How to use korutiny in prode and sleep well at night
Korutiny - a powerful tool for asynchronous code execution. They work in parallel, communicate with each other and consume few resources. It would seem that without fear, you can introduce corutinas in production. But there are fears and they interfere.
The report by Vladimir Ivanov on AppsConf is just about the fact that the devil is not so bad and that it is possible to use Korutin today:
About speaker : Vladimir Ivanov ( dzigoro ) is a leading Android developer at EPAM with 7 years of experience, enjoys Solution Architecture, React Native and iOS development, and also has a Google Cloud Architect certificate.
For information: the current status of Korutin - in the release, came out of Beta. Kotlin 1.3 was released, the Korutins were declared stable and world peace came.
')

Recently, I conducted a survey on Twitter that people have been using Corutin:
Statistics are not happy. I think that RxJava is too complicated tool for tasks in which it is usually used by developers. Korutiny more suitable for managing asynchronous operation.
In my previous reports, I told you how to refactor with RxJava on Korutina in Kotlin, so I will not dwell on this in detail, but only recall the main points.
Because if we use RxJava, then the usual examples of implementation look like this:
We have an interface, for example, we write a GitHub client and want to perform a couple of operations for it:
In both cases, the functions will return Single business objects: GitHubUser or a list of GitHubRepository.
The implementation code for this interface is as follows:
- We take compositeDisposable , so that there is no memory leak.
- Add a call to the first method.
- Use convenient operators to get the user, for example flatMap .
- Get a list of its repositories.
- We write Boilerplate that it was carried out on the necessary flows.
- When everything is ready - we show the list of repositories for the logged in user.
RxJava code difficulties:
What will be the same code with Korutins to version 0.26?
In 0.26, the API has changed, and we are talking about production. No one had time to apply 0.26 per product, but we are working on it.
With Corutin our interface will change quite significantly . Functions will stop returning any Singles and other helper objects. They will immediately return the business objects: GitHubUser and the GitHubRepository list. The GitHubUser and GitHubRepository functions will have suspend modifiers. This is good, because suspend us almost does not commit to anything:
If you look at the code that already uses the implementation of this interface, then it will change significantly compared to RxJava:
- The main action takes place where we call the coroutine builder async , wait for the answer and get userlnfo .
- Use data from this object.
- Make another call to async and call await .
Everything looks as if no asynchronous work is happening, and we just write commands to the bar and they are executed. In the end, we do what needs to be done on the UI.
Why are korutiny better?
2 steps to the side
A little distracted, there are a couple of things that still need to talk.
Step 1. withContext vs launch / async
In addition to the coroutine builder async, there is a coroutine builder withContext .
Launch or async creates a new Coroutine context , which is not always necessary. If you have a Coroutine context that you want to use throughout the application, then you do not need to recreate it. You can simply reuse the existing one. To do this, you need a coroutine builder withContext. It simply re-uses the existing Coroutine context. It will be 2-3 times faster, but now it is not a fundamental question. If the exact numbers are interesting, then here is the stackoverflow question with benchmarks and details.
Step 2. Refactoring
What if you refactor a really complex RxJava chain? I ran into this in production:
I had a complex chain with a public subject , with zip and side effects in each zipper , which else sent something to the event bus. The task at least was to get rid of the event bus. I spent the day, but could not refactor the code to solve the problem. The correct solution was to throw everything out and rewrite the code to coroutine in 4 hours .
The code below is very similar to what I did:
- We do async for one task, for the second and third.
- We are waiting for the result and add all this to the object.
- Done!
If you have complex chains and have korutiny, then just refactor. This is real fast.
What prevents developers from using Cortina in the sale?
In my opinion, we, as developers, are now prevented from using Korutiny only by the fear of something new:
Let's go for the points.
1. Lifecycle management
Stop
Are you familiar with the Thread.stop () method? If you used it, not for long. In JDK 1.1, the method was immediately declared obsolete, since it is impossible to take and stop a certain piece of code and there are no guarantees that it will complete correctly. Most likely you will only receive memory corruption .
Therefore, Thread.stop () does not work . You need to be canceled cooperatively, that is, the code on the other side knew that you are canceling it.
How we apply stops with RxJava:
In RxJava, we use CompositeDisposable .
- Add the compositeDisposable variable to the activity in the fragment or in the presenter, where we use RxJava.
- In onDestro y add Dispose and all exceptions go away by themselves.
Approximately the same principle with korutinami:
Consider the example of a simple task .
Normally, coroutine builders return a job , and in some cases Deferred .
- We can memorize this job.
- Give the command "launch" coroutine builder . The process starts, something happens, the result of the execution is remembered.
- If we don’t transfer anything else, then “launch” launches the function and returns us the reference to the job.
- Job remember, and in onDestroy we say “cancel” and everything works well.
What is the problem approach? For each job, a field is needed. You need to maintain a list of jobs to cancel them all together. The approach leads to duplication of code, do not do so.
The good news is that we have alternatives : CompositeJob and Lifecycle-aware job .
CompositeJob is an analogue of compositeDisposable. It looks like this :
- On one fragment we get one job.
“All job’s are added to CompositeJob and give the command: “ job.cancel () for everyone! ” .
The approach is easily implemented in 4 lines, not counting the class declaration:
You will need:
- map with string key,
- the add method to which you will add the job,
- optional key parameter.
If you want to use the same key for the same job, please. If not, hashCode solves our problem. We add job in map which we transferred, and we cancel previous with the same key. If we exceed the task, we are not interested in the previous result. We cancel it and run it again.
Cancel is simple: get job by key and cancel. The second cancel for the entire map cancels everything. All code is written in half an hour in four lines and it works. If you do not want to write - take an example above.
Did you use Android Lifecycle , Lifecycle owner or observer ?
