Single Core Windows
Windows is one of the most versatile and flexible operating systems, it works on completely different architectures and is available in different versions. Today, it supports x86, x64, ARM and ARM64 architectures. Windows at one time supported Itanium, PowerPC, DEC Alpha and MIPS. In addition, Windows supports a variety of SKUs operating in various environments; from data centers, laptops, Xbox and phones to embedded versions for the Internet of things, for example, at ATMs.
The most surprising aspect is that the core of Windows practically does not change depending on all these architectures and SKUs . The kernel is dynamically scaled depending on the architecture and the processor on which it works, so as to take full advantage of the hardware. Of course, there is a certain amount of code associated with a particular architecture in the kernel, but there is a minimal amount of it, which allows Windows to run on various architectures.
In this article, I will talk about the evolution of key parts of the Windows kernel, which allow it to transparently scale from low-power NVidia Tegra chip running on Surface RT 2012 to giant monsters working in Azure data centers.
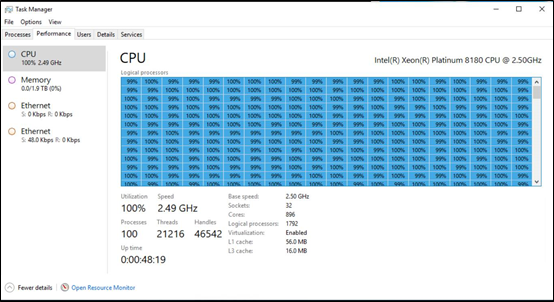
Windows Task Manager running on a prerelease Windows DataCenter class machine, with 896 cores supporting 1792 logical processors and 2 TB of memory
')
Before discussing the details of the Windows kernel, we make a small digression towards refactoring . Refactoring plays a key role in increasing the reuse of OS components on various SKUs and platforms (for example, client, server, and phone). The basic idea of refactoring is to allow reuse of the same DLL on different SKUs, supporting small modifications made specifically for the desired SKU, without renaming the DLL or breaking applications.
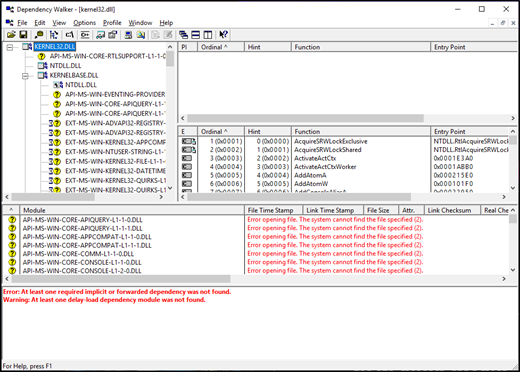
The basic Windows refactoring technology is a little-documented technology called " API sets ." API sets are a mechanism that allows the OS to decouple the DLL and the place of their use. For example, the API set allows applications for win32 to continue to use kernel32.dll, while the implementation of all APIs is written to another DLL. These implementation DLLs may also differ in different SKUs. You can view the API sets in the business by running a dependency bypassing on a traditional Windows DLL, for example, kernel32.dll.
Having finished this digression about the structure of Windows, which allows the system to maximize code reuse and sharing, let's move on to the technical depths of launching the kernel according to the scheduler, which is the key to OS scaling.
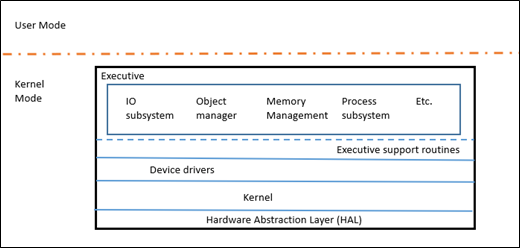
Windows NT is essentially a microkernel , in the sense that it has its own core Kernel (KE) with a limited set of functions, using the Executive layer (Ex) to execute all high-level policies. EX is still a kernel mode, so this is not exactly a microkernel. The kernel is responsible for scheduling threads, synchronizing between processors, handling hardware-level exceptions, and implementing low-level functions that depend on hardware. The EX layer contains various subsystems that provide a set of functionality, which is usually considered the core - IO, Object Manager, Memory Manager, Process Subsystem, etc.
