O'Reilly's London Velocity Conference: Overview and Slides

Velocity is a conference dedicated to distributed systems. It is organized by O'Reilly, and it takes place three times a year: once in California, once in New York and once in Europe (and the city changes every year).
In 2018, the conference was in London from October 30 to November 2. The main office of Badoo is in the same place, so my colleagues and I had just two reasons to go to Velocity.
Her device turned out to be somewhat more complicated than the one I encountered at Russian conferences. In addition to the rather familiar two days of reports, there were two more days of training, which can be taken in full, in part or not at all. All together it turns into a serious quest for choosing the type of ticket you want.
In this review I will tell about those reports and master classes that I remember. I attach references to additional materials to some reports. Partly these are materials the authors referred to, and partly materials for further study that I found myself.
The general impression from the conference: the authors perform very well (and the keynote of the session is the whole show with the presentation of the speakers and their appearance on the stage to the music), but at the same time I came across few reports that would be profound from a technical point of view.
The most "hot" topic of this conference is Kubernetes , which is mentioned almost in every second report.
Work with social networks is very well built: in the official twitter account during the conference there were a lot of operational retweets with reports. This allowed us to see what was happening in other halls.
Master Classes
October 31 was the day when there were no reports, but six or eight master classes took place, three hours of pure time each, of which two had to be chosen.
PS In the original, they are called the tutorial, but it seems to me correct to translate them as a "master class."
Chaos Engineering Bootcamp
Host: Ana Medina , Engineer at Gremlin | Description
The workshop was dedicated to introducing chaos engineering. Ana spoke fluently about what it is, how useful it is, how it can be used, what software can help and how to start using it in the company.
In general, it was a good introduction for beginners, but I didn’t really like the practical part, which was the deployment of a demo web application in a cluster of several machines using Kubernetes and attaching monitoring from DataDog to it. The main problem was that we spent almost half the time of the master class on this and this was only needed in order to play around for 5-10 minutes with scripts that emulate various problems in the cluster and look at the changes in the graphs.
It seems to me that for the same effect it was enough to give access to a pre-configured DataDog and / or demonstrate it all from the scene, and this time to spend, for example, on a more detailed review and examples of using the same Chaos Monkey, about which it was just literally told a couple of phrases.


Interesting: at this conference, speakers often mentioned the term "blast radius", which I had not met before. They denoted the part of the system that turns out to be off when a specific problem occurs.
Additional materials:
- Chaos Engineering: The History, Principles, and Practice
- Chaos Monkey Guide for Engineers
- A repository with scripts for emulating problems in the system (the scripts were used in the master class and there are also links to the presentation from the same master class)
- Chaos Engineering Monitoring & Metrics Guide
- Planning Your Own Chaos Day
Building evolutionary infrastructure
Host: Kief Morris , infrastructure consultant and author of "Infrastructure as a code" | Description
The main theses of the master class can be reduced to two things:
- Systems change all the time, so it’s normal that the infrastructure also needs to change;
- Once the infrastructure is changing, it is necessary to ensure that it is simple and safe, and this can be achieved only by automation.
The main part of his story was devoted precisely to automating changes in infrastructure, possible solutions to this problem and testing changes. I am not an expert in this topic, but it seemed to me that he spoke very confidently and in detail (and very quickly).
The main point that I remember from this master class is the recommendation to make the most distinction between environments (production, steaming, etc.) from the code into environment variables. This will reduce the likelihood of errors in the infrastructure when changing environments and make it more testable.