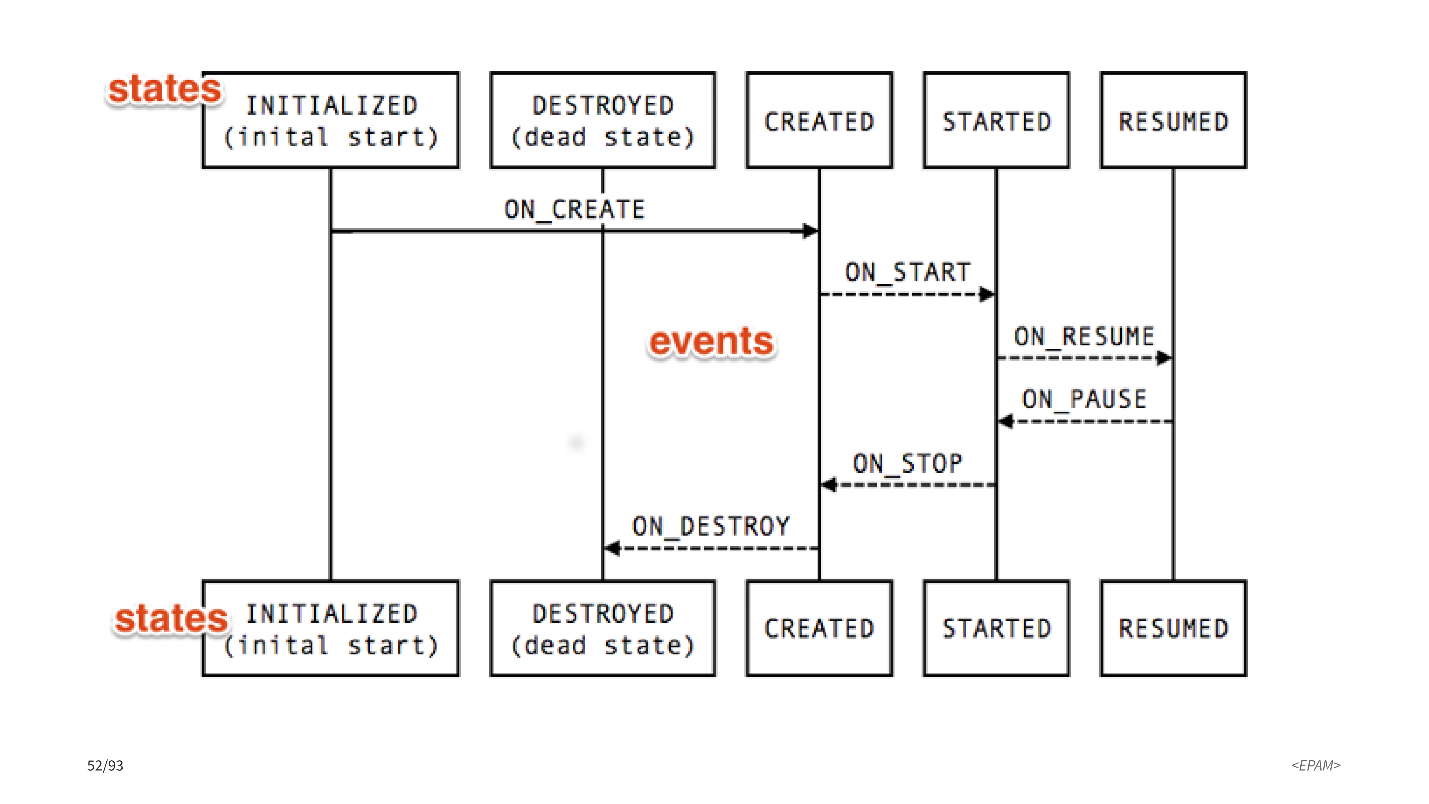
Our activity and fragments have certain states. Most interesting: created, started and resumed . There are different transitions between states. LifecycleObserver allows you to subscribe to these transitions and do something when one of the transitions happens.
It looks quite simple:
You hang up the annotation with some parameter on the method, and it is called with the appropriate transition. It is enough just to use this approach for corutin:
- You can write the base class AndroidJob .
- In the class we will pass Lifecycle .
- The LifecycleObserver interface will implement the job.
All we need is:
- In the constructor, add to the Lifecycle as an Observer.
- Subscribe to ON_DESTROY or anything else that interests us.
- Make a cancel at ON_DESTROY.
- Start one parentJob in your snippet.
- Call the Joy jobs designer or lifecycle of your activity fragment. No difference.
- Pass this parentJob as a parent .
The finished code looks like this:
When you cancel parent, all child corutines are canceled and you no longer need to write anything in the fragment. Everything happens automatically, no more ON_DESTROY. The main thing is not to forget to pass parent = parentJob .
WITH Lifecycle management sorted out. We have a couple of tools that make it all easy and comfortable.
What about complex scenarios and non-trivial production tasks?
2. Complex use-cases
Complex scripts and nontrivial tasks are:
- Operators - complex operators in RxJava: flatMap, debounce, etc.
- Error-handling - complex error handling. Not simple try..catch , but for example, nested.
- Caching is a non - trivial task. In production, we ran into a cache and wanted to get a tool to easily solve the problem of caching with corutines.
When we thought about operators for corutin, the first option was repeatWhen () .
If something went wrong and the quorutine could not reach the server inside, then we want to try again several times with some exponential fallback. Perhaps the reason is a bad connection and we get the desired result by repeating the operation several times.
With Corutin, this task is easily implemented:
Operator implementation:
- He takes Deferred .
- You will need to call async to get this object.
- Instead of Deferred, you can transfer and suspend a block and, in general, any suspend function.
