Continuous integration in Yandex
Maintaining a huge code base while ensuring high performance for a large number of developers is a serious challenge. Over the past 5 years, Yandex has been developing a special system of continuous integration. In this article, we’ll tell you about the scale of the Yandex code base, about transferring development to a single repository with a trunk-based approach to development, about what tasks a continuous integration system should solve in order to work effectively in such conditions.

Many years ago in Yandex there were no special rules in the development of services: each department could use any languages, any technologies, any deployment systems. And as practice has shown, such freedom did not always help to move forward faster. At that time, there were often several in-house or open-source developments for solving the same problems. With the growth of the company, this ecosystem worked worse. At the same time, we wanted to remain one big Yandex, and not be divided into many independent companies, because it gives a lot of advantages: many people do some similar tasks, the results of their work can be reused. Starting from a variety of data structures, such as distributed hash tables and lock-free queues, and ending with a lot of different specialized code that we have written for 20 years.
Many tasks that we solve do not solve in the open-source world. There is no MapReduce that works well on our volumes (5000+ servers) and our tasks, there is no task tracker that can handle all of our tens of millions of tickets. This is attractive in Yandex - you can do really big things.
But we have a serious drop in efficiency when we solve the same tasks anew, rework ready-made solutions, making it difficult to integrate between components. It is good and convenient to do everything just for yourself in your own corner, you can not think about others for the time being. But as soon as the service becomes quite noticeable, it will have dependencies. It only seems that different services are weakly dependent on each other, in fact - there are a lot of connections between different parts of the company. Many services are available through the application Yandex / Browser /, etc., or embedded in each other. For example, Alice appears in the Browser, with the help of Alice you can order a taxi. We all use common components: YT , YQL , Nirvana .
The old development model had significant problems. Due to the presence of many repositories, it’s difficult for an ordinary developer, especially for a beginner, to find out:
- where is the component?
- how it works: there is no opportunity to "take and read"
- Who is developing and supporting it now?
- How to start using it?
As a result, there was a problem of mutual use of components. The components almost could not use other components, because they represented "black boxes" for each other. This had a negative effect on the company, since the components were not only not re-used, but often did not improve. Many components were duplicated, the amount of code that had to be maintained was greatly increased. We generally moved slower than we could.
Single repository and infrastructure
5 years ago we started a project to transfer development to a single repository, with common systems for building, testing, deploying and monitoring.
The main goal we wanted to achieve is to remove interference that prevents the integration of someone else's code. The system should provide easy access to ready-made working code, a clear scheme for its connection and use, collection: projects are always collected (and pass tests).
As a result of the project, a single stack of infrastructure technologies emerged for the company: source code storage, code review system, build system, continuous integration system, deployment, monitoring.
Now most of the source code of Yandex projects is stored in a single repository, or is in the process of moving to it:
- More than 2000 developers work on projects.
- over 50,000 projects and libraries.
- repository size exceeds 25 GB.
- more than 3,000,000 commits have already been made to the repository.
Benefits for the company:
- Any project from the repository gets ready infrastructure:
- a system for viewing and navigating through the source code and a code-review system.
- build system and distributed build. This is a separate large topic, and we will definitely reveal it in the following articles.
- continuous integration system.
- deployment, integration with the monitoring system.
- code sharing, active team interaction.
- all code is shared, you can come to another project and make the changes you need there. This is especially important in a large company, because the other team, from which you need something, may not have the resources. With the common code, you have the opportunity to do some of the work yourself and “help it happen” to the changes you need.
- There is an opportunity to conduct global refactoring. You do not need to maintain old versions of your API or library, you can change them and change the places where they are used in other projects.
- the code becomes less “diverse”. You have a set of ways to solve problems, and there is no need to add another way that does roughly the same thing, but with a few differences.
- In the project next to you, most likely, there will be no completely exotic languages and libraries.
It should also be understood that this development model has drawbacks that need to be taken into account:
- a common repository requires a separate special infrastructure.
- the library you need may not be in the repository, but it is in open-source. There are costs to add and update it. It strongly depends on the language and the library, somewhere almost free, somewhere very expensive.
- you need to constantly work on the health of the code. This includes at least the fight against unnecessary dependencies and the "dead" code.
Our approach to a common repository imposes general rules that everyone should follow. In the case of using a single repository, restrictions are imposed on the languages used, libraries, deployment methods. But in the next project everything will be the same or very similar to yours, and you can even fix something there.
To the model of the general repository, all large companies. The monolithic repository is a large and well studied and discussed topic, so now we will not go into it much. If you would like to learn more, then at the end of the article you will find several useful links that reveal this topic in more detail.
Conditions in which the continuous integration system operates
Development is conducted on the model Trunk based development. Most users work with HEAD or the most recent copy of the repository obtained from the main branch called trunk, which is being developed. Committing changes to the repository are performed sequentially. Immediately after the commit, the new code is visible and can be used by all developers. Development in separate branches is not welcome, although branches can be used for releases.
Projects depend on the source code. Projects and libraries form a complex dependency graph. And that means that changes made in one project potentially affect the rest of the repository.
A large stream of commits goes to the repository:
- more than 2000 commits per day.
- up to 10 changes per minute during peak hours.
The codebase contains more than 500,000 build targets and tests.
Without a special system of continuous integration in such conditions it would be very difficult to move quickly forward.
Continuous integration system
The system of continuous integration launches assemblies and tests for each change:
- Precommit checks. Allowing you to check the code before the commit and avoid breaking tests on the trunk. Assemblies and tests run on top of HEAD. Currently, precommit checks are run voluntarily. For particularly important projects pre-commit checks are required.
- Postcommit checks after committing to the repository.
Builds and tests run in parallel on large clusters of hundreds of servers. Builds and tests run on different platforms. Under the main platform (linux), all projects are collected and all tests are run, and under the other platforms, a subset set up by users.
After receiving and analyzing the results of the builds and the test run, the user receives feedback, for example, if changes break any tests.

