Overview of Deep Domain Adaptation Basic Methods (Part 2)
In the first part, we learned about the methods of domain adaptation through deep learning. We talked about the main data sets, as well as discrepancy-based and adversarial-based non-generative approaches. These methods show themselves well for some tasks. And this time we will analyze the most complex and promising adversarial-based methods: generative models, as well as algorithms that show the best results on VisDA data (adaptations from synthetic data to real photos).

Generative models
At the core of this approach is GAN’s ability to generate data from the required distribution. Thanks to this property, you can get the right amount of synthetic data and use them for training. The main idea of methods from the generative models family is to generate data that is as similar as the representatives of the target domain using the source domain. Thus, new synthetic data will have the same labels as the representatives of the original domain, on the basis of which they were obtained. The model for the target domain is then simply trained on this generated data.
Introduced at ICML-2018, the CyCADA method : Cycle-Consistent Adversarial Domain Adaptation ( code ) is a representative member of the generative models family. It combines several successful approaches from the GANs and domain adaptation. Its important part is the use of cycle-consistency loss, first presented in the article about CycleGAN . The idea of cycle-consistency loss is that the image obtained by generating from the source to the target domain, followed by the inverse transformation, should be close to the initial image. In addition, CyCADA includes adaptation at the pixel level and at the level of vector representations, as well as semantic loss to preserve the structure in the generated image.
Let be and - networks for the target and source domains, respectively, and - target and source domains, - markup on the source domain, and - generators from the source to the target domain and vice versa and - discriminators belonging to the target and source domains, respectively. Then the loss function, which is minimized in CyCADA, is the sum of six loss functions (the training scheme with loss numbers is presented below):
- - model classification on generated data and pseudo-labels from the source domain.
- - adversarial-loss for generator training .
- - adversarial-loss for generator training .
- (cycle-consistency loss) - -loss, ensuring that images obtained from and will be close.
- - adversarial-loss for vector views and on the generated data (similar to that used in ADDA).
- (semantic consistency loss) - loss responsible for the fact that will work in a similar way as on images taken from so from .
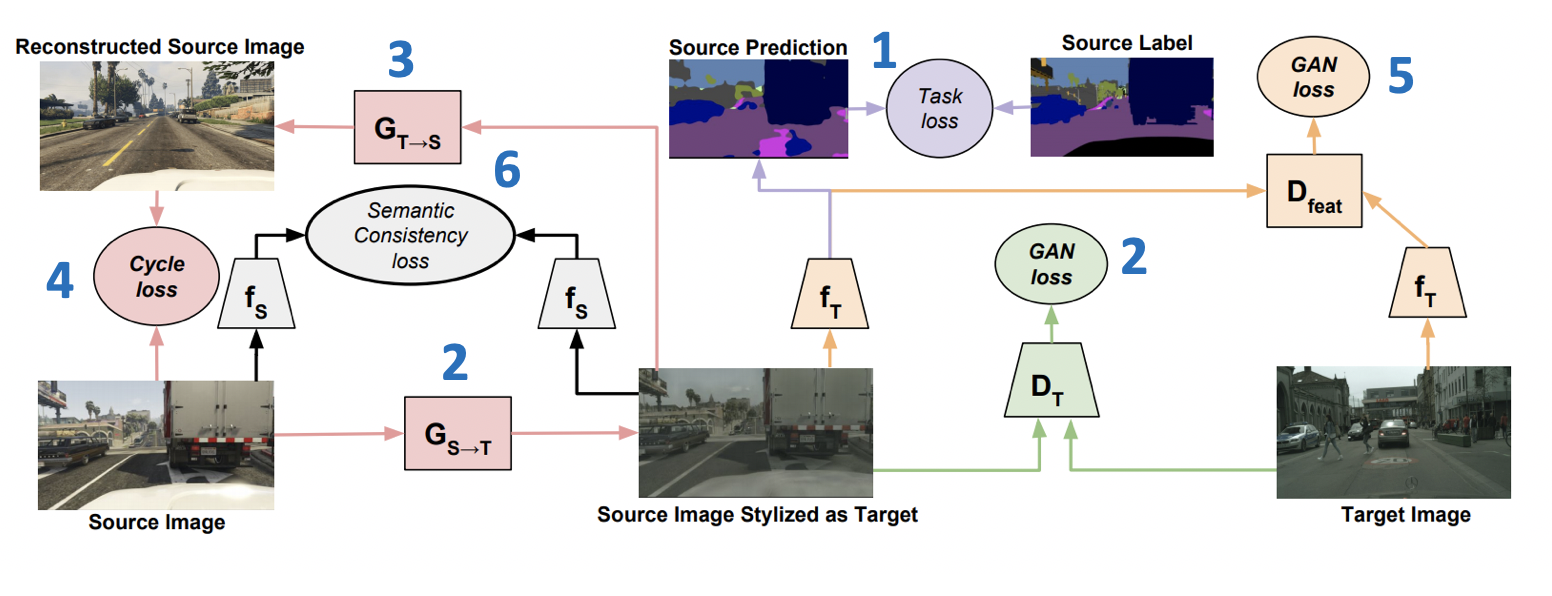
CyCADA results:
- On a pair of digital domains USPS -> MNIST: 95.7%.