- Cycle for - you are waiting for the result of your korutiny. If something happens and the repeat counter is not exhausted, try again through Delay . If not, then no.
The function can be easily customized: put an exponential Delay or pass a lambda function that will calculate the Delay depending on the circumstances.
Enjoy, it works!
Also often come across them. Here again, everything is simple:
- Use zipper and call await on your Deferred.
- Instead of Deferred, you can use the suspend function and the coroutine builder with withContext. You will convey the context you need.
This again works and I hope that I have removed this fear.
Do you have a cache implementation in production with RxJava? We use rxcache.
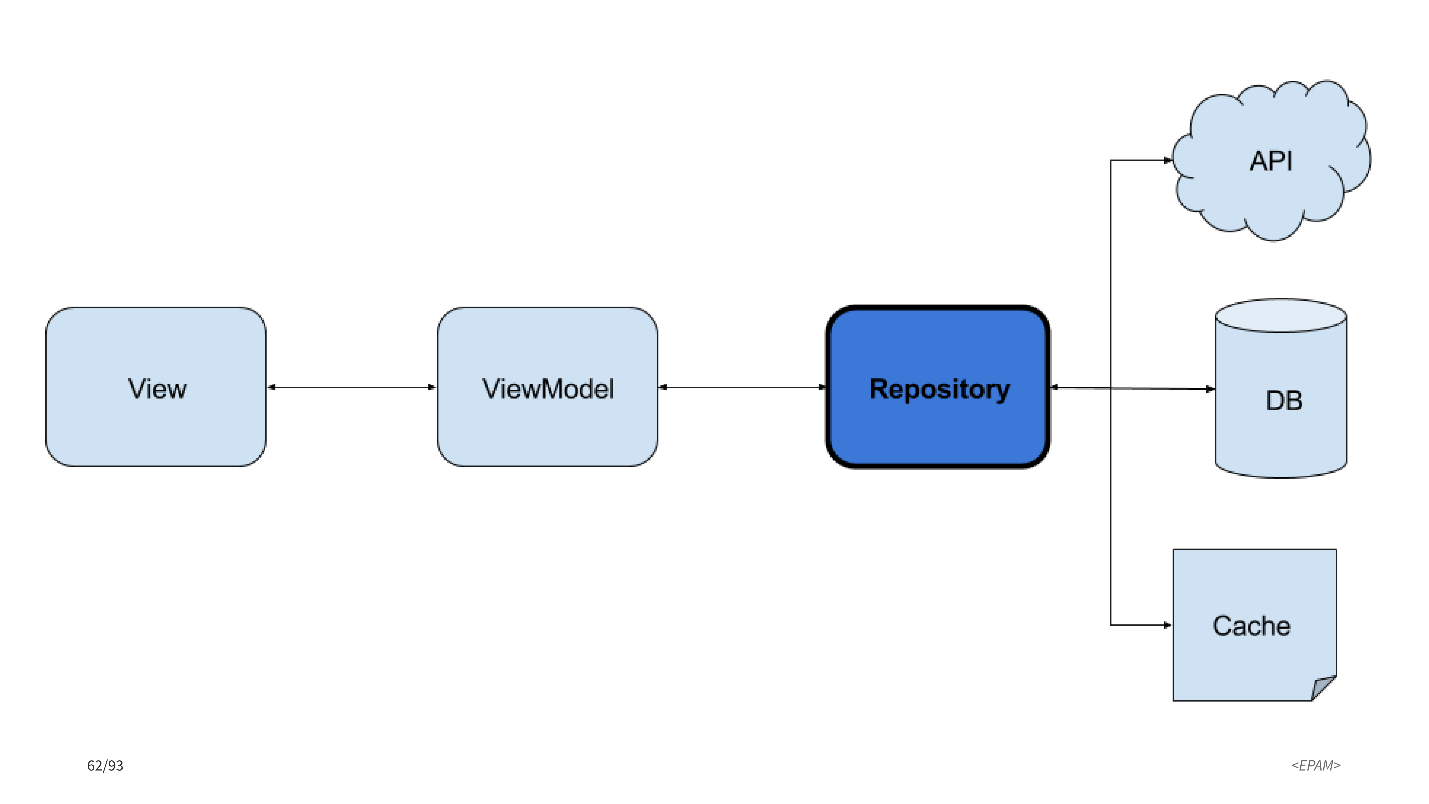
In the diagram on the left: View and ViewModel . On the right - data sources: network calls and database.
If we want something to be cached, then cache will be another data source.
Types of cache:
We write a simple and primitive cache for the third case. Coroutine builder withContext comes to the rescue again.
- You perform each operation with withContext and see if any data is coming.
- If the data from persistence does not come, then you try to get it from memory.cache .
- If the memory.cache is also not, then contact the network source and get your data. Do not forget, of course, put in all the caches.
This is a rather primitive implementation and there are many questions here, but the method works if you need the cache in one place. For production tasks this cache is not enough. Need something more complicated.
For those who still use RxJava, you can use RxCache. We still use it too. RxCache is a special library. Allows you to cache data and manage its life cycle.
For example, you want to say that this data will become obsolete in 15 minutes: “Please, after this period of time, do not give the data from the cache, but send me fresh data”.
The library is wonderful because it will support the team declaratively. The declaration is very similar to what you do with Retrofit :
- You say that you have a CacheProvider .
- Start a method and say that LifeCache's lifetime is 15 minutes. The key by which it will be available is Features .
- Returns Observable <Reply , where Reply is an auxiliary library object for working with cache.
The use is quite simple:
- With Rx Cache access to RestApi .
- Appeals to CacheProvider .
- Feed him Observable.
- The library itself will figure out what to do: go to the cache or not, if the time runs out, contact Observable and perform another operation.