In case of detection of new breakdowns of the assembly or tests, we send a notification to test owners and the author of changes. The system also stores and displays the results of checks in a special interface. The web interface of the integration system displays the progress and the result of the test with a breakdown by test type. The screen with the results of verification now may look like this:
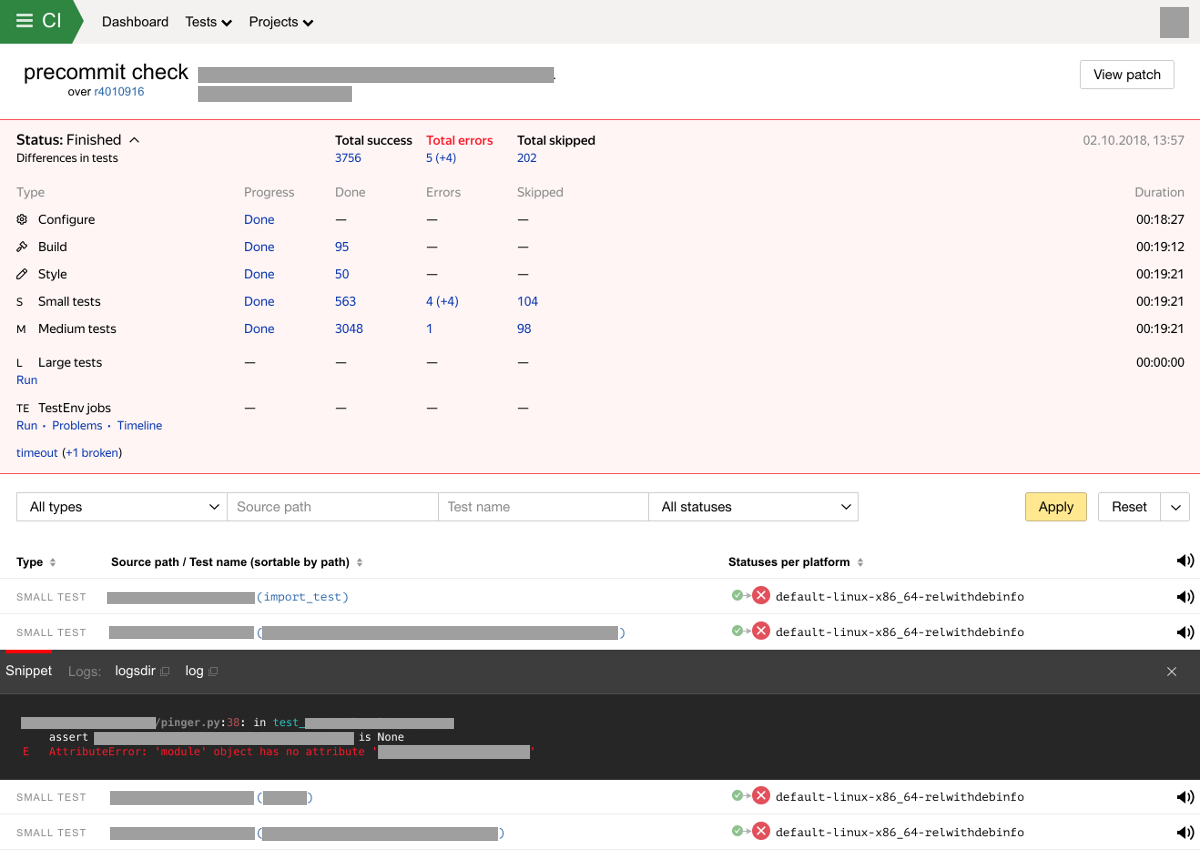
Features and capabilities of the continuous integration system
Solving various problems faced by developers and testers, we developed our system of continuous integration. The system is already solving many problems, but there is still much to be improved.
Types and sizes of tests
There are several types of targets that a continuous integration system can launch:
- configure. The configuration step performed by the build system. The configuration includes the analysis of the configuration files of the build system, the definition of dependencies between projects and the parameters of the build and run tests.
- build. Build libraries and projects.
- style. At this stage, it is checked that the code style meets the specified requirements.
- test. Tests are divided into stages according to their timeout for operation time and requirements for computing resources.
- small. <1 min
- medium. <10 min
- large. > 10 min. In addition, there may be special requirements for computing resources.
- extra large. This is a special type of test. Such tests are characterized by a set of the following characteristics: long operating time, large consumption of resources, large amount of input data, they may require special access and most importantly support complex test scripts described below. There are much fewer such tests than other types of tests, but they are very important.
Test run frequency and binary breakdown search
Huge resources are allocated for testing in Yandex - hundreds of powerful servers. But even with a large number of resources, we can not run all the tests for each change affecting them. But at the same time it is very important for us to always help the developer to localize the place where the test breaks, especially in such a large repository.
How we act. For every change for all affected projects, builds, style checks, and tests with small and medium sizes are run. The rest of the tests are run not on every affecting commit, but at some intervals, if there are commits that affect the tests. In some cases, users can control the startup frequency, in other cases, the startup frequency is set by the system. If a test breakdown is detected, the process of searching for a test commit commit is started. The less frequently the test is run, the longer we will look for breaking commit after detecting a breakdown.