To better understand the size of the components, here’s an approximate breakdown of the number of lines of code in several key directories of the kernel source tree (including comments). The table does not include much more related to the core.
For more information on the Windows architecture, see the “ Windows Internals ” book series.
Having prepared the ground in this way, let's talk a little about the scheduler, its evolution and how the Windows kernel can scale to so many different architectures with so many processors.
A stream is a basic unit that executes program code, and it is the Windows scheduler that plans its work. When deciding which threads to start, the scheduler uses their priorities, and in theory, the thread with the highest priority should run on the system, even if it means that there is no time left for threads with lower priorities.
Having worked quantum time (the minimum amount of time that a thread can work), the stream experiences a decrease in dynamic priority so that threads with high priority cannot work forever, the soul of everyone else. When another thread wakes up to work, it is prioritized, calculated based on the importance of the event that caused the wait (for example, the priority is greatly increased for the foreground user interface, and not much to complete input / output operations). Therefore, the thread works with high priority, while it remains interactive. When it becomes associated primarily with computing (CPU-bound), its priority drops, and it is returned to it after other high-priority threads get their CPU time. In addition, the kernel arbitrarily increases the priority of ready-made threads that have not received processor time for a certain period in order to prevent their computational starvation and correct the inversion of priorities.
The Windows scheduler initially had one ready queue, from which it selected the next highest priority thread to start. However, with the beginning of support for an ever-increasing number of processors, the only line has become a bottleneck, and around the exit area of Windows Server 2003, the scheduler changed jobs and organized one ready queue per processor. When switching to the support of several requests for a single processor, they did not make a single global lock protecting all the queues, and allowed the scheduler to make decisions based on local optima. This means that at any time one thread with the highest priority runs in the system, but does not necessarily mean that the N highest priority threads in the list (where N is the number of processors) are running in the system. This approach justified itself until Windows began to switch to low-power CPUs, such as laptops and tablets. When the stream with the highest priorities did not work on such systems (for example, the user interface front-end stream), this led to noticeable interface glitches. Therefore, in Windows 8.1, the scheduler was transferred to a hybrid model, with queues for each processor for threads associated with this processor, and a shared queue of ready processes for all processors. This did not affect the speed in a noticeable way due to other changes in the architecture of the scheduler, for example, refactoring of the database lock of the dispatcher.
In Windows 7, they introduced such a thing as a dynamic scheduler with fair shares (Dynamic Fair Share Scheduler, DFSS); This primarily concerned terminal servers. This feature tried to solve the problem related to the fact that one terminal session with a high CPU load could affect flows in other terminal sessions. Since the scheduler did not take into account the session and simply used the priority for the distribution of threads, users in different sessions could affect the work of users in other sessions, strangling their flows. It also gave an unfair advantage to sessions (and users) with a large number of threads, since a session with a large number of threads had more opportunities to get CPU time. An attempt was made to add to the scheduler a rule according to which each session was treated on an equal basis with the others in terms of processor time. There is similar functionality in Linux with their absolutely honest scheduler ( Completely Fair Scheduler ). In Windows 8, this concept was summarized as a group scheduler and added to the scheduler, with the result that each session fell into an independent group. In addition to priorities for threads, the scheduler uses the scheduler groups as a second-level index, deciding which thread to run next. In the terminal server, all scheduler groups have the same weight, so all sessions get the same amount of CPU time, regardless of the number or priority of threads within the scheduler groups. In addition, such groups are also used for more precise control over processes. In Windows 8, work objects (Job) were added to support CPU time management . Using a special API, you can decide which part of the processor time a process can use, should it be a soft or hard constraint, and be notified when the process reaches these constraints. This is similar to cgroups resource management on Linux.
Starting with Windows 7, Windows Server now supports over 64 logical processors on a single computer. To add support for such a large number of processors, a new category, the “processor group,” was introduced into the system. A group is an unchanged set of logical processors with the number of not more than 64 pieces, which are considered by the scheduler as a computational unit. The kernel when loading determines which processor belongs to which group, and for machines with fewer than 64 processor cores, this approach is almost impossible to notice. One process can be divided into several groups (for example, an instance of a SQL server); a single thread at a time can be executed only within one group.
