The landscape of cloud machine translation services. Lecture in Yandex
This is the last report from the sixth Hyperbaton , which we will publish on Habré. Grigory Sapunov from Intento shared his approach to assessing the quality of cloud machine translation services, spoke about the results of the assessment and the main differences between the available services.
- My name is Grigory Sapunov, I will tell you about the landscape of cloud machine translation services. We have been measuring this landscape for over a year now, it is very dynamic and interesting.

I will tell you what it is, why it is useful to understand what is happening there, about the available solutions, which are quite a lot, about comparing stock models, pre-trained machine translation models, about customized models that began to appear actively in the last year, and I will give my recommendations on the choice of models.
')
Machine translation has become a very useful tool that helps automate many different tasks. It replaces the person only in some topics, but at least can greatly reduce costs. If you need to translate a lot of product descriptions or reviews on a large web service, then the person here is simply not able to cope with the large flow, and machine translation is really good. And there are already many ready-made solutions on the market. These are some kind of pre-trained models, they are often called stock models, and models with domain adaptation, which has been strongly developed lately.
At the same time, it is quite difficult and expensive to create your own machine translation solution. Modern technology of machine translation, neural network machine translation, requires a lot of things to take off inside. You need talents to do this, you need a lot of data to train it, and time to do it. In addition, neural network machine translation requires much more machine resources than previous versions of machine translations such as SMT or rule-based.
At the same time, machine translation, which is available in the cloud, is very different. And the right choice of machine translation allows you to greatly simplify life, save time, money and eventually solve your problem or not. The variation in quality, reference-based metrics, which we measure, can be four times.

At the same time, prices may vary by a factor of 200. This is a completely abnormal situation. Services of more or less the same quality can differ by 200 times. This is an easy way for you to save or spend extra money.
At the same time, services significantly differ in product characteristics. This may be format support, file support, the presence of a batch mode, or the lack of it, this is the maximum amount of text that a service can translate at one time, and much more. And all this needs to be understood when choosing a service. If you choose the wrong service, you will either have to redo it or you will not get the quality you would like to receive. In the end, it comes down to the fact that you quickly bring something to the market, save money, provide the best quality to your product. Or do not provide.

Compare these services to understand exactly what suits you, long and expensive. If you do this yourself, you must integrate with all cloud machine translation services, write these integrations, enter into contracts, first arrange a separate billing, integrate with everyone. Next, drive through all these services some of your data, evaluate. It is prohibitively expensive. The budget of such a project may exceed the budget of the main project for which you are doing this.
So this is an important topic, but it’s difficult to study independently, and in this place we are good at helping to understand what’s what.

There is a range of technologies on the market. Almost all services have moved to a neural network machine translation or some kind of hybrid. There are still a number of statistical machine translators on the market.
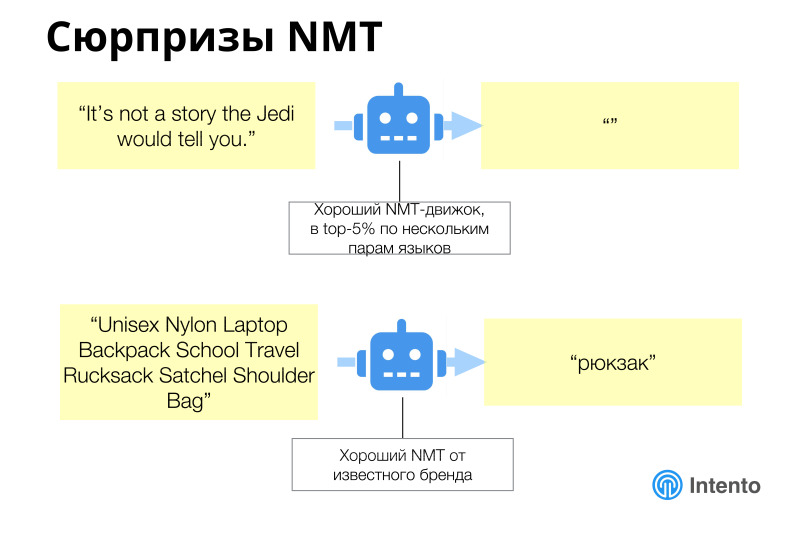
Each has its own characteristics. NMT seems to be a more modern good technology, but there are also some subtleties.
In general, neural network machine translation works better than previous models, but you also need to follow it, there are completely unexpected results. As a true Yoda, he can be silent, give an empty answer to some string, and you need to be able to catch it and understand that he behaves this way on your data. Or a great example from e-commerce, when a large description of the goods was sent to machine translation, and he just said that this was a backpack and that's it. And it was the stable behavior of this machine service, which is good and works fine on general data, news data. But in this particular area, e-commerce works poorly. And you need to understand this, you need to drive off all these services on your data in order to choose the one that fits your data best. This is not a service that will work better on news or something else. This is the one that should work better on your particular case. This must be understood in each case.

There are many levels of customization. Zero level - its absence. There are stock models pre-trained, these are all those that are deployed in the cloud now by different providers. There is an option with fully customized models on their cases, when you, conditionally, place an order in some company that deals with machine translation, it is a model for you from your data from scratch. But it is long, expensive, requires large shells. There is a large provider who will charge you $ 5,000 for such an experiment, the numbers of this order. Things that are expensive to try. And this does not guarantee you anything. You can train a model, but it will be worse than what is available on the market, and money is thrown to the wind. These are the two extreme options. Either stock model, or customized on your body.
There are intermediate cases. There are glossaries, a very good thing that helps to improve current machine translation models. And there is a domain adaptation, which is now actively developing, some transfer learning, whatever hides behind these words, which allows you to train a certain general model or even a special model to train on your data, and the quality of such a model will be better than just a general model. This is a good technology, it works, now in the stage of active development. Watch her, I will tell you about her later.