')
When running precommit checks, we also run only assemblies and light tests. Further, the user can manually initiate the launch of heavy tests by selecting from the list provided by the system of affected tests.
Flashing Test Detection
Flashing tests are such tests, the result of the launch (Passed / Failed) of which on the same code may depend on various factors. The causes of the flashing tests can be different: sleep in the test code, errors when working with multithreading, infrastructure problems (inaccessibility of any systems), etc. Flashing tests present a serious problem:
- This leads to the fact that the system of continuous integration spam false notifications about breakdowns of tests.
- Pollute the results of checks. It becomes more difficult to decide on the success of the test results.
- Delay product releases.
- Difficult to detect. Tests may flash very rarely.
Developers can ignore flashing tests when analyzing test results. Sometimes incorrect.
It is impossible to completely eliminate the flashing tests, it must be taken into account in the system of continuous integration.
At the moment, for every check we run all the tests twice to detect flashing tests. We also take into account complaints from users (notification recipients). If we detect blinking, we mark the test with a special flag (muted) and inform the test owner. After this, only test owners will receive notification of test breakdowns. Next, we continue to run the test in the normal mode, while analyzing the history of its launches. If the test does not blink in a specific time window, the automation may decide that the test has stopped flashing and you can reset the flag.
Our current algorithm is quite simple and many improvements are planned in this place. First of all, we want to use much more useful signals.
Automatic update of test input
When testing the most complex Yandex systems, in addition to other testing methods, testing using black box strategy + data-driven testing is often used. To ensure good coverage, such tests require a large set of input data. Data can be selected from production clusters. But there is a problem with the fact that the data quickly become obsolete. The world does not stand still, our systems are constantly evolving. Outdated test data over time will not provide good test coverage, and then completely lead to breakage of the test due to the fact that programs begin to use new data that are not in the outdated test data.
In order for the data not to become outdated, the continuous integration system is able to update it automatically. How it works.
- Test data is stored in a special resource repository.
- The test contains metadata describing the required input data.
- The correspondence between the required test input data and the resources is stored in the continuous integration system.
- The developer provides regular delivery of fresh data to the storage of resources.
- The continuous integration system searches for new versions of test data in the resource repository and switches input data.
It is important to update the data in such a way that false testing will not occur. You cannot just take and, starting from a certain commit, start using new data, since in the event of a breakdown of the test, it will be unclear who is to blame - commit or new data. This will also make diff tests unresponsive (described below).

