Teaching an agent to play Mario Kart using filters
Vladimir Ivanov vivanov879 , Sr. Deep Learning Engineer at NVIDIA , continues to talk about reinforcement training. In this article, we will discuss the training of the agent for completing quests and how neural networks use filters for image recognition.
The previous article dealt with agent training for simple shooters.
Vladimir will talk about the application of reinforcement training in practice at the AI Conference on November 22.
')
The previous time, we examined examples of video games, where reinforcement training helps to solve the problem. It is curious that for a successful neural network game only visual information was needed. Every fourth frame, the neural network analyzes the screen shot and makes a decision.

At first glance, it looks like magic. Some kind of complex structure, which is a neural network, receives a picture as input and gives the correct solution. Let's see step by step what is going on inside: what turns a set of pixels into action?
Before you go to the computer, let's see what a person sees.
When a person looks at an image, his gaze clings to both small details (faces, figures of people, trees), and to the picture as a whole. Whether it is a children's play on the alley or a football match, a person, based on his life experience, can understand the content of the picture, the mood and context of the taken picture.

When we admire the work of a master in an art gallery, our life experience still tells us that there are characters behind the layers of colors. You can guess their intentions and movement in the picture.

In the case of abstract painting, a look finds simple shapes on the image: circles, triangles, squares. Find them much easier. Sometimes this is all that manages to see.

Items can be positioned so that the picture acquired an unexpected shade.

When we admire the work of a master in an art gallery, our life experience still tells us that there are characters behind the layers of colors. You can guess their intentions and movement in the picture.
In the case of abstract painting, a look finds simple shapes on the image: circles, triangles, squares. Find them much easier. Sometimes this is all that manages to see.
Items can be positioned so that the picture acquired an unexpected shade.
That is, we can perceive the picture as a whole, abstracting from its specific components. Unlike us, the computer initially does not have this feature. We have a wealth of life experience that tells us which objects are important and what physical properties they have. Let's think what tool to give the machine so that she can study the images.
Many happy owners of phones with high-quality cameras before placing a photo from the phone in a social network impose on it various filters. With the filter, you can change the mood of the photo. You can select some items more clearly.

In addition, the filter can highlight the edges of objects in the photo.

Since the filters have the ability to highlight various objects in the image, let's give the computer the opportunity to pick them up. What is a digital image? This is a square matrix of numbers, at each point of which the intensity values for the three color channels are located: red, green and blue. Now we give the neural network available, for example, 32 filters. Each filter in turn impose on the image. The filter core is applied to adjacent pixels.

Initially, the values of the core of each filter will be random. But we will give the neural network the ability to customize them depending on the task. After the first layer with filters, we can put a few more. Since there are a lot of filters, we need a lot of data to set them up. For this fit any big bank of marked-up pictures. For example, dasset MSCoco.

The neural network adjusts the weights for solving this problem. In our case - for image segmentation, that is, determining the class of each pixel of the image. Now let's see how the images will look after each layer of filters.
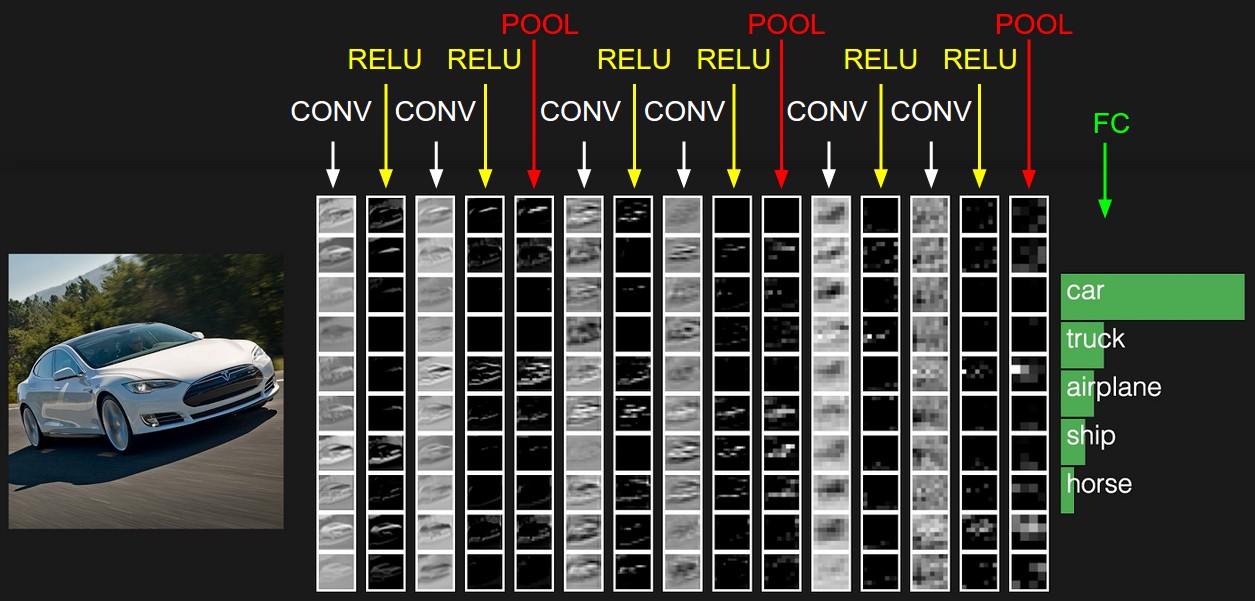
If you look closely, you will notice that the filters in varying degrees leave the car, and clean the surrounding area - the road, trees and sky.
Let's return to the agent who studies to play games. For example, take the racing game Mario Kart.
We gave him a powerful image analysis tool - a neural network. We will see what filters will be selected to learn how to drive. Take for a start an open area.
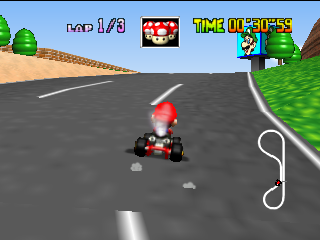
Let's see how the image looks after the first 24 filters. Here they are located in the form of a table 8x3.