There is another important dimension to raise or use the cloud. There is a popular delusion in this place, people still think that cloud machine translation services, if you use them, will take your data and train their models on them. This is not true for the last year or two. All major services have refused this, they have explicitly stated in terms of service that we do not use your data to train our models. It is important. This removes a bunch of barriers to the adaptation of cloud machine translation. Now you can safely use these services and be sure that the service will not use your data to train your models, and it will not become your competitor with time. It's safe.
This is the first advantage of clouds compared to what it was two years ago.
The second advantage, if you deploy a neural network transfer inside you, you need to raise a rather heavy infrastructure with graphic accelerators to train all these neural networks. And even after training for inference, you still need to use high-performance graphics cards to make it work. It turns out expensive. The cost of owning such a decision is really big. And a company that is not going to professionally provide API to the market does not need to do this, you need to take the cloud service ready and use it. In this place you have savings in money, in time, and there is a guarantee that your data will not be used for service needs.
About the comparison.

We have been dealing with this topic for a long time, we have been regularly measuring quality for a year and a half. We have chosen automatic reference metrics, they allow you to do this massively, and get some confidence intervals. We more or less know at what amount of data the quality metrics settle down, and we can make an adequate choice between different services. But we must remember that the metrics are automatic and human metrics complement each other. Automatic metrics are good for conducting a preliminary analysis, choosing places that people should especially pay attention to, and then linguists or domain experts look at these translation options and choose what suits you.

I’ll tell you about the systems on the market, how we all analyzed them, how they compare with prices, and I’ll tell you about our analysis results, what is important here in quality, and what is beyond quality also important when choosing a service.

First of all, there are already a large number of cloud services of machine translation, we considered only those in which there are pre-trained models that can be taken and started to use, and they have a public API.
There are still some number of services that do not have a public API or they are deployed inside, we do not consider them in our study. But even among these services there are already a large number of them, we measure and evaluate 19 such services. Practice shows that the average person knows several market leaders, but does not know about the rest. And they are, and they are good places.

We took the popularity of languages on the web and divided them into four groups. The most popular, more than 2% of sites, less popular and even less. There are four groups of languages by which we analyze further, and from all this we focus on the first group, the most popular languages, and a little bit on the second.
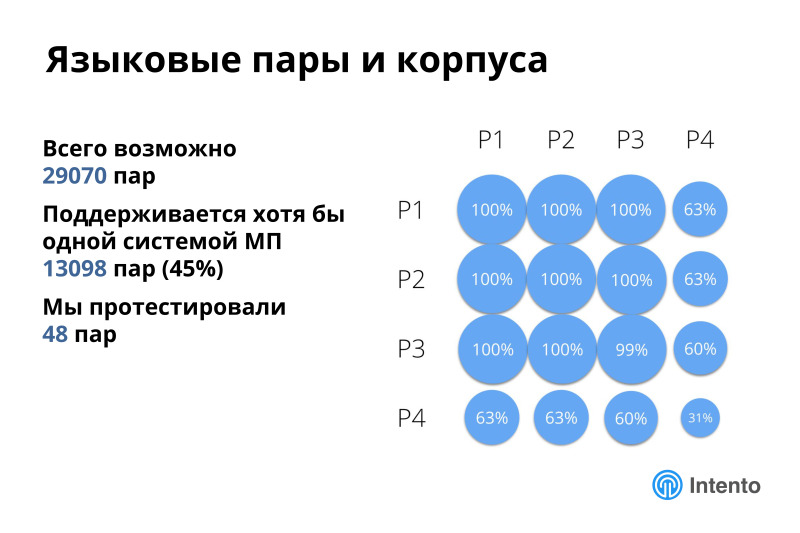
Support within the first three groups is almost 100%. If you need a language that is not super exotic, then you will get it from the cloud. And if you need an exotic pair, it may turn out that one of the languages is not supported by any machine cloud translation service. But even with all the restrictions, about half of all possible pairs are supported. That's not bad.

From all this, we tested 48 pairs, compiled such a matrix, selected primarily English and all the languages of the first group, partially the languages within the first group, and a little English and the languages of the second group. This more or less covers typical usage scenarios, but many other interesting things remain outside. We estimated these pairs, measured them and tell you what is happening there. Full report is on the link, it is free, we update it regularly, I will agitate you to use it.
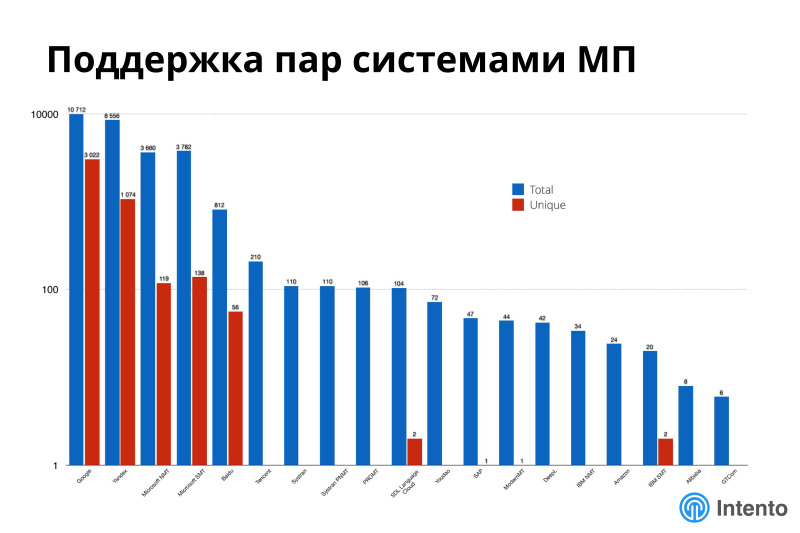
No numbers and axes are visible on this graph, but this is about the support of different languages by different machine translation systems. On the X axis, different machine translation systems, on the Y axis in a logarithmic scale, the number of supported pairs in general and unique. For this picture red is unique, blue is everything. It can be seen that if you have a very exotic combination of languages, it may turn out that you need to use seven different providers because of the uniqueness, because only one of them supports a very specific pair that you need.

To assess the quality, we chose news corps, general domain corpus. This does not guarantee that the situation in your specific data from another area will be the same, most likely not the same, but this is a good demonstration of how to approach this research in general, how to choose the right service for you. I will show on the example of news areas. It is easily transferred to any other area of yours.

