How to pass cyber tests on the "Checkpoint" part 2
Hello everyone, I am Nikita Curtin, curator of the Israeli High School of IT and Security HackerU .
And I continue to talk about cyber tests from the leading Israeli company in the field of information security Checkpoint. In the previous post I described how I passed four tests, and in this I want to tell you about the following three, which I managed to pass.
For those who missed the first post I will tell, Checkpoint this summer, has published a series of cyber tests.
Challenge officially ended by the end of September 2018.
')
Tasks were divided into six categories:
• Logic
• Web
• Programming
• Networking
• Reversing
• Surprise
Two tasks for each direction. As I already wrote , Checkpoint has already managed to gain respect and interest on my part, so I decided to accept these challenges. However, in view of employment, I was able to allow myself to take on only 8 of 12 tasks (from four different categories). And I managed to solve 7 of them.
So:
Challenge: "Puzzle"
Description:
We finally found you!
We need to assemble this puzzle, and as the prophecy says, only you are capable of it.
The puzzle is very fancy. It consists of a board with 10 columns and 10 rows. Total - 100 parts. And each of them - carries a mystery! Details consist of four parts: upper, lower, right and left. Each share is a number. For example:
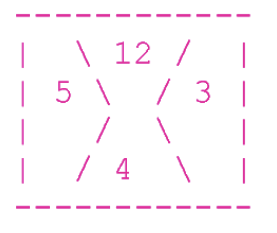
Over - 12, on the right - 3, below - 4 and on the left - 5.
In order for the puzzle to take shape, all the details must be placed on the board in such a way that each share is adjacent to an equal in value.
In addition, the share that does not adjoin to anything, but is part of the board's border, must be with a value of 0. The remaining shares may not have a zero value. Here is a true example of 4 parts:
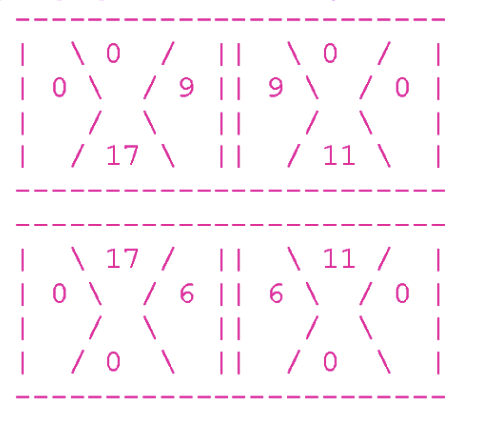
At the top of the board, all shares forming the boundary are zero.
Consider the top left part. Its right share is equal to 9, and the share adjacent to it (the left share of the upper right part) is also equal to 9.
Unfortunately, all our items are shuffled. They are in the following format:
Cube id [share]; cube id, [share];… cube id, [share]
Where id of the cube are numbers from 0 to 99, and the shares consist of numbers arranged in order: upper, right, lower, left.
For example, look at the following shuffled board:

Here is the line describing this board:

We need you to complete the puzzle!
Write us a line that looks exactly like this:
Id of the cube, how many times it needs to be rotated clockwise; cube id, how many times it should be rotated clockwise; ... cube id, how many times it should be rotated clockwise
The line with the solution of this board will look like this:

The above line corresponds to the following (solved) puzzle:

Consider the top left part. In the line it corresponds to the designation "2,2". As we take the cube number 2 from the input:
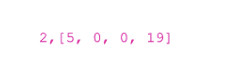
But we twist it clockwise twice and get [0,19,5,0].
Now consider the upper middle part. In the line it corresponds to the designation "1.0". Therefore, we take the cube number 1 from the input:

And we don’t twist it at all (yes, spin 0 times) - it means that it is already in the correct position.
Got it?
Now help us to complete the puzzle!
It looks like this:

Good luck!
