Reinforcement Training
Hello!
We have opened a new stream for the “Machine learning” course, so wait for the articles related to this discipline, so to speak, in the near future. Well, of course, open seminars. And now let's look at reinforcement learning.
Reinforcement training is an important type of machine learning where the agent learns to behave in the environment, performing actions and seeing results.
')
In recent years, we have seen a lot of success in this fascinating field of research. For example, DeepMind and Deep Q Learning Architecture in 2014, victory over the Go champion with AlphaGo in 2016, OpenAI and PPO in 2017, among others.

DeepMind DQN
In this series of articles we will focus on studying the various architectures used today to solve the problem of learning with reinforcement. These include Q-learning, Deep Q-learning, Policy Gradients, Actor Critic and PPO.
In this article you will learn:
It is very important to master these aspects before plunging into the implementation of reinforcement training agents.
The idea of reinforcement training is that the agent learns from the environment, interacting with her and receiving rewards for taking actions.

Learning through interaction with the environment comes from our natural experience. Imagine that you are a child in the living room. You see a fireplace and walk up to it.
Nearby is warm, you feel good (positive reward +1). You understand that fire is a positive thing.
But then you try to touch the fire. Oh! He burned his hand (negative reward -1). You have just realized that fire is positive when you are at a sufficient distance, because it produces heat. But if you get close to him - burn yourself.
That is how people learn through interaction. Reinforcement learning is simply a computational approach to learning through action.
Reinforcement learning process

As an example, imagine an agent is learning to play Super Mario Bros. The reinforcement learning process (Reinforcement Learning - RL) can be modeled as a loop that works as follows:
This RL cycle produces a sequence of states, actions, and rewards.
The agent's goal is to maximize the expected accumulated reward.
The central idea of the reward hypothesis
Why is the agent's goal to maximize the expected accrued remuneration? Well, reinforcement learning is based on the idea of a reward hypothesis. All goals can be described by maximizing the expected accumulated reward.
Therefore, in reinforcement training, in order to achieve the best behavior, we need to maximize the expected accumulated reward.
The accumulated reward at each time step t can be written as:

This is equivalent to:
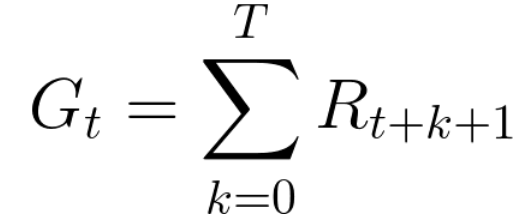
However, in reality, we cannot simply add such rewards. Earlier rewards (at the beginning of the game) are more likely because they are more predictable than rewards in the longer term.

Suppose your agent is a small mouse, and your opponent is a cat. Your goal is to eat the maximum amount of cheese before the cat eats you. As we see in the diagram, the mouse is more likely to eat the cheese next to it than the cheese near the cat (the closer we are to it, the more dangerous it is).
As a result, a cat's reward, even if it is more (more cheese), will be reduced. We are not sure we can eat it. To lower the reward, we do the following:
The accumulated expected remuneration, taking into account discounting, is as follows:
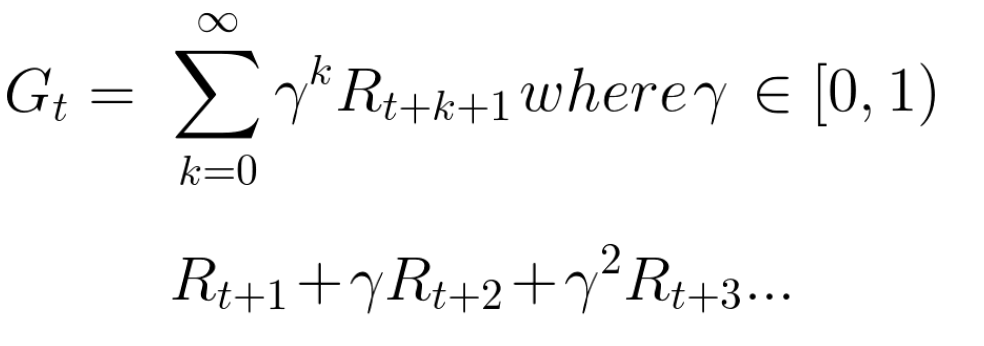
Roughly speaking, each reward will be reduced by a gamut of time. As the time step increases, the cat becomes closer to us, so a future reward is becoming less and less likely.