Reports
November 1 and 2 were the days of reports. They were divided into two principal blocks: a series of three or four short keynote reports that went into one stream in the morning (and a large hall of two smaller ones was set up for them) and longer thematic reports in five streams that went the rest of the day . During the day there were several big pauses between the reports, when you could walk around the expo with the stands of the conference partners.
Evolution of Runtastic Backend
Simon Lasselsberger (Runtastic GmbH) | Description and slides
One of the few reports in which the author did not simply tell how something needs to be done, but showed the details of a specific project and what happened to it.
At the beginning, Runtastic had a common Percona Server database and a monolith with code serving mobile applications and the site. Then they began to write in Cassandra (I don’t remember for what reason exactly in it) a part of the data for which the key-value storage was enough. Gradually, the base was plump, and they added MongoDB, to which they began to write data from most services. Over time, they made a general level that serves requests from both the web and mobile applications (something like our support , as I understand it).
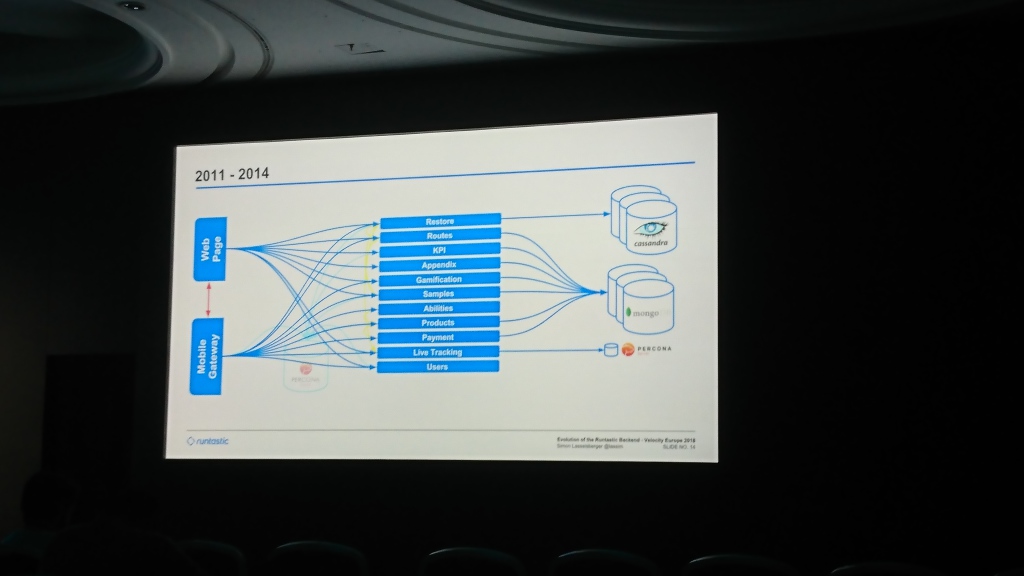
Most of the report was devoted to moving between data centers. At first they kept the server in Hetzner, which after some time was considered not stable enough and the data was migrated to T-Systems. A few years later they were faced with a shortage of space already there and moved again to Linz AG. The most interesting part here is data migration. They started copying data, which lasted several months. They could not wait so long, because they ran out of space and could not add it, so they made a fallback in the code that tried to read data from the old data center if it was not in the new one.
In the future, they plan to split the data into several separate data centers (Simon said several times that this is necessary for Russia and China) and to strictly separate the databases for individual services (the common pool is now used for all services).
A curious approach to the design of modules in the system, about which Simon casually mentioned: hexagonal architecture .
It is a program for users of programs and programs.
Alistair cockburn
Additional materials:
Monitoring custom metrics; or How I learned later
Maxime Petazzoni (SignalFx) | Description and Presentation
The story was devoted to collecting the metrics necessary for understanding the operation of the application. The main message was that the usual RED metrics (Rate, Errors, and Duration) are absolutely not enough, and besides them, you need to immediately collect others that will help you understand what is happening inside the application.
Thesis, the author proposed to collect counters and timers for some important actions in the system (and failures counters), build graphs and distribution histograms on them, define a meta-model for custom metrics (so that different metrics have the same set of required parameters and the same values are called the same everywhere).

Words to retell the details is hard enough, it will be easier to see the details and examples in the presentation, the link to which is on the report page on the conference website.
Additional materials:
How serverless changes the IT department
Paul Johnston (Roundabout Labs) | Description and Presentation
The author introduced himself as a CTO and environmentalist, and said that serverless is not a technological, but a business decision ("You pay nothing if it's unused"). Then he described the best practices for working with serverless, what competencies are needed to work with him and how it affects the choice of new employees and work with existing ones.

The key point of the "influence on the IT department" that I remembered was the shift of the necessary competencies from simply writing code to working with the infrastructure and its automation ("More" engineering "than" developing "). Everything else was pretty trite (you need to constantly code review, document the data streams and events available for use in the system, communicate more and learn quickly, but for some reason the author attributed them to the features of serverless.