We chose the hLEPOR metric, which is about the same as BLEU, but according to our intuitive feeling, it gives a better impression of how the services relate to each other. For simplicity, consider that the metric from 0 to 1, 1 is full compliance with a certain reference translation, 0 is a complete discrepancy. hLEPOR better gives an intuitive feeling, which means a difference of 10 units compared to BLEU. You can read about the metric separately, everything is described in the research methodology. This is a normal metric, a proxy metric, not perfect, but it conveys the essence well.

The difference in prices is enormous. We made a matrix, for what price you can get a translation of 1 million characters. You can download and see the difference is colossal, from $ 5 to $ 1000 per million characters. Choosing the wrong service simply raises your costs tremendously, or choosing the right one can help save a lot in this place. The market is opaque, you need to understand what is worth and where is what quality. Keep this matrix in your head. It is difficult to compare all services, at a price, prices are often not very transparent, the policy is not very clear, there are some grades. This is all difficult, this table helps to make a decision.
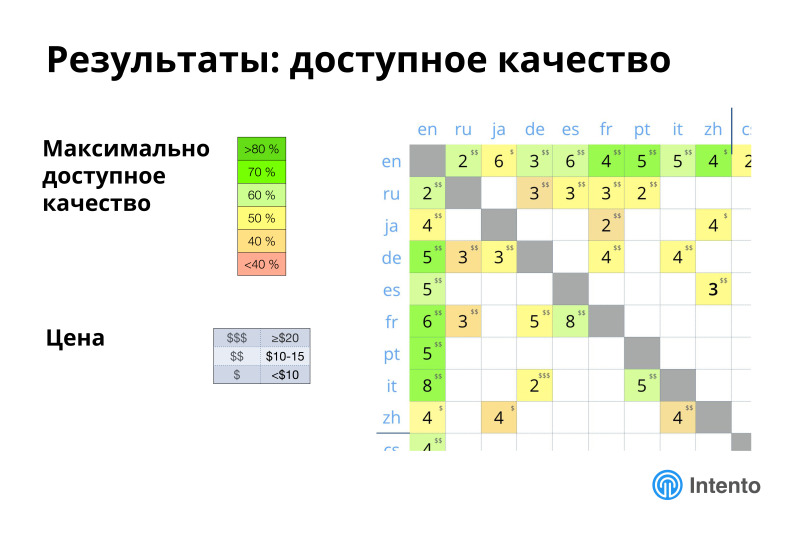
We have brought the results of our analysis into such funny pictures. This picture shows what the maximum available quality is for those pairs that we measured, the greener - the higher quality is available, what is the competition in these pairs, is there anything to choose from, conditionally, about 8 providers provide this The maximum available quality, somewhere only 2, and there is another dollar icon, this is about the price for which you get the maximum quality. The spread is large, somewhere cheap you can get acceptable quality, somewhere it is not very acceptable and expensive, various combinations are possible. The landscape is complex, there is no one super player who is everywhere better in everything, cheap, good and so on. Everywhere there is a choice, and everywhere it needs to be done rationally.

