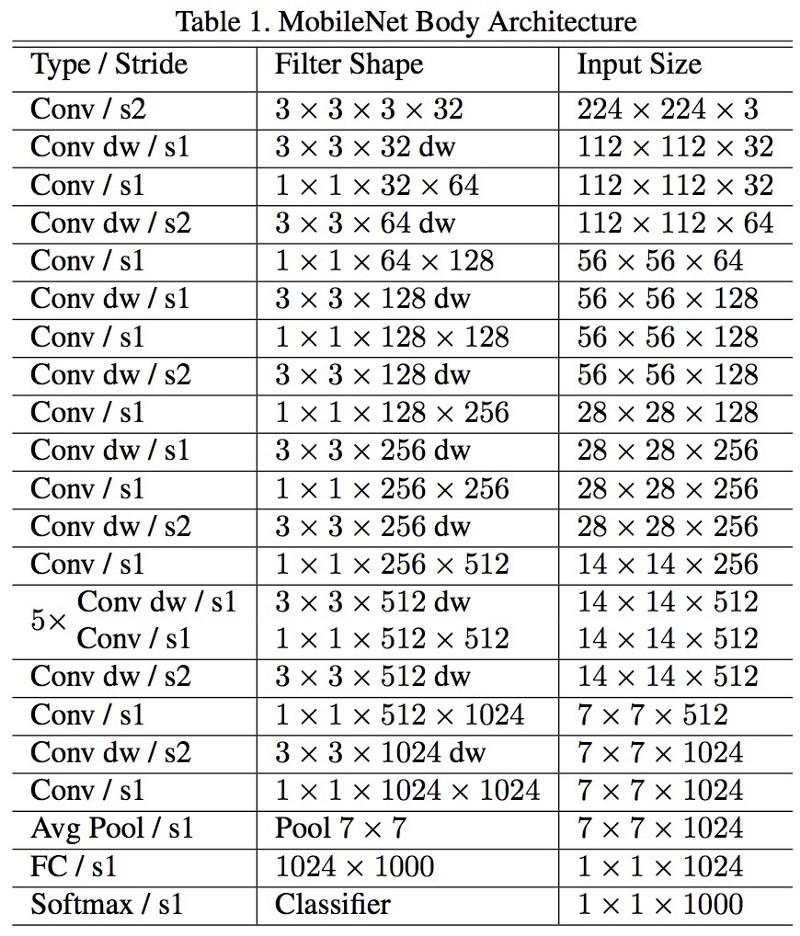
New architecture M obileNets was released in April 2017. To reduce the number of parameters, it uses detachable convolutions, the same as in Xception. Even in the paper it is argued that the authors were able to greatly reduce the number of parameters: approximately twice in the case of FaceNet. Full model architecture:
We tested this network in a real problem and found that it runs disproportionately slowly on the package of 1 (batch of 1) on the Titan Xp video card. Compare the duration of the output for one image:
This is not a quick job! The number of parameters and the size of the network on the disk are reduced, but there is no sense in it.
FractalNet uses a recursive architecture that has not yet been tested on ImageNet and is a derivative or more general version of ResNet.
We believe that the development of neural network architectures is of paramount importance for the development of deep learning. We highly recommend that you carefully read and think about all the works presented here.
You may ask why we have to spend so much time developing architectures, and why we don’t use data instead that will tell us what to use and how to combine the modules? Tempting opportunity, but work on this is still underway. Here are some initial results.
In addition, we only talked about computer vision architectures. In other areas, development is also underway, and it would be interesting to study the evolution in other areas.
If you are interested in comparing neural networks and computational performance, see our recent work .
Algorithms of deep neural networks today have gained great popularity, which is largely ensured by the well thought-out architecture. Let's look at the history of their development over the past few years. If you are interested in a deeper analysis, refer to this work .
Comparison of popular architectures for Top-1 one-crop accuracy and the number of operations required for one straight pass. Read more here .
LeNet5
In 1994, one of the first convolutional neural networks was developed, which marked the beginning of deep learning. This pioneering work of Yan Lekun (Yann LeCun) after many successful iterations since 1988 has received the name LeNet5 !
')
The architecture of LeNet5 has become fundamental for deep learning, especially in terms of the distribution of image properties throughout the entire picture. Convolutions with trained parameters made it possible with the help of several parameters to efficiently extract the same properties from different places. In those years there were still no video cards capable of speeding up the learning process, and even the central processors were slow. Therefore, the key advantage of the architecture was the ability to save the parameters and results of calculations, in contrast to the use of each pixel as separate input data for a large multilayered neural network. In LeNet5, in the first layer, pixels are not used, because the images are highly correlated spatially, so using separate pixels as input properties will not allow you to take advantage of these correlations.