Using the library is very convenient and I would like to get a similar one for Corutin.
Inside EPAM, we write the Coroutine Cache library, which will execute all the functions of RxCache. We wrote the first version and run it inside the company. As soon as the first release comes out, I’ll be happy to write about it on my Twitter. It will look like this:
We will have a getFeatures suspend function. The function will be passed as a block into a special function of a higher order withCache , which will itself understand what needs to be done.
Perhaps we will make the same interface to support declarative functions.
Error processing

Simple error handling is often found by developers and is usually quite simple. If you do not have complicated things, then in catch you catch an exercise and see what happened there, write to the log or show an error to the user. On the UI, you can easily do this.
In simple cases, everything is expected to be easy - error handling with corutins is done through try-catch-finally .
In production, in addition to simple cases, there are:
- nested try-catch ,
- Many different types of expressions ,
- Errors in the network or in business logic,
- User errors. He did something wrong again and is to blame for everything.
We must be ready for this.
There are 2 possible solutions: CoroutineExceptionHandler and the Result classes approach.
Coroutine Exception Handler
This is a special class for handling complex error cases. ExceptionHandler allows you to take as your argument the Exception as an error and handle it.
How do we usually handle complex errors?
The user clicked something, the button did not work. He needs to say what went wrong and direct it to a specific action: check the Internet, Wi-Fi, try it later or delete the application and never use it again. Say about this user can be quite simple:
- Let's get the default message: “Something went wrong!” And analyze the exception.
- If it is ConnectionException, then we take a localized message from the resources: “Man, turn on Wi-Fi and your problems will go away. I guarantee it. ”
- If the server said something wrong , then you need to inform the client: “Go out and log in again”, or “Do not do it in Moscow, do it in another country”, or “Sorry, comrade. All I can do is just say that something went wrong. ”
- If this is a completely different error , for example, out of memory , we say: "Something went wrong, I'm sorry."
- All messages are output.
What you write to CoroutineExceptionHandler will run on the same Dispatcher where you run coruntine. So if you give the “launch” command to the UI, then everything happens on the UI. You do not need a separate dispatching, which is very convenient.
It’s easy to use:
There is a plus operator. In the Coroutine context add a handler and everything works, which is very convenient. We used it for a while.
Result classes
We later realized that a CoroutineExceptionHandler might be missing. The result, which is formed by the work of korutina, may consist of several data, of different parts or process several situations.
Result classes helps to cope with this problem:
- In your business logic, you get the Result class .
- Mark as sealed .
- Inherit from the class two other data classes: Success and Error .
- In Success, transfer your data that is formed as a result of performing corutina.
- In Error add exception.
Then you can implement the business logic as follows:
You call the Coroutine context - Coroutine builder withContex and you can handle different situations.
For example, a logged in user:
- We exit and say that this is an error. Let the logic above handle it.
- You can call RestApi or other business logic.
- If everything is fine, then Result.Success is returned .
- If an exception occurs, then Result.Error .
The approach allows you to delegate error handling somewhere further, although the ExceptionHandler does the same.
Result classes work, tests are convenient to write. We use Result classes, but you can use both ExceptionHandler and try-catch.
3. Testing
The last thing that worries us and prevents sleep well. If you are writing unit tests , then you are sure that everything is working correctly. With Corutin, we also want to write unit tests.
Let's see how to do it. Globally, in order to write unit-tests, we need to solve 2 problems:
Replacing context
So the presenter looks like:
For example, if in the login method you launch your coruntine, then it explicitly uses the UI context. This is not very good for tests, since one of the principles of application testing says that all dependencies must be explicitly passed to a method or class . Here the principle is not respected, so the code needs to be improved in order to write a unit-test.
The improvement is quite simple:
- In the login method, configure the transfer of coroutineContext. It is clear that in the code of your application you do not want to pass it everywhere explicitly. In Kotlin, you can simply write that it should be the default UI.
- Call your Coroutine builder with the Coroutine Contex that you pass to the method.
In the unit test, you can do the following:
- You can create your LoginPresenter and call the login method with some context, for example, with Unconfined.
- Unconfined reports that the quorutine will be launched on the stream that starts it. This allows one line to write tests and check the result.
Mocking coroutines
The next question is mocking a corutin. I recommend using Mockk for unit tests. This is a lightweight unit-testing framework specifically written in Kotlin, in which it is easy to work with Korutins. You can replace the suspend function or the coroutine with the help of the special function coEvery and instead of calling corutina, return an interesting business object.
Here, a login call instead of a cortina simply returns githubUser :
If you have Mockito-kotlin , then everything is a little more difficult - you will have to dance with a tambourine. Perhaps there is a more accurate way, but now we use this:
We use just runBlocking . With the given block we do the same as in the previous example.
We can write a complete test on our presenter :
- Prepare your business data, for example, GitHubUser .
- The LoginPresenter explicitly passes the dependency to our API, but now it will be locked. How do you mokiruete it up to you.
- Then call presenter.login with the Unconfined context and check that all the necessary data that we are expecting has been generated in the Presenter.
And that's it! Testing Korutin really easy.
Let's sum up
useful links
The report by Vladimir Ivanov on AppsConf is just about the fact that the devil is not so bad and that it is possible to use Korutin today:
- why corutinos, not RxJava ;
- what fears interfere with developers ;
- how to make a cache using korutiny ;
- how to handle errors correctly .
About speaker : Vladimir Ivanov ( dzigoro ) is a leading Android developer at EPAM with 7 years of experience, enjoys Solution Architecture, React Native and iOS development, and also has a Google Cloud Architect certificate.
Everything you read is a product of experience and various studies, so take it as it is, without any guarantees.
