MIT course "Computer Systems Security". Lecture 17: User Authentication, Part 1
Massachusetts Institute of Technology. Lecture course # 6.858. "Security of computer systems". Nikolai Zeldovich, James Mykens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security methods based on the latest scientific work. Topics include operating system (OS) security, capabilities, information flow control, language security, network protocols, hardware protection and security in web applications.
Lecture 1: "Introduction: threat models" Part 1 / Part 2 / Part 3
Lecture 2: "Control of hacker attacks" Part 1 / Part 2 / Part 3
Lecture 3: "Buffer overflow: exploits and protection" Part 1 / Part 2 / Part 3
Lecture 4: "Separation of privileges" Part 1 / Part 2 / Part 3
Lecture 5: "Where Security Errors Come From" Part 1 / Part 2
Lecture 6: "Opportunities" Part 1 / Part 2 / Part 3
Lecture 7: "Sandbox Native Client" Part 1 / Part 2 / Part 3
Lecture 8: "Model of network security" Part 1 / Part 2 / Part 3
Lecture 9: "Web Application Security" Part 1 / Part 2 / Part 3
Lecture 10: "Symbolic execution" Part 1 / Part 2 / Part 3
Lecture 11: "Ur / Web programming language" Part 1 / Part 2 / Part 3
Lecture 12: "Network Security" Part 1 / Part 2 / Part 3
Lecture 13: "Network Protocols" Part 1 / Part 2 / Part 3
Lecture 14: "SSL and HTTPS" Part 1 / Part 2 / Part 3
Lecture 15: "Medical Software" Part 1 / Part 2 / Part 3
Lecture 16: "Attacks through the side channel" Part 1 / Part 2 / Part 3
Lecture 17: "User Authentication" Part 1 / Part 2 / Part 3
So let's get started. With the return of you, I hope the holidays for all have gone right. Today we will talk about user authentication. So, the topic of the lecture is to find out how users can prove their identity to the program? In particular, the article that is intended for today's occupation affects the very foundations of the existence of the security community. Is there anything better to authenticate than passwords?
')

At the highest level, it seems that passwords are a terrible idea, because they have very low entropy and it is easy for attackers to solve them. The secret questions that we use to recover forgotten passwords have even less entropy than the passwords themselves, and this also seems to be a problem.
And even worse, users will usually use the same password on many different sites. This means that a vulnerability in one easily guessed password endangers the user experience with many sites.
I liked the following quote from the article for today's lecture: “the continued dominance of passwords among all other ways to authenticate a user is a major challenge for security research.” Thus, the security community wants an alternative better than passwords. However, it is unclear whether there is in fact an authentication scheme that can completely replace passwords, while being more convenient, more widely applicable and more secure.
Today we will look at three questions. First, we will look at how existing passwords work. After that, we’ll talk about the global desired password properties for any authentication scheme. Finally, we will look at what is written in the lecture article on indicators, or authentication characteristics, and see how some other authentication schemes are compared in terms of efficiency with passwords.

So what is a password? The password is a shared secret for the user and the server. Thus, a primitive password scheme implementation should basically just have a table on the server side that matches usernames with their passwords.
This is the easiest way to imagine the implementation of one of the authentication schemes - the user enters his name and password, the server searches for them in this table, compares the password with the name, and if everything matches, the user is authenticated. It is clear that the problem is that if the attacker hacks the server, he can simply look at this table and take over all the passwords. So this is clearly a bad thing.
Perhaps a solution to this problem is to store the server with a table that looks like this: the username does not correspond to the password itself, but to its hash. In this case, the user enters the password in plain text, the server checks its hash code and compares it with the value in the table. The advantage of this scheme is that these hash functions are designed in such a way that the hash is difficult to invert into the password. If this table is lost, there is a data leak, or the attacker hacked the server and took possession of it, he will see strings of random alphanumeric characters instead of text passwords and it will be difficult for him to restore their original image.
At least in theory, using hashes is a pretty good thing. But now, in practice, attackers will not have to use a brute-force attack to determine the prototype of the hash value.

