Building client routing / semantic search at Profi.ru
Building client routing / semantic search and clustering arbitrary external corpuses at Profi.ru
Tldr
2 department of the DS Department for a bit more than a few months. done at first).
Projected goals
- If you’re looking at what you’re looking for, then you can’t understand how to do it.
- Find totally new services and synonyms for the existing services;
- As a sub-goal of (2) - learn to build proper clusters on arbitrary external corpuses;
Achieved goals
It was clear that I’m not able to get it. enough proxies + probably some experience with selenium).
Business goals:
- ~
88+%(vs ~60%with elastic search) accuracy for client routing / intent classification (~5kclasses); - Search is agnostic to input quality (misprints / partial input);
- Classifier generalizes the morphologic structure of the language is exploited;
- Classifier severely beats elastic on various benchmarks (see below);
- New services were found + at least
15,000synonyms (vs. the current state of5,000+ ~30,000). I expect this figure to double;
The last bullet is a ballpark estimate, but a conservative one.
Also AB tests will follow. But I am confident in these results.
"Scientific" goals:
- We have been thoroughly compared with the database of service synonyms;
- We are able to beat weakly supervised (see their bag-size-a-bag-of-ngrams) elastic pattern on this benchmark (see details below) using UNSUPERVISED methods;
- We’ve been developing a model for the RLP, which is an RRNNGNG case-style bag;
- We demonstrated that our final embedding technique was combined with state-of-the-art unsupervised algorithms (UMAP + HDBSCAN) can produce stellar clusters;
- We demonstrated the possibility of feasibility and usability of:
- Knowledge distillation;
- Augmentations for text data (sic!);
- Training text-based classifiers with dynamic augmentations reduced convergence of time drastically (10x) compared to generating static datasets (ie, CNN);
Overall project structure
This does not include the final classifier.
We also have redeemed the classifier bottleneck.

What works in NLP now?
A birds' eye view:
Also you may know that NLP may be experiencing the moment now .
Large scale UMAP hack