But on machines where the number of CPU cores exceeds 64, Windows began to show new bottlenecks that did not allow such demanding applications as SQL Server to scale linearly with the increase in the number of processor cores. Therefore, even with the addition of new cores and memory, speed measurements did not show a significant increase. One of the main problems associated with this was a dispute over the blocking of the dispatcher base. The blocking of the dispatcher's base protected access to the objects that had to be scheduled. Among these objects are streams, timers, I / O ports, other kernel-susceptible objects (events, semaphores, mutexes). Under the pressure of the need to resolve such problems, in Windows 7, work was done to eliminate the blocking of the dispatcher's base and replace it with more precise adjustments, for example, object-by-blocking. This allowed performance measurements such as SQL TPC-C to show a 290% increase in speed compared to the previous scheme in some configurations. It was one of the biggest productivity gains in the history of Windows, due to a change in a single feature.
Windows 10 brought another innovation by introducing CPU sets. CPU Sets allow the process to divide the system so that the process can be divided into several groups of processors, not allowing other processes to use them. The Windows kernel doesn't even allow device interrupts to use the processors in your set. This ensures that even devices will not be able to execute their code on processors issued to the group of your application. It looks like a low-tech virtual machine. It is clear that this is a powerful feature, so many security measures are built into it so that the application developer does not make big mistakes while working with the API. The functionality of the CPU sets is used in game mode (Game Mode).
Finally, we come to support ARM64, which appeared in Windows 10 . The ARM architecture supports the big.LITTLE architecture, which is heterogeneous in nature - the “large” core runs fast and consumes a lot of energy, while the “small” core runs slowly and consumes less. The idea is that minor tasks can be performed on a small core, thus saving battery. To support the big.LITTLE architecture and increase battery life when running Windows 10 on ARM, support for a heterogeneous layout was added to the scheduler, taking into account the wishes of the application working with the big.LITTLE architecture.
By desires, I mean that Windows tries to maintain applications with high quality, tracking threads running in the foreground (or those that do not have enough CPU time), and ensuring that they run on the “big” core. All background tasks, services, and other auxiliary threads run on small kernels. Also in the program, you can forcibly mark the unimportance of the thread to make it work on a small core.
Work on Behalf: in Windows, quite a lot of work in the foreground is carried out by other services running in the background. For example, when searching in Outlook, the search itself is performed by the Indexer background service. If we just run all the services on the small core, the quality and speed of the applications in the foreground will suffer. So that under such scenarios of work it does not slow down on the big.LITTLE architectures, Windows tracks application calls to other processes in order to perform work on their behalf. In this case, we give out the foreground priority to the flow related to the service, and force it to run on the large core.
With this let me finish the first article on the Windows kernel, giving an overview of the work of the scheduler. Articles with similar technical details about the internal workings of the OS will follow later.
The most surprising aspect is that the core of Windows practically does not change depending on all these architectures and SKUs . The kernel is dynamically scaled depending on the architecture and the processor on which it works, so as to take full advantage of the hardware. Of course, there is a certain amount of code associated with a particular architecture in the kernel, but there is a minimal amount of it, which allows Windows to run on various architectures.
In this article, I will talk about the evolution of key parts of the Windows kernel, which allow it to transparently scale from low-power NVidia Tegra chip running on Surface RT 2012 to giant monsters working in Azure data centers.
Windows Task Manager running on a prerelease Windows DataCenter class machine, with 896 cores supporting 1792 logical processors and 2 TB of memory
')
Evolution of a single core
Before discussing the details of the Windows kernel, we make a small digression towards refactoring . Refactoring plays a key role in increasing the reuse of OS components on various SKUs and platforms (for example, client, server, and phone). The basic idea of refactoring is to allow reuse of the same DLL on different SKUs, supporting small modifications made specifically for the desired SKU, without renaming the DLL or breaking applications.