- On the task of segmentation GTA 5 -> Cityscapes: Mean IoU = 39.5%.
As part of the Generate To Adapt: Aligning Domains using Generative Adversarial Networks ( code ) train this generator , so that at the output he would produce images close to the source domain. Such allows you to convert data from the target domain and apply to them the classifier trained on the marked data of the source domain.
To train such a generator, the authors use a modified discriminator. from the AC-GAN article. Feature of this lies in the fact that it not only answers 1 if it came to the input data from the source domain, and 0 otherwise, but also, in the case of a positive answer, classifies the input data into classes of the original domain.
Denote as a convolutional network that gives a vector representation of the image, - a classifier that works on a vector derived from . Schemes of learning and algorithm inference:
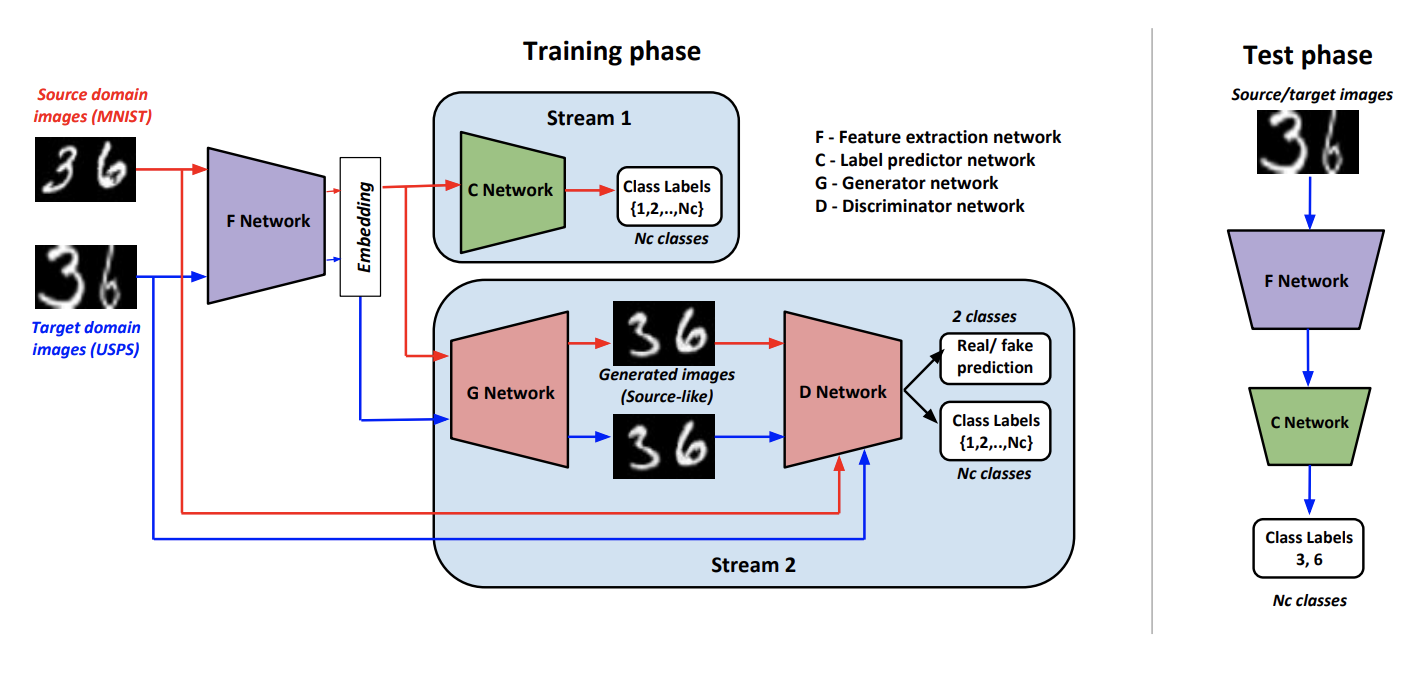
The learning procedure consists of several components:
- Discriminator is learning to define a domain for all received from data, and for the original domain is still added classification loss, as described above.