Korutin, Kotlin and RxJava
For information: the current status of Korutin - in the release, came out of Beta. Kotlin 1.3 was released, the Korutins were declared stable and world peace came.
')
Recently, I conducted a survey on Twitter that people have been using Corutin:
- 13% of Korutin in Prode. All is well;
- 25% try them in the pet project;
- 24% - What's Kotlin?
- The main mass in 38% RxJava everywhere.
Statistics are not happy. I think that RxJava is too complicated tool for tasks in which it is usually used by developers. Korutiny more suitable for managing asynchronous operation.
In my previous reports, I told you how to refactor with RxJava on Korutina in Kotlin, so I will not dwell on this in detail, but only recall the main points.
Why do we use korutiny?
Because if we use RxJava, then the usual examples of implementation look like this:
interface ApiClientRx { fun login(auth: Authorization) : Single<GithubUser> fun getRepositories (reposUrl: String, auth: Authorization) : Single<List<GithubRepository>> } //RxJava 2 implementation We have an interface, for example, we write a GitHub client and want to perform a couple of operations for it:
- Log in user
- Get a list of GitHub repositories.
In both cases, the functions will return Single business objects: GitHubUser or a list of GitHubRepository.
The implementation code for this interface is as follows:
private fun attemptLoginRx () { showProgress(true) compositeDisposable.add(apiClient.login(auth) .flatMap { user -> apiClient.getRepositories(user.repos_url, auth) } .map { list -> list.map { it.full_name } } .subscribeOn(Schedulers.io()) .observeOn(AndroidSchedulers.mainThread()) .doFinally { showProgress(false) } .subscribe( { list -> showRepositories(this, list) }, { error -> Log.e("TAG", "Failed to show repos", error) } )) } - We take compositeDisposable , so that there is no memory leak.
- Add a call to the first method.
- Use convenient operators to get the user, for example flatMap .
- Get a list of its repositories.
- We write Boilerplate that it was carried out on the necessary flows.
- When everything is ready - we show the list of repositories for the logged in user.
RxJava code difficulties:
- Complexity. In my opinion, the code is too complicated for the simple task of two network calls and displaying something on the UI .
- Unbound stack traces. Stack traces are almost unrelated to the code you write.
- Overuse of resources . RxJava generates many objects under the hood and performance may decline.
What will be the same code with Korutins to version 0.26?
In 0.26, the API has changed, and we are talking about production. No one had time to apply 0.26 per product, but we are working on it.
With Corutin our interface will change quite significantly . Functions will stop returning any Singles and other helper objects. They will immediately return the business objects: GitHubUser and the GitHubRepository list. The GitHubUser and GitHubRepository functions will have suspend modifiers. This is good, because suspend us almost does not commit to anything:
interface ApiClient { suspend fun login(auth: Authorization) : GithubUser suspend fun getRepositories (reposUrl: String, auth: Authorization) : List<GithubRepository> } //Base interface If you look at the code that already uses the implementation of this interface, then it will change significantly compared to RxJava:
private fun attemptLogin () { launch(UI) { val auth = BasicAuthorization(login, pass) try { showProgress(true) val userlnfo = async { apiClient.login(auth) }.await() val repoUrl = userlnfo.repos_url val list = async { apiClient.getRepositories(repoUrl, auth) }.await() showRepositories( this, list.map { it -> it.full_name } ) } catch (e: RuntimeException) { showToast("Oops!") } finally { showProgress(false) } } } - The main action takes place where we call the coroutine builder async , wait for the answer and get userlnfo .
- Use data from this object.
- Make another call to async and call await .
Everything looks as if no asynchronous work is happening, and we just write commands to the bar and they are executed. In the end, we do what needs to be done on the UI.
Why are korutiny better?
- This code is easier to read. It is written as if it were consistent.
- Most likely the performance of this code is better than on RxJava.
- It's very easy to write tests, but we'll get to them a bit later.
2 steps to the side
A little distracted, there are a couple of things that still need to talk.
Step 1. withContext vs launch / async
In addition to the coroutine builder async, there is a coroutine builder withContext .
Launch or async creates a new Coroutine context , which is not always necessary. If you have a Coroutine context that you want to use throughout the application, then you do not need to recreate it. You can simply reuse the existing one. To do this, you need a coroutine builder withContext. It simply re-uses the existing Coroutine context. It will be 2-3 times faster, but now it is not a fundamental question. If the exact numbers are interesting, then here is the stackoverflow question with benchmarks and details.
General rule: Use withContext without doubt where it is semantically appropriate. But if you need parallel loading, for example several pictures or parts of data, then async / await is your choice.
Step 2. Refactoring
What if you refactor a really complex RxJava chain? I ran into this in production:
observable1.getSubject().zipWith(observable2.getSubject(), (t1, t2) -> { // side effects return true; }).doOnError { // handle errors } .zipWith(observable3.getSubject(), (t3, t4) -> { // side effects return true; }).doOnComplete { // gather data } .subscribe() I had a complex chain with a public subject , with zip and side effects in each zipper , which else sent something to the event bus. The task at least was to get rid of the event bus. I spent the day, but could not refactor the code to solve the problem. The correct solution was to throw everything out and rewrite the code to coroutine in 4 hours .
The code below is very similar to what I did:
try { val firstChunkJob = async { call1 } val secondChunkJob = async { call2 } val thirdChunkJob = async { call3 } return Result( firstChunkJob.await(), secondChunkJob.await(), thirdChunkJob.await()) } catch (e: Exception) { // handle errors } - We do async for one task, for the second and third.
- We are waiting for the result and add all this to the object.
- Done!
If you have complex chains and have korutiny, then just refactor. This is real fast.
What prevents developers from using Cortina in the sale?