Episodic or continuous tasks
A task is an instance of a learning problem with reinforcement. We can have two types of tasks: episodic and continuous.
Episodic task
In this case, we have a starting point and an ending point (the terminal state). This creates an episode : a list of states, actions, rewards, and new states.
Take for example Super Mario Bros: the episode begins with the launch of the new Mario and ends when you are killed or reach the end of the level.

Start a new episode
Continuous tasks
These are tasks that go on forever (without a terminal state) . In this case, the agent must learn to choose the best actions and simultaneously interact with the environment.
For example, an agent that performs automated stock trading. For this task there is no starting point and terminal state. The agent continues to work until we decide to stop it.

Monte Carlo vs time difference method
There are two ways to learn:
Monte Carlo
When the episode ends (the agent reaches the “terminal state”), the agent looks at the total accumulated reward to see how well he has done. In the Monte Carlo approach, the reward is obtained only at the end of the game.
Then we start a new game with added knowledge. The agent makes the best decisions with each iteration.
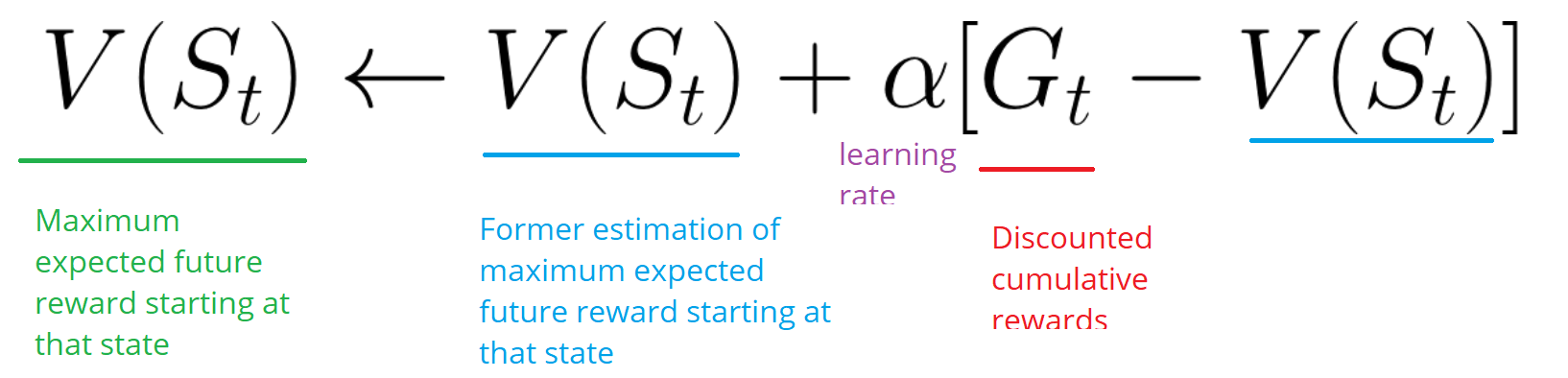
Let's give an example:
If we take the labyrinth as the environment:
By running more and more episodes, the agent will learn to play better and better.
Temporary differences: learning at every time step
The Temporal Difference Learning (TD) method will not wait for the end of the episode to update the maximum possible reward. It will update V depending on the experience gained.
This method is called TD (0) or step-by-step TD (updates the utility function after any single step).

TD methods only expect the next time step to update values. At time t + 1 , a TD target is formed using the reward Rt + 1 and the current estimate V (St + 1).