The basic Windows refactoring technology is a little-documented technology called " API sets ." API sets are a mechanism that allows the OS to decouple the DLL and the place of their use. For example, the API set allows applications for win32 to continue to use kernel32.dll, while the implementation of all APIs is written to another DLL. These implementation DLLs may also differ in different SKUs. You can view the API sets in the business by running a dependency bypassing on a traditional Windows DLL, for example, kernel32.dll.
Having finished this digression about the structure of Windows, which allows the system to maximize code reuse and sharing, let's move on to the technical depths of launching the kernel according to the scheduler, which is the key to OS scaling.
Kernel components
Windows NT is essentially a microkernel , in the sense that it has its own core Kernel (KE) with a limited set of functions, using the Executive layer (Ex) to execute all high-level policies. EX is still a kernel mode, so this is not exactly a microkernel. The kernel is responsible for scheduling threads, synchronizing between processors, handling hardware-level exceptions, and implementing low-level functions that depend on hardware. The EX layer contains various subsystems that provide a set of functionality, which is usually considered the core - IO, Object Manager, Memory Manager, Process Subsystem, etc.
To better understand the size of the components, here’s an approximate breakdown of the number of lines of code in several key directories of the kernel source tree (including comments). The table does not include much more related to the core.
| Kernel subsystems | Lines of code |
|---|---|
| Memory manager | 501, 000 |
| Registry | 211,000 |
| Power | 238,000 |
| Executive | 157,000 |
| Security | 135,000 |
| Kernel | 339,000 |
| Process sub-system | 116,000 |
For more information on the Windows architecture, see the “ Windows Internals ” book series.
Scheduler
Having prepared the ground in this way, let's talk a little about the scheduler, its evolution and how the Windows kernel can scale to so many different architectures with so many processors.
A stream is a basic unit that executes program code, and it is the Windows scheduler that plans its work. When deciding which threads to start, the scheduler uses their priorities, and in theory, the thread with the highest priority should run on the system, even if it means that there is no time left for threads with lower priorities.
Having worked quantum time (the minimum amount of time that a thread can work), the stream experiences a decrease in dynamic priority so that threads with high priority cannot work forever, the soul of everyone else. When another thread wakes up to work, it is prioritized, calculated based on the importance of the event that caused the wait (for example, the priority is greatly increased for the foreground user interface, and not much to complete input / output operations). Therefore, the thread works with high priority, while it remains interactive. When it becomes associated primarily with computing (CPU-bound), its priority drops, and it is returned to it after other high-priority threads get their CPU time. In addition, the kernel arbitrarily increases the priority of ready-made threads that have not received processor time for a certain period in order to prevent their computational starvation and correct the inversion of priorities.
The Windows scheduler initially had one ready queue, from which it selected the next highest priority thread to start. However, with the beginning of support for an ever-increasing number of processors, the only line has become a bottleneck, and around the exit area of Windows Server 2003, the scheduler changed jobs and organized one ready queue per processor. When switching to the support of several requests for a single processor, they did not make a single global lock protecting all the queues, and allowed the scheduler to make decisions based on local optima. This means that at any time one thread with the highest priority runs in the system, but does not necessarily mean that the N highest priority threads in the list (where N is the number of processors) are running in the system. This approach justified itself until Windows began to switch to low-power CPUs, such as laptops and tablets. When the stream with the highest priorities did not work on such systems (for example, the user interface front-end stream), this led to noticeable interface glitches. Therefore, in Windows 8.1, the scheduler was transferred to a hybrid model, with queues for each processor for threads associated with this processor, and a shared queue of ready processes for all processors. This did not affect the speed in a noticeable way due to other changes in the architecture of the scheduler, for example, refactoring of the database lock of the dispatcher.