Theoretically, this problem can be solved in many different ways. Find your own and share it. I reflected on several options and finally came to the following conclusions:
The first. At any given time, I just need to define one cube. For each cube, I will surely always know two sides: the top and the left. At the beginning it is 0 and 0. The next cube at the top will also have 0, and on the left, the number corresponding to the number of the right fraction of the previous cube.
The second. Because of the huge number of different variations between cubes, I should try to make as few steps as possible and get rid of senseless checking at the first negative result.
Third. To work with different cubes, I always need to remember their initial position (id), the number of turns from the starting point and, apparently, the numbers of the sides (top, right, bottom, left).
Fourth. The initial input is a string. And the output is also a string (and not the current position).
Based on all this, I have developed the following strategy for myself:
To move linearly - from left to right until, until I rest in the right corner. Next, go down to the line and start from the bottom left of the cube, which is above.
Compliance should be checked after each rotation. So if 4 turns have already been made and there is still no match for this cube, I take the next one. Each checked cube can potentially be checked with all the other details, for this I can recursively repeat the initialization of each of them with a full set of all other cubes.
To keep track of all the manipulations with the original data, I chose an object-oriented programming method, in which a cube is an object having an id, a number of rotations, and four sides: top, right, bottom, and left.
Instead of copying the original state and avoiding false counts after multiple rotations, I always increased the count by one. But when I checked the final number of rotations, I used modulo (remainder of division) by 4.
For example, if one rotation is necessary (from [1,2,3,4] to [4,1,2,3]), but first three rotations were mistakenly made (at present [2,3,4,1] ), next time you need 2 (from the current [2,3,4,1] to the required [4,1,2,3]). 3 plus 2 equals 5. And 5% 4 = 1, and this is what you need.
I always need to keep track of used cubes and prevent repeated checks. For this, I use the table of cubes id. And if the compared cube matches, I remove it from the list.
I selected the following data structures:
HashMap - to bind id (initial position) and a cube built from the input string.
Stack - to check the associated id cubes.
Array - for temporary testing of the result.
Object code cube:
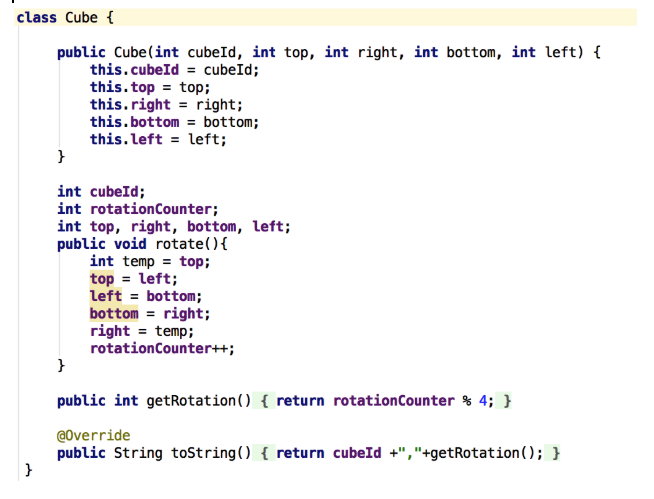
String manipulation functions:

The logic of the decision to find matching cubes:

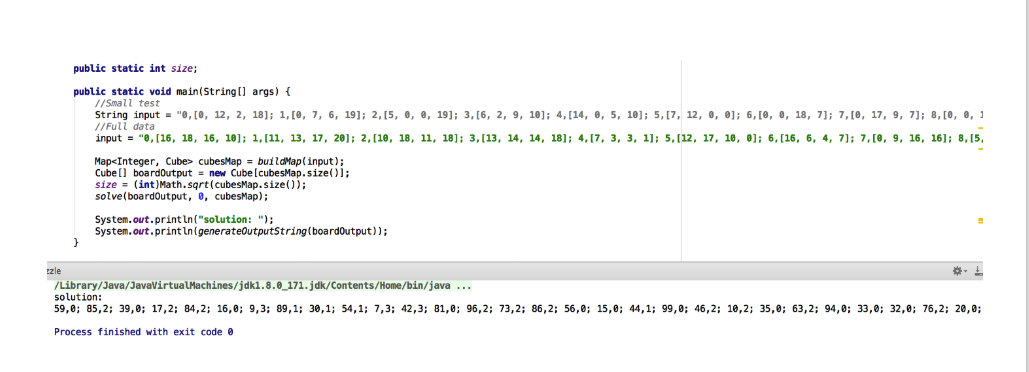
Result:
Challenge: Ping Pong
Description:
I bet you're not fast enough to beat me.