In my opinion, we, as developers, are now prevented from using Korutiny only by the fear of something new:
- We do not know what to do with the lifecycle , with the activity and the life cycle of the fragments. How to work with korutinami in these cases?
- No experience solving daily complex tasks in production using korutin.
- Not enough tools. For RxJava, a bunch of libraries and functions are written. For example RxFCM . There are a lot of operators in RxJava itself, which is good, but what about korutin?
- We do not really understand how to test Korutiny.
If we get rid of these four fears, we will be able to sleep at night and use the korutiny in production.
Let's go for the points.
1. Lifecycle management
- Korutiny can flow away as disposable or AsyncTask . This problem needs to be solved manually.
- To avoid the random Null Pointer Exception, the cortinas need to be stopped.
Stop
Are you familiar with the Thread.stop () method? If you used it, not for long. In JDK 1.1, the method was immediately declared obsolete, since it is impossible to take and stop a certain piece of code and there are no guarantees that it will complete correctly. Most likely you will only receive memory corruption .
Therefore, Thread.stop () does not work . You need to be canceled cooperatively, that is, the code on the other side knew that you are canceling it.
How we apply stops with RxJava:
private val compositeDisposable = CompositeDisposable() fun requestSmth() { compositeDisposable.add( apiClientRx.requestSomething() .subscribeOn(Schedulers.io()) .observeOn(AndroidSchedulers.mainThread()) .subscribe(result -> {}) } override fun onDestroy() { compositeDisposable.dispose() } In RxJava, we use CompositeDisposable .
- Add the compositeDisposable variable to the activity in the fragment or in the presenter, where we use RxJava.
- In onDestro y add Dispose and all exceptions go away by themselves.
Approximately the same principle with korutinami:
private val job: Job? = null fun requestSmth() { job = launch(UI) { val user = apiClient.requestSomething() … } } override fun onDestroy() { job?.cancel() } Consider the example of a simple task .
Normally, coroutine builders return a job , and in some cases Deferred .
- We can memorize this job.
- Give the command "launch" coroutine builder . The process starts, something happens, the result of the execution is remembered.
- If we don’t transfer anything else, then “launch” launches the function and returns us the reference to the job.
- Job remember, and in onDestroy we say “cancel” and everything works well.
What is the problem approach? For each job, a field is needed. You need to maintain a list of jobs to cancel them all together. The approach leads to duplication of code, do not do so.
The good news is that we have alternatives : CompositeJob and Lifecycle-aware job .
CompositeJob is an analogue of compositeDisposable. It looks like this :
private val job: CompositeJob = CompositeJob() fun requestSmth() { job.add(launch(UI) { val user = apiClient.requestSomething() ... }) } override fun onDestroy() { job.cancel() } - On one fragment we get one job.
“All job’s are added to CompositeJob and give the command: “ job.cancel () for everyone! ” .
The approach is easily implemented in 4 lines, not counting the class declaration:
Class CompositeJob { private val map = hashMapOf<String, Job>() fun add(job: Job, key: String = job.hashCode().toString()) = map.put(key, job)?.cancel() fun cancel(key: String) = map[key]?.cancel() fun cancel() = map.forEach { _ ,u -> u.cancel() } } You will need:
- map with string key,
- the add method to which you will add the job,
- optional key parameter.
If you want to use the same key for the same job, please. If not, hashCode solves our problem. We add job in map which we transferred, and we cancel previous with the same key. If we exceed the task, we are not interested in the previous result. We cancel it and run it again.
Cancel is simple: get job by key and cancel. The second cancel for the entire map cancels everything. All code is written in half an hour in four lines and it works. If you do not want to write - take an example above.
Lifecycle-aware job
Did you use Android Lifecycle , Lifecycle owner or observer ?
Our activity and fragments have certain states. Most interesting: created, started and resumed . There are different transitions between states. LifecycleObserver allows you to subscribe to these transitions and do something when one of the transitions happens.
It looks quite simple:
public class MyObserver implements LifecycleObserver { @OnLifecycleEvent(Lifecycle.Event.ON_RESUME) public void connectListener() { ... } @OnLifecycleEvent(Lifecycle.Event.ON_PAUSE) public void disconnectListener() { … } } You hang up the annotation with some parameter on the method, and it is called with the appropriate transition. It is enough just to use this approach for corutin:
class AndroidJob(lifecycle: Lifecycle) : Job by Job(), LifecycleObserver { init { lifecycle.addObserver(this) } @OnLifecycleEvent(Lifecycle.Event.ON_DESTROY) fun destroy() { Log.d("AndroidJob", "Cancelling a coroutine") cancel() } } - You can write the base class AndroidJob .
- In the class we will pass Lifecycle .
- The LifecycleObserver interface will implement the job.
All we need is:
- In the constructor, add to the Lifecycle as an Observer.
- Subscribe to ON_DESTROY or anything else that interests us.
- Make a cancel at ON_DESTROY.
- Start one parentJob in your snippet.
- Call the Joy jobs designer or lifecycle of your activity fragment. No difference.
- Pass this parentJob as a parent .
The finished code looks like this:
private var parentJob = AndroidJob(lifecycle) fun do() { job = launch(UI, parent = parentJob) { // code } } When you cancel parent, all child corutines are canceled and you no longer need to write anything in the fragment. Everything happens automatically, no more ON_DESTROY. The main thing is not to forget to pass parent = parentJob .
If you use, you can write a simple lint rule, which will highlight you: “Oh, you forgot your parent!”
WITH Lifecycle management sorted out. We have a couple of tools that make it all easy and comfortable.
What about complex scenarios and non-trivial production tasks?
2. Complex use-cases
Complex scripts and nontrivial tasks are:
- Operators - complex operators in RxJava: flatMap, debounce, etc.
- Error-handling - complex error handling. Not simple try..catch , but for example, nested.