UMAP to 100m + point (or maybe even 1bn) sized datasets. Essentially build a KNN graph with FAIS and then just rewrite the main UMAP loop into PyTorch using your GPU. We’ve only got 10-15m points after all, but please follow this thread for details.
What works best
- For supervised fast-text classification meets the RNN (bi-LSTM) + carefully chosen set of n-grams;
- Implementation - plain python for n-grams + PyTorch Embedding bag layer;
- For clustering - this model + UMAP + HDBSCAN;
Best classifier benchmarks
Manually annotated dev set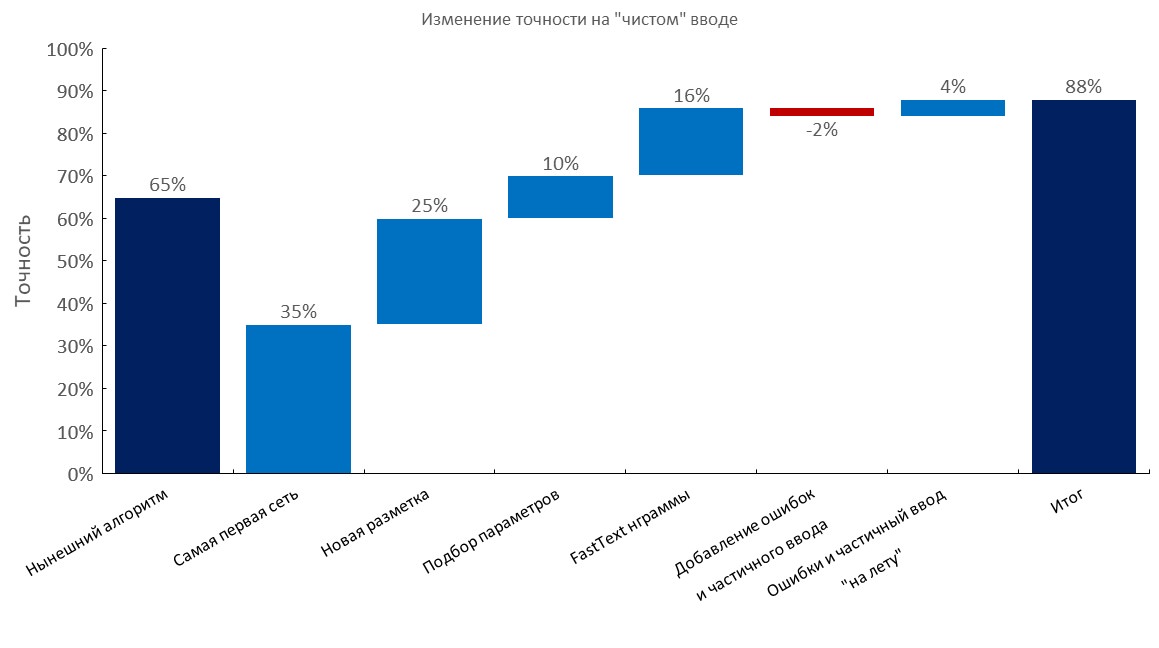
Left to right:
(Top1 accuracy)
- Current algorithm (elastic search);
- First RNN;
- New annotation;
- Tuning;
- Fast-text embedding bag layer;
- Adding typos and partial input;
- Dynamic generation of errors and partial input ( training time reduced by 10x );
- Final score;
Manually annotated dev set + 1-3 errors per query
Left to right:
(Top1 accuracy)
- Current algorithm (elastic search);
- Fast-text embedding bag layer;
- Adding typos and partial input;
- Dynamic generation of errors and partial input;
- Final score;
Manually annotated dev set + partial input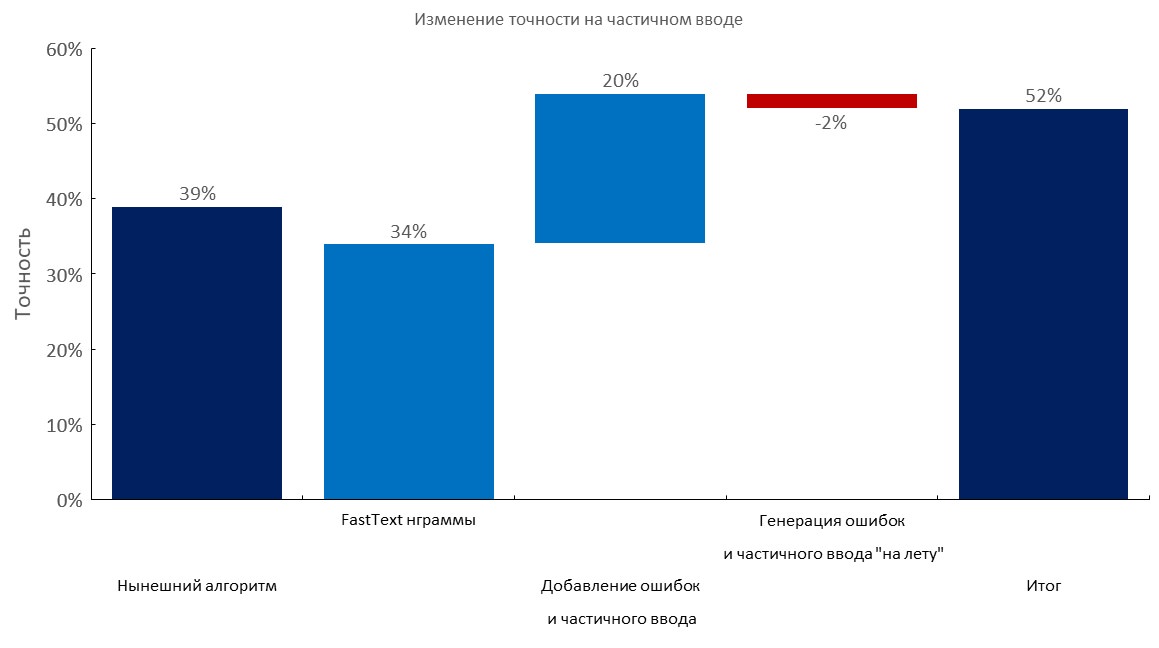
Left to right:
(Top1 accuracy)
- Current algorithm (elastic search);
- Fast-text embedding bag layer;
- Adding typos and partial input;
- Dynamic generation of errors and partial input;
- Final score;
Large scale corpuses / n-gram selection
- We collected the largest corpuses for the Russian language:
- Areneum - a processed version is available here - dataset authors did not reply;
- Taiga ;
- Common crawl and wiki - please follow these articles;
- We collected a
100mword dictionary using 1TB crawl ; - Also use this hack to download such files faster (overnight);
- (I.e. 500kg class)
Stress test of our 1M n-grams on 100M vocabulary:
Text augmentations
In a nutshell:
- Take a large dictionary with errors (eg 10-100m unique words);
- Generate an error (drop a letter, swap a letter using calculated probabilities, insert a random letter, maybe use keyboard layout, etc);
- Check that new word is in dictionary;
If you’re trying to get the best of your money, you’ll be able to do this. 30-50% of words we had on some corpuses .