Here is where I am:
nc 35.157.111.68 10158
By running this command, you get:
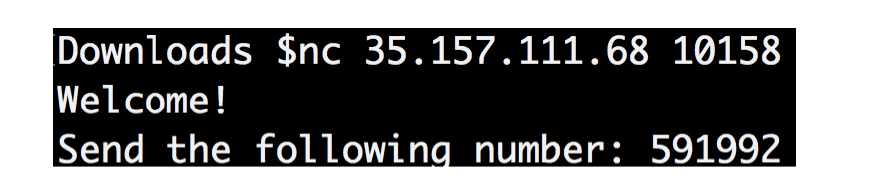
At first glance, it seems that this is a task to work with streams.
However, after receiving the first data, it seems that it falls into the Timeout, and then it will completely disappear.
When the data ends, a new row delimiter appears.
I recreated the stream using Python code.
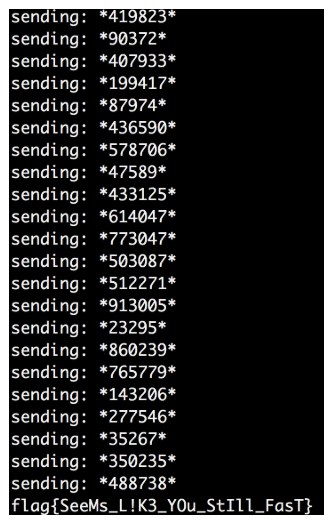
It seemed to work, so I added an iterative code that repeats the ping-pong algorithm, and I will wait until the flag appears.

After a huge number of such ping-pong repassings (perhaps more than a thousand) between the client and the server, I finally achieve the goal.
Challenge: "Protocol"
Description:
Hi!
We need to extract the secret data from a special server. We don’t know much about him, but we managed to intercept traffic that communicates with this server.
We also know that the path to this secret file is: /usr/PRivAtE.txt
You can find the sniff file here (link to file).
Please tell us what the secret is!
Good luck!
I downloaded the file and opened it using Wireshark
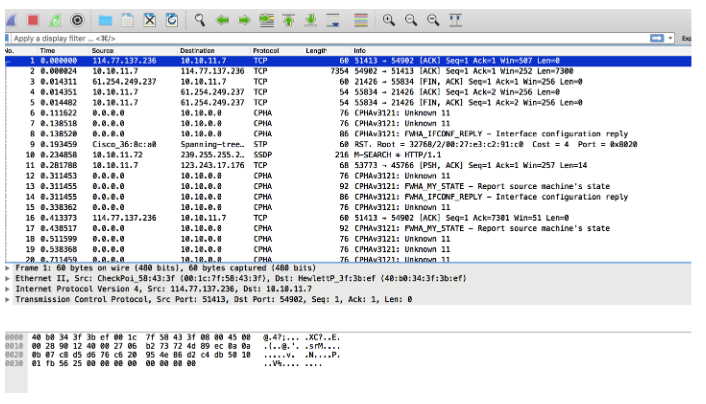
And checked the registered negotiations
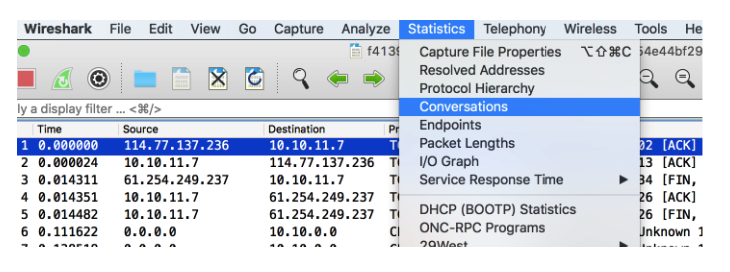
It allowed me to figure out what was going on.