- Caching is a non - trivial task. In production, we ran into a cache and wanted to get a tool to easily solve the problem of caching with corutines.
Repeat
When we thought about operators for corutin, the first option was repeatWhen () .
If something went wrong and the quorutine could not reach the server inside, then we want to try again several times with some exponential fallback. Perhaps the reason is a bad connection and we get the desired result by repeating the operation several times.
With Corutin, this task is easily implemented:
suspend fun <T> retryDeferredWithDelay( deferred: () -> Deferred<T>, tries: Int = 3, timeDelay: Long = 1000L ): T { for (i in 1..tries) { try { return deferred().await() } catch (e: Exception) { if (i < tries) delay(timeDelay) else throw e } } throw UnsupportedOperationException() } Operator implementation:
- He takes Deferred .
- You will need to call async to get this object.
- Instead of Deferred, you can transfer and suspend a block and, in general, any suspend function.
- Cycle for - you are waiting for the result of your korutiny. If something happens and the repeat counter is not exhausted, try again through Delay . If not, then no.
The function can be easily customized: put an exponential Delay or pass a lambda function that will calculate the Delay depending on the circumstances.
Enjoy, it works!
Zips
Also often come across them. Here again, everything is simple:
suspend fun <T1, T2, R> zip( source1: Deferred<T1>, source2: Deferred<T2>, zipper: BiFunction<T1, T2, R>): R { return zipper.apply(sourcel.await(), source2.await()) } suspend fun <T1, T2, R> Deferred<T1>.zipWith( other: Deferred<T2>, zipper: BiFunction<T1, T2, R>): R { return zip(this, other, zipper) } - Use zipper and call await on your Deferred.
- Instead of Deferred, you can use the suspend function and the coroutine builder with withContext. You will convey the context you need.
This again works and I hope that I have removed this fear.
Cache
Do you have a cache implementation in production with RxJava? We use rxcache.
In the diagram on the left: View and ViewModel . On the right - data sources: network calls and database.
If we want something to be cached, then cache will be another data source.
Types of cache:
- Network Source for network calls.
- In-memory cache .
- Persistent cache with expiration for storage on disk so that the cache survives the restart of the application.
We write a simple and primitive cache for the third case. Coroutine builder withContext comes to the rescue again.
launch(UI) { var data = withContext(dispatcher) { persistence.getData() } if (data == null) { data = withContext(dispatcher) { memory.getData() } if (data == null) { data = withContext(dispatcher) { network.getData() } memory.cache(url, data) persistence.cache(url, data) } } } - You perform each operation with withContext and see if any data is coming.
- If the data from persistence does not come, then you try to get it from memory.cache .
- If the memory.cache is also not, then contact the network source and get your data. Do not forget, of course, put in all the caches.
This is a rather primitive implementation and there are many questions here, but the method works if you need the cache in one place. For production tasks this cache is not enough. Need something more complicated.
Rx has rxcache
For those who still use RxJava, you can use RxCache. We still use it too. RxCache is a special library. Allows you to cache data and manage its life cycle.
For example, you want to say that this data will become obsolete in 15 minutes: “Please, after this period of time, do not give the data from the cache, but send me fresh data”.
The library is wonderful because it will support the team declaratively. The declaration is very similar to what you do with Retrofit :
public interface FeatureConfigCacheProvider { @ProviderKey("features") @LifeCache(duration = 15, timeUnit = TimeUnit.MINUTES) fun getFeatures( result: Observable<Features>, cacheName: DynamicKey ): Observable<Reply<Features>> } - You say that you have a CacheProvider .
- Start a method and say that LifeCache's lifetime is 15 minutes. The key by which it will be available is Features .
- Returns Observable <Reply , where Reply is an auxiliary library object for working with cache.
The use is quite simple:
val restObservable = configServiceRestApi.getFeatures() val features = featureConfigCacheProvider.getFeatures( restObservable, DynamicKey(CACHE_KEY) ) - With Rx Cache access to RestApi .
- Appeals to CacheProvider .
- Feed him Observable.
- The library itself will figure out what to do: go to the cache or not, if the time runs out, contact Observable and perform another operation.
Using the library is very convenient and I would like to get a similar one for Corutin.
Coroutine Cache in Development
Inside EPAM, we write the Coroutine Cache library, which will execute all the functions of RxCache. We wrote the first version and run it inside the company. As soon as the first release comes out, I’ll be happy to write about it on my Twitter. It will look like this:
val restFunction = configServiceRestApi.getFeatures() val features = withCache(CACHE_KEY) { restFunction() } We will have a getFeatures suspend function. The function will be passed as a block into a special function of a higher order withCache , which will itself understand what needs to be done.
Perhaps we will make the same interface to support declarative functions.
Error processing
Simple error handling is often found by developers and is usually quite simple. If you do not have complicated things, then in catch you catch an exercise and see what happened there, write to the log or show an error to the user. On the UI, you can easily do this.
In simple cases, everything is expected to be easy - error handling with corutins is done through try-catch-finally .
In production, in addition to simple cases, there are:
- nested try-catch ,
- Many different types of expressions ,
- Errors in the network or in business logic,
- User errors. He did something wrong again and is to blame for everything.
We must be ready for this.
There are 2 possible solutions: CoroutineExceptionHandler and the Result classes approach.
Coroutine Exception Handler
This is a special class for handling complex error cases. ExceptionHandler allows you to take as your argument the Exception as an error and handle it.
How do we usually handle complex errors?