Overall, the report seemed a bit ambiguous. Many things that the speaker was talking about can be attributed to any complex system that does not fit entirely in the head.
Additional materials:
- Serverless Best Practices - author's article c disclosing best practices
Don't panic! How to cope now
Euan Finlay (Financial Times) | Description and Presentation
A report on how to deal with production incidents if something goes wrong right now. The main theses were divided into parts by time.
Before the incident:
- delimit alerts for criticality - perhaps some may wait, and there is no need to urgently deal with them;
- Prepare a plan for incident handling beforehand and keep documentation up to date;
- conduct exercises - break something and see what happens (aka chaos engineering);
- get a single place where all information about changes and problems flows.
During the incident:
- it’s normal that you don’t know everything — involve other people if necessary;
- create a single place for communication between people working on solving the incident;
- Look for the most simple solution that will return the production to a working state, and do not try to completely solve the problem.
After the incident:
- Understand why the problem arose and what it taught you;
- It is important to write a report about this ("incident report");
- Determine what can be improved and plan specific actions.
In the end, Yuen told the funny story of the incident in the Financial Times, which arose from the fact that the production base (which was called prod ) had been modified by mistake instead of pre-production ( pprod ), and advised to avoid such similar names.
Learning from the web of life (Keynote)
Claire Janisch (BiomimicrySA) | Description
I was late for this report, but I was very well spoken about on Twitter. Need to see if it falls.
A video of the speech can be viewed on the conference website .
The Misinformation Age (Keynote)
Jane Adams (Two Sigma Investments) | Description
Philosophical report on the topic "can we trust decision-making algorithms". The general conclusion was that no: the algorithm can optimize specific metrics, but at the same time it has a serious effect on what is difficult to measure or lies outside of these metrics (as an example, there was discrimination in the employee hiring algorithm at Amazon, which negatively affected the culture in the company and forced to abandon this algorithm).
The Freedom of Kubernetes (Keynote)
Kris Nova | Description
I remembered two thoughts from there:
- flexibility is not freedom, but chaos;
- complexity itself is not a problem if it carries some value (in the original it was called “necessary complexity”), which exceeds the cost of this complexity.
The report was quite philosophical, therefore, on the one hand, I did not manage to take a lot out of it, but on the other, what I finally made is applicable not only in Kubernetes.

What changes when we go offline-first? (Keynote)
Martin Kleppmann (University of Cambridge), author of "Designing Data-Intensive Applications" | Description
The report consisted of two logical parts: in the first, Martin talked about the problem of synchronizing data between themselves, which can change in several sources independently of each other, and in the second, he described possible solutions and algorithms that can be used for this purpose ( operational transformation , OT , and conflict-free replicated data type , CRDT)) and offered its solution - the automerge library for solving such problems.
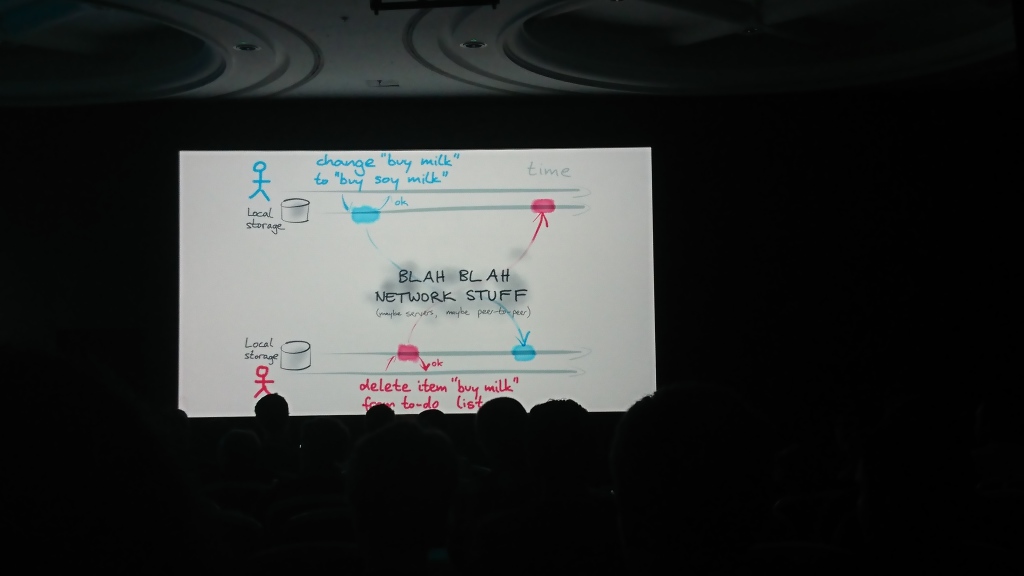


