Dump, extract: the architecture of complex chat bots
Users, having communicated with smart voice assistants, wait for intelligence from chatbots. If you are developing a bot for business, the expectations are even higher: the customer wants the user to follow the necessary, pre-written script, and the user wants the robot to answer the questions posed sensibly and preferably with human language, help solve problems, and sometimes just support small talk.
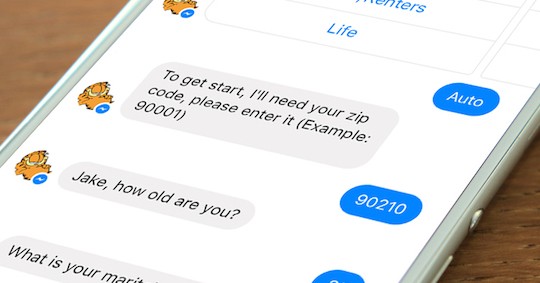
We do English-speaking chat bots that communicate with users through different channels - Facebook Messenger, SMS, Amazon Alexa and the web. Our bots replace support services, insurance agents, and be able to just chat. Each of these tasks requires its own approach to development.
In this article we will describe what modules our service consists of, how each one is made, what approach we have chosen and why. We share our experience analyzing different tools: when generative neural networks are not the best choice, why instead of Doc2vec we use Word2vec, what is the charm and horror of ChatScript, and so on.
')
At first glance it may seem that the problems that we solve are rather trivial. However, in the field of Natural Language Processing there are a number of difficulties associated with both the technical implementation and the human factor.

These are just a few of the most obvious aspects, but there is also slang, jargon, humor, sarcasm, spelling and pronunciation errors, abbreviations and other points that make it difficult to work in this area.
To solve these problems, we developed a bot that uses a set of approaches. The AI part of our system consists of a dialog manager, recognition service and important complex microservices that solve specific problems: Intent Classifier, FAQ-service, Small Talk.
The task of the Dialog Manager in the bot is a software simulation of communication with a live agent: he must guide the user through a conversation scenario to some useful goal.
To do this, firstly, find out what the user wants (for example, calculate the cost of insurance for cars), secondly, find out the necessary information (address and other user data, data about drivers and cars). After that, the service should give a useful answer - fill out the form and give the client the result of this data. However, we should not ask the user about what he has already indicated earlier.
Dialog Manager allows you to create such a scenario: to describe programmatically, to build from small bricks - specific questions or actions that should occur at a certain moment. In fact, the scenario is a directed graph, where each node is a message, a question, an action, and an edge determines the order and conditions for switching between these nodes if there is a multiple choice of switching from one node to another.
Basic node types
If the node is closed, the control will not be transferred to it again, and the user will not see the question that has already been asked. Thus, if we perform a depth-first search on such a column to the first open node, we will receive a question that must be asked to the user at a given point in time. Alternately answering the questions that Dialog Manager generates, the user gradually closes all the nodes in the graph, and it will be considered that he executed the prescribed script. Then we, for example, give the user a description of the insurance options that we can offer.

Suppose we ask the user a name, and he will also give out his date of birth, name, gender, marital status, address, or send a photo of his driver’s license in one message. The system will extract all relevant data and close the corresponding nodes, that is, questions about the date of birth and gender will no longer be asked.
Also in Dialog Manager implemented the ability to simultaneously communicate on several topics. For example, the user says: "I want to get insurance." Then, without completing this dialogue, he adds: "I want to make a payment on a previously attached policy." In such cases, Dialog Manager saves the context of the first topic, and after completing the second scenario, offers to resume the previous dialogue from the place where it was interrupted.
There is an opportunity to return to questions that the user has already answered earlier. To do this, the system saves a snapshot of the graph when receiving each message from the client.
In addition to ours, we considered another AI approach to implementing the dialog manager: the user's intention and parameters are sent to the input of the neural network, and the system itself generates the corresponding states, the next question to be asked. However, in practice this method requires the addition of the rule based approach. Perhaps such an implementation option is suitable for trivial scenarios - for example, for ordering food, where you need to get only three parameters: what the user wants to order, when he wants to receive the order and where to bring it. But in the case of complex scenarios, as in our subject area, this is still unattainable. At the moment, machine learning technologies are not able to qualitatively guide the user to the target in a complex scenario.