- On the data from the source domain using a combination of adversarial-loss and classification loss, the student is trained to generate a result that is similar to the domain source and is correctly classified .
- and Learn to classify data from the source domain. Also With the help of another classification loss, it is changed so as to increase the quality of classification .
- With adversarial-loss learns to cheat on data from the target domain.
- The authors empirically deduced that before serving in it makes sense to concat vector from with normal noise and one-hot class vector ( for target data).
The results of the method on benchmarks:
- On digital domains USPS -> MNIST: 90.8%.
- On dataset Office, the average adaptation quality for pairs of Amazon and Webcam domains: 86.5%.
- The average value of quality in 12 categories without a unknown class: 76.7%.
The article From source to target and back: symmetric bi-directional adaptive GAN ( code ) presented the SBADA-GAN model, which is quite similar to CyCADA and the objective function of which, just like in CyCADA, consists of 6 terms. In the notation of the authors and - generators from the source domain to the target and vice versa, and - discriminators that distinguish real data from those generated in the source and target domains, respectively, and - classifiers that are trained on data from the source domain and on their versions transformed into the target domain.
SBADA-GAN, like CyCADA, uses the idea from CycleGAN, consistency loss and pseudo-labels for the data generated in the target domain, making up the objective function from the corresponding components. The features of SBADA-GAN include:
- The image + noise is fed to the generator input.
- The test uses a linear combination of the predictions of the target-model and the source-model on the result of the transformation .
SBADA-GAN training scheme:
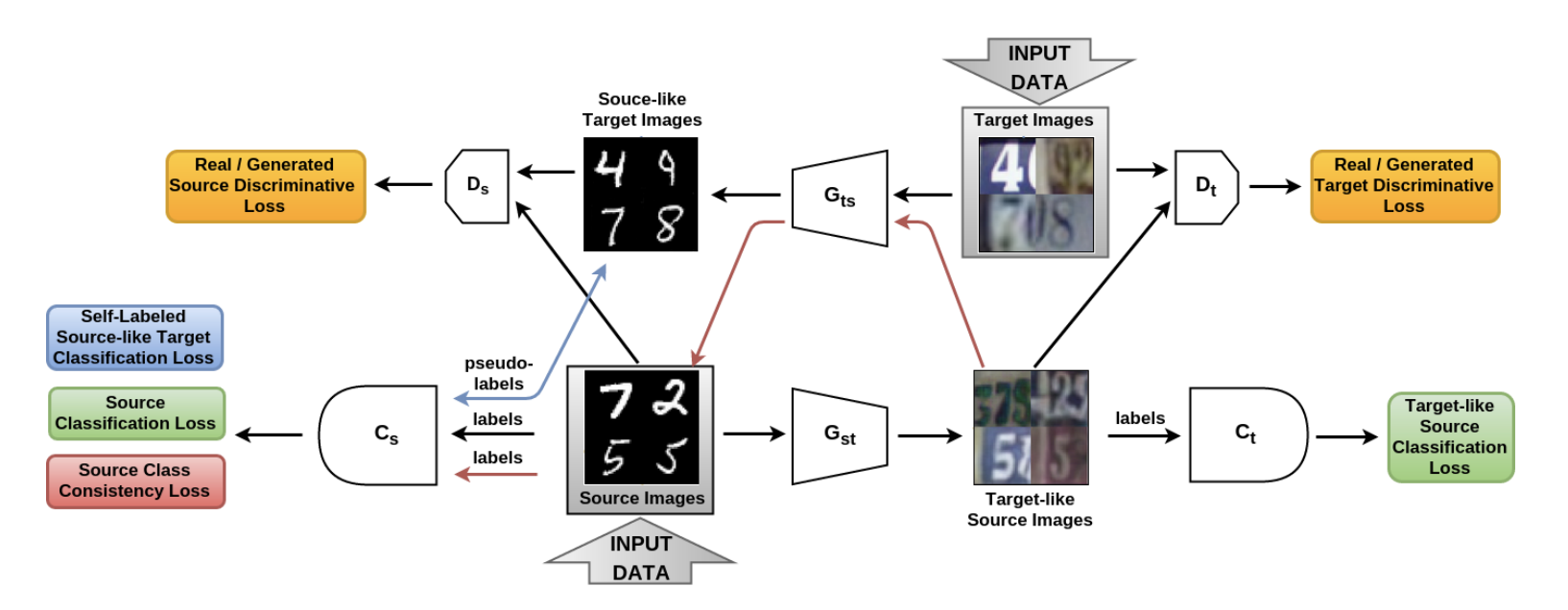
The authors of SBADA-GAN conducted more experiments than the authors of CyCADA, and obtained the following results:
- On USPS -> MNIST domains: 95.0%.