In Windows 7, they introduced such a thing as a dynamic scheduler with fair shares (Dynamic Fair Share Scheduler, DFSS); This primarily concerned terminal servers. This feature tried to solve the problem related to the fact that one terminal session with a high CPU load could affect flows in other terminal sessions. Since the scheduler did not take into account the session and simply used the priority for the distribution of threads, users in different sessions could affect the work of users in other sessions, strangling their flows. It also gave an unfair advantage to sessions (and users) with a large number of threads, since a session with a large number of threads had more opportunities to get CPU time. An attempt was made to add to the scheduler a rule according to which each session was treated on an equal basis with the others in terms of processor time. There is similar functionality in Linux with their absolutely honest scheduler ( Completely Fair Scheduler ). In Windows 8, this concept was summarized as a group scheduler and added to the scheduler, with the result that each session fell into an independent group. In addition to priorities for threads, the scheduler uses the scheduler groups as a second-level index, deciding which thread to run next. In the terminal server, all scheduler groups have the same weight, so all sessions get the same amount of CPU time, regardless of the number or priority of threads within the scheduler groups. In addition, such groups are also used for more precise control over processes. In Windows 8, work objects (Job) were added to support CPU time management . Using a special API, you can decide which part of the processor time a process can use, should it be a soft or hard constraint, and be notified when the process reaches these constraints. This is similar to cgroups resource management on Linux.
Starting with Windows 7, Windows Server now supports over 64 logical processors on a single computer. To add support for such a large number of processors, a new category, the “processor group,” was introduced into the system. A group is an unchanged set of logical processors with the number of not more than 64 pieces, which are considered by the scheduler as a computational unit. The kernel when loading determines which processor belongs to which group, and for machines with fewer than 64 processor cores, this approach is almost impossible to notice. One process can be divided into several groups (for example, an instance of a SQL server); a single thread at a time can be executed only within one group.
But on machines where the number of CPU cores exceeds 64, Windows began to show new bottlenecks that did not allow such demanding applications as SQL Server to scale linearly with the increase in the number of processor cores. Therefore, even with the addition of new cores and memory, speed measurements did not show a significant increase. One of the main problems associated with this was a dispute over the blocking of the dispatcher base. The blocking of the dispatcher's base protected access to the objects that had to be scheduled. Among these objects are streams, timers, I / O ports, other kernel-susceptible objects (events, semaphores, mutexes). Under the pressure of the need to resolve such problems, in Windows 7, work was done to eliminate the blocking of the dispatcher's base and replace it with more precise adjustments, for example, object-by-blocking. This allowed performance measurements such as SQL TPC-C to show a 290% increase in speed compared to the previous scheme in some configurations. It was one of the biggest productivity gains in the history of Windows, due to a change in a single feature.
Windows 10 brought another innovation by introducing CPU sets. CPU Sets allow the process to divide the system so that the process can be divided into several groups of processors, not allowing other processes to use them. The Windows kernel doesn't even allow device interrupts to use the processors in your set. This ensures that even devices will not be able to execute their code on processors issued to the group of your application. It looks like a low-tech virtual machine. It is clear that this is a powerful feature, so many security measures are built into it so that the application developer does not make big mistakes while working with the API. The functionality of the CPU sets is used in game mode (Game Mode).
Finally, we come to support ARM64, which appeared in Windows 10 . The ARM architecture supports the big.LITTLE architecture, which is heterogeneous in nature - the “large” core runs fast and consumes a lot of energy, while the “small” core runs slowly and consumes less. The idea is that minor tasks can be performed on a small core, thus saving battery. To support the big.LITTLE architecture and increase battery life when running Windows 10 on ARM, support for a heterogeneous layout was added to the scheduler, taking into account the wishes of the application working with the big.LITTLE architecture.
By desires, I mean that Windows tries to maintain applications with high quality, tracking threads running in the foreground (or those that do not have enough CPU time), and ensuring that they run on the “big” core. All background tasks, services, and other auxiliary threads run on small kernels. Also in the program, you can forcibly mark the unimportance of the thread to make it work on a small core.
Work on Behalf: in Windows, quite a lot of work in the foreground is carried out by other services running in the background. For example, when searching in Outlook, the search itself is performed by the Indexer background service. If we just run all the services on the small core, the quality and speed of the applications in the foreground will suffer. So that under such scenarios of work it does not slow down on the big.LITTLE architectures, Windows tracks application calls to other processes in order to perform work on their behalf. In this case, we give out the foreground priority to the flow related to the service, and force it to run on the large core.
With this let me finish the first article on the Windows kernel, giving an overview of the work of the scheduler. Articles with similar technical details about the internal workings of the OS will follow later.
Source: https://habr.com/ru/post/428469/
All Articles