Dialog Manager is written in the Python, Tornado framework, because initially our AI part was written as a single service. A language was chosen in which all this can be implemented without spending resources on communication.
Our product is able to communicate through different channels, but the AI part is completely client independent: this communication only comes in the form of proxied text. The dialog manager conveys the user's context, response and collected data to the Recognition Service, which is responsible for recognizing the user's intentions and extracting the necessary data.
Today, the Recognition Service consists of two logical parts: the Recognition Manager, which manages the recognition pipeline, and the extractors.
Recognition Manager is responsible for all the basic stages of speech sense recognition: tokenization, lemmatization, etc. It also determines the order of extractors (objects that recognize entities and signs in texts) by which a message will be skipped, and decides when it is necessary to stop recognition and return finished result. This allows you to run only the necessary extractors in the most expected order.
If we asked what the name of the user is, then it is logical to check whether the name came in the answer. The name has come, and there is no more useful text - it means that recognition can be completed at this step. Some more useful entities have come, which means that recognition needs to be continued. Most likely, the person added some more personal data - respectively, you need to run the personal data processing extractor.
Depending on the context, the order in which the extractors are started may vary. This approach allows us to significantly reduce the load on the entire service.
As mentioned above, extractors are able to recognize certain entities and characteristics in texts. For example, one extractor recognizes phone numbers; the other determines whether the person answered the question positively or negatively; the third one recognizes and verifies the address in the message; the fourth is the user's vehicle data. Passing a message through a set of extractors is the process of recognizing our incoming messages.
For optimal performance of any complex system, it is necessary to combine approaches. We followed this principle when working on extractors. I will highlight some of the principles of work that we used in extractors.
Using our own microservices with Machine Learning inside (extractors send a message to this service, sometimes supplement it with the information they have and return the result).
We looked at the NLTK, Stanford CoreNLP and SpaCy libraries. NLTK is the first Google issue when you start a NLP survey. It is very cool for prototyping solutions, has extensive functionality and is quite simple. But its performance leaves much to be desired.
The Stanford CoreNLP has a serious disadvantage: it pulls the Java virtual machine with very large modules, built-in libraries, and consumes a lot of resources. In addition, the output from this library is difficult to customize.
As a result, we stopped at SpaCy, because it has enough functionality for us and has an optimal balance of lightness and speed. The SpaCy library is dozens of times faster than the NLTK and offers much better dictionaries. However, it is much easier than Stanford CoreNLP.
At the moment we use spaCy for tokenization, vectorization of the message (using the built-in trained neural network), primary recognition of parameters from the text. Since the library covers only 5% of our recognition needs, we had to add a lot of functions.
Recognition Service was not always a two-part structure. The first version was the most trivial: we in turn used different extractors and tried to understand if there were any particular parameters or intentions in the text. The AI did not even smell there - it was a completely rule based approach. The difficulty was that the same intention could be expressed in a mass of ways, each of which should be described in the rules. At the same time, it is necessary to take into account the context, since the same user phrase, depending on the question posed, may require different actions. For example, from the dialogue: “Are you married?” - “Already two years” it can be understood that the user is married (boolean value). And from the dialogue “How long do you drive this car?” - “For two years already”, you need to extract the value “2 years”.
From the very beginning, we understood that the support of a rule based solution would require great efforts, and with an increase in the number of supported intentions, the number of rules will increase much faster than in the case of an ML-based system. However, a business point of view. we needed to launch MVP, a rule based approach allowed us to do this quickly. Therefore, we used it, and in parallel we worked on the ML-model of intent recognition. As soon as she appeared and began to give satisfactory results, the rule-based approach slowly began to depart.
For most cases of information extraction, we used ChatScript. This technology provides its own declarative language that allows you to write templates for extracting data from natural language. Thanks to WordNet under the hood, this solution is very powerful (for example, you can specify “color” in the recognition pattern, and WordNet recognizes any narrowing concept, such as “red”). We did not see any analogs at that time. But ChatScript is written very crookedly and buggy, with its use it is almost impossible to implement complex logic.
As a result, the disadvantages outweighed, and we abandoned ChatScript in favor of NLP libraries in Python.
In the first version of Recognition Service, we came up against the ceiling for flexibility. The introduction of each new feature greatly slowed down the whole system.