Here we have drawn the best systems for these language pairs. It can be seen that there is no one better system, different services are better on different pairs in this particular area - news, in other areas the situation will change. Somewhere Google is good, somewhere Deepl is good, this is a fresh European translator, about which very few people know, this is a small company that successfully fights against Google and defeats it, really good quality. On the Russian-English pair, Yandex is stably good. Amazon recently appeared, connected the Russian language and others, and it is also not bad. This is a fresh change. A year ago, much of this was not, there were fewer leaders. Now the situation is very dynamic.
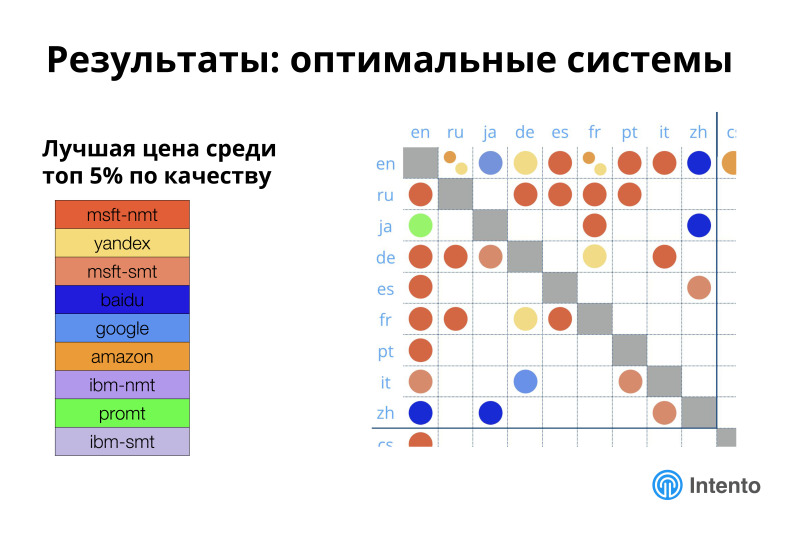
Knowing the best system is not always important. It is often important to know the optimal system. If you look at the top 5% of systems for this quality, then among this top 5% is the cheapest, giving it a good quality. In this place, the situation is significantly different. Google leaves this comparison, Microsoft rises very much, Yandex becomes bigger, Amazon crawls out even more, more exotic providers appear. The situation becomes different.
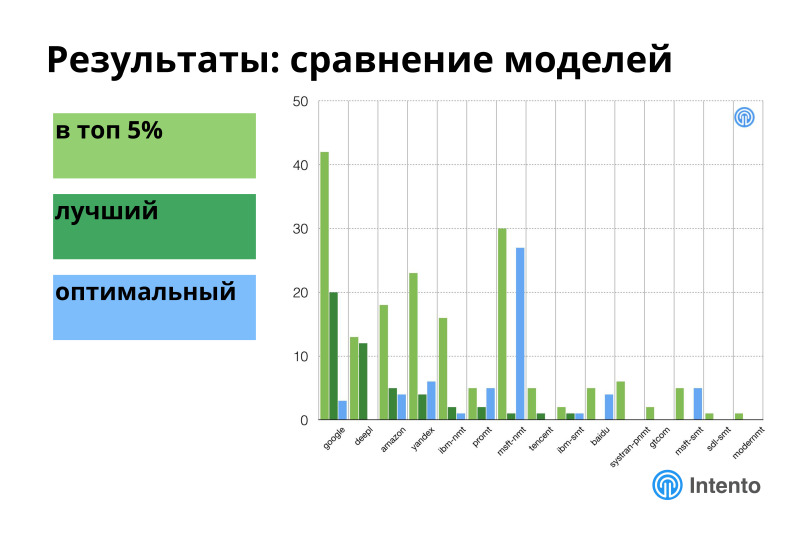
If you look at all the providers of machine translation, horizontally - different providers, vertically - how often the provider is in one of these tops, then almost every one of them is in the top 5% sooner or later. The best of them for any specific pairs measured are 7 providers, the optimal ones are also 7. This means that if you have a set of languages into which you need to translate and you want to provide maximum or optimum quality, you need one provider not enough, you need to connect the portfolio of these providers, and then you will have the maximum quality, maximum efficiency for the money and so on. No one player is the best. If you have complex tasks, you need a lot of different pairs, you have a direct way to using different providers, it is better than using someone.
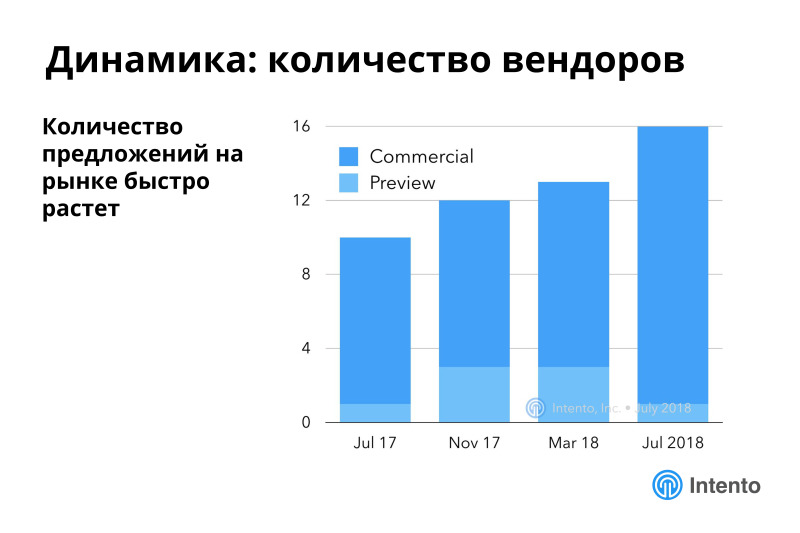
The market is very dynamic, the number of offers is growing rapidly. We began to measure in the beginning of the 17th year, a fresh benchmark was published in July. The number of available services is growing, some of them are still in the preview, they do not have a public pricing, they are in some kind of alpha or beta that you can use, but the conditions are not very clear.
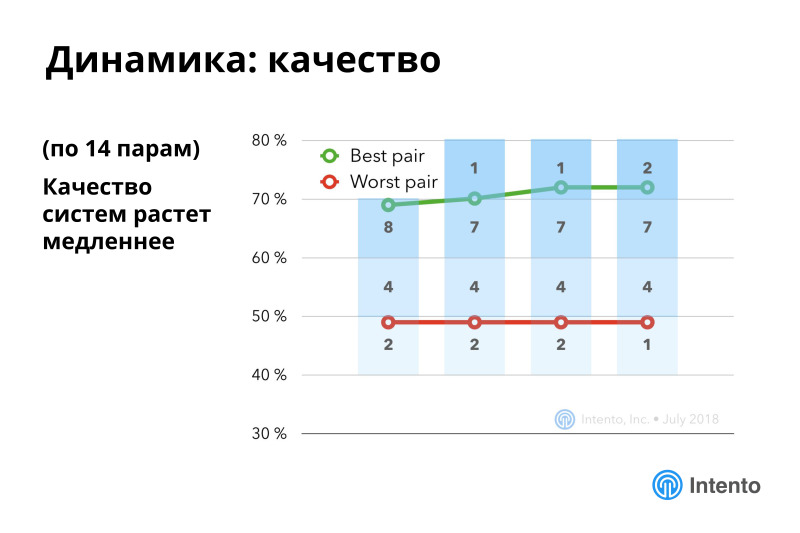
Quality grows slower, but also grows. The main interest occurs within specific language pairs.
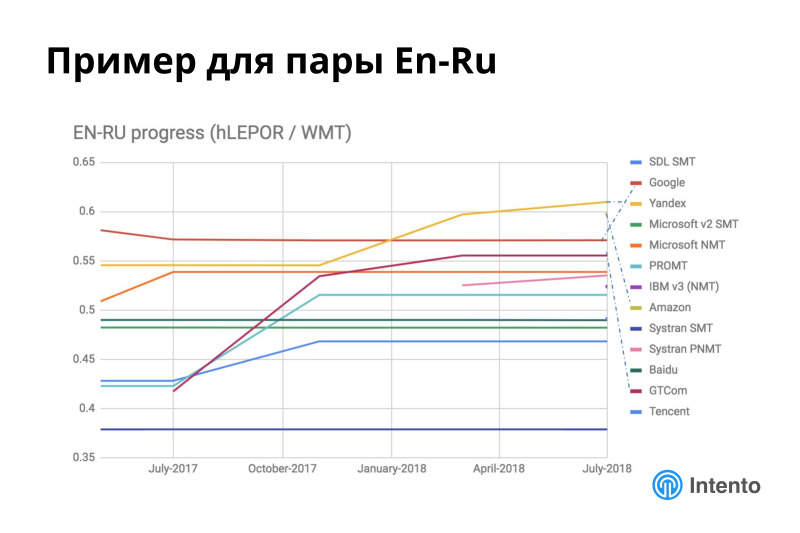
For example, the situation within the English-Russian language pair is very dynamic. Yandex over the past six months has greatly improved its quality. Amazon appeared, it is presented to the right with one dot, it also goes close behind Yandex. The GTCom provider, which almost no one knows, is a good pumper, it’s a Chinese provider, it translates well from Chinese into English and Russian, and English - Russian also handles well.
A similar picture occurs more or less in all language pairs. Everywhere something is changing, new players are constantly appearing, their quality is changing, models are being retrained. You see, there are stable providers, the quality of which does not change. In this case, the stable ones are rather dead, because there are other unstable ones, the quality of which is more or less improving. This is a good story, they are constantly improving.
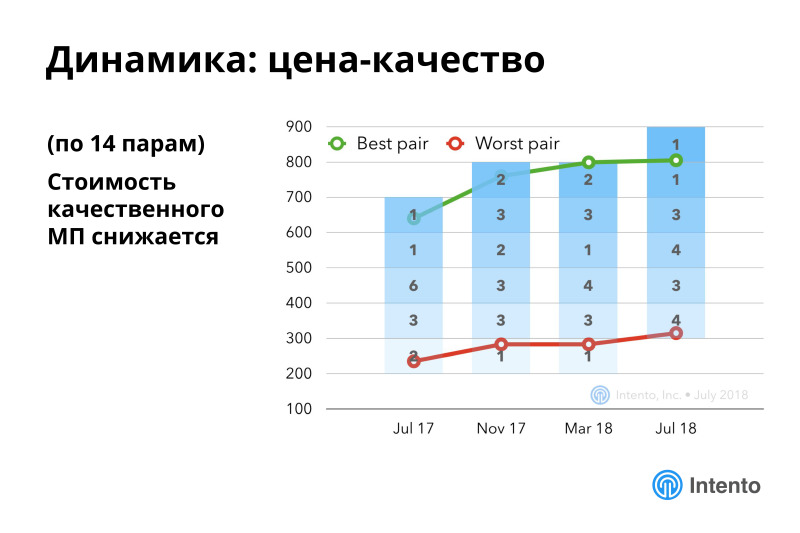
If you count a more complex metric about price-quality, then there are stable improvements. This means that the cost of high-quality machine translation is constantly decreasing, with every month, every year, you get more and more high-quality machine translation for less money. It's good.