Attackers can actually take advantage of the fact that in practice passwords have an uneven distribution. And by uneven distribution, I mean ... let's say we know that all passwords are up to 20 characters long. In practice, users do not use this entire range, preferring passwords like 123, todd or something like that. However, empirical studies have shown how such passwords work, and it was found that about 20% of users use the 5000 most popular passwords. In other words, this means that if an attacker has a database of these 5000 passwords, he can easily hash them and then, when viewing a stolen password table, simply match the hashes. So empirically, the hacker will be able to recover about 20% of the passwords in the server table.
Yahoo experts found that passwords contain from 10 to 20 bits of entropy, 10-20 bits of randomness. In fact, it is not so much. If we consider the complexity of creating a hash function, then modern machines calculate millions of such hashes every second. Thus, the hash function in its design must be easily computed so that computers can easily hash passwords. However, the combination of this fact with insufficient randomness of passwords means that, in principle, this scheme is not as secure as it seems.
There is a thing with which you can try to make life difficult for a hacker - this is a complex function of key formation. In this case, I mean that the password hash is used as the source data, on the basis of which the server generates a key that is stored on the server.

What is good about these key generation functions is that they have customizable complexity, that is, you can turn a certain knob and make this function run slower or faster depending on how much you want to save on process performance.
Suppose you want to form a key. As an example, the standard key generation PBKDF2 or, perhaps, BCrypt, you can learn more about them from the Internet. Let's imagine that one of these key generation functions took a whole second to calculate, rather than a few milliseconds. In fact, it will make the attacker’s work much more difficult, because trying to generate values for 5000 top-level passwords will take much longer.
At the internal level, these key generation functions often work by repeatedly calling the hash, accessing it many times, so everything is pretty simple. But does the use of the time consuming key generation process solve the security problem we face? The answer is no, because one of the problems is that the adversary can build something called the Rainbow tables, or "rainbow tables." The “rainbow table” is simply a password-to-hash map. Thus, even if the system uses one of these expensive key generation functions, an attacker can one time calculate one of these tables. This can be a bit tricky, because processing each key generation function is quite a slow thing, but an attacker can create this table once and then use it to hack all subsequent systems based on the same key generation function algorithms. This is how these "rainbow tables" work.
I repeat once again - in order to maximize the economic benefits of creating the Rainbow table, an attacker can take advantage of the uneven distribution of passwords, which I mentioned earlier. Thus, an attacker can build such a table only for some small set of all possible passwords.
Student: probably, “salting” makes it much more difficult?
Professor: yes, yes, exactly. We will go to the "pickles" in a couple of seconds. In general, if you do not use salting, rainbow tables allow an attacker, by making some effort offline, to calculate this table, and then get the benefit of being able to calculate basic passwords based on the work done.
The next thing to think about in order to improve the situation is salting. How does it work? The basic principle is to introduce some additional randomness into the password generation method. You take this hash function, put the “salt” in there, and then the password, and this is all stored in a table on the server.