So we decided to completely rewrite the Recognition Service, dividing it into two logical parts: small, lightweight extractors and Recognition Manager, which will manage the process.
In order for a bot to communicate adequately - to provide the necessary information on request and to fix the user's data - it is necessary to determine the user's intention (intent) based on the text sent to them. The list of intents, according to which we can interact with users, is limited to the client’s business objectives: it may be the intention to find out the conditions of insurance, fill in data about yourself, get an answer to a frequently asked question, and so on.
There are many approaches to classification of intents based on neural networks, in particular, on recurrent LSTM / GRU. They have proven themselves in recent studies, but they have a common drawback: a very large sample is required for correct operation. On a small amount of data, such neural networks are either difficult to train, or they produce unsatisfactory results. The same applies to the Fast Text framework from Facebook (we looked at it as this is a state-of-the-art solution for handling short and medium phrases).
Our training samples are very high-quality: a dataset is made up of a full-time team of linguists who are proficient in English and know the specifics of the insurance field. However, our samples are relatively small. We tried to dilute them with public data, but those, with rare exceptions, did not match our specifics. We also tried to attract freelancers with Amazon Mechanical Turk, but this method also turned out to be inoperative: the data they sent was partially poor quality, the samples had to be completely rechecked.
Therefore, we were looking for a solution that would work on a small sample. A good quality of data processing was demonstrated by the Random Forest classifier trained on data that was converted into vectors of our bag-of-words model. With the help of cross-validation, we have selected the optimal parameters. Among the advantages of our model are speed and size, as well as relative ease of deployment and additional training.
In the process of working on the Intent Classifier, it became clear that for some tasks its use is not optimal. Suppose the user wants to change the name specified in the insurance, or the car number. That the qualifier correctly defined this intention, it would be necessary to manually add to the template all the phrases used in this case. We found another way: to make a small extractor for the Recognition Service, which defines intent by keywords and NLP methods, and to use the Intent Classifier for non-sample phrases in which the keyword method does not work.
Many of our clients have sections with FAQ. In order for the user to receive such answers directly from the chat bot, it was necessary to provide a solution that would (a) recognize the FAQ query; b) would find the most relevant answer in our database and give it out.
There are a number of models trained on SQUAD from Stanford. They work well when the response text from the FAQ contains the words from the user's question. Suppose the FAQ says: "Frodo said that he would take the Ring to Mordor, although he did not know the way there." If the user asks: “Where does Frodo put the Ring?”, The system will respond: “To Mordor”.
Our script, as a rule, was different. For example, a bot should respond differently to two similar requests - “Can I pay?” And “Can I pay online?”: In the first case, you can offer a form of payment to a person, in the second case, you can pay online, here’s the page address.
Another class of solutions for assessing the similarity of documents is focused on long answers - at least a few sentences, among which contains information that interests the user. Unfortunately, in cases with short questions and answers (“How do I pay online?” - “You can pay with PayPal”), they are very unstable.
Another solution is the Doc2vec approach: the large text is distilled into a vector representation, which is then compared with other documents in the same form and reveals the coefficient of similarity. This approach also had to be put aside: it is focused on long texts, but we mainly deal with questions and answers from one or two sentences.
Our decision was based on two steps. First: we, using embeddings, translated into vectors each word in the sentence, using the Google Word2vec model. After that, we considered the average vector over all words, representing one sentence as one vector. The second step we took the question vector and found in the FAQ database stored in the same vector form, the closest answer to a certain extent, in our case cosine.
The advantages include ease of implementation, very easy extensibility and fairly simple interpretability. The disadvantages are weak optimization possibilities: this model is difficult to refine - it either works well in most of your use cases, or you have to give it up.
Sometimes the user writes something absolutely irrelevant, for example: "The weather is good today." This is not included in the list of interests we are interested in, but we still want to respond intelligently, demonstrating the intelligence of our system.
For such solutions, a combination of the approaches described above is used: they are based on either very simple rule based solutions or generative neural networks. We wanted to get a prototype early, so we took a public dataset from the Internet and used an approach very similar to the one used for the FAQ. For example, a user has written something about the weather — and using an algorithm comparing the vector representations of two sentences for a certain cosine measure, we are looking for a proposal in a public dataset that will be as close as possible to the subject of the weather.