The user clicked something, the button did not work. He needs to say what went wrong and direct it to a specific action: check the Internet, Wi-Fi, try it later or delete the application and never use it again. Say about this user can be quite simple:
val handler = CoroutineExceptionHandler(handler = { , error -> hideProgressDialog() val defaultErrorMsg = "Something went wrong" val errorMsg = when (error) { is ConnectionException -> userFriendlyErrorMessage(error, defaultErrorMsg) is HttpResponseException -> userFriendlyErrorMessage(Endpoint.EndpointType.ENDPOINT_SYNCPLICITY, error) is EncodingException -> "Failed to decode data, please try again" else -> defaultErrorMsg } Toast.makeText(context, errorMsg, Toast.LENGTH_SHORT).show() }) - Let's get the default message: “Something went wrong!” And analyze the exception.
- If it is ConnectionException, then we take a localized message from the resources: “Man, turn on Wi-Fi and your problems will go away. I guarantee it. ”
- If the server said something wrong , then you need to inform the client: “Go out and log in again”, or “Do not do it in Moscow, do it in another country”, or “Sorry, comrade. All I can do is just say that something went wrong. ”
- If this is a completely different error , for example, out of memory , we say: "Something went wrong, I'm sorry."
- All messages are output.
What you write to CoroutineExceptionHandler will run on the same Dispatcher where you run coruntine. So if you give the “launch” command to the UI, then everything happens on the UI. You do not need a separate dispatching, which is very convenient.
It’s easy to use:
launch(uiDispatcher + handler) { ... } There is a plus operator. In the Coroutine context add a handler and everything works, which is very convenient. We used it for a while.
Result classes
We later realized that a CoroutineExceptionHandler might be missing. The result, which is formed by the work of korutina, may consist of several data, of different parts or process several situations.
Result classes helps to cope with this problem:
sealed class Result { data class Success(val payload: String) : Result() data class Error(val exception: Exception) : Result() } - In your business logic, you get the Result class .
- Mark as sealed .
- Inherit from the class two other data classes: Success and Error .
- In Success, transfer your data that is formed as a result of performing corutina.
- In Error add exception.
Then you can implement the business logic as follows:
override suspend fun doTask(): Result = withContext(CommonPool) { if ( !isSessionValidForTask() ) { return@withContext Result.Error(Exception()) } … try { Result.Success(restApi.call()) } catch (e: Exception) { Result.Error(e) } } You call the Coroutine context - Coroutine builder withContex and you can handle different situations.
For example, a logged in user:
- We exit and say that this is an error. Let the logic above handle it.
- You can call RestApi or other business logic.
- If everything is fine, then Result.Success is returned .
- If an exception occurs, then Result.Error .
The approach allows you to delegate error handling somewhere further, although the ExceptionHandler does the same.
Result classes work, tests are convenient to write. We use Result classes, but you can use both ExceptionHandler and try-catch.
3. Testing
The last thing that worries us and prevents sleep well. If you are writing unit tests , then you are sure that everything is working correctly. With Corutin, we also want to write unit tests.
Let's see how to do it. Globally, in order to write unit-tests, we need to solve 2 problems:
- Replacing context . To be able to substitute the context in which everything happens;
- Mocking coroutines . To be able to mokirovat korutiny
Replacing context
So the presenter looks like:
val login() { launch(UI) { … } } For example, if in the login method you launch your coruntine, then it explicitly uses the UI context. This is not very good for tests, since one of the principles of application testing says that all dependencies must be explicitly passed to a method or class . Here the principle is not respected, so the code needs to be improved in order to write a unit-test.
The improvement is quite simple:
val login (val coroutineContext = UI) { launch(coroutineContext) { ... } } - In the login method, configure the transfer of coroutineContext. It is clear that in the code of your application you do not want to pass it everywhere explicitly. In Kotlin, you can simply write that it should be the default UI.
- Call your Coroutine builder with the Coroutine Contex that you pass to the method.
In the unit test, you can do the following:
fun testLogin() { val presenter = LoginPresenter () presenter.login(Unconfined) } - You can create your LoginPresenter and call the login method with some context, for example, with Unconfined.
- Unconfined reports that the quorutine will be launched on the stream that starts it. This allows one line to write tests and check the result.
Mocking coroutines
The next question is mocking a corutin. I recommend using Mockk for unit tests. This is a lightweight unit-testing framework specifically written in Kotlin, in which it is easy to work with Korutins. You can replace the suspend function or the coroutine with the help of the special function coEvery and instead of calling corutina, return an interesting business object.
Here, a login call instead of a cortina simply returns githubUser :
coEvery { apiClient.login(any()) } returns githubUser If you have Mockito-kotlin , then everything is a little more difficult - you will have to dance with a tambourine. Perhaps there is a more accurate way, but now we use this:
given { runBlocking { apiClient.login(any()) } }.willReturn (githubUser) We use just runBlocking . With the given block we do the same as in the previous example.
We can write a complete test on our presenter :
fun testLogin() { val githubUser = GithubUser('login') val presenter = LoginPresenter(mockApi) presenter.login (Unconfined) assertEquals(githubUser, presenter.user()) } - Prepare your business data, for example, GitHubUser .
- The LoginPresenter explicitly passes the dependency to our API, but now it will be locked. How do you mokiruete it up to you.
- Then call presenter.login with the Unconfined context and check that all the necessary data that we are expecting has been generated in the Presenter.
And that's it! Testing Korutin really easy.
Let's sum up
- Rx- . . , RxJava RxJava. - — , .
- . , . Unit- — , , , . — welcome!
- . , , , , . .
useful links
- , Android GDE Android Coroutine Recipes . , : lifeCircle, coroutineContexts, Coroutine builders .
- GitHub.
- Android Kotlin, , Codelab .
- . Twitter . Medium «» Android, async- .
news
30 Mail.ru . , .
AppsConf , .
, , , .
youtube- AppsConf 2018 — :)
Source: https://habr.com/ru/post/429908/
All Articles