LeNet5 features:
- A convolutional neural network using a sequence of three layers: convolution layers (convolution), grouping layers (pooling) and nonlinearity layers (non-linearity) -> since the publication of Lekun’s work, this is probably one of the main features of in-depth training applied to images.
- Uses convolution to extract spatial properties.
- A subsample using spatial averaging of maps.
- Nonlinearity in the form of a hyperbolic tangent or sigmoid.
- The final classifier in the form of a multilayered neural network (MLP).
- A sparse connectivity matrix between the layers reduces the amount of computation.
This neural network formed the basis of many subsequent architectures and inspired many researchers.
Development
From 1998 to 2010, the neural networks were in a state of incubation. Most people did not notice their growing capabilities, although many developers gradually honed the algorithms. Due to the flourishing of mobile phone cameras and the cheapening of digital cameras, more and more training data became available to us. At the same time, computing capabilities grew, processors became more powerful, and video cards became the main computing tool. All these processes allowed the development of neural networks, albeit rather slowly. Interest in the tasks that could be solved using neural networks increased, and finally the situation became obvious ...
Dan Ciresan Net
In 2010, Dan Kireshan (Dan Claudiu Ciresan) and Jörgen Schmidhuber published one of the first descriptions of the implementation of GPU-neural networks . Their work contained a direct and reverse implementation of a 9-layer neural network on the NVIDIA GTX 280 .
AlexNet
In 2012, Alexey Krizhevsky published AlexNet , an in-depth and extended version of LeNet, which won by a large margin in the difficult competition ImageNet.
In AlexNet, the results of LeNet calculations are scaled to a much larger neural network, which is able to study much more complex objects and their hierarchies. Features of this solution:
- Use of linear rectification units (ReLU) as non-linearities.
- Using the drop technique to selectively ignore individual neurons during training, thus avoiding overtraining of the model.
- Overlap max pooling, which avoids the effects of averaging average pooling.
- Use the NVIDIA GTX 580 to speed learning.
By that time, the number of cores in the video cards had greatly increased, which made it possible to reduce the training time by about 10 times, and as a result, it became possible to use much larger datasets and pictures.
The success of AlexNet launched a small revolution, convolutional neural networks turned into a workhorse of deep learning - this term henceforth meant "large neural networks capable of solving useful tasks."
Overfeat
In December 2013, NYU Laboratory Yana Lekuna published a description of Overfeat , a variety of AlexNet. The article also described the bounding boxes, and subsequently many other works on this subject were published. We believe that it is better to learn how to segment objects, and not to use artificial bounding boxes.
VGG
In Oxford-developed VGG networks, for each convolutional layer, 3x3 filters were first used, and they also combined these layers in a sequence of convolutions.
This is contrary to the principles in LeNet, according to which large bundles were used to extract the same image properties. Instead of the 9x9 and 11x11 filters used in AlexNet, much smaller filters began to be used, dangerously close to the 1x1 convolutions, which LeNet authors tried to avoid, at least in the first layers of the network. But the great advantage of VGG was the discovery that several 3x3 bundles combined into a sequence could emulate larger receptive fields, for example, 5x5 or 7x7. These ideas will later be used in the Inception and ResNet architectures.
VGG networks use multiple 3x3 convolutional layers to represent complex properties. Note blocks 3, 4, and 5 in VGG-E: 256 × 256 and 512 × 512 3 × 3 filter sequences are used to extract more complex properties and combine them. This is tantamount to large convolutional classifiers 512x512 with three layers! This gives us a huge amount of parameters and excellent learning abilities. But it was difficult to learn such networks, it was necessary to break them up into smaller ones, adding layers one by one. The reason was the lack of effective ways to regularize models or some methods of restricting a large search space, which is supported by many parameters.
VGG in many layers use a large number of properties, so the training required a large computational cost . You can reduce the load by reducing the number of properties, as is done in the bottleneck layers of the Inception architecture.
Network-in-network
The network-in-network (NiN) architecture is based on a simple idea: using 1x1 bundles to increase the combinatorial properties of the convolutional layers.