Now we have no goal to create a bot that would learn from every message received from customers: first, experience shows that this is the way to death of the bot (recall how IBM Watson had to erase the database , because it began to diagnose with , and Microsoft's Twitter-bot managed to become a racist in just a day). Secondly, we strive to close the tasks of insurance companies as best we can; self-learning bot is not our business task. We have written a number of tools for linguists and QA-teams, with which they can manually train bots, exploring dialogs and correspondence with users during post-moderation.
However, our bot seems to be ready to pass the Turing test. Some users start a serious conversation with him, believing that they are communicating with an insurance agent, and one even started threatening the chief with a complaint when the bot misunderstood him.
Now we are working on the visual part: the display of the entire graph of the script and the ability to compose it using the GUI.
On the part of the Recognition Service, we implement linguistic analysis to recognize and understand the meaning of each word in the message. This will improve the accuracy of the reaction and extract additional data. For example, if a person fills in a car insurance and mentions that he has an uninsured house, the bot will be able to remember this message and give it to the operator to contact the client and offer home insurance.
Another feature in the work - processing feedback. After the completion of the dialogue with the bot, we ask the user whether the service pleased him. If Sentiment Analysis recognized the user feedback as positive, we offer the user to share opinions in social networks. If the analysis shows that the user has reacted negatively, the bot clarifies what was wrong, fixes the answer, says: “Okay, we will correct” - and does not offer to share the feedback in the tape.
One of the keys to making communication with the bot as natural as possible is to make the bot modular, to expand the set of reactions available to it. We are working on it. Maybe thanks to this, the user was ready to sincerely accept our bot as an insurance agent. The next step: to make the person try to announce the bot thanks.
The article was written together with Sergey Kondratyuk and Mikhail Kazakov . Write in the comments your questions, we will prepare more practical materials on them.
We do English-speaking chat bots that communicate with users through different channels - Facebook Messenger, SMS, Amazon Alexa and the web. Our bots replace support services, insurance agents, and be able to just chat. Each of these tasks requires its own approach to development.
In this article we will describe what modules our service consists of, how each one is made, what approach we have chosen and why. We share our experience analyzing different tools: when generative neural networks are not the best choice, why instead of Doc2vec we use Word2vec, what is the charm and horror of ChatScript, and so on.
')
At first glance it may seem that the problems that we solve are rather trivial. However, in the field of Natural Language Processing there are a number of difficulties associated with both the technical implementation and the human factor.
- A billion people speak English, and each speaker uses it in his own way: there are different dialects, individual features of speech.
- Many words, phrases and expressions are ambiguous: a typical example is in this picture.
- Context is necessary for the correct interpretation of the meaning of words. However, the bot that asks the client clarifying questions is not as cool as the one that can switch to any topic as desired by the user and answer any question.
- Often, in lively speech and correspondence, people either neglect the rules of grammar, or respond so briefly that it is almost impossible to restore the structure of the sentence.
- Sometimes in order to answer a user's question, it is necessary to verify his request with the texts of the FAQ. At the same time, you need to make sure that the text found in the FAQ is really the answer, and not just contains several words that match the query.
These are just a few of the most obvious aspects, but there is also slang, jargon, humor, sarcasm, spelling and pronunciation errors, abbreviations and other points that make it difficult to work in this area.
To solve these problems, we developed a bot that uses a set of approaches. The AI part of our system consists of a dialog manager, recognition service and important complex microservices that solve specific problems: Intent Classifier, FAQ-service, Small Talk.
Start a conversation. Dialog Manager
The task of the Dialog Manager in the bot is a software simulation of communication with a live agent: he must guide the user through a conversation scenario to some useful goal.
To do this, firstly, find out what the user wants (for example, calculate the cost of insurance for cars), secondly, find out the necessary information (address and other user data, data about drivers and cars). After that, the service should give a useful answer - fill out the form and give the client the result of this data. However, we should not ask the user about what he has already indicated earlier.
Dialog Manager allows you to create such a scenario: to describe programmatically, to build from small bricks - specific questions or actions that should occur at a certain moment. In fact, the scenario is a directed graph, where each node is a message, a question, an action, and an edge determines the order and conditions for switching between these nodes if there is a multiple choice of switching from one node to another.
Basic node types
- Nodes that are waiting until the queue reaches them and they appear in the messages.
- Nodes waiting until the user shows a certain intention (for example, he writes: “I want to get insurance”).
