Using ClickHouse in VK, or Why we wrote KittenHouse
 At the beginning of the year, we decided to learn how to store and read VK debug logs more efficiently than before. Debug logs are, for example, video conversion logs (mainly the output of the ffmpeg command and a list of steps for pre-processing files), which sometimes we need only 2-3 months after processing the problem file.
At the beginning of the year, we decided to learn how to store and read VK debug logs more efficiently than before. Debug logs are, for example, video conversion logs (mainly the output of the ffmpeg command and a list of steps for pre-processing files), which sometimes we need only 2-3 months after processing the problem file.At that time, we had 2 ways of storing and processing logs - our own logs engine and rsyslog, which we used in parallel. We began to consider other options and realized that ClickHouse from Yandex is quite suitable for us - we decided to implement it.
In this article I will talk about how we started using ClickHouse VKontakte, which rake we came to, and what KittenHouse and LightHouse are. Both products are available in open-source links at the end of the article.
The task of collecting logs
System requirements:
')
- Storage of hundreds of terabytes of logs.
- Storage for months or (rarely) for years.
- High write speed.
- High reading speed (reading rarely).
- Index support.
- Support for long lines (> 4 Kb).
- Easy operation.
- Compact storage.
- Ability to insert with tens of thousands of servers (UDP will be a plus).
Possible solutions
Let's briefly list the options that we considered, and their disadvantages:
Logs engine
Our samopisny microservice for logs.
- Able to give only the last N lines that are placed in RAM.
- Not very compact storage (no transparent compression).
Hadoop
- Not all formats have indexes.
- The reading speed could be higher (depending on the format).
- Difficulty setting.
- There is no possibility of insertion from tens of thousands of servers (need Kafka or analogs).
Rsyslog + files
- No indexes.
- Slow read speed (normal grep / zgrep).
- Architecturally, the lines are not supported> 4 Kb, even less via UDP (1.5 Kb).
± Compact storage achieved by logrotate on krone
We used rsyslog as a backup for long-term storage, but the long lines were cut off, so it can hardly be called ideal.
LSD + files
- No indexes.The difference from rsyslog in our case is that LSD supports long lines, but for insertion from tens of thousands of servers, significant improvements are needed in the internal protocol, although this can be done.
- Slow read speed (normal grep / zgrep).
- Not really designed for insertion from tens of thousands of servers.
± Compact storage is achieved by logrotate on krone.
Elasticsearch
- Problems with operation.ELK stack is almost the industry standard for storing logs. In our experience, everything is fine with the speed of reading, but there are problems with writing, for example, during the merging of indices.
- Unstable recording.
- No UDP.
- Bad compression.
ElasticSearch is primarily designed for full-text search and relatively frequent read requests. It is more important for us to have a stable record and the ability to read our data more or less quickly, and by exact coincidence. The index at ElasticSearch is sharpened for full-text search, and the disk space occupied is quite large compared to the gzip of the original content.
Clickhouse
- No UDP.
By and large, the only thing that did not suit us at ClickHouse was the lack of communication over UDP. In fact, only rsyslog had one of the listed options, but rsyslog did not support long lines.
According to the rest of the criteria, ClickHouse approached us, and we decided to use it, and solve transport problems in the process.
Why do you need KittenHouse
As you probably know, VKontakte works on PHP / KPHP, with “engines” (microservices) on C / C ++ and a little on Go. PHP does not have a “state” concept between requests, except perhaps shared memory and open connections.
Since we have tens of thousands of servers from which we want to be able to send logs to ClickHouse, it would be expensive to keep connections from each PHP worker open (each server can have 100+ workers). Therefore, we need some kind of proxy between ClickHouse and PHP. We called this proxy KittenHouse.
KittenHouse, v1
First, we decided to try as simple a scheme as possible in order to understand whether our approach will work or not. If Kafka comes to mind when solving this problem, then you are not alone. However, we did not want to use additional intermediate servers - in this case, it was easy to rest against the performance of these servers, and not of ClickHouse itself. In addition, we collected logs and we needed a predictable and small delay in the insertion of data. The scheme is as follows:

On each of the servers, our local proxy (kittenhouse) is set up, and each instance holds strictly one HTTP connection with the required ClickHouse server. Insertion is carried out in buffer tables, as it is often not recommended to insert in MergeTree.