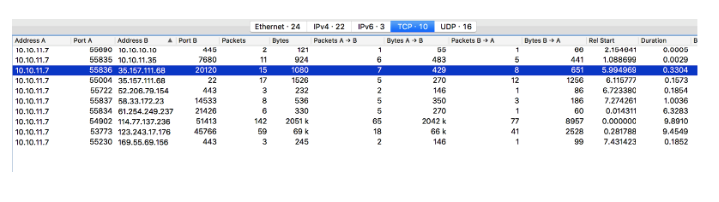
I noticed that there were negotiations between IP 35.157.111.68 through port 20120 and SSH port 22. I should check this port 20120, I decided, and then go to SSH (later I realized that this was not necessary).
I used the nc command to check this IP and port, and received the answer: “0 8 Welcome”
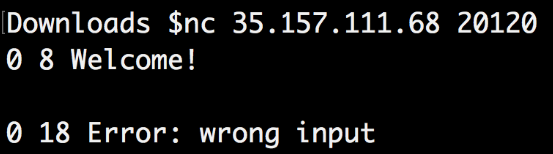
I wasn’t sure what input he was expecting, so I went back to Wireshark to see if there might still be some clues left.
I filtered all data packets for 35.157.111.68 on port 20120 and found an easy-to-read conversation:
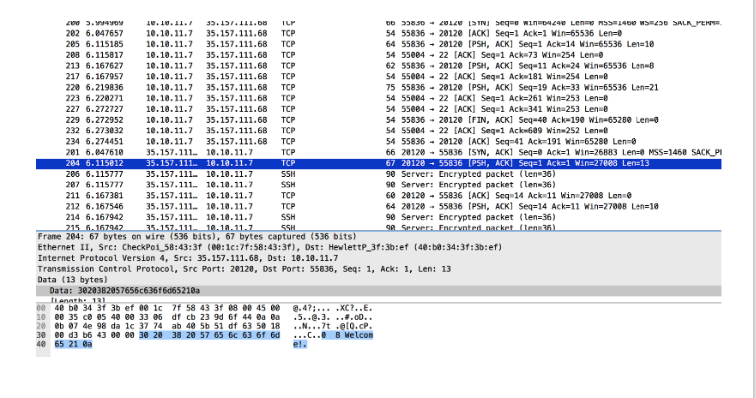
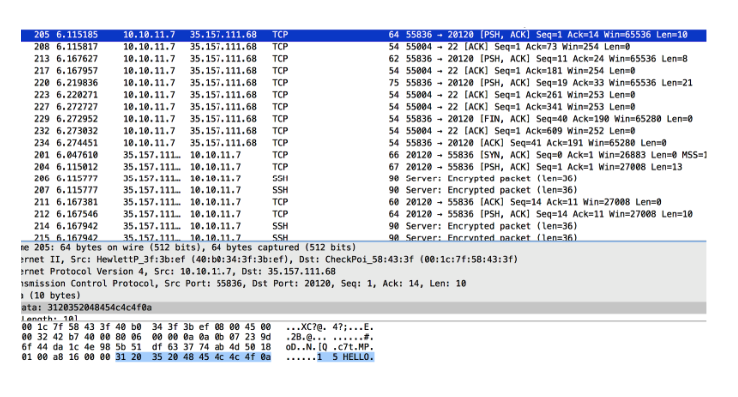
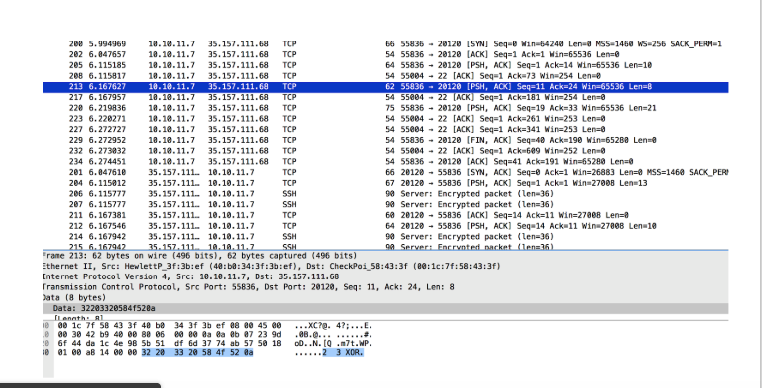
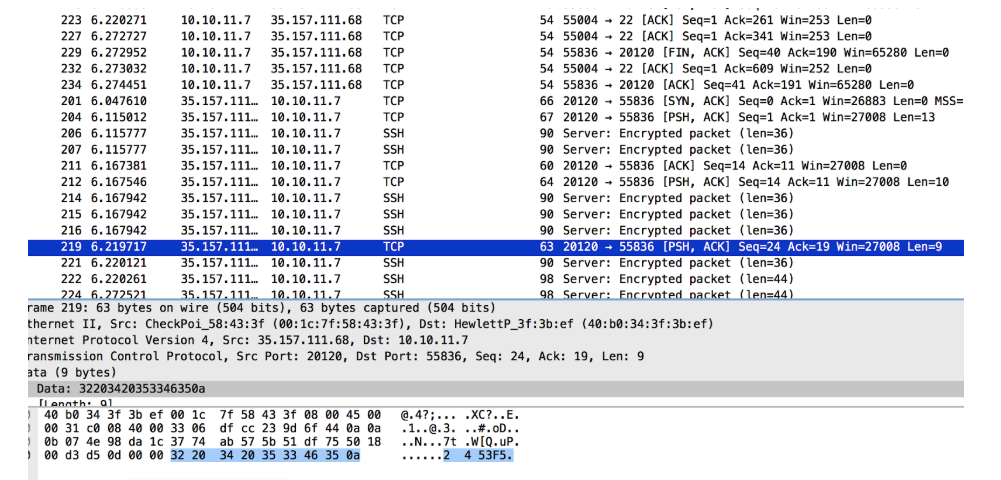
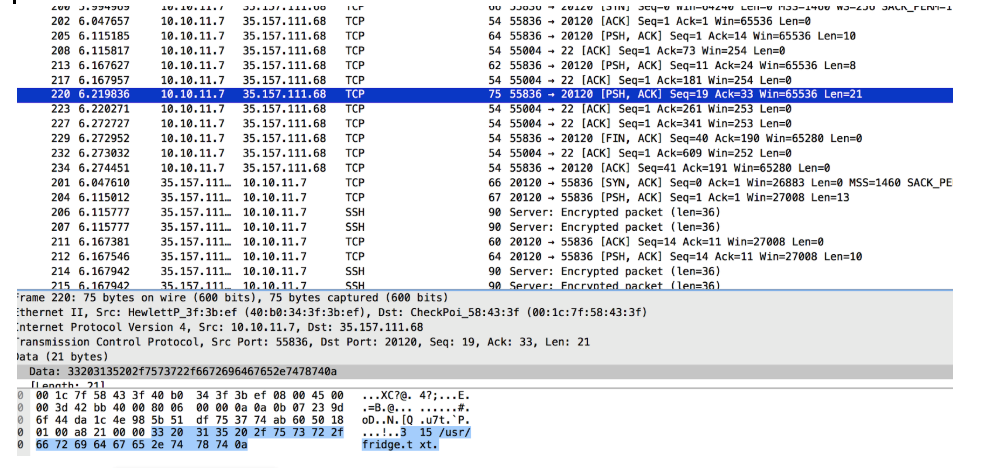
I recreated all this using the nc command line:
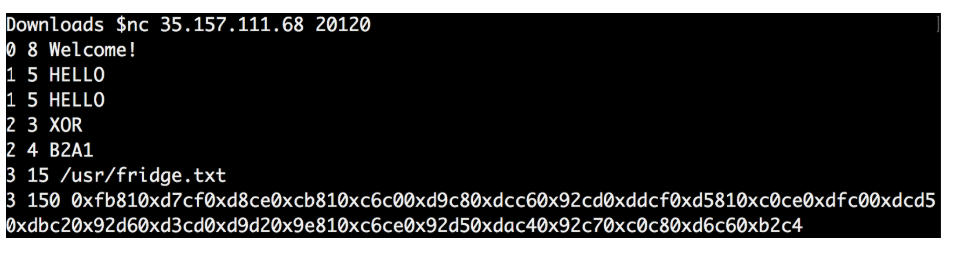
I noticed that the answer to my “2 3 XOR” request was different from the one in the file.