In NiN, spatial MLP layers are applied after each convolution in order to better combine the properties before feeding to the next layer. It may seem that the use of 1x1 bundles is contrary to the original LeNet principles, but in fact it allows you to combine properties better than just stuffing more convolutional layers. This approach differs from using bare pixels as input to the next layer. In this case, 1x1 convolutions are used for spatial combination of properties after convolution within property maps, so much fewer parameters can be used that are common to all pixels of these properties!
MLPs can greatly enhance the efficiency of individual convolutional layers by combining them into more complex groups. This idea was later used in other architectures, such as ResNet, Inception, and their variants.
GoogLeNet and Inception
Google's Christian Szegedy has bothered to reduce the amount of computation in deep neural networks, and as a result, he created GoogLeNet, the first Inception architecture .
By the fall of 2014, deep learning models have become very useful in categorizing the contents of images and frames from video. Many skeptics have recognized the benefits of deep learning and neural networks, and Internet giants, including Google, have been greatly interested in deploying efficient and large networks on their server capacities.
Christian was looking for ways to reduce the computational load in neural networks, achieving the highest performance (for example, in ImageNet). Or keeping the amount of calculations, but still at the same time improving performance.
As a result, the team created the Inception module:
At first glance, this is a parallel combination of convolutional filters 1x1, 3x3 and 5x5. But the highlight was the use of 1x1 convolutional blocks (NiN) to reduce the number of properties before serving in the "expensive" parallel blocks. Usually this part is called a bottleneck, it is described in more detail in the next chapter.
In GoogLeNet, a stem without Inception modules is used as the initial layer, and also uses an average pooling and softmax classifier similar to NiN. This classifier performs very few operations compared to AlexNet and VGG. It also helped create a very efficient neural network architecture .
Bottleneck layer
This layer reduces the number of properties (and hence the operations) in each layer, so that the speed of obtaining the result can be kept at a high level. Before transferring data to “expensive” convolutional modules, the number of properties decreases, say, 4 times. This greatly reduces the amount of computation, which made the architecture popular.
Let's figure it out. Suppose we have 256 properties at the input and 256 at the output, and let the Inception-layer only perform 3x3 convolutions. We get 256x256x3x3 convolutions (589 000 multiply operations with accumulation, that is, MAC operations). This may go beyond our computational rate requirements, say that a layer was processed in 0.5 milliseconds on Google Server. Then reduce the number of properties for coagulation to 64 (256/4). In this case, we first execute the convolution 1x1 256 -> 64, then another 64 convolutions in all Inception branches, and then again apply the convolution 1x1 of 64 -> 256 properties. Number of operations:
- 256 × 64 × 1 × 1 = 16 000
- 64 × 64 × 3 × 3 = 36 000
- 64 × 256 × 1 × 1 = 16,000
A total of about 70,000, reduced the number of operations almost 10 times! But at the same time, we did not lose generalization in this layer. Bottleneck layers showed superior performance on dataset ImageNet, and were used in later architectures such as ResNet. The reason for their success is that the input properties are correlated, which means you can get rid of redundancy by correctly combining the properties with 1x1 convolutions. And after coagulation with a smaller number of properties, it is possible on the next layer to expand them again into a meaningful combination.
Inception V3 (and V2)
Christian and his team have been very effective researchers. In February 2015, the architecture of Batch-normalized Inception was introduced as the second version of Inception . Batch normalization (batch-normalization) calculates the mean and standard deviation of all property distribution maps in the output layer, and normalizes their responses with these values. This corresponds to the "bleaching" of the data, that is, the responses of all neural maps lie in the same range and with zero mean. This approach facilitates learning, because the subsequent layer does not have to remember the offsets of the input data and can only search for the best combinations of properties.
In December 2015, a new version of Inception modules and the corresponding architecture was released . The author’s article explains the original GoogLeNet architecture better, there is much more detail about the decisions made. Key ideas:
- Maximizing the flow of information in the network due to the careful balance between its depth and width. Before each pooling, property maps increase.
- With increasing depth, the number of properties or layer width also increases systematically.
- The width of each layer increases to increase the combination of properties before the next layer.