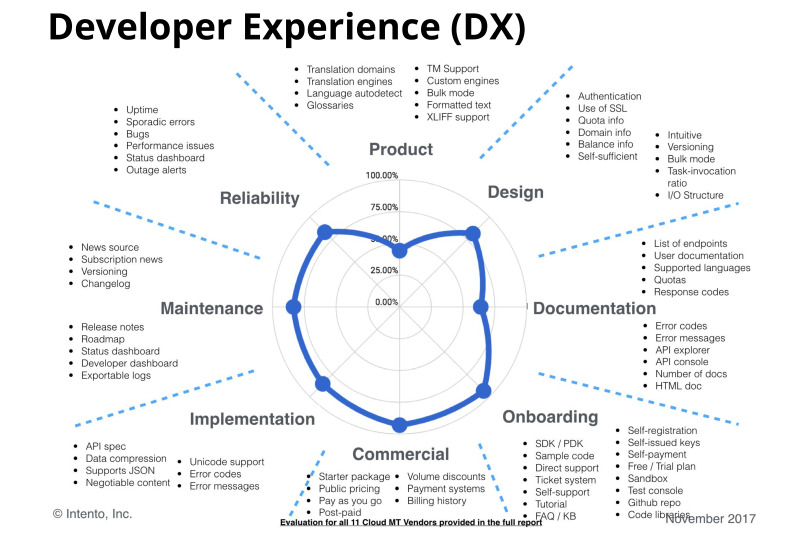
In addition to prices and quality, there is a huge layer of issues that are also important when choosing a particular provider. These are all sorts of product features, html support, xml, support for tricky and not so formats, bulk mode, autodetection of the language - a popular topic, support for glossaries, customization, service reliability. And what we call developer happiness, then you can read what we mean by reference.
This is to create machine disaster. DX , , , HTTP, , API, , , . , API, . , , API , - . .
, . , , SDK, , , . . .
, , API NDA. . . , - .
, . , , , . - , , .
— , . , , .

- . , , . , - , Google, Microsoft, IBM, - , , , .