A TD goal is an estimate of the expected: in fact, you update the previous estimate of V (St) to the goal within one step.
Compromise Exploration / Operation
Before considering the various strategies for solving problems of learning with reinforcement, we must consider another very important topic: a compromise between exploration and exploitation.
Remember that the goal of our RL agent is to maximize the expected accumulated reward. However, we can fall into the common trap.
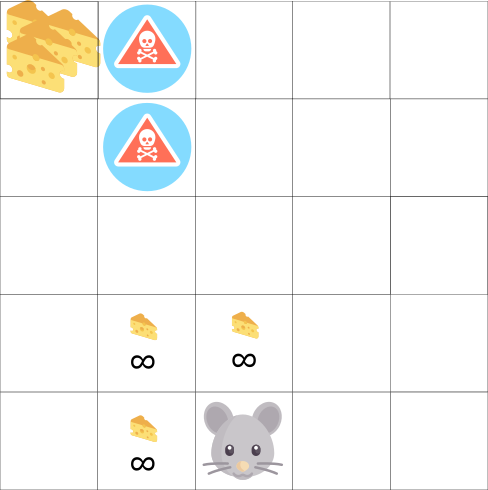
In this game, our mouse can have an infinite number of small pieces of cheese (+1 each). But at the top of the maze there is a giant piece of cheese (+1000). However, if we focus only on remuneration, our agent will never reach a gigantic piece. Instead, he will use only the closest source of rewards, even if this source is small (exploitation). But if our agent looks at the situation a little, he will be able to find a great reward.
This is what we call the trade-off between exploration and exploitation. We must define a rule that will help deal with this compromise. In future articles you will learn different ways to do this.
Three reinforcement training approaches
Now that we have identified the basic elements of reinforcement learning, let's move on to three approaches to solving reinforcement learning objectives: cost-based, policy-based, and model-based.
Based on cost
In cost-based RL, the goal is to optimize the utility function V (s).
A utility function is a function that informs us of the maximum expected reward that an agent will receive in each state.
The value of each state is the total amount of remuneration that an agent can expect to accumulate in the future, starting with this state.
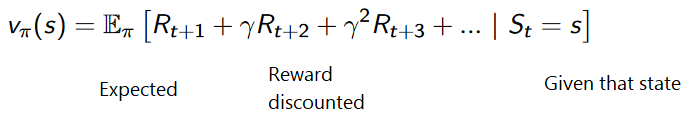
The agent will use this utility function to decide which state to select at each step. The agent selects the state with the highest value.
In the maze example, at each step, we take the largest value: -7, then -6, then -5 (and so on) to achieve the goal.
Based on policy
In RL based on policy, we want to directly optimize the policy function π (s) without using the utility function. The policy is what determines the behavior of the agent at a given time.
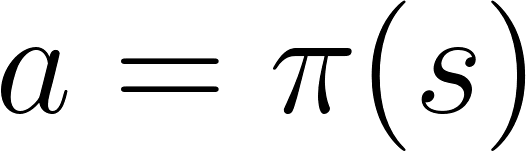
action = policy (state)
We study the function of politics. This allows us to compare each state with the best appropriate action.
There are two types of policies:

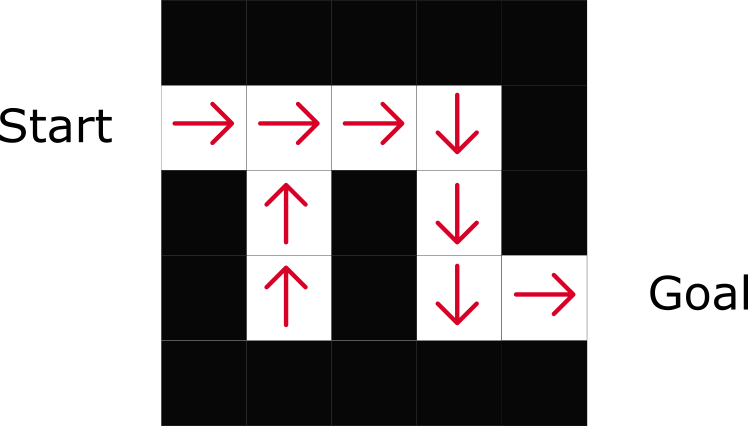
As you can see, the policy directly indicates the best action for each step.