I repeated the whole procedure over and over again to see if the answer changes every time.
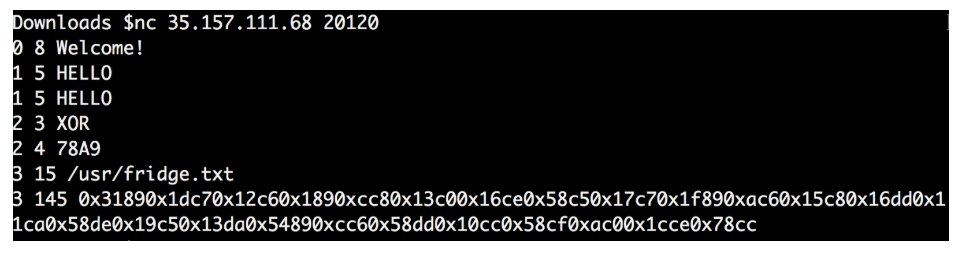
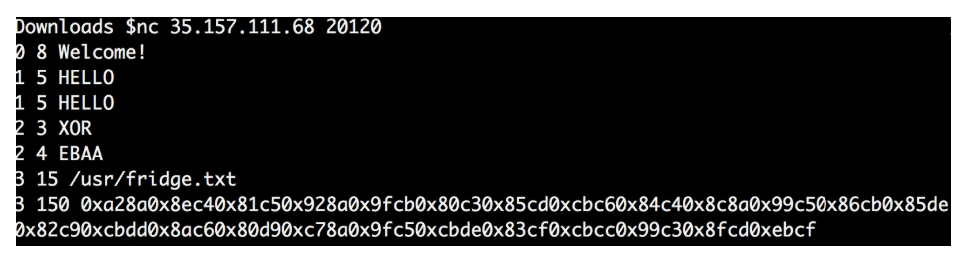
As I thought, the 4 values each time were different, as were the final data.
It seems that the four values obtained are the key to decipher the final data.
I also noticed that the numbers in front of each data packet are not random.
It looks like this.
The first number indicates the order: 0 -> first, 1 -> second, 2 -> third, etc ...
The second number means the length of the phrase 8 -> “Welcome”, 5 -> “Hello” ->, etc ...
I wondered if this was the key to decoding. Since the final data is a continuous block line of 4 HEX values and the XOR key is also 4 HEX values. Perhaps I can iterate over each one and divide it into separate bytes, after which they will be copied with bytes from the key.
And I tried to perform the decryption:

Everything turned out, but there was no flag in the received data.

I reread the rules and remembered that the path to this secret file is: /usr/PRivAtE.txt
I repeated the procedure again, but this time I requested the path "/usr/PRivAtE.txt"
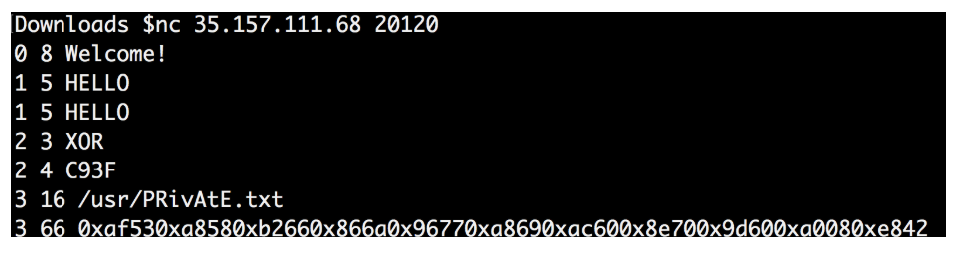
I tried to decrypt the final data again:

And the flag was in my hands:

Did you succeed? Write your ideas and options, I will be glad to comment.