- As far as possible, only 3x3 convolutions are used. Considering that 5x5 and 7x7 filters can be decomposed with a few 3x3
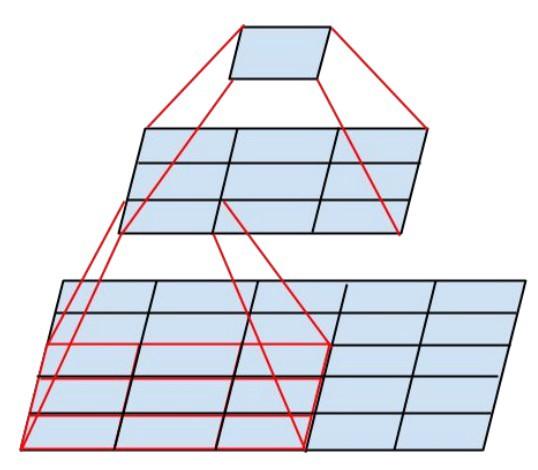
The new Inception module looks like this: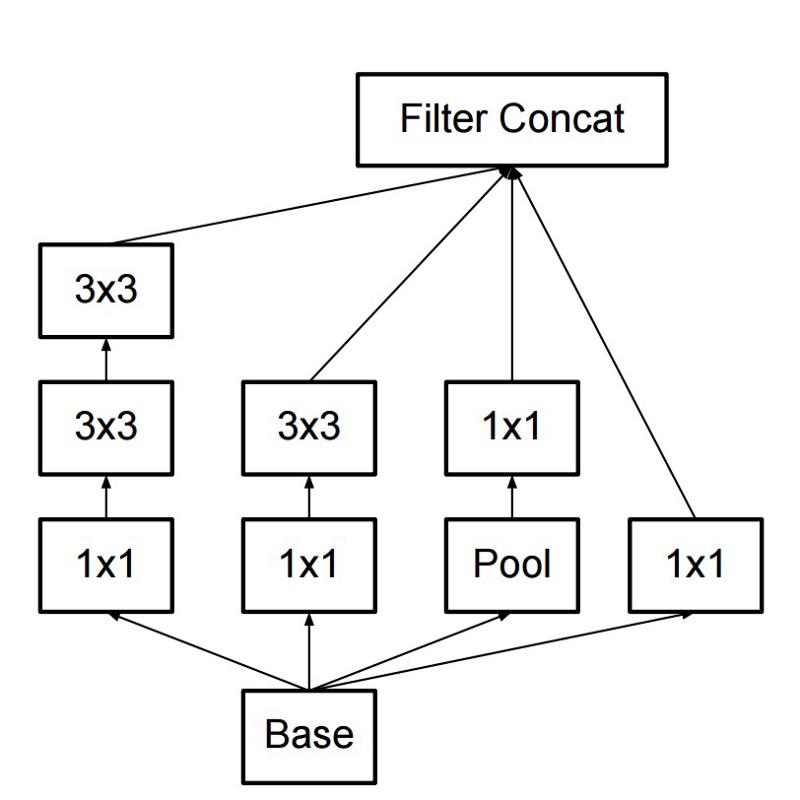
- Filters can also be decomposed using smoothed bundles into more complex modules:

- Inception modules can use pooling to reduce data size during Inception calculations. This is similar to performing a convolution with strides in parallel with a simple pooling layer:

As the final classifier, Inception uses a softmax pooling layer.
ResNet
In December 2015, at about the same time as the architecture of Inception v3 was presented, a revolution occurred - published ResNet . It contains simple ideas: we submit the output of two successful convolutional layers And bypass the input data for the next layer!
Such ideas have already been proposed, for example, here . But in this case, the authors bypass the TWO layers and apply the approach on a large scale. Bypassing one layer does not give much benefit, and bypassing two is a key finding. This can be considered as a small classifier, as a network-in-a-network!
It was also the first ever example of learning a network of several hundred, even thousands of layers.
In multi-layer ResNet, a bottleneck layer was used, similar to that used in Inception:
This layer reduces the number of properties in each layer, first using a 1x1 convolution with a lower output (usually a quarter of the input), then a 3x3 layer comes, and then again a 1x1 convolution into more properties. As in the case of Inception-modules, it saves computational resources, while maintaining a wealth of combinations of properties. Compare with more complex and less obvious stem in Inception V3 and V4.
ResNet uses a softmax for the final classifier in ResNet.
Every day there is more information about the ResNet architecture:
- It can be considered as a system of simultaneously parallel and serial modules: in many modules the inout-signal comes in parallel, and the output signals of each module are connected in series.
- ResNet can be considered as several ensembles of parallel or sequential modules .
- It turned out that ResNet usually operates with blocks of relatively small depth of 20-30 layers, working in parallel, rather than driving them consistently along the entire length of the network.