? , , , . — , . 10 . 1 . 2 . , 2 . . 50 .
hLEPOR, , , , , , . , . — . , . , , - , . , . , , , . .
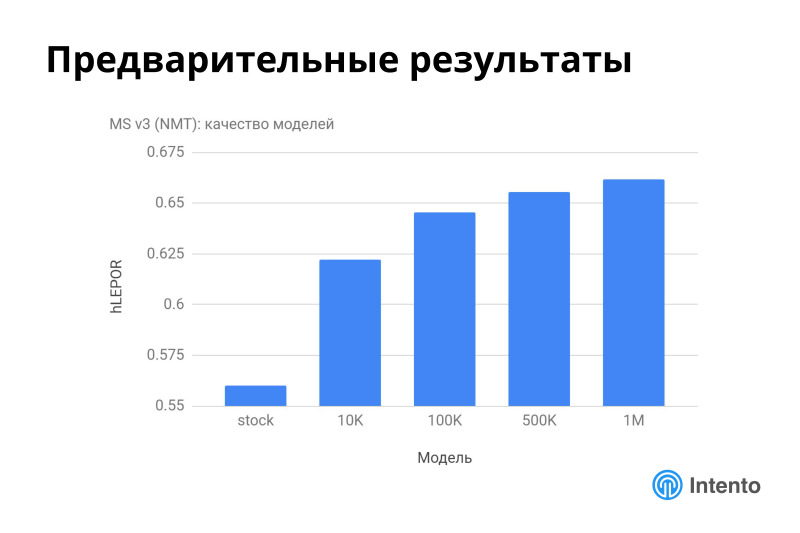
, . Microsoft, 3 API. , , , Microsoft . . , , . , , 10 . Microsoft . , . , , .
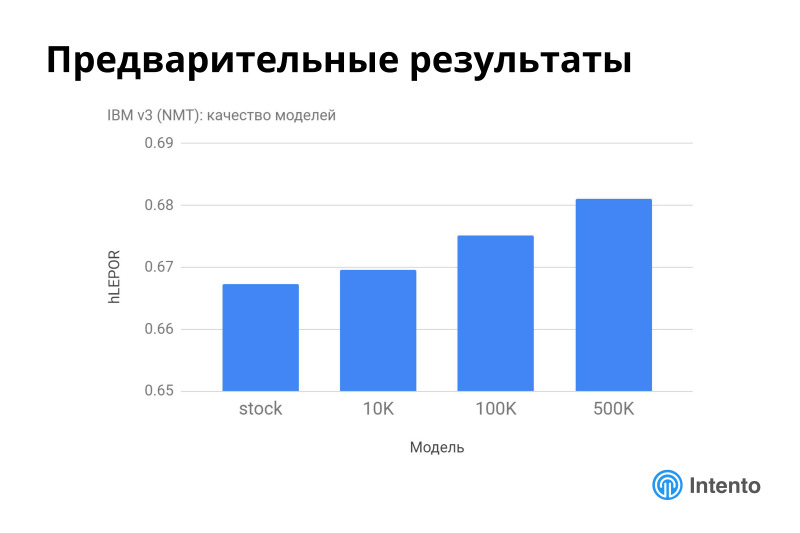
IBM, , . , . 2% — .
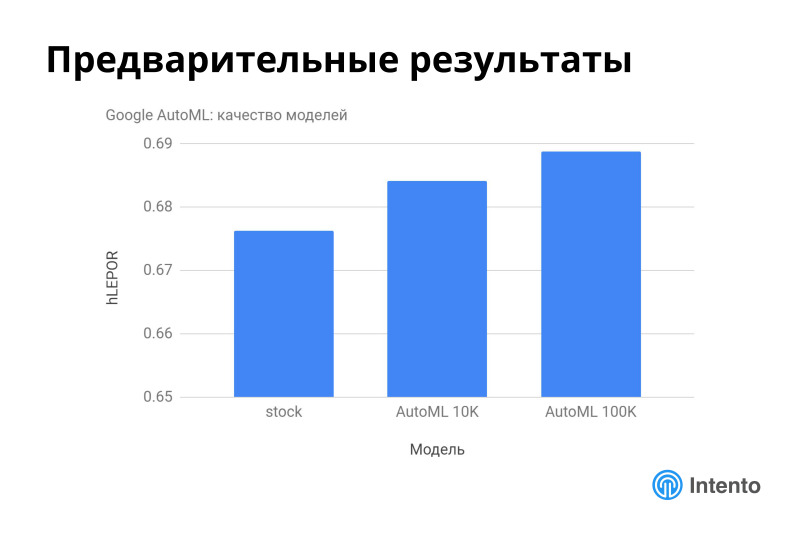
Google AutoML , , 10 100 . .
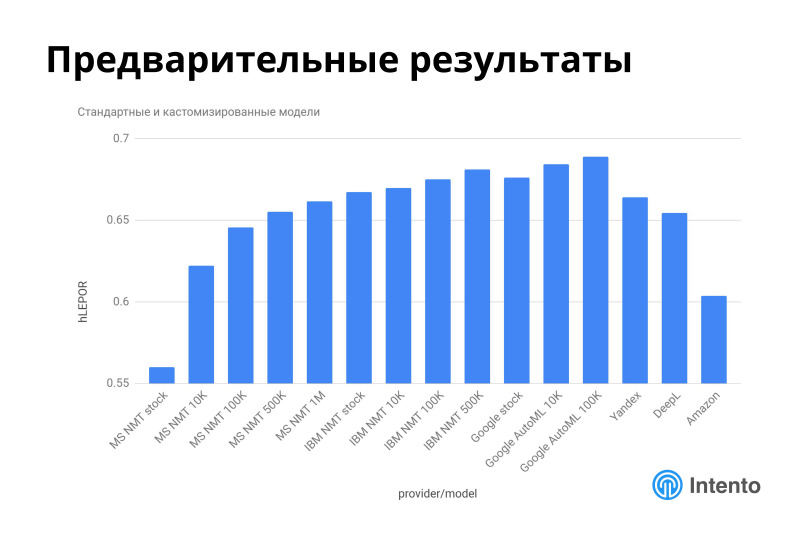
, Microsoft, Google, - — , Deepl, Amazon, Google, Microsoft. , . ? , - , - . , Google Deepl, , , . . , . .
, , , , . . , , . , , . . , . , .
?

. . , , .
, . , - . It happens. , , , -. , , , . , , , - , , . — .
- , , . -, . , , . , , , . . — , , .