And I continue to talk about cyber tests from the leading Israeli company in the field of information security Checkpoint. In the previous post I described how I passed four tests, and in this I want to tell you about the following three, which I managed to pass.
For those who missed the first post I will tell, Checkpoint this summer, has published a series of cyber tests.
Challenge officially ended by the end of September 2018.
')
Tasks were divided into six categories:
• Logic
• Web
• Programming
• Networking
• Reversing
• Surprise
Two tasks for each direction. As I already wrote , Checkpoint has already managed to gain respect and interest on my part, so I decided to accept these challenges. However, in view of employment, I was able to allow myself to take on only 8 of 12 tasks (from four different categories). And I managed to solve 7 of them.
So:
Challenge: "Puzzle"
Description:
We finally found you!
We need to assemble this puzzle, and as the prophecy says, only you are capable of it.
The puzzle is very fancy. It consists of a board with 10 columns and 10 rows. Total - 100 parts. And each of them - carries a mystery! Details consist of four parts: upper, lower, right and left. Each share is a number. For example:
Over - 12, on the right - 3, below - 4 and on the left - 5.
In order for the puzzle to take shape, all the details must be placed on the board in such a way that each share is adjacent to an equal in value.
In addition, the share that does not adjoin to anything, but is part of the board's border, must be with a value of 0. The remaining shares may not have a zero value. Here is a true example of 4 parts:
At the top of the board, all shares forming the boundary are zero.
Consider the top left part. Its right share is equal to 9, and the share adjacent to it (the left share of the upper right part) is also equal to 9.
Unfortunately, all our items are shuffled. They are in the following format:
Cube id [share]; cube id, [share];… cube id, [share]
Where id of the cube are numbers from 0 to 99, and the shares consist of numbers arranged in order: upper, right, lower, left.
For example, look at the following shuffled board:
Here is the line describing this board:
We need you to complete the puzzle!
Write us a line that looks exactly like this:
Id of the cube, how many times it needs to be rotated clockwise; cube id, how many times it should be rotated clockwise; ... cube id, how many times it should be rotated clockwise
The line with the solution of this board will look like this:
The above line corresponds to the following (solved) puzzle:
Consider the top left part. In the line it corresponds to the designation "2,2". As we take the cube number 2 from the input:
But we twist it clockwise twice and get [0,19,5,0].
Now consider the upper middle part. In the line it corresponds to the designation "1.0". Therefore, we take the cube number 1 from the input:
And we don’t twist it at all (yes, spin 0 times) - it means that it is already in the correct position.
Got it?
Now help us to complete the puzzle!
It looks like this:
Good luck!
Theoretically, this problem can be solved in many different ways. Find your own and share it. I reflected on several options and finally came to the following conclusions:
The first. At any given time, I just need to define one cube. For each cube, I will surely always know two sides: the top and the left. At the beginning it is 0 and 0. The next cube at the top will also have 0, and on the left, the number corresponding to the number of the right fraction of the previous cube.
The second. Because of the huge number of different variations between cubes, I should try to make as few steps as possible and get rid of senseless checking at the first negative result.
Third. To work with different cubes, I always need to remember their initial position (id), the number of turns from the starting point and, apparently, the numbers of the sides (top, right, bottom, left).
Fourth. The initial input is a string. And the output is also a string (and not the current position).
Based on all this, I have developed the following strategy for myself:
To move linearly - from left to right until, until I rest in the right corner. Next, go down to the line and start from the bottom left of the cube, which is above.