- Since the output signal goes back and serves as an input, as is done in the RNN, ResNet can be considered an improved plausible model of the cerebral cortex .
Inception V4
Once again, Christian and his team distinguished themselves by releasing a new version of Inception .
The inception module following the stem is the same as in Inception V3:
In this case, the Inception module is combined with the ResNet module:
This architecture turned out, for my taste, more complicated, less elegant, and also filled with imperfect heuristic solutions. It is difficult to understand why the authors made these or other decisions, and it is just as difficult to give them some kind of assessment.
Therefore, the prize for a clean and simple neural network, easy to understand and modify, goes to ResNet.
SqueezeNet
SqueezeNet published recently. This is a remake of a new way of many concepts from ResNet and Inception. The authors have demonstrated that improving the architecture can reduce the size of networks and the number of parameters without complex compression algorithms.
Eet
All the features of recent architectures are combined into a very efficient and compact network that uses very few parameters and computing power, but gives excellent results. The architecture was called ENet , it was developed by Adam Paszke. For example, we used it for very accurate marking of objects on the screen and parsing scenes. A few examples of how Enet works . These videos are not related to the training dataset .
Here you can find the technical details of ENet. This is a network based on the encoder and decoder. The encoder is built on the usual CNN scheme for categorization, and the decoder is an upsampling netowrk network designed for segmentation by distributing categories back to the original size image. For segmentation of images only neural networks were used, no other algorithms.
As you can see, ENet has the highest specific accuracy compared to all other neural networks.
ENet was designed to use as few resources as possible from the very beginning. As a result, the encoder and decoder together occupy only 0.7 MB with an accuracy of fp16. And with this tiny size, ENet is not inferior or superior to other purely neural network solutions in terms of segmentation accuracy.
Module analysis
Published a systematic assessment of CNN-modules. It turned out that it is profitable:
- Use ELU non-linearity without batch normalization (batchnorm) or ReLU with normalization.
- Apply a learned transformation of the RGB color space.
- Use a linear learning rate decay policy.
- Use the sum of the average and maximum pooling layer.
- Use a mini package of 128 or 256. If this is too much for your video card, reduce the learning rate in proportion to the size of the package.
- Use fully connected layers as convolutional and average forecasts for issuing the final solution.
- If you increase the size of the training dataset, make sure that you have not reached the plateau in training. Clean data is more important than size.
- If you cannot increase the size of the input image, reduce the stride in subsequent layers, the effect will be about the same.
- If your network has a complex and highly optimized architecture, as in GoogLeNet, then modify it with care.
Xception
Xception introduced to the Inception module a simpler and more elegant architecture that is no less efficient than ResNet and Inception V4.
This is what the Xception module looks like:
This network will appeal to anyone thanks to the simplicity and elegance of its architecture:
It contains 36 convolutions, and this is similar to ResNet-34. At the same time, the model and code are simple, as in ResNet, and much nicer than in Inception V4.
The Torch7 implementation of this network is available here , and the implementation on Keras / TF is here.
Curiously, the authors of the recent Xception architecture were also inspired by our work on separable convolution filters .
MobileNets
New architecture M obileNets was released in April 2017. To reduce the number of parameters, it uses detachable convolutions, the same as in Xception. Even in the paper it is argued that the authors were able to greatly reduce the number of parameters: approximately twice in the case of FaceNet. Full model architecture:
We tested this network in a real problem and found that it runs disproportionately slowly on the package of 1 (batch of 1) on the Titan Xp video card. Compare the duration of the output for one image:
- resnet18: 0.002871
- alexnet: 0,001003
- vgg16: 0.001698
- squeezenet: 0.002725
- mobilenet: 0.033251
This is not a quick job! The number of parameters and the size of the network on the disk are reduced, but there is no sense in it.
Other noteworthy architectures
FractalNet uses a recursive architecture that has not yet been tested on ImageNet and is a derivative or more general version of ResNet.
Future
We believe that the development of neural network architectures is of paramount importance for the development of deep learning. We highly recommend that you carefully read and think about all the works presented here.
You may ask why we have to spend so much time developing architectures, and why we don’t use data instead that will tell us what to use and how to combine the modules? Tempting opportunity, but work on this is still underway. Here are some initial results.
In addition, we only talked about computer vision architectures. In other areas, development is also underway, and it would be interesting to study the evolution in other areas.
If you are interested in comparing neural networks and computational performance, see our recent work .
Source: https://habr.com/ru/post/430524/
All Articles