What is the "salt"? This is just a long string representing the first part of this hash function. So why is it better to use this scheme? Note that the “salt” is actually stored in cleartext on the server side. You might think: Well, if this “salt” is stored in clear text on the server side and the attacker can steal the table of correspondence between usernames and passwords, so why can't he at the same time steal this “salt”? What is the use of such a decision?
Student: because if you choose the most common password, you cannot simply use it once and find a new user.
Professor: quite right. Basically what “salt” does is that it prevents the attacker from creating a single “rainbow table” that could be used against all hashes. In principle, you can consider “salt” a way to make even identical passwords unique. In practice, many systems use the concept of salting.
In fact, the “salt” makes it possible to add as many bits as possible to this pseudo-password, since the more bits the better. What else needs to be done is to take into account that every time a user changes his password, the “salt” also needs to be changed. Because one of the reasons for this decision is laziness of users who want to use the same password several times. Changing the “salt” will ensure that the thing that is stored in the password database is actually different even if one password is replaced with the exact same password.
Audience: why is it called "salt"?
Professor: This is a good question, and I cannot answer it for sure. However, I am sure that there is some justification for this. Why are cookies called cookies? The Internet probably knows why, but I do not know.
Student: perhaps because “salt” adds a bit of “taste” to the hash?
Professor: Well, I'm glad that we are shooting this on video, because we obviously have a chance to get a film award. I am sure that there is some answer on the Internet, so I will look for it later.
So, the approaches discussed above are quite simple. I assumed that the user somehow passes the password to the server, but did not specify how this happens. So how do we transfer these passwords?
First, you can simply send the password over the network in clear text. This is bad, because there may be an attacker on the network who monitors the traffic you send. He can simply assign a password and impersonate you.
Therefore, we always start with one straw man, before I show you other straw men, who, of course, are also fatally flawed. So the first thing you might think about is sending the password in clear text. From a security point of view, it is much better to send a password through an encrypted connection, so we use cryptography. It is possible that we have some kind of secret key used to convert the password before sending it over the network. So at the highest level, it seems that encryption always makes things better, like a trademark guaranteeing product quality.
But the problem is that if you don’t think carefully about how to use encryption and hashing, you cannot take advantage of the security benefits that you rely on. For example, if there is someone who sits between you - the user and the server, this notorious attacker, the "man in the middle", who actually monitors your traffic while pretending to be a server.
If you send encrypted data without authenticating the other party, you may run into a problem. Because the client simply chooses a random key and sends it to some addressee on the other side, which may or may not be the server.
In fact, you send something to a certain person, who after that will get the opportunity to take possession of all your secrets.
Given this, people may think that it is much better not to send the password itself, but its hash. In fact, this in itself does not give you anything, because whether you send a password or a password hash, this password hash has the same semantic power as the original password, and it will not help you if you have not authenticated the server.
So the main point is that simply adding encryption or just adding hashing does not necessarily give you any additional security benefits. If the client cannot authenticate the person to whom he or she sends the password, the client may mistakenly disclose the password to the person who does not intend to disclose it.
Therefore, perhaps a better idea than the previous two, is to use the so-called "call / answer" protocol, or the challenge / response protocol. Here is an example of a very simple call / response protocol. Here we have a client, and here we have a server. The client says to the server: “Hello, I’m Alice”, after which the server answers it with some call C. Then the client is going to answer with the hash of this call sent by the server, combining it with a password.

The server knows the answer, so at the moment the server can accept this sequence — the client’s response. The server also knows the challenge it has sent, and presumably knows the password, so the server can calculate the value of the received hash and see that it actually corresponds to the one sent by the user.
The positive feature of this protocol, if we ignore the existence of a “man in the middle” for a second, is that the server will be sure that the user is really Alice, because only Alice will know this password. At the same time, if Alice sends this thing not to the server, but to a person who pretended to be a server, he will not know the password. Because the attacker can use C, but he still does not know the password, but in order to find out the password, he needs to invert this hash function again. Do you have any questions?
Student: can the client, instead of sending the password to the server and receiving a hashed server call, simply send the hashed password to the server?
Professor: so you ask why the client simply does not send the hashed password to the server? There are 2 reasons for this. We will discuss one later, it is called Antihammering protection and is designed to defend against “bad” customers who constantly ask: “is this a password, or is this a password, maybe this is a password?”. This authentication mechanism simplifies the process for both the server and the client, but you can, in fact, create a hash on the client side using JavaScript or something like that. But the basic idea is that somehow you must ensure the maximum complexity of authentication in order to prevent the attacker from quickly guessing the password. More questions?