Our approach is far superior, if you have access to a large domain vocabulary .
Best unsupervised / semi-supervised results
KNN is used to compare different embedding methods.
(vector size) List of models tested:
- (512) Large scale fighter sentence trained on 200 GB of common crawl data;
- (300) sentence a sentence sentence from a service;
- (300) Fast-text obtained from here, pre-trained on araneum corpus;
- (200) Fast-text trained for our domain data;
- (300) Fast-text trained on 200GB of Common Crawl data;
- (300) A Siamese network trained with services / synonyms / random sentences from Wikipedia;
- (200) First iteration of embedding bag embossing bag;
- (200) Same, the word is taken;
- (300);
- (300);
- (250) Bottleneck layer (250 neurons);
- Weakly supervised elastic search baseline;
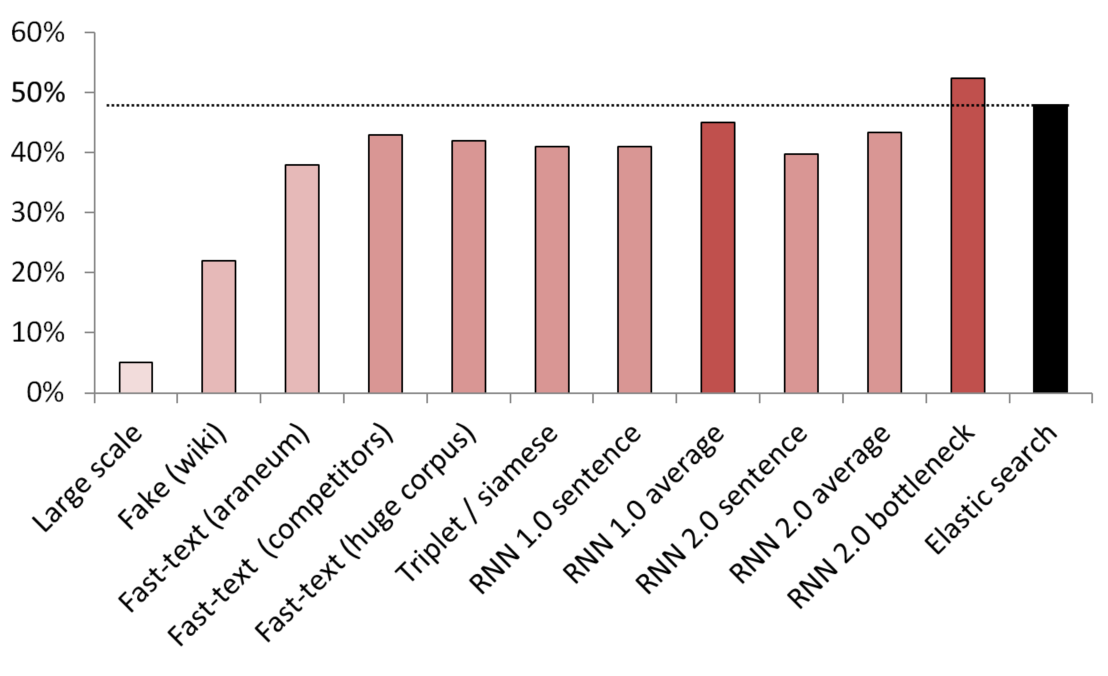
To avoid leaks, all sampled. It was compared with services / synonyms. It was taken by the women to get vocabularies (it was not embraced by the words of the Wikipedia sentence).
Cluster visualization
3D
2D
Cluster exploration "interface"
Green - new word / synonym.
Gray background - likely new word.
Gray text - existing synonym.

We didn’t
- See the above charts;
- Plain average / tf-idf average of fast-text embeddings - a VERY formidable baseline ;
- Fast-text> Word2Vec for Russian;
- Sentence embedding by fake;
- BPE (sentencepiece) showed no improvement on our domain;
- Char level models struggled to generalize, despite the recant paper from google;
- We tried a multi-head transformer (LSTM-based models.) When we migrated, we’dn’t be able to follow the embracing bag;
- BERT - it seems to be overkill
- ELMO - Seems like I think it’s not worth it;
Deploy
Done using:
- Docker container with a simple web-service;
- CPU-only for inference is enough;
- ~
2.5 msper query on CPU, batching not really necessary; - ~
1GBRAM memory footprint; - Almost no dependencies, apart from
PyTorch,numpyandpandas(and web server ofc). - Mimic fast-text n-gram generation like this ;
- Embedding bag layer + indexes as a directory;
')
Source: https://habr.com/ru/post/428674/
All Articles