- On MNIST -> SVHN domains: 61.1%.
- On Synth Signs -> GTSRB road signs: 97.7%.
From the family of generative models, it makes sense to consider more important articles:
Visual Domain Adaptation Challenge
As part of the workshop at the ECCV and ICCV conferences, a competition on domain adaptation of the Visual Domain Adaptation Challenge is held . In it, participants are invited to train a classifier on synthetic data and adapt it to unpartitioned data from ImageNet.
The algorithm presented in Self-ensembling for visual domain adaptation ( code ) won VisDA-2017. This method is built on the idea of self-ensembling: there is a network teacher (teacher model) and a network student (student model). At each iteration, the input image is run through both of these networks. A student is trained using the sum of classification loss and consistency loss, where the classification loss is the usual cross-entropy with a well-known class mark, and the consistency loss is the average square of the difference between teacher and student predictions (squared difference). Teacher network weights are calculated as an exponential moving average of student network weights. Below is illustrated this learning procedure.
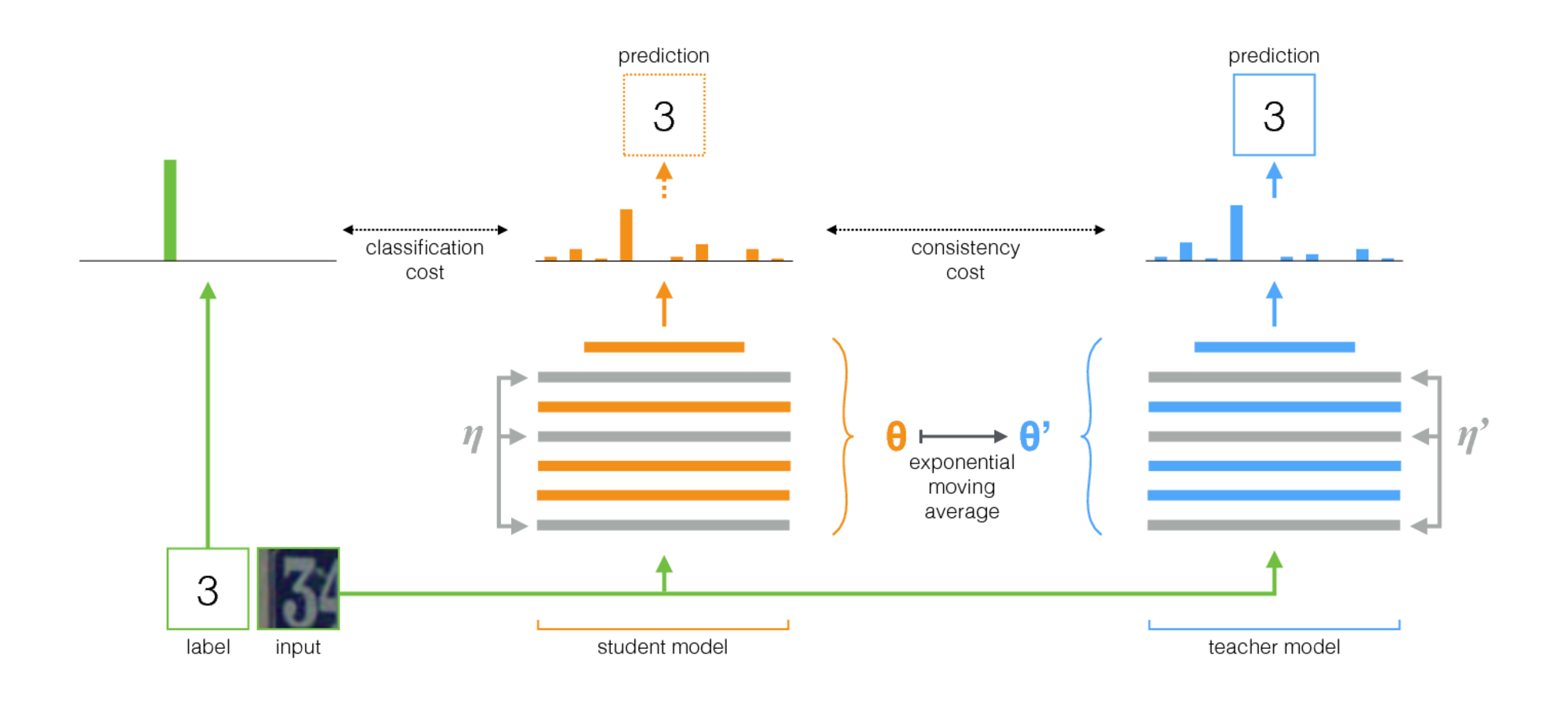
Important features of the application of this method for domain adaptation are:
- In the batch, when training, the data from the source domain is mixed with class labels and data from the target domain no tags.
- Before input to the neural networks, various strong augmentations are applied to the input images: Gaussian noises, affine transformations, etc.
- Both networks used strong regularization methods (for example, dropout).
- - exit network student, - teacher networks. If the input was from the target domain, then only consistency loss between and , cross-entropy loss = 0.
- For confidence of learning, confidence thresholding is applied: if the teacher's prediction is less than the threshold (0.9), then consistency loss loss = 0.
The scheme of the procedure described:

The algorithm has achieved high performance on the main data sets. True, for each task, the authors separately selected a set of augmentations.
- USPS -> MNIST: 99.54%.
- MNIST -> SVHN: 97.0%.
- Synth Numbers -> SVHN: 97.11%.
- On Synth Signs -> GTSRB road signs: 99.37%.
- The average value of quality in 12 categories without class Unknown: 92.8%. It is important to note that this result was obtained using an ensemble of 5 models and using test time augmentation.
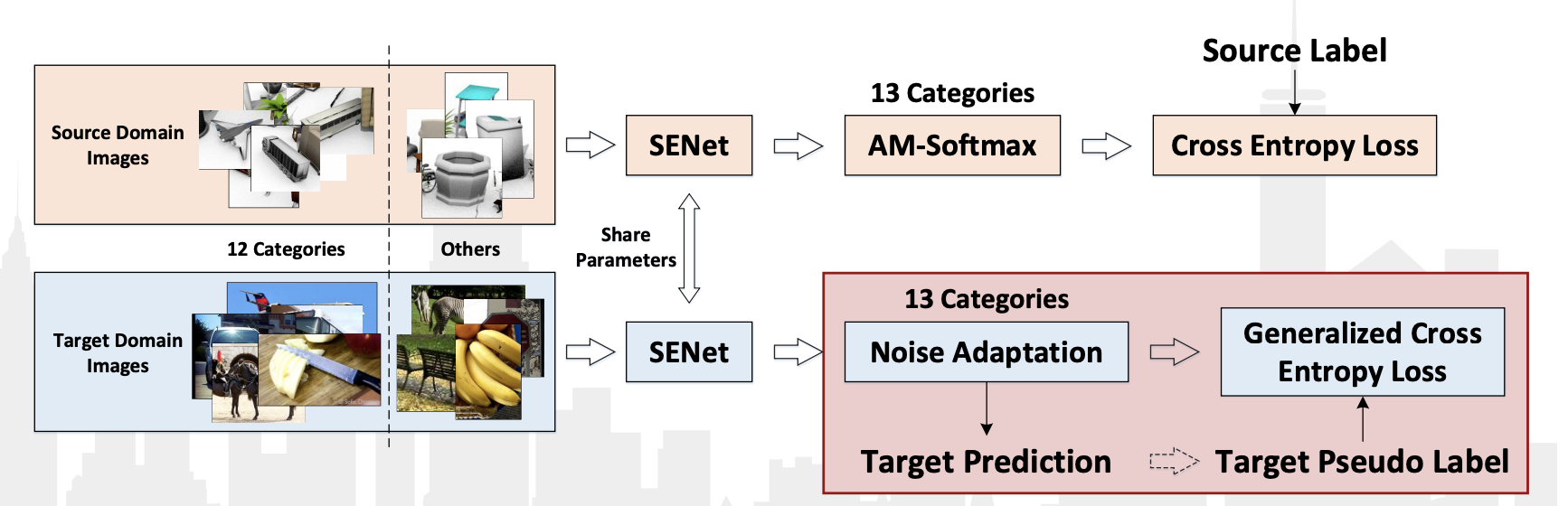
The VisDA-2018 competition was held this year as part of the ECCV-2018 conference. This time they added the 13th grade: Unknown, where everything that did not fall into 12 classes fell into. In addition, there was a separate competition for the detection of objects belonging to these 12 classes. The Chinese team JD AI Research won in both nominations. At the classification competition, they achieved a result of 92.3% (the average value of quality in 13 categories). There are no publications with a detailed description of their method, there is only a presentation from the workshop .
Of the features of their algorithm, we can note:
- Use of pseudo-labels for data from the target domain and additional learning of the classifier on them along with the data from the source domain.
- Using the SE-ResNeXt-101 convolutional network, AM-Softmax and Noise adaption layers, Generalized cross entropy loss layers for data from the target domain.
The scheme of the algorithm from the presentation:
Conclusion
For the most part, we discussed adaptation methods built on an adversarial-based approach. However, in the last two contests, VisDA defeated algorithms that are not related to it and use pseudo-label training and modifications to more classical deep learning methods. In my opinion, this is due to the fact that the methods based on GANs are still only at the beginning of their development and are extremely unstable. But every year we get more and more new results that improve the work of GANs. In addition, the focus of interest of the scientific community in the field of domain adaptation is mainly focused on adversarial-based methods, and new articles mainly investigate this approach. Therefore, it is likely that the algorithms associated with the GANs will gradually come to the forefront in adaptation issues.