- Nodes awaiting data from the user to validate and save them.
- Nodes for the implementation of various algorithmic constructions (cycles, branching, etc.).
If the node is closed, the control will not be transferred to it again, and the user will not see the question that has already been asked. Thus, if we perform a depth-first search on such a column to the first open node, we will receive a question that must be asked to the user at a given point in time. Alternately answering the questions that Dialog Manager generates, the user gradually closes all the nodes in the graph, and it will be considered that he executed the prescribed script. Then we, for example, give the user a description of the insurance options that we can offer.
“I've already said everything!”
Suppose we ask the user a name, and he will also give out his date of birth, name, gender, marital status, address, or send a photo of his driver’s license in one message. The system will extract all relevant data and close the corresponding nodes, that is, questions about the date of birth and gender will no longer be asked.
"And by the way ..."
Also in Dialog Manager implemented the ability to simultaneously communicate on several topics. For example, the user says: "I want to get insurance." Then, without completing this dialogue, he adds: "I want to make a payment on a previously attached policy." In such cases, Dialog Manager saves the context of the first topic, and after completing the second scenario, offers to resume the previous dialogue from the place where it was interrupted.
There is an opportunity to return to questions that the user has already answered earlier. To do this, the system saves a snapshot of the graph when receiving each message from the client.
What options?
In addition to ours, we considered another AI approach to implementing the dialog manager: the user's intention and parameters are sent to the input of the neural network, and the system itself generates the corresponding states, the next question to be asked. However, in practice this method requires the addition of the rule based approach. Perhaps such an implementation option is suitable for trivial scenarios - for example, for ordering food, where you need to get only three parameters: what the user wants to order, when he wants to receive the order and where to bring it. But in the case of complex scenarios, as in our subject area, this is still unattainable. At the moment, machine learning technologies are not able to qualitatively guide the user to the target in a complex scenario.
Dialog Manager is written in the Python, Tornado framework, because initially our AI part was written as a single service. A language was chosen in which all this can be implemented without spending resources on communication.
"Let's decide." Recognition Service
Our product is able to communicate through different channels, but the AI part is completely client independent: this communication only comes in the form of proxied text. The dialog manager conveys the user's context, response and collected data to the Recognition Service, which is responsible for recognizing the user's intentions and extracting the necessary data.
Today, the Recognition Service consists of two logical parts: the Recognition Manager, which manages the recognition pipeline, and the extractors.
Recognition Manager
Recognition Manager is responsible for all the basic stages of speech sense recognition: tokenization, lemmatization, etc. It also determines the order of extractors (objects that recognize entities and signs in texts) by which a message will be skipped, and decides when it is necessary to stop recognition and return finished result. This allows you to run only the necessary extractors in the most expected order.
If we asked what the name of the user is, then it is logical to check whether the name came in the answer. The name has come, and there is no more useful text - it means that recognition can be completed at this step. Some more useful entities have come, which means that recognition needs to be continued. Most likely, the person added some more personal data - respectively, you need to run the personal data processing extractor.
Depending on the context, the order in which the extractors are started may vary. This approach allows us to significantly reduce the load on the entire service.
Extractors
As mentioned above, extractors are able to recognize certain entities and characteristics in texts. For example, one extractor recognizes phone numbers; the other determines whether the person answered the question positively or negatively; the third one recognizes and verifies the address in the message; the fourth is the user's vehicle data. Passing a message through a set of extractors is the process of recognizing our incoming messages.
For optimal performance of any complex system, it is necessary to combine approaches. We followed this principle when working on extractors. I will highlight some of the principles of work that we used in extractors.
Using our own microservices with Machine Learning inside (extractors send a message to this service, sometimes supplement it with the information they have and return the result).
- Using POS tagging, Syntactic parsing, Semantic parsing (for example, determining the user's intent by verb)
- Using full-text search (can be used to find the make and model of the car in the messages)
- Using regular expressions and response patterns
- Using third-party APIs (such as the Google Maps API, SmartyStreets, etc.)
- A verbatim search for sentences (if the person answered “yep” shortly, then there is no point in passing it through the ML algorithms to search for intent).
- We also use ready-made natural language processing solutions in extractors.
What options?
We looked at the NLTK, Stanford CoreNLP and SpaCy libraries. NLTK is the first Google issue when you start a NLP survey. It is very cool for prototyping solutions, has extensive functionality and is quite simple. But its performance leaves much to be desired.