Student: I just wanted to point out that even if a client does hashing, then if someone takes possession of the server table and uses it for hashing, he will be able to log into the network.
Professor: quite right. Yes, it becomes a bit dangerous depending on who can take control of this challenge C. Because if the client and the server can choose the values of this C, it makes it difficult for the client to organize such attacks. One of the problems with using this protocol is that the client is not able to randomly enter this HCC value. You can imagine that you can make this protocol more difficult to invert with the server if the client is able to select some call C in the HCC part, but in this case there will be an opposing call to the client and server.
If there are no more questions, we will assume that we have finished the discussion of the mechanisms for transferring the password from the client to the server. Despite the fact that the server must invert the hash and password received from the client, an attacker can still try to conduct an attack using brute-force, and you can only protect the server from attacks of this kind using one of these expensive hash functions that we discussed earlier .
One more thing, as we just said, is that you can really let a customer pick their own call at the HCC. In fact, it will act as if the client used salt. This will make it harder for a hacker to create a “rainbow table”.
Therefore, note that if the hacker is on the server side and the server chooses the same value C again, again and again, this allows the attacker to create a “rainbow table”. But if the client “salted” his answer to the server, it would be very difficult to create a “rainbow table”.
Above, I mentioned Antihammer protection - it was designed to limit the number of guessing attempts, or password guessing. The idea here is that if you have clients who are trying to organize a brute-force attack by speeding through passwords, you do not want to give them that opportunity. One of the ways we can provide protection to Antihammer is simply to limit the speed so that we assume the server says, "I will only accept three passwords per second from any particular user."

Here you can also mention the use of time-out, which does not allow the client to make several attempts to enter a password in a row. , 10 , : « 10 , ». . «» , TPN . ? – , , , .
, , , - . , , - , , . – . , , .
, — , , — . , , . , . , , .
, , , Dictionary attack, « ». , , Microsoft Telepathwords. . , , , Telepathwords , . , , , , .
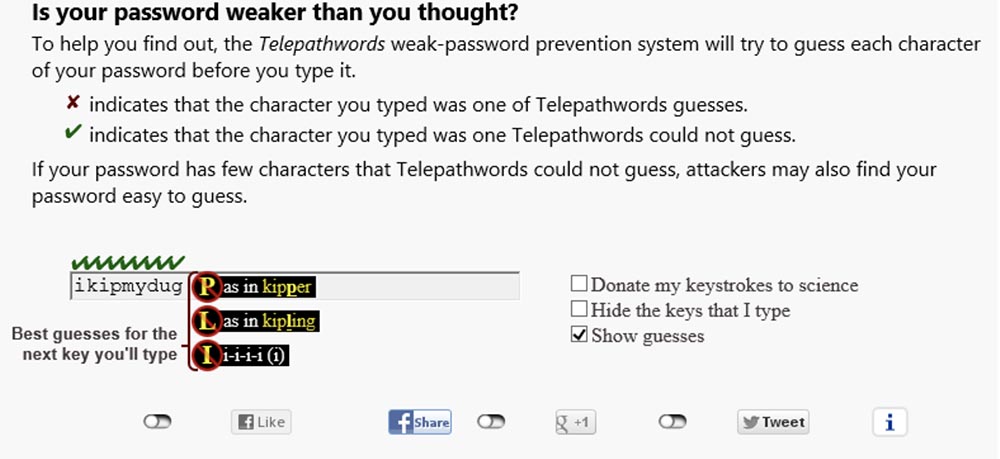
«», , , , , «».

«» , . Telepathwords? , , . , .

, . , , . , .
, Telepathwords , , , , , . .
, — , , , .
: , , IP- , Antihammer .
: , . Antihammer IP-, , . , Antihammer , – . , Antihammer , , , , , , .
, . , . , .
: Antihammer? , , ? , , SRP Zero Knowledge Protocol, ZKP, …
: , ?
: ?
:Yes, they are used. These protocols provide stronger encryption guarantees. In most cases, they are not backward compatible with current systems, so in practice you don’t notice how often they are used. But there are some protocols that allow the server to not know at all what the password is, such as ZKP, which are actually used in practice.
27:20 min.
Course MIT "Computer Systems Security". Lecture 17: User Authentication, Part 2
Full version of the course is available here .
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until December for free if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?
Source: https://habr.com/ru/post/429680/
All Articles