Based on the model
In RL, based on the model, we model the environment. This means that we create a model of environmental behavior. The problem is that each environment will need a different view of the model. That is why we will not focus much on this type of training in the following articles.
Introducing Deep Learning with Reinforcement
Deep Reinforcement Learning (Deep Reinforcement Learning) introduces deep neural networks for solving reinforcement learning problems - hence the name “deep”.
For example, in the next article we will work on Q-Learning (classical reinforcement learning) and Deep Q-Learning.
You will see the difference in that in the first approach we use the traditional algorithm to create a table Q, which helps us to find out what action to take for each state.
In the second approach, we will use a neural network (for approximation of remuneration based on state: the value of q).
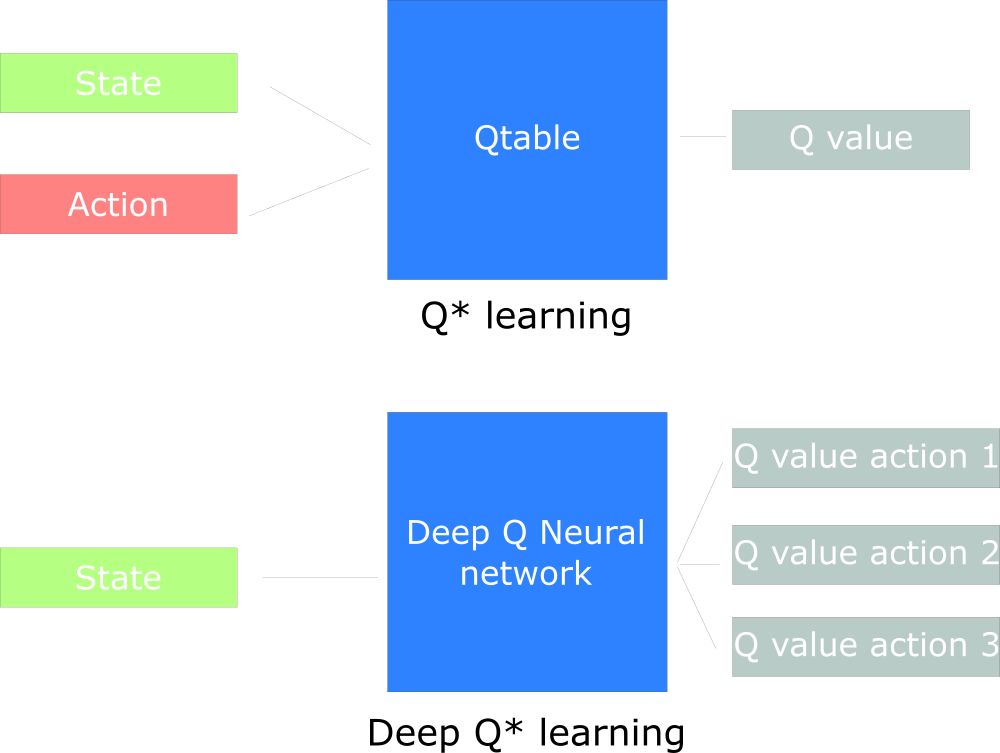
The scheme, inspired by the training manual Q from Udacity
That's all. As always, we are waiting for your comments or questions here or you can ask the course instructor Arthur Kadurin in his open lesson on networking.
We have opened a new stream for the “Machine learning” course, so wait for the articles related to this discipline, so to speak, in the near future. Well, of course, open seminars. And now let's look at reinforcement learning.
Reinforcement training is an important type of machine learning where the agent learns to behave in the environment, performing actions and seeing results.
')
In recent years, we have seen a lot of success in this fascinating field of research. For example, DeepMind and Deep Q Learning Architecture in 2014, victory over the Go champion with AlphaGo in 2016, OpenAI and PPO in 2017, among others.