Features KittenHouse, v1
The first version of KittenHouse was pretty little skilled, but for tests this was enough:
- Communication through our RPC (TL Scheme).
- Maintain 1 TCP / IP connection per server.
- Buffering in memory by default, with a limited buffer size (the rest is discarded).
- The ability to write to disk, in this case there is a guarantee of delivery (at least once).
- The insertion interval is once every 2 seconds.
First problems
We encountered the first problem when the ClickHouse server was turned off for several hours and then turned back on. Below you can see the load average on the server after it has “risen”:
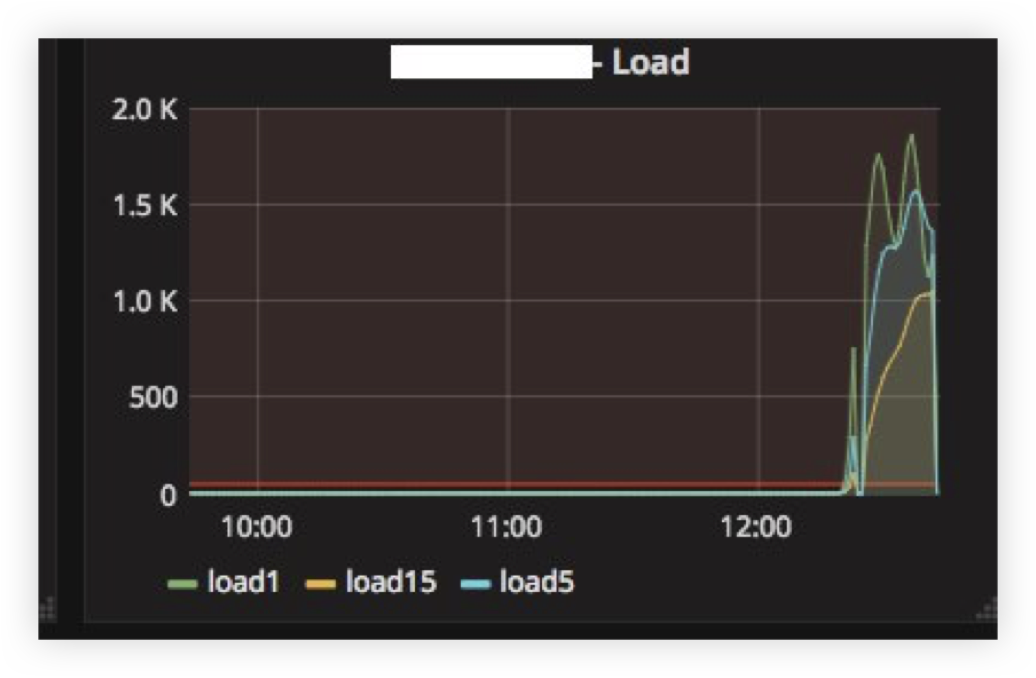
The reason is quite simple: ClickHouse has a threading connection model, so when you try to make an INSERT from a thousand nodes at the same time, there is a very strong competition for CPU resources and the server barely responded. However, all the data was eventually inserted and nothing fell.
To solve this problem, we put nginx in front of ClickHouse and, in general, it helped.
Further development
In the course of operation, we encountered some more problems, mainly not with ClickHouse, but with our way of using it. Here is another rake that we stepped on:
A large number of “chunks” in Buffer tables leads to frequent buffer drops in MergeTree
In our case, there were 16 pieces of buffer and a reset interval every 2 seconds, and tables of 20 pieces, which gave up to 160 inserts per second. This periodically had a very bad effect on insert performance — many background merges appeared and disk utilization reached 80% and more.
Solution: increased the default buffer reset interval, reduced the number of pieces to 2.
Nginx gives 502 when upstream connections end
This in itself is not a problem, but in combination with frequent flushing of the buffer, this gave a fairly high background of 502 errors when trying to insert into any of the tables, as well as when trying to perform a SELECT.
Solution: they wrote their reverse proxy using the fasthttp library, which groups the insert into tables and very economically consumes the connections. It also distinguishes between SELECT and INSERT and has separate connection pools for insertion and reading.