The Stanford CoreNLP has a serious disadvantage: it pulls the Java virtual machine with very large modules, built-in libraries, and consumes a lot of resources. In addition, the output from this library is difficult to customize.
As a result, we stopped at SpaCy, because it has enough functionality for us and has an optimal balance of lightness and speed. The SpaCy library is dozens of times faster than the NLTK and offers much better dictionaries. However, it is much easier than Stanford CoreNLP.
At the moment we use spaCy for tokenization, vectorization of the message (using the built-in trained neural network), primary recognition of parameters from the text. Since the library covers only 5% of our recognition needs, we had to add a lot of functions.
"It used to be like that ..."
Recognition Service was not always a two-part structure. The first version was the most trivial: we in turn used different extractors and tried to understand if there were any particular parameters or intentions in the text. The AI did not even smell there - it was a completely rule based approach. The difficulty was that the same intention could be expressed in a mass of ways, each of which should be described in the rules. At the same time, it is necessary to take into account the context, since the same user phrase, depending on the question posed, may require different actions. For example, from the dialogue: “Are you married?” - “Already two years” it can be understood that the user is married (boolean value). And from the dialogue “How long do you drive this car?” - “For two years already”, you need to extract the value “2 years”.
From the very beginning, we understood that the support of a rule based solution would require great efforts, and with an increase in the number of supported intentions, the number of rules will increase much faster than in the case of an ML-based system. However, a business point of view. we needed to launch MVP, a rule based approach allowed us to do this quickly. Therefore, we used it, and in parallel we worked on the ML-model of intent recognition. As soon as she appeared and began to give satisfactory results, the rule-based approach slowly began to depart.
For most cases of information extraction, we used ChatScript. This technology provides its own declarative language that allows you to write templates for extracting data from natural language. Thanks to WordNet under the hood, this solution is very powerful (for example, you can specify “color” in the recognition pattern, and WordNet recognizes any narrowing concept, such as “red”). We did not see any analogs at that time. But ChatScript is written very crookedly and buggy, with its use it is almost impossible to implement complex logic.
As a result, the disadvantages outweighed, and we abandoned ChatScript in favor of NLP libraries in Python.
In the first version of Recognition Service, we came up against the ceiling for flexibility. The introduction of each new feature greatly slowed down the whole system.
So we decided to completely rewrite the Recognition Service, dividing it into two logical parts: small, lightweight extractors and Recognition Manager, which will manage the process.
"What do you want?". Intent Classifier
In order for a bot to communicate adequately - to provide the necessary information on request and to fix the user's data - it is necessary to determine the user's intention (intent) based on the text sent to them. The list of intents, according to which we can interact with users, is limited to the client’s business objectives: it may be the intention to find out the conditions of insurance, fill in data about yourself, get an answer to a frequently asked question, and so on.
There are many approaches to classification of intents based on neural networks, in particular, on recurrent LSTM / GRU. They have proven themselves in recent studies, but they have a common drawback: a very large sample is required for correct operation. On a small amount of data, such neural networks are either difficult to train, or they produce unsatisfactory results. The same applies to the Fast Text framework from Facebook (we looked at it as this is a state-of-the-art solution for handling short and medium phrases).
Our training samples are very high-quality: a dataset is made up of a full-time team of linguists who are proficient in English and know the specifics of the insurance field. However, our samples are relatively small. We tried to dilute them with public data, but those, with rare exceptions, did not match our specifics. We also tried to attract freelancers with Amazon Mechanical Turk, but this method also turned out to be inoperative: the data they sent was partially poor quality, the samples had to be completely rechecked.
Therefore, we were looking for a solution that would work on a small sample. A good quality of data processing was demonstrated by the Random Forest classifier trained on data that was converted into vectors of our bag-of-words model. With the help of cross-validation, we have selected the optimal parameters. Among the advantages of our model are speed and size, as well as relative ease of deployment and additional training.
In the process of working on the Intent Classifier, it became clear that for some tasks its use is not optimal. Suppose the user wants to change the name specified in the insurance, or the car number. That the qualifier correctly defined this intention, it would be necessary to manually add to the template all the phrases used in this case. We found another way: to make a small extractor for the Recognition Service, which defines intent by keywords and NLP methods, and to use the Intent Classifier for non-sample phrases in which the keyword method does not work.