But research in non-adversarial-based approaches also continues. Here are some interesting articles from this area:
Discrepancy-based methods can be classified as “historical”, but many of the ideas are used in the newest methods: MMD, pseudo-labels, metric-learning, etc. In addition, sometimes in simple adaptation tasks it makes sense to use these methods because of their relative ease of learning and better interpretability of the results.
In conclusion, I want to note that the methods of domain adaptation are still looking for their application in applied areas, but the promising tasks that require the use of adaptation are gradually becoming more and more. For example, domain adaptation is actively used in teaching autonomous car modules : since typing real data on city streets is expensive and time-consuming, autonomous cars use synthetic data (SYNTHIA and GTA 5 are examples of them), in particular. to solve the segmentation problem of what the camera “sees” from the car.
Obtaining high-quality models based on in-depth training in Computer Vision rests in many ways on the presence of large marked datasets for training. Markup almost always requires a lot of time and money, which significantly increases the development cycle of models and, as a result, products based on them.
Domain adaptation methods are aimed at solving this problem and can potentially contribute to a breakthrough in many applied tasks and in artificial intelligence as a whole. Transferring knowledge from one domain to another is indeed a difficult and interesting task, which is currently being actively investigated. If you suffer from a lack of data in your tasks, and can emulate data or find similar domains, I recommend trying the methods of domain adaptations!
')
Source: https://habr.com/ru/post/429966/
All Articles