? . , . , , , . , .
, , . API . , , . SDK NodeJS, .NET, CLI. , API, . . , , . , , , — .
web tools . , , , API. . , , .
, . -, , . . , . . , , , , . , , , , . Deepl? , Google .
In addition, remember that now, having your own unique data, you can train your models in cloud services and use them. The quality is likely to be much better than the default models, and certainly better than the wrong model. Thank.
- My name is Grigory Sapunov, I will tell you about the landscape of cloud machine translation services. We have been measuring this landscape for over a year now, it is very dynamic and interesting.
I will tell you what it is, why it is useful to understand what is happening there, about the available solutions, which are quite a lot, about comparing stock models, pre-trained machine translation models, about customized models that began to appear actively in the last year, and I will give my recommendations on the choice of models.
')
Machine translation has become a very useful tool that helps automate many different tasks. It replaces the person only in some topics, but at least can greatly reduce costs. If you need to translate a lot of product descriptions or reviews on a large web service, then the person here is simply not able to cope with the large flow, and machine translation is really good. And there are already many ready-made solutions on the market. These are some kind of pre-trained models, they are often called stock models, and models with domain adaptation, which has been strongly developed lately.
At the same time, it is quite difficult and expensive to create your own machine translation solution. Modern technology of machine translation, neural network machine translation, requires a lot of things to take off inside. You need talents to do this, you need a lot of data to train it, and time to do it. In addition, neural network machine translation requires much more machine resources than previous versions of machine translations such as SMT or rule-based.
At the same time, machine translation, which is available in the cloud, is very different. And the right choice of machine translation allows you to greatly simplify life, save time, money and eventually solve your problem or not. The variation in quality, reference-based metrics, which we measure, can be four times.
At the same time, prices may vary by a factor of 200. This is a completely abnormal situation. Services of more or less the same quality can differ by 200 times. This is an easy way for you to save or spend extra money.
At the same time, services significantly differ in product characteristics. This may be format support, file support, the presence of a batch mode, or the lack of it, this is the maximum amount of text that a service can translate at one time, and much more. And all this needs to be understood when choosing a service. If you choose the wrong service, you will either have to redo it or you will not get the quality you would like to receive. In the end, it comes down to the fact that you quickly bring something to the market, save money, provide the best quality to your product. Or do not provide.
Compare these services to understand exactly what suits you, long and expensive. If you do this yourself, you must integrate with all cloud machine translation services, write these integrations, enter into contracts, first arrange a separate billing, integrate with everyone. Next, drive through all these services some of your data, evaluate. It is prohibitively expensive. The budget of such a project may exceed the budget of the main project for which you are doing this.
So this is an important topic, but it’s difficult to study independently, and in this place we are good at helping to understand what’s what.
There is a range of technologies on the market. Almost all services have moved to a neural network machine translation or some kind of hybrid. There are still a number of statistical machine translators on the market.
Each has its own characteristics. NMT seems to be a more modern good technology, but there are also some subtleties.
In general, neural network machine translation works better than previous models, but you also need to follow it, there are completely unexpected results. As a true Yoda, he can be silent, give an empty answer to some string, and you need to be able to catch it and understand that he behaves this way on your data. Or a great example from e-commerce, when a large description of the goods was sent to machine translation, and he just said that this was a backpack and that's it. And it was the stable behavior of this machine service, which is good and works fine on general data, news data. But in this particular area, e-commerce works poorly. And you need to understand this, you need to drive off all these services on your data in order to choose the one that fits your data best. This is not a service that will work better on news or something else. This is the one that should work better on your particular case. This must be understood in each case.
There are many levels of customization. Zero level - its absence. There are stock models pre-trained, these are all those that are deployed in the cloud now by different providers. There is an option with fully customized models on their cases, when you, conditionally, place an order in some company that deals with machine translation, it is a model for you from your data from scratch. But it is long, expensive, requires large shells. There is a large provider who will charge you $ 5,000 for such an experiment, the numbers of this order. Things that are expensive to try. And this does not guarantee you anything. You can train a model, but it will be worse than what is available on the market, and money is thrown to the wind. These are the two extreme options. Either stock model, or customized on your body.
There are intermediate cases. There are glossaries, a very good thing that helps to improve current machine translation models. And there is a domain adaptation, which is now actively developing, some transfer learning, whatever hides behind these words, which allows you to train a certain general model or even a special model to train on your data, and the quality of such a model will be better than just a general model. This is a good technology, it works, now in the stage of active development. Watch her, I will tell you about her later.
There is another important dimension to raise or use the cloud. There is a popular delusion in this place, people still think that cloud machine translation services, if you use them, will take your data and train their models on them. This is not true for the last year or two. All major services have refused this, they have explicitly stated in terms of service that we do not use your data to train our models. It is important. This removes a bunch of barriers to the adaptation of cloud machine translation. Now you can safely use these services and be sure that the service will not use your data to train your models, and it will not become your competitor with time. It's safe.
This is the first advantage of clouds compared to what it was two years ago.
The second advantage, if you deploy a neural network transfer inside you, you need to raise a rather heavy infrastructure with graphic accelerators to train all these neural networks. And even after training for inference, you still need to use high-performance graphics cards to make it work. It turns out expensive. The cost of owning such a decision is really big. And a company that is not going to professionally provide API to the market does not need to do this, you need to take the cloud service ready and use it. In this place you have savings in money, in time, and there is a guarantee that your data will not be used for service needs.
About the comparison.
We have been dealing with this topic for a long time, we have been regularly measuring quality for a year and a half. We have chosen automatic reference metrics, they allow you to do this massively, and get some confidence intervals. We more or less know at what amount of data the quality metrics settle down, and we can make an adequate choice between different services. But we must remember that the metrics are automatic and human metrics complement each other. Automatic metrics are good for conducting a preliminary analysis, choosing places that people should especially pay attention to, and then linguists or domain experts look at these translation options and choose what suits you.
I’ll tell you about the systems on the market, how we all analyzed them, how they compare with prices, and I’ll tell you about our analysis results, what is important here in quality, and what is beyond quality also important when choosing a service.
First of all, there are already a large number of cloud services of machine translation, we considered only those in which there are pre-trained models that can be taken and started to use, and they have a public API.
There are still some number of services that do not have a public API or they are deployed inside, we do not consider them in our study. But even among these services there are already a large number of them, we measure and evaluate 19 such services. Practice shows that the average person knows several market leaders, but does not know about the rest. And they are, and they are good places.