DeepMind DQN
In this series of articles we will focus on studying the various architectures used today to solve the problem of learning with reinforcement. These include Q-learning, Deep Q-learning, Policy Gradients, Actor Critic and PPO.
In this article you will learn:
- What is reinforcement learning, and why rewards are central
- Three reinforcement training approaches
- What does “deep” mean in deep learning with reinforcement
It is very important to master these aspects before plunging into the implementation of reinforcement training agents.
The idea of reinforcement training is that the agent learns from the environment, interacting with her and receiving rewards for taking actions.
Learning through interaction with the environment comes from our natural experience. Imagine that you are a child in the living room. You see a fireplace and walk up to it.
Nearby is warm, you feel good (positive reward +1). You understand that fire is a positive thing.
But then you try to touch the fire. Oh! He burned his hand (negative reward -1). You have just realized that fire is positive when you are at a sufficient distance, because it produces heat. But if you get close to him - burn yourself.
That is how people learn through interaction. Reinforcement learning is simply a computational approach to learning through action.
Reinforcement learning process
As an example, imagine an agent is learning to play Super Mario Bros. The reinforcement learning process (Reinforcement Learning - RL) can be modeled as a loop that works as follows:
- The agent receives the S0 state from the environment (in our case, we receive the first frame of the game (state) from Super Mario Bros (environment))
- Based on this state of S0, the agent takes action A0 (the agent will move to the right)
- The environment is moving to a new state S1 (new frame)
- The environment gives some reward to R1 agent (not dead: +1)
This RL cycle produces a sequence of states, actions, and rewards.
The agent's goal is to maximize the expected accumulated reward.
The central idea of the reward hypothesis
Why is the agent's goal to maximize the expected accrued remuneration? Well, reinforcement learning is based on the idea of a reward hypothesis. All goals can be described by maximizing the expected accumulated reward.
Therefore, in reinforcement training, in order to achieve the best behavior, we need to maximize the expected accumulated reward.
The accumulated reward at each time step t can be written as:
This is equivalent to:
However, in reality, we cannot simply add such rewards. Earlier rewards (at the beginning of the game) are more likely because they are more predictable than rewards in the longer term.
Suppose your agent is a small mouse, and your opponent is a cat. Your goal is to eat the maximum amount of cheese before the cat eats you. As we see in the diagram, the mouse is more likely to eat the cheese next to it than the cheese near the cat (the closer we are to it, the more dangerous it is).
As a result, a cat's reward, even if it is more (more cheese), will be reduced. We are not sure we can eat it. To lower the reward, we do the following:
- We determine the discount rate, called gamma. It must be between 0 and 1.
- The more gamma, the less discount. This means that the learning agent is more concerned with long-term rewards.
- On the other hand, the smaller the gamma, the greater the discount. This means that the priority is short-term remuneration (the nearest cheese).
The accumulated expected remuneration, taking into account discounting, is as follows:
Roughly speaking, each reward will be reduced by a gamut of time. As the time step increases, the cat becomes closer to us, so a future reward is becoming less and less likely.
Episodic or continuous tasks
A task is an instance of a learning problem with reinforcement. We can have two types of tasks: episodic and continuous.
Episodic task
In this case, we have a starting point and an ending point (the terminal state). This creates an episode : a list of states, actions, rewards, and new states.
Take for example Super Mario Bros: the episode begins with the launch of the new Mario and ends when you are killed or reach the end of the level.
Start a new episode
Continuous tasks
These are tasks that go on forever (without a terminal state) . In this case, the agent must learn to choose the best actions and simultaneously interact with the environment.
For example, an agent that performs automated stock trading. For this task there is no starting point and terminal state. The agent continues to work until we decide to stop it.