Began to run out of memory with intensive insertion
The fasthttp library has its advantages and disadvantages. One of the drawbacks is that the request and response are completely buffered in memory before giving control to the request handler. In our case, this resulted in the fact that if the insertion into ClickHouse “did not have time”, then the buffers started to grow and eventually all the memory on the server ended, which led to the killing of the reverse proxy by OOM. Colleagues have drawn demotivator:

Solution: patching fasthttp to support body streaming of a POST request was not an easy task, so we decided to use Hijack () connections and upgrade the connection to our protocol if a request came with the HTTP method KITTEN. Because the server must answer MEOW in response, if it understands this protocol, the whole scheme is called the KITTEN / MEOW protocol.
We read only from 50 random connections at the same time, therefore, thanks to TCP / IP, the rest of the clients “wait” and we do not spend memory on buffers until the turn has reached the corresponding clients. This reduced memory consumption by at least 20 times, and we had no more such problems.
ALTER tables can go long if there are long queries.
In ClickHouse, non-blocking ALTER is in the sense that it does not interfere with both SELECT and INSERT queries. But ALTER cannot begin until the queries to this table have been completed, sent before ALTER.
If you have on the server a background of “long” queries to some tables, then you may encounter a situation that ALTER on this table will not have time to execute in a default timeout of 60 seconds. But this does not mean that ALTER will not pass: it will be executed as soon as those SELECT queries have finished executing.
This means that you don’t know at what time ALTER actually occurred, and you don’t have the ability to automatically recreate the Buffer tables so that their schema is always the same. This can lead to problems when pasting.


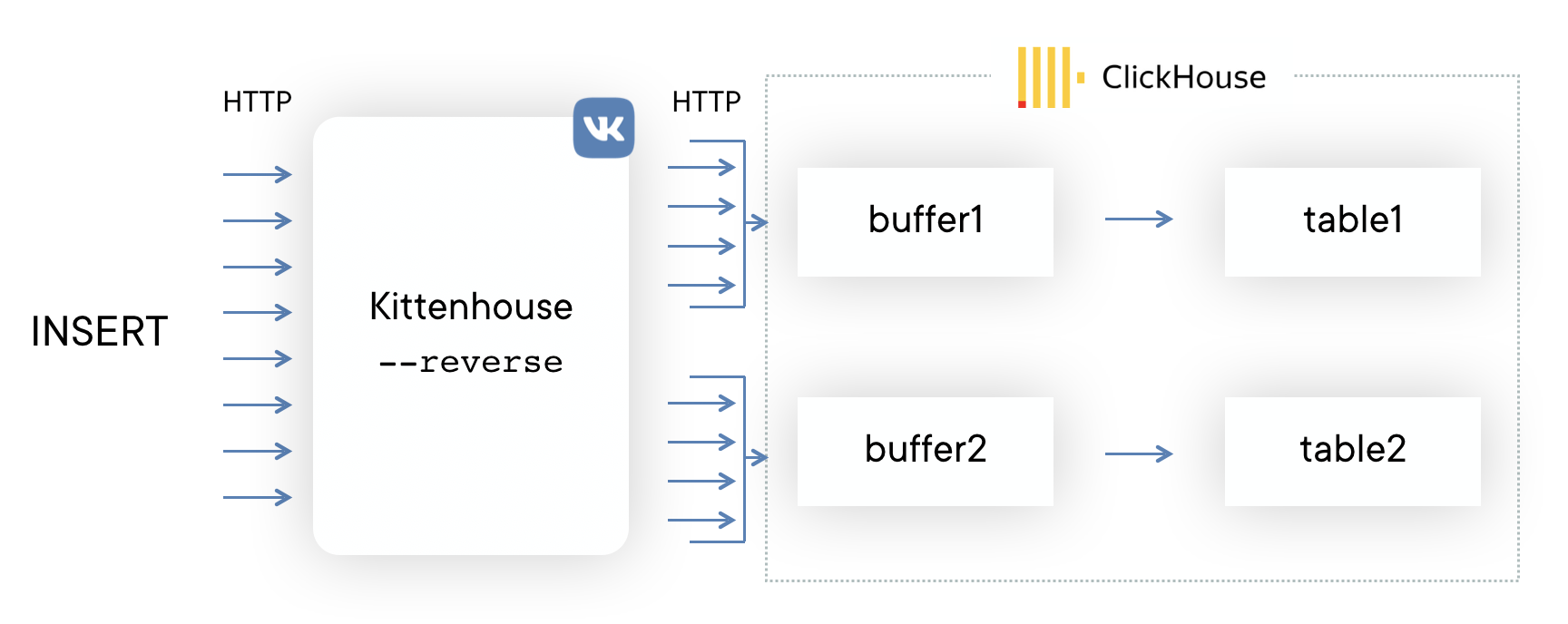
Solution: We plan to eventually completely abandon the use of buffer tables. In general, buffer tables have a scope, we still use them and do not have huge problems. But now we have finally reached the moment when it is easier to implement the functionality of buffer tables on the reverse proxy side than to continue to put up with their shortcomings. The approximate scheme will look like this (the dotted line shows the asynchrony of the ACK on the INSERT).