We took the popularity of languages on the web and divided them into four groups. The most popular, more than 2% of sites, less popular and even less. There are four groups of languages by which we analyze further, and from all this we focus on the first group, the most popular languages, and a little bit on the second.
Support within the first three groups is almost 100%. If you need a language that is not super exotic, then you will get it from the cloud. And if you need an exotic pair, it may turn out that one of the languages is not supported by any machine cloud translation service. But even with all the restrictions, about half of all possible pairs are supported. That's not bad.
From all this, we tested 48 pairs, compiled such a matrix, selected primarily English and all the languages of the first group, partially the languages within the first group, and a little English and the languages of the second group. This more or less covers typical usage scenarios, but many other interesting things remain outside. We estimated these pairs, measured them and tell you what is happening there. Full report is on the link, it is free, we update it regularly, I will agitate you to use it.
No numbers and axes are visible on this graph, but this is about the support of different languages by different machine translation systems. On the X axis, different machine translation systems, on the Y axis in a logarithmic scale, the number of supported pairs in general and unique. For this picture red is unique, blue is everything. It can be seen that if you have a very exotic combination of languages, it may turn out that you need to use seven different providers because of the uniqueness, because only one of them supports a very specific pair that you need.
To assess the quality, we chose news corps, general domain corpus. This does not guarantee that the situation in your specific data from another area will be the same, most likely not the same, but this is a good demonstration of how to approach this research in general, how to choose the right service for you. I will show on the example of news areas. It is easily transferred to any other area of yours.
We chose the hLEPOR metric, which is about the same as BLEU, but according to our intuitive feeling, it gives a better impression of how the services relate to each other. For simplicity, consider that the metric from 0 to 1, 1 is full compliance with a certain reference translation, 0 is a complete discrepancy. hLEPOR better gives an intuitive feeling, which means a difference of 10 units compared to BLEU. You can read about the metric separately, everything is described in the research methodology. This is a normal metric, a proxy metric, not perfect, but it conveys the essence well.
The difference in prices is enormous. We made a matrix, for what price you can get a translation of 1 million characters. You can download and see the difference is colossal, from $ 5 to $ 1000 per million characters. Choosing the wrong service simply raises your costs tremendously, or choosing the right one can help save a lot in this place. The market is opaque, you need to understand what is worth and where is what quality. Keep this matrix in your head. It is difficult to compare all services, at a price, prices are often not very transparent, the policy is not very clear, there are some grades. This is all difficult, this table helps to make a decision.
We have brought the results of our analysis into such funny pictures. This picture shows what the maximum available quality is for those pairs that we measured, the greener - the higher quality is available, what is the competition in these pairs, is there anything to choose from, conditionally, about 8 providers provide this The maximum available quality, somewhere only 2, and there is another dollar icon, this is about the price for which you get the maximum quality. The spread is large, somewhere cheap you can get acceptable quality, somewhere it is not very acceptable and expensive, various combinations are possible. The landscape is complex, there is no one super player who is everywhere better in everything, cheap, good and so on. Everywhere there is a choice, and everywhere it needs to be done rationally.
Here we have drawn the best systems for these language pairs. It can be seen that there is no one better system, different services are better on different pairs in this particular area - news, in other areas the situation will change. Somewhere Google is good, somewhere Deepl is good, this is a fresh European translator, about which very few people know, this is a small company that successfully fights against Google and defeats it, really good quality. On the Russian-English pair, Yandex is stably good. Amazon recently appeared, connected the Russian language and others, and it is also not bad. This is a fresh change. A year ago, much of this was not, there were fewer leaders. Now the situation is very dynamic.
Knowing the best system is not always important. It is often important to know the optimal system. If you look at the top 5% of systems for this quality, then among this top 5% is the cheapest, giving it a good quality. In this place, the situation is significantly different. Google leaves this comparison, Microsoft rises very much, Yandex becomes bigger, Amazon crawls out even more, more exotic providers appear. The situation becomes different.
If you look at all the providers of machine translation, horizontally - different providers, vertically - how often the provider is in one of these tops, then almost every one of them is in the top 5% sooner or later. The best of them for any specific pairs measured are 7 providers, the optimal ones are also 7. This means that if you have a set of languages into which you need to translate and you want to provide maximum or optimum quality, you need one provider not enough, you need to connect the portfolio of these providers, and then you will have the maximum quality, maximum efficiency for the money and so on. No one player is the best. If you have complex tasks, you need a lot of different pairs, you have a direct way to using different providers, it is better than using someone.
The market is very dynamic, the number of offers is growing rapidly. We began to measure in the beginning of the 17th year, a fresh benchmark was published in July. The number of available services is growing, some of them are still in the preview, they do not have a public pricing, they are in some kind of alpha or beta that you can use, but the conditions are not very clear.
Quality grows slower, but also grows. The main interest occurs within specific language pairs.
For example, the situation within the English-Russian language pair is very dynamic. Yandex over the past six months has greatly improved its quality. Amazon appeared, it is presented to the right with one dot, it also goes close behind Yandex. The GTCom provider, which almost no one knows, is a good pumper, it’s a Chinese provider, it translates well from Chinese into English and Russian, and English - Russian also handles well.
A similar picture occurs more or less in all language pairs. Everywhere something is changing, new players are constantly appearing, their quality is changing, models are being retrained. You see, there are stable providers, the quality of which does not change. In this case, the stable ones are rather dead, because there are other unstable ones, the quality of which is more or less improving. This is a good story, they are constantly improving.
If you count a more complex metric about price-quality, then there are stable improvements. This means that the cost of high-quality machine translation is constantly decreasing, with every month, every year, you get more and more high-quality machine translation for less money. It's good.
Link from the slide
In addition to prices and quality, there is a huge layer of issues that are also important when choosing a particular provider. These are all sorts of product features, html support, xml, support for tricky and not so formats, bulk mode, autodetection of the language - a popular topic, support for glossaries, customization, service reliability. And what we call developer happiness, then you can read what we mean by reference.
This is to create machine disaster. DX , , , HTTP, , API, , , . , API, . , , API , - . .
, . , , SDK, , , . . .
, , API NDA. . . , - .
, . , , , . - , , .
— , . , , .
- . , , . , - , Google, Microsoft, IBM, - , , , .
? , , , . — , . 10 . 1 . 2 . , 2 . . 50 .
hLEPOR, , , , , , . , . — . , . , , - , . , . , , , . .
, . Microsoft, 3 API. , , , Microsoft . . , , . , , 10 . Microsoft . , . , , .
IBM, , . , . 2% — .
Google AutoML , , 10 100 . .
, Microsoft, Google, - — , Deepl, Amazon, Google, Microsoft. , . ? , - , - . , Google Deepl, , , . . , . .
, , , , . . , , . , , . . , . , .
?
. . , , .
, . , - . It happens. , , , -. , , , . , , , - , , . — .
- , , . -, . , , . , , , . . — , , .
: , , , ,
? . , . , , , . , .
, , . API . , , . SDK NodeJS, .NET, CLI. , API, . . , , . , , , — .
web tools . , , , API. . , , .
, . -, , . . , . . , , , , . , , , , . Deepl? , Google .
In addition, remember that now, having your own unique data, you can train your models in cloud services and use them. The quality is likely to be much better than the default models, and certainly better than the wrong model. Thank.
Source: https://habr.com/ru/post/430266/
All Articles