Additional materials:
A programmer's guide to secure connections
Speaker: Liz Rice | Description and slides
The report was held in the form of a live coding session, and in it Liz showed how HTTPS works, what errors can occur when working with secure connections and how to solve them. Some great depths were not there, but the demonstration itself was very good.
The most useful: a slide with the main mistakes ( he is from the report of Liz at another conference ):

Additional materials:
But you were afraid to ask
Simon Stewart (Selenium Project) | Description
The main thesis of the report is that it is much easier to manage dependencies in code in monorepo, and this overrides all the advantages of individual repositories. He appealed to the fact that Google and Microsoft store data in one repository (86 Tb and 300 Gb, respectively), and the Facebook repository (54 Gb files) uses "off the shell mercurial".
The hall "exploded" after the question "Who has more repositories in the company than employees?"
The argument “with a large repository to work slowly” was broken as follows:
- you do not need to take the entire change history to the local machine: use shadow clone and sparse checkout ;
- You do not need to use all the files from the repository: organize a hierarchy of files and work only with the correct directory, and exclude everything else.
Additional materials:
Building a distributed real-time stream processing system
Amy Boyle (New Relic) | Description and Presentation
A good story about working with streaming data from an engineer from NewRelic (where they clearly have a lot of experience working with such data). Amy told about the work with streaming data, how it can be aggregated, what can be done with delayed data, how to shuffle event streams and how to rebalance them when the handler fails, what to monitor, etc.
There was a lot of material in the report, I will not try to retell it, but simply recommend to watch the presentation itself (it is already on the conference website).


Architecting for TV
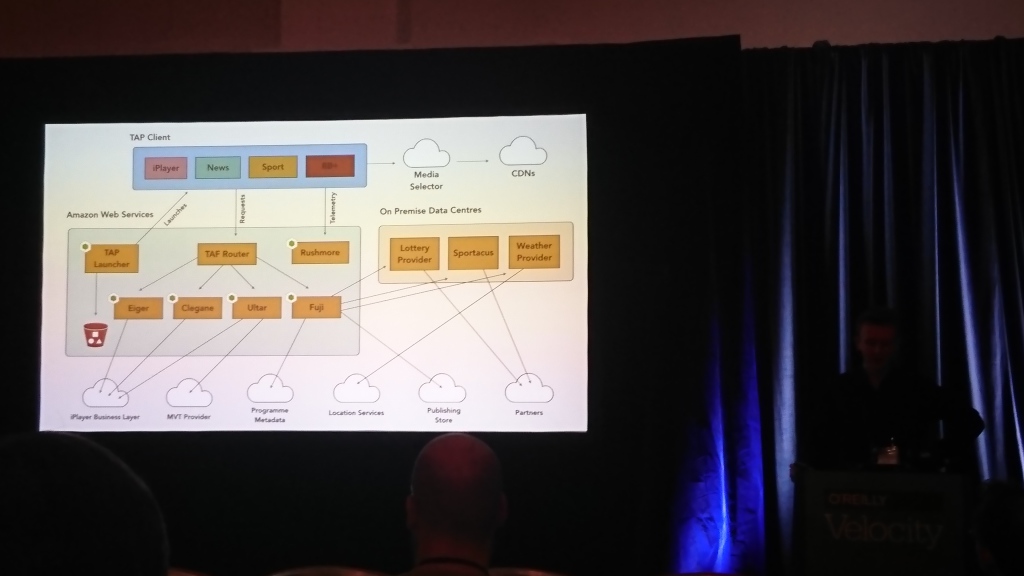
David Buckhurst (BBC), Ross Wilson (BBC) | Description
Much of the talk was about the BBC frontend. The guys have interactive television and many televisions and other devices (computers, phones, tablets) on which this should work. With different devices, you need to work in completely different ways, so they invented their own JSON-based language to describe the interfaces and translate it into what they can understand a particular device.
The main conclusion for me is that in comparison with TV people, mobile applications have no problems with old customers.
')
Source: https://habr.com/ru/post/429982/
All Articles