Reading data
Let's say we figured out the insert. How to read these logs from ClickHouse? Unfortunately, we didn’t find any convenient and easy-to-use tools for reading raw data (without graphing and other things) from ClickHouse, so we wrote our solution - LightHouse. Its capabilities are rather modest:
- Quick view of the contents of the tables.
- Filtering, sorting.
- Editing SQL query.
- View table structure.
- Shows the approximate number of lines and disk space.
However, LightHouse is fast and can do what we need. Here are a couple of screenshots:
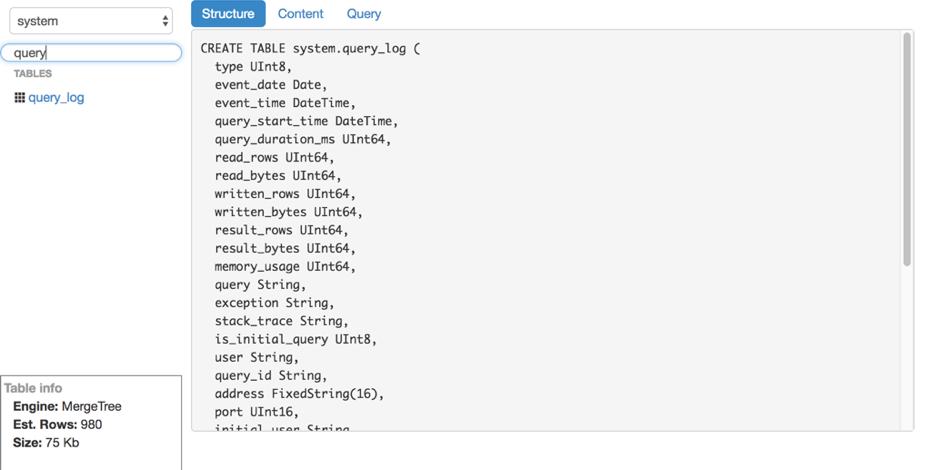
View table structure
Content Filtering

results
ClickHouse is practically the only open-source database that has taken root on VKontakte. We are pleased with the speed of its work and are ready to put up with the shortcomings, which are discussed below.
Difficulties at work
Overall, ClickHouse is a very stable database and very fast. However, as with any product, especially so young, there are features in the work that need to be considered:
- Not all versions are equally stable: do not upgrade to a new version on the production, it is better to wait for several bugfix releases.
- For optimal performance, it is highly advisable to configure RAID and some other things according to the instructions. This was recently reported on highload .
- Replication does not have built-in speed limits and can cause significant degradation of server performance, if it is not limited by itself (but this is promised to be fixed).
- In Linux, there is an unpleasant feature of the virtual memory mechanism: if you actively write to the disk and data do not have time to be reset, at some point the server completely “goes to itself”, begins to actively reset page cache to disk and almost completely blocks the ClickHouse process. This sometimes happens with large merges, and this needs to be monitored, for example, periodically flushing the buffers themselves or doing sync.
Open source
KittenHouse and LightHouse are now available in open source in our github repository:
- KittenHouse: github.com/vkcom/kittenhouse
- LightHouse: github.com/vkcom/lighthouse
Thank!
Yuri Nasretdinov, developer in the backend-infrastructure section of VKontakte
Source: https://habr.com/ru/post/430168/
All Articles