It is not necessary for each of the 24 outputs to have an obvious meaning, because the images go further to the input to the following filters. Dependencies can be completely different. However, in this case, you can detect some logic in the outputs. For example, the second filter in the first line highlights the road with black. The first filter of the seventh line duplicates its function. And most of the other filters are clearly visible cards, which we manage.
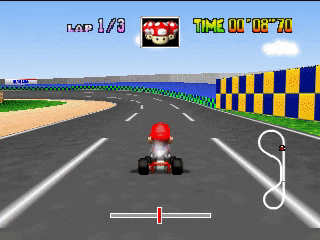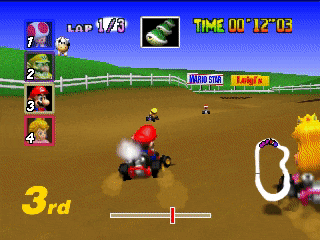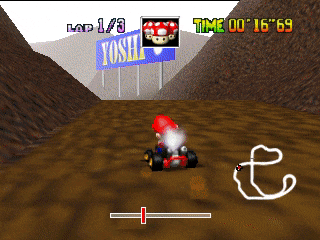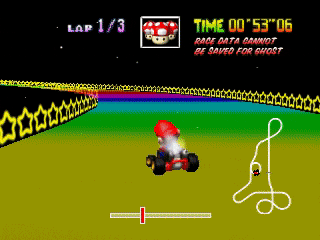
In this game, the surrounding area changes and there is a tunnel. What does the racing neural network pay attention to when entering the tunnel?
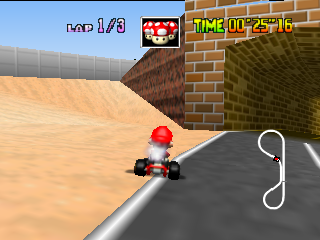
Outputs of the first layer of filters:

In the sixth line, the first filter marks the entrance to the tunnel. Thus, during the ride, the network learned to identify them.
And what happens when the machine gets into the tunnel?

The result of the action of the first 24 filters:

Despite the fact that the illumination of the scene has changed, as well as the environment, the neural network snatches the most important thing - the road and maps. Again, the second filter in the first line, which was responsible for finding the path in an open area, retains its functions in the tunnel. And in the same way, the first filter of the seventh row, as before, finds its way.
Now, when we figured out what the neural network sees, let's try to use it to solve more complex problems. Before that, we considered tasks where there is practically no need to think ahead, but we need to solve the task that is right before us. In shooters and races, you need to act “reflexively”, quickly responding to sudden changes in the game. What about the passage of the quest game? For example, the game Montezuma Revenge, in which you need to find the keys and open the locked doors to get out of the pyramid.

Last time we discussed that the agent did not learn to look for new keys and doors, since these actions take a lot of playing time, and therefore a signal in the form of points received will be very rare. If you use points for battered enemies as a reward to the agent, he will constantly knock out rolling skulls and will not look for new moves.
Let's reward the agent for open new rooms. Let's use a priori the well-known fact that this is a quest, and all the rooms in it are different.

Therefore, if the picture on the screen is fundamentally different from what we saw before, the agent receives a reward.
Before that, we considered game agents that rely solely on visual data during training. But if we have access to other data from the game, we will use them too. Consider, for example, the Dota game. Here, the network receives twenty thousand numbers at the entrance, which completely describe the state of the game. For example, the position of the allies, the health of the towers.

Players are divided into two teams of five people each. The game lasts an average of 40 minutes. Each player chooses a hero with unique abilities. And each player can buy items that change the parameters of damage, speed and field of view.
Despite the fact that the game at first glance is significantly different from Doom, the learning process remains the same. Except for a few moments. Since the planning horizon in this game is higher than in Doom, we will process the last 16 frames for decision making. And the reward signal that the agent receives will be somewhat more complicated. It includes the number of defeated enemies, the damage caused, as well as the money earned in the game. In order for neural networks to play together, we will include in the reward the well-being of the team members of the agent.
As a result, the team of bots beats strong enough teams of people, but loses to the champions. The reason for the defeat is that the bots rarely played an hour long matches. A game with real people dragged on longer than those who played on simulators. That is, if an agent finds himself in a situation for which he has not trained, he begins to have difficulties.
Source: https://habr.com/ru/post/429570/
All Articles