Monte Carlo vs time difference method
There are two ways to learn:
- Collecting rewards at the end of the episode, and then calculating the maximum expected future reward - the Monte Carlo approach
- Evaluation of remuneration at every step - a temporary difference
Monte Carlo
When the episode ends (the agent reaches the “terminal state”), the agent looks at the total accumulated reward to see how well he has done. In the Monte Carlo approach, the reward is obtained only at the end of the game.
Then we start a new game with added knowledge. The agent makes the best decisions with each iteration.
Let's give an example:
If we take the labyrinth as the environment:
- We always start with the same starting point.
- We stop the episode if the cat eats us or we move> 20 steps.
- At the end of the episode we have a list of states, actions, rewards and new states.
- The agent summarizes the total Gt reward (to see how well he coped).
- It then updates V (st) in accordance with the above formula.
- Then a new game is launched with new knowledge.
By running more and more episodes, the agent will learn to play better and better.
Temporary differences: learning at every time step
The Temporal Difference Learning (TD) method will not wait for the end of the episode to update the maximum possible reward. It will update V depending on the experience gained.
This method is called TD (0) or step-by-step TD (updates the utility function after any single step).
TD methods only expect the next time step to update values. At time t + 1 , a TD target is formed using the reward Rt + 1 and the current estimate V (St + 1).
A TD goal is an estimate of the expected: in fact, you update the previous estimate of V (St) to the goal within one step.
Compromise Exploration / Operation
Before considering the various strategies for solving problems of learning with reinforcement, we must consider another very important topic: a compromise between exploration and exploitation.
- Intelligence finds more environmental information.
- Exploitation uses known information to maximize reward.
Remember that the goal of our RL agent is to maximize the expected accumulated reward. However, we can fall into the common trap.
In this game, our mouse can have an infinite number of small pieces of cheese (+1 each). But at the top of the maze there is a giant piece of cheese (+1000). However, if we focus only on remuneration, our agent will never reach a gigantic piece. Instead, he will use only the closest source of rewards, even if this source is small (exploitation). But if our agent looks at the situation a little, he will be able to find a great reward.
This is what we call the trade-off between exploration and exploitation. We must define a rule that will help deal with this compromise. In future articles you will learn different ways to do this.
Three reinforcement training approaches
Now that we have identified the basic elements of reinforcement learning, let's move on to three approaches to solving reinforcement learning objectives: cost-based, policy-based, and model-based.
Based on cost
In cost-based RL, the goal is to optimize the utility function V (s).
A utility function is a function that informs us of the maximum expected reward that an agent will receive in each state.
The value of each state is the total amount of remuneration that an agent can expect to accumulate in the future, starting with this state.
The agent will use this utility function to decide which state to select at each step. The agent selects the state with the highest value.
In the maze example, at each step, we take the largest value: -7, then -6, then -5 (and so on) to achieve the goal.
Based on policy
In RL based on policy, we want to directly optimize the policy function π (s) without using the utility function. The policy is what determines the behavior of the agent at a given time.
action = policy (state)
We study the function of politics. This allows us to compare each state with the best appropriate action.
There are two types of policies:
- Deterministic: politics in a given state will always return the same action.
- Stochastic: displays the probability of distribution by action.
As you can see, the policy directly indicates the best action for each step.
Based on the model
In RL, based on the model, we model the environment. This means that we create a model of environmental behavior. The problem is that each environment will need a different view of the model. That is why we will not focus much on this type of training in the following articles.
Introducing Deep Learning with Reinforcement
Deep Reinforcement Learning (Deep Reinforcement Learning) introduces deep neural networks for solving reinforcement learning problems - hence the name “deep”.
For example, in the next article we will work on Q-Learning (classical reinforcement learning) and Deep Q-Learning.
You will see the difference in that in the first approach we use the traditional algorithm to create a table Q, which helps us to find out what action to take for each state.
In the second approach, we will use a neural network (for approximation of remuneration based on state: the value of q).
The scheme, inspired by the training manual Q from Udacity
That's all. As always, we are waiting for your comments or questions here or you can ask the course instructor Arthur Kadurin in his open lesson on networking.
Source: https://habr.com/ru/post/429090/
All Articles