What hides PDF

There are a lot of information in PDF files. Most of it is used for the same visualization of the document on different platforms. But there is also a lot of metadata: the date and time of creation and editing, which application was used, the subject of the document, the title, the author, and much more. This is a standard set of metadata, and there are ways to insert custom metadata into PDF: hidden comments in the middle of the file. In this article, we will present some forms of metadata and show where to look for them.
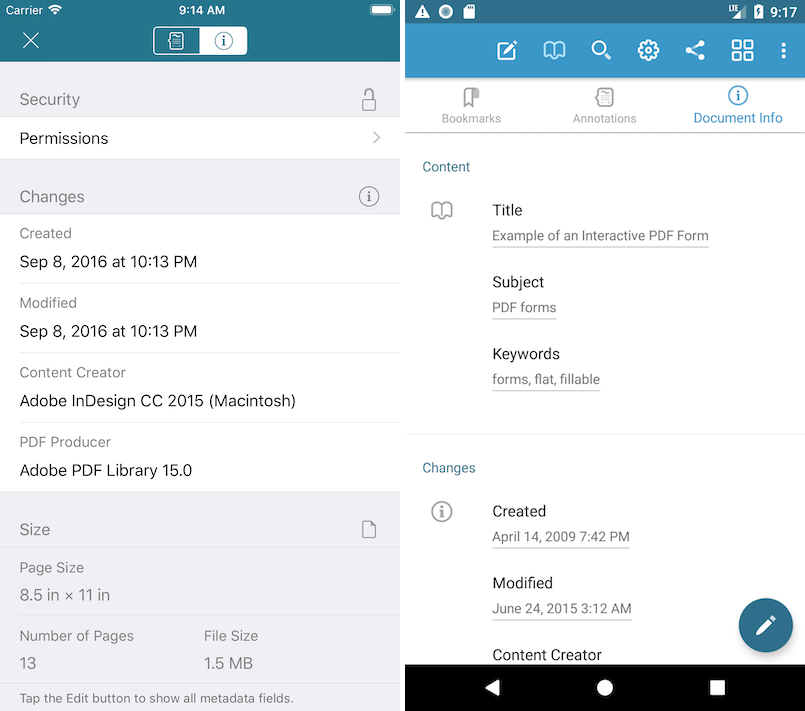
Information Metadata
Starting with PDF 1.0, there is a standardized set of values that can be added to the document. File managers use these values to improve document search. They include:
- Author
- date of creation
- Creator
- Producer
In PDF 1.1, this set was expanded to include additional data that helps to find documents:
')
- Title
- Theme
- Keywords
- Date Edited (ModDate)
Strictly speaking, this information is not really hidden, as many applications allow you to view it. But it is not shown to the general public. In any case, if you are concerned about security, you should carefully rely on this information, because it can be edited later. Since the metadata can be updated separately from the displayed content, this means that the file manager and metadata will show the changes, and the contents may not change.
Additional Metadata
Now the PDF standard supports even more metadata. Instead of a small set of default values, you can store a whole stream of information in XMP format. As a result, there can be embedded data of any type. Again, they are not displayed, but the file manager is able to analyze them.
The XMP stream can be encoded, so it is not always readable by people, but many applications can read and edit this information. Here is an example of what XMP looks like in a human-readable format:
<xmp:CreateDate>1851-08-18</xmp:CreateDate> <xmp:CreatorTool>Ink and Paper</xmp:CreatorTool> <dc:creator> <rdf:Seq> <rdf:li>Nick Winder</rdf:li> </rdf:Seq> </dc:creator> <dc:title> <rdf:Alt> <rdf:li xml:lang="x-default">My Amazing PDF</rdf:li> </rdf:Alt> </dc:title> As it is easy to understand, this information is invaluable when trying to determine the history of a document or trying to embed other information. PSPDFKit for iOS and Android supports reading and editing metadata.
Object Metadata
Metadata streams are not limited to documents only; Metadata can also be assigned to any object in the document. For example, a stream with an embedded image. To complicate matters, supporting metadata can also be stored in the stream itself. If we go further, we can embed PDF into the metadata of the image stream , thereby achieving infinite recursion! Therefore, the next time you check the metadata for information, remember that you may have to go through several levels to find the information you are looking for.
Additional save / update
The PDF standard has the concept of advanced storage, which many applications, including PSPDFKit, implement to speed up storage. In short, this method adds additional information to the end of the document, and old objects that are no longer referenced will remain there. It’s great when you change document elements on the fly and don’t want to wait for a long save process, or, for example, for the auto save function, where the process runs in a background thread and we want to use a minimum of resources.
As you can see, this opens up a whole Pandora's box: the document’s history reveals confidential or erroneous information that has been removed from the eyes, but it remains in the document. In such situations, it is recommended to perform a full document save This will lead to the removal of old objects or even “smoothing”, so that the forms can not be edited in the future.
PDF Comments
In many programming languages, comments are provided so that the compiler or interpreter ignores the string, the same option is in PDF. The% symbol is used in a format in different ways, but one of them is an indication of a comment in the code. Therefore, if a user opens a document in a text editor, he may see some secret messages inserted by your PDF processor. PDF renders will ignore these comment lines, so the file looks correct and does not show any comments after rendering.
One big dictionary!
The last thing to note is that the PDF format is in fact one big dictionary! Technically, anyone can insert a document and change something. Not every change is as easy as editing a single line, but it can be done. For this reason, you should always remember what information can be hidden in PDF. In addition, if you are processing confidential information, you should definitely use digital signatures to ensure that the document is not changed by someone other than its author, and that the author is who you expect, and not someone else.
Conclusion
This article lists some ways to get metadata into a document without your knowledge. There are other factors that need to be considered, such as support for javascript in pdf . With javascript the options are generally endless. Documents can also store hidden objects that are usually analyzed but not displayed. This is a good way to embed some type of information into a parser. PDF is a very extensive standard, so you should always know which PDF reading software you use and trust it.
Source: https://habr.com/ru/post/429138/
All Articles