"They always ask about it." FAQ
Many of our clients have sections with FAQ. In order for the user to receive such answers directly from the chat bot, it was necessary to provide a solution that would (a) recognize the FAQ query; b) would find the most relevant answer in our database and give it out.
There are a number of models trained on SQUAD from Stanford. They work well when the response text from the FAQ contains the words from the user's question. Suppose the FAQ says: "Frodo said that he would take the Ring to Mordor, although he did not know the way there." If the user asks: “Where does Frodo put the Ring?”, The system will respond: “To Mordor”.
Our script, as a rule, was different. For example, a bot should respond differently to two similar requests - “Can I pay?” And “Can I pay online?”: In the first case, you can offer a form of payment to a person, in the second case, you can pay online, here’s the page address.
Another class of solutions for assessing the similarity of documents is focused on long answers - at least a few sentences, among which contains information that interests the user. Unfortunately, in cases with short questions and answers (“How do I pay online?” - “You can pay with PayPal”), they are very unstable.
Another solution is the Doc2vec approach: the large text is distilled into a vector representation, which is then compared with other documents in the same form and reveals the coefficient of similarity. This approach also had to be put aside: it is focused on long texts, but we mainly deal with questions and answers from one or two sentences.
Our decision was based on two steps. First: we, using embeddings, translated into vectors each word in the sentence, using the Google Word2vec model. After that, we considered the average vector over all words, representing one sentence as one vector. The second step we took the question vector and found in the FAQ database stored in the same vector form, the closest answer to a certain extent, in our case cosine.
The advantages include ease of implementation, very easy extensibility and fairly simple interpretability. The disadvantages are weak optimization possibilities: this model is difficult to refine - it either works well in most of your use cases, or you have to give it up.
"And talk?". Small talk
Sometimes the user writes something absolutely irrelevant, for example: "The weather is good today." This is not included in the list of interests we are interested in, but we still want to respond intelligently, demonstrating the intelligence of our system.
For such solutions, a combination of the approaches described above is used: they are based on either very simple rule based solutions or generative neural networks. We wanted to get a prototype early, so we took a public dataset from the Internet and used an approach very similar to the one used for the FAQ. For example, a user has written something about the weather — and using an algorithm comparing the vector representations of two sentences for a certain cosine measure, we are looking for a proposal in a public dataset that will be as close as possible to the subject of the weather.
Training
Now we have no goal to create a bot that would learn from every message received from customers: first, experience shows that this is the way to death of the bot (recall how IBM Watson had to erase the database , because it began to diagnose with , and Microsoft's Twitter-bot managed to become a racist in just a day). Secondly, we strive to close the tasks of insurance companies as best we can; self-learning bot is not our business task. We have written a number of tools for linguists and QA-teams, with which they can manually train bots, exploring dialogs and correspondence with users during post-moderation.
However, our bot seems to be ready to pass the Turing test. Some users start a serious conversation with him, believing that they are communicating with an insurance agent, and one even started threatening the chief with a complaint when the bot misunderstood him.
Plans
Now we are working on the visual part: the display of the entire graph of the script and the ability to compose it using the GUI.
On the part of the Recognition Service, we implement linguistic analysis to recognize and understand the meaning of each word in the message. This will improve the accuracy of the reaction and extract additional data. For example, if a person fills in a car insurance and mentions that he has an uninsured house, the bot will be able to remember this message and give it to the operator to contact the client and offer home insurance.
Another feature in the work - processing feedback. After the completion of the dialogue with the bot, we ask the user whether the service pleased him. If Sentiment Analysis recognized the user feedback as positive, we offer the user to share opinions in social networks. If the analysis shows that the user has reacted negatively, the bot clarifies what was wrong, fixes the answer, says: “Okay, we will correct” - and does not offer to share the feedback in the tape.
One of the keys to making communication with the bot as natural as possible is to make the bot modular, to expand the set of reactions available to it. We are working on it. Maybe thanks to this, the user was ready to sincerely accept our bot as an insurance agent. The next step: to make the person try to announce the bot thanks.
The article was written together with Sergey Kondratyuk and Mikhail Kazakov . Write in the comments your questions, we will prepare more practical materials on them.
Source: https://habr.com/ru/post/429638/
All Articles