Compliance should be checked after each rotation. So if 4 turns have already been made and there is still no match for this cube, I take the next one. Each checked cube can potentially be checked with all the other details, for this I can recursively repeat the initialization of each of them with a full set of all other cubes.
To keep track of all the manipulations with the original data, I chose an object-oriented programming method, in which a cube is an object having an id, a number of rotations, and four sides: top, right, bottom, and left.
Instead of copying the original state and avoiding false counts after multiple rotations, I always increased the count by one. But when I checked the final number of rotations, I used modulo (remainder of division) by 4.
For example, if one rotation is necessary (from [1,2,3,4] to [4,1,2,3]), but first three rotations were mistakenly made (at present [2,3,4,1] ), next time you need 2 (from the current [2,3,4,1] to the required [4,1,2,3]). 3 plus 2 equals 5. And 5% 4 = 1, and this is what you need.
I always need to keep track of used cubes and prevent repeated checks. For this, I use the table of cubes id. And if the compared cube matches, I remove it from the list.
I selected the following data structures:
HashMap - to bind id (initial position) and a cube built from the input string.
Stack - to check the associated id cubes.
Array - for temporary testing of the result.
Object code cube:
String manipulation functions:
The logic of the decision to find matching cubes:
Result:
Challenge: Ping Pong
Description:
I bet you're not fast enough to beat me.
Here is where I am:
nc 35.157.111.68 10158
By running this command, you get:
At first glance, it seems that this is a task to work with streams.
However, after receiving the first data, it seems that it falls into the Timeout, and then it will completely disappear.
When the data ends, a new row delimiter appears.
I recreated the stream using Python code.
It seemed to work, so I added an iterative code that repeats the ping-pong algorithm, and I will wait until the flag appears.
After a huge number of such ping-pong repassings (perhaps more than a thousand) between the client and the server, I finally achieve the goal.
Challenge: "Protocol"
Description:
Hi!
We need to extract the secret data from a special server. We don’t know much about him, but we managed to intercept traffic that communicates with this server.
We also know that the path to this secret file is: /usr/PRivAtE.txt
You can find the sniff file here (link to file).
Please tell us what the secret is!
Good luck!
I downloaded the file and opened it using Wireshark
And checked the registered negotiations
It allowed me to figure out what was going on.
I noticed that there were negotiations between IP 35.157.111.68 through port 20120 and SSH port 22. I should check this port 20120, I decided, and then go to SSH (later I realized that this was not necessary).
I used the nc command to check this IP and port, and received the answer: “0 8 Welcome”
I wasn’t sure what input he was expecting, so I went back to Wireshark to see if there might still be some clues left.
I filtered all data packets for 35.157.111.68 on port 20120 and found an easy-to-read conversation:
I recreated all this using the nc command line:
I noticed that the answer to my “2 3 XOR” request was different from the one in the file.
I repeated the whole procedure over and over again to see if the answer changes every time.
As I thought, the 4 values each time were different, as were the final data.
It seems that the four values obtained are the key to decipher the final data.
I also noticed that the numbers in front of each data packet are not random.
It looks like this.
The first number indicates the order: 0 -> first, 1 -> second, 2 -> third, etc ...
The second number means the length of the phrase 8 -> “Welcome”, 5 -> “Hello” ->, etc ...
I wondered if this was the key to decoding. Since the final data is a continuous block line of 4 HEX values and the XOR key is also 4 HEX values. Perhaps I can iterate over each one and divide it into separate bytes, after which they will be copied with bytes from the key.
And I tried to perform the decryption:
Everything turned out, but there was no flag in the received data.
I reread the rules and remembered that the path to this secret file is: /usr/PRivAtE.txt
I repeated the procedure again, but this time I requested the path "/usr/PRivAtE.txt"
I tried to decrypt the final data again:
And the flag was in my hands:
Did you succeed? Write your ideas and options, I will be glad to comment.
Source: https://habr.com/ru/post/429114/
All Articles