Therefore, we make it so that there is some small interval of commits, on which the test is launched from both the old and the new versions of the input data.

Diff tests
Diff tests we call a special type of data-driven tests that differ from the generally accepted approach in that the test does not have a reference result, but at the same time we need to find in which commits the test changed its behavior.
The standard approach to data-driven testing is as follows. The test has a benchmark result when you first run the test. The benchmark result can be stored in the repository next to the test. Subsequent runs of the test should lead to the same result.

If the result is different from the reference, the developer must decide whether the change is expected or error. If the change is expected, the developer should update the reference result while fixing the changes in the repository.
There are difficulties when using this approach in a large repository with large flows of commits:
- There can be many tests and the tests can be very hard. The developer does not have the opportunity to run all the affected tests in the working environment.
- After making changes, the test may break if the reference result was not updated simultaneously with making changes to the code. Then another developer can make changes to the same component and the test result will change again. We get the imposition of one error on another. With such problems it is very difficult to understand, it takes time from the developers.
What we do. Diff tests consist of 2 parts:
- Check component.
- We start the test and save the result to the resource storage.
- Do not compare the result with the reference.
- We can catch some of the errors, for example, the program does not start / does not end, crashes, the program does not respond. The result can also be validated: the presence of any fields in the response, etc.
- Diff component.
- We compare the results obtained on different launches and build diff. In the simplest case, this is a function that takes 2 parameters and returns a diff.
- The appearance of the diff depends on the test, but it must be understandable for someone who will look at the diff. Usually diff is an html file.
The launch of check and diff components is controlled by a continuous integration system.

If the continuous integration system detects a diff, then a binary search is first performed on the commit that caused the change. After receiving a notification from the developer, it is possible to examine the diff and decide what to do next: recognize the diff as expected (for this you need to perform a special action) or repair / "roll back" your changes.
To be continued
In the next article we will tell about how the system of continuous integration is arranged.
Links
Monolithic repository, Trunk-based development
Data-driven testing
Source: https://habr.com/